






C
bool containsDuplicate(int* nums, int numsSize){
for(int i = 0;i<numsSize;i++)
{
for(int j = 0;j<numsSize;j++){
if(i!=j){
if(nums[i]==nums[j])
return true;}
}
}
return false;
}
Java
class Solution {
public boolean containsDuplicate(int[] nums) {
Arrays.sort (nums);//运用sort函数对数组nums进行排序
int n = nums.length;
for(int i = 0;i<n-1;i++){
if(nums[i]==nums[i+1]) {
return true;
}
}
return false;
}
}sort函数使用格式:Arrays.sort(数组名,起始下标,终止下标);
默认升序时格式:Arrays.sort(数组名);
当传入参数的类型是Java中的类:
函数基本格式 int compare (Object o1,Object o2);
此时sort格式:Arrays.sort(数组名,起始下标,终止下标,new cmp());

考查动态规划
需要掌握动态规划问题设计状态的技巧(无后效性),需要知道如何推动转移方程,最后去优化空间。
1)定义状态(定义子问题)——>要具有无后效性
无后效性:
为了保证计算子问题能够按照顺序、不重复地进行,动态规划要求已经求解的子问题不受后续阶段的影响。这个条件也被叫做「无后效性」。换言之,动态规划对状态空间的遍历构成一张有向无环图,遍历就是该有向无环图的一个拓扑序。有向无环图中的节点对应问题中的「状态」,图中的边则对应状态之间的「转移」,转移的选取就是动态规划中的「决策」。
子问题:根据题目第一想到的就是:“经过第i个元素的连续子数组的最大和是多少”。但是这种描述有不确定的地方(有后效性)。不确定i这个数是连续子数组中第几个元素,i的位置多变无法确定。所以我们就固定让i作为连续子数组中最后一个元素。
新子问题:以 −i 结尾的连续子数组的最大和是多少
定义:dp[i]:表示以 nums[i] 结尾 的 连续 子数组的最大和。
2)状态转移方程(描述子问题之间的联系)
根据状态的定义nums[i]一定被选取,并且以 nums[i] 结尾的连续子数组与以 nums[i-1] 结尾的连续子数组只相差一个元素 nums[i] 。
举例找规律:数组[-1,1,2]
子问题 1:以 -1 结尾的连续子数组的最大和是多少;
以 -1 结尾的连续子数组是 [-1],因此最大和就是 -1。
子问题 2:以 1 结尾的连续子数组的最大和是多少;
以 1 结尾的连续子数组是 [-1,1],因此最大和就是 0。
子问题 3:以 2 结尾的连续子数组的最大和是多少;
以 2 结尾的连续子数组是 [-1,1,2],因此最大和就是 2。
说明若子问题i的结果<=0,则i+1的答案就是以nums[i]结尾的数值。
从而如下分类讨论:
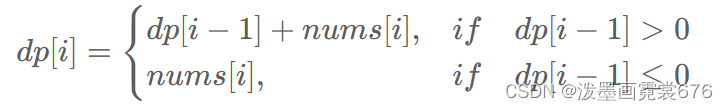
3)思考初始值
dp[0]据定义只有一个数,且一定以nums[0]结尾。
dp[0] = nums[0]
4)思考输出
这里状态的定义不是题目中的问题的定义,不能直接将最后一个状态返回回去
5)优化空间
根据「状态转移方程」,dp[i]的值只和 dp[i - 1] 有关,因此可以使用「滚动变量」的方式将代码进行优化。
C
int maxSubArray(int* nums, int numsSize) {
int pre = 0,maxAns = nums[0];
for(int i = 0;i<numsSize;i++){
pre = fmax(pre + nums[i],nums[i]);
maxAns = fmax(pre,maxAns);
}
return maxAns;
}
Java
class Solution {
public int maxSubArray(int[] nums) {
int pre = 0;
int res = nums[0];
for(int num :nums){
pre = Math.max(pre + num,num);
res = Math.max(pre,res);
}
return res;
}
}Java中for each用法
for each 循环
为了更方便地遍历数组, java 提供了更简单快捷的实现方式,即 for each 循环,演示如下:
int [] nums ={1,2,3,4,5};
for ( int n : nums ){
System . out . println ( n );
}其中 n 表示每一个数组元素本身, for each 循环不能获取数组索引。
Java中Math.max()用法
Math.max(),比较的是两个同一类型数据的大小,取较大的值返回
public int maxSubArray(int[] nums) {
int pre = 0, maxAns = nums[0];
for (int x : nums) {
pre = Math.max(pre + x, x);
maxAns = Math.max(maxAns, pre);
}
return maxAns;
}
}
注意 ,这里面的两个参数如果指向同一个逻辑地址去取相同数据的话,就会报错,原因是源码不允许数据跟它本身相比较(就是说不能比较都是从同一逻辑地址取出来的两个数据),但是不同逻辑地址取出来的两个值相等的数据是可以进行比较的。上面代码中的pre就是先赋值,创建出新的栈空间分配给pre,然后与maxAns从已经存在的逻辑地址空间中取出nums[0]的值,再进行比较,尽管循环的第一步两个变量的值一样,但因为是从不同逻辑地址取出来的数据,就不会报错。否则代码运行会报错。
C语言的比较函数fmax
fmax是C语言(C99)自带的一个函数,用于比较两数大小,返回较大值。返回值为双精度浮点型,同时可用fmaxf,fmaxl
#include<stdio.h>
#include<math.h>
int main()
{
printf("fmax (-100.0, -1.0) = %f\n", fmax(-100.0, -1.0));
return 0;
}同样可以宏定义一个max达到与fmax函数同样的效果:
#include<stdio.h>
#define max(x,y) (x) > (y) ? (x) : (y)
int main()
{
printf("max (-100.0, -1.0) = %f\n", max(-100.0, -1.0));
return 0;
}运行结果与使用fmax函数的结果是一样的。
1.两数之和

