







写在前面
仅作为技术学习和练习,不会对服务器及其它造成相关影响,不用于商业用途
其它由于运行本文源代码对安居客造成的一切影响或由于用于其它商业用途产生的相关责任与作者无关
初步分析
首先是要明确目标地址,明确目标地址后,就可以对页面进行整体分析了
目标地址:https://yt.zu.anjuke.com/fangyuan![]() https://yt.zu.anjuke.com/fangyuan
https://yt.zu.anjuke.com/fangyuan
目标地址只能到根目录下的一级分类,如果直接链接到二级分类就会触发验证码
请输入验证码 ws:121.36.42.44![]() https://yt.zu.anjuke.com/fangyuan/gaoxinquf进入页面后,可以先根据网站的分类选择进行选择,选择的时候我们要注意观察url的变化,不同的参数代表了我们不同的选择,这对我们后面进行抓取是有用的
https://yt.zu.anjuke.com/fangyuan/gaoxinquf进入页面后,可以先根据网站的分类选择进行选择,选择的时候我们要注意观察url的变化,不同的参数代表了我们不同的选择,这对我们后面进行抓取是有用的

 可以看到在选择几个选项后url的变化
可以看到在选择几个选项后url的变化
zu.anjuke.com是域名地址
fangyuan、gaoxinquf可以直接音译
zj204:zj是租金的意思,204是代表的租金价位段是1k-1.5k的,基于这个我们推断
zj201 zj202 zj203 zj204 zj205是代表每一个租金价位段
后面的fx1,根据我们选择的顺序可以知道是代表的是房型,这里选择了一室,所以给出了一个fx1
二、三、四也是这样代表 fx1 fx2 fx3 fx4
最后是类型,类型肯定就是最后一个参数了 x1
所以最后类型的判断就是x1 x2可以这样推断
所以最后的结果就是:
域名/fangyuan(房源)/gaoxinquf(高新区房)/zj204(租金1k-1.5k)-fx1(一室)-x1(整租)
有了这个之后我们就确定了目标地址,确定目标地址后就可以对页面进行初步审查
审查并不一定能确认需要获取的元素的class或id,但可以让我们对整个页面有一个了解
因为有些class或id是动态的,所以初步审查有时候并不一定是准确的,如果不准确就会导致我们在抓取的时候出现问题,所以我们还是等后面的BeautifulSoup,lxml解析页面后进行最终确定
初步审查我们可以记录下目标元素的class或id等解析之后看是否相同就可以知道具体情况了
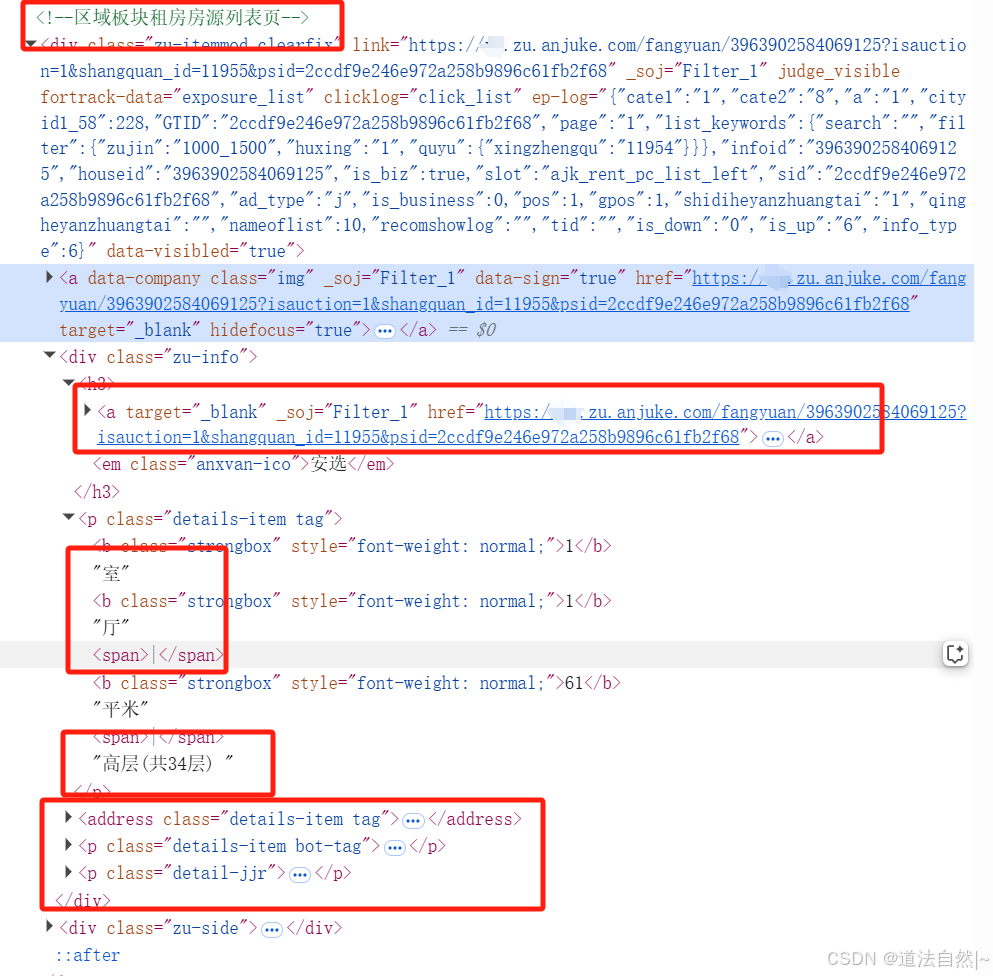
经过审查页面后,可以看到有用的信息非常多,首先每个<div>所代表的就是一栏,然后很多信息都在<div>中的信息中包含了,例如链接、当前页数还有很多其它信息这里不一 一 说了,本次目标信息就在zu-info这个<div>中,分别获取到<a><address><p>这几个元素的内容应该是差不多了
所以进行初步的程序编写
通过初步请求,我们得到了返回状态值为200
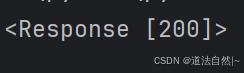
这说明了爬取难度不是很大,因为并没有报出ssl证书错误的问题
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 2382
2382

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