Java
暴力枚举
class Solution {
public int[] twoSum(int[] nums, int target) {
for(int i = 0;i < nums.length;i++){
for(int j = i + 1;j<nums.length;j++){
if(nums[i] + nums[j] == target)
return new int[]{i, j};
}
}
return new int[0];
}
}1)Java返回两个变量的方法:return new int[] { i, j };
2)return new int[0];//含义:空数组。
由题意可知 题中有且只有一解 所以根本不可能进行到这一行 返回空数组即可
哈希表方法
class Solution {
public int[] twoSum(int[] nums, int target) {
Map<Integer,Integer>hashtable = new HashMap<Integer,Integer>();
for(int i = 0;i<nums.length;i++){
if(hashtable.containsKey(target - nums[i])){
return new int[] {hashtable.get(target-nums[i]),i};
}
hashtable.put(nums[i],i);
}
return new int[0];
}
}哈希表简述:当遍历到数字 a 时,用 target 减去 a,就会得到 b,若 b 存在于哈希表中,我们就可以直接返回结果了。若 b不存在,那么我们需要将 a 存入哈希表,好让后续遍历的数字使用。
该题哈希表思路:通过一个for循环,判断target-nums[i]是否在hashtable中,如果在,则找到了,返回结果即可,如果不在,则把num[i],和i存储到hashtable中。
注:get用于取得属性的值
Map<Integer, Integer> hashtable = new HashMap<Integer, Integer>();
创建一个Map集合,类型为Integer, Integer,集合名称为hashtable
第一个参数(此为Integer) 是对"键"(关键字Key即哈希表中所需要寻找的数字)的数据类型的限制
第二个参数(此为Integer)是对"值"的数据类型的限制
存储时,键、值类型只能是Integer类型,否则会报错。

java
class Solution {
public void merge(int[] nums1, int m, int[] nums2, int n) {
for (int i = 0; i != n; ++i) {
nums1[m + i] = nums2[i];
}
Arrays.sort(nums1);
}
}
class Solution {
public void merge(int[] nums1, int m, int[] nums2, int n) {
System.arraycopy(nums2,0,nums1,m,n);
Arrays.sort(nums1);
}
}思路:将nums2数组值都赋给nums1数组,扩张了数组1,再用sort函数进行升序排序;或应用System.arraycopy进行拷贝.
System.arraycopy( 原数组, 从原数据的起始位置开始,目标数组,目标数组的开始起始位置, 要copy的数组的长度)
class Solution {
public int[] intersect(int[] nums1, int[] nums2) {
if(nums1.length>nums2.length){
return intersect(nums2,nums1);
}
Map<Integer,Integer> map = new HashMap<Integer,Integer>();
for(int num :nums1){
int count = map.getOrDefault(num,0)+1;
map.put(num,count);
}
int [] intersection = new int[nums1.length];
int index = 0;
for(int num:nums2){
int count = map.getOrDefault(num,0);
if (count > 0){
intersection[index++] = num;
count--;
if(count>0){
map.put(num,count); }
else{
map.remove(num);
}
}
}
return Arrays.copyOfRange(intersection,0,index);
}
}
Map.getOrDefault(Object key, V defaultValue);
如果在Map中存在key,则返回key所对应的的value。
如果在Map中不存在key,则返回默认值。
例如:
map.put(num, map.getOrDefault(num, 0) + 1);
表示:
value默认从1开始,每次操作后num对应的value值加1
可以用来统计数字出现的次数

public class Solution {
public int maxProfit(int[] prices) {
int minprice = Integer.MAX_VALUE;
int maxprofit = 0;
for(int i = 0;i < prices.length;i++){
if(prices[i]<minprice){
minprice = prices[i];
}
else if(prices[i] - minprice>maxprofit){
maxprofit = prices[i]-minprice;
}
}
return maxprofit;
}
}
思路:
一次遍历
算法
假设自己来购买股票。随着时间的推移,每天我们都可以选择出售股票与否。那么,假设在第 i 天,如果我们要在今天卖股票,那么我们能赚多少钱呢?
显然,如果我们真的在买卖股票,我们肯定会想:如果我是在历史最低点买的股票就好了!太好了,在题目中,我们只要用一个变量记录一个历史最低价格 minprice,我们就可以假设自己的股票是在那天买的。那么我们在第 i 天卖出股票能得到的利润就是 prices[i] - minprice。
因此,我们只需要遍历价格数组一遍,记录历史最低点,然后在每一天考虑这么一个问题:如果我是在历史最低点买进的,那么我今天卖出能赚多少钱?当考虑完所有天数之时,我们就得到了最好的答案。


class Solution {
public int[][] matrixReshape(int[][] mat, int r, int c) {
int m = mat.length;
int n = mat[0].length;
if(m*n != r*c){
return mat;
}
int [][] ans = new int [r][c];
for(int x = 0;x<m*n;x++){
ans[x/c][x%c] = mat[x/n][x%n];
}
return ans;
}
}
二维数组的一维表示
思路:对于一个行数为 m,列数为 n,行列下标都从 0 开始编号的二维数组,我们可以通过下面的方式,将其中的每个元素 ( i , j ) 映射到整数域内,并且它们按照行优先的顺序一一对应着 [0,mn)中的每一个整数。形象化地来说,我们把这个二维数组「排扁」成了一个一维数组。此为flatten 操作。
当初疑惑点:n指mat[0].length,表示数组0的长度,通过数字x除以数组的单位长度,从而计算出x压缩为一维数组是的地址位置的行数,x%n:压缩为一维数组的列数。

class Solution {
public List<List<Integer>> generate(int numRows) {
List<List<Integer>> ret = new ArrayList<List<Integer>>();
for (int i = 0; i < numRows; ++i) {
List<Integer> row = new ArrayList<Integer>();
for (int j = 0; j <= i; ++j) {
if (j == 0 || j == i) {
row.add(1);
} else {
row.add(ret.get(i - 1).get(j - 1) + ret.get(i - 1).get(j));
}
}
ret.add(row);
}
return ret;
}
}
思路及解法 数学

ArrayList(顺序表)
//无参构造
List<Integer> list1 = new ArrayList<>();
//利用其它 Collection 构建 ArrayList
List<Integer> list2 = new ArrayList<>(list1);
//指定顺序表初始容量
List<Integer> list3 = new ArrayList<>(10);
Integer 一个整型数据用来存储整数,整数包括正整数,负整数和零。
int 与 integer区别:
1、数据类型不同:int 是基础数据类型,而 Integer 是包装数据类型;
2、默认值不同:int 的默认值是 0,而 Integer 的默认值是 null;
3、内存中存储的方式不同:int 在内存中直接存储的是数据值,而 Integer 实际存储的是对象引用,当 new 一个 Integer 时实际上是生成一个指针指向此对象;
4、实例化方式不同:Integer 必须实例化才可以使用,而 int 不需要;
5、变量的比较方式不同:int 可以使用 == 来对比两个变量是否相等,而 Integer 一定要使用 equals 来比较两个变量是否相等。
36.有效的数独


方法:一次遍历
有效的数独满足以下三个条件:
同一个数字在每一行只能出现一次;
同一个数字在每一列只能出现一次;
同一个数字在每一个小九宫格只能出现一次。
可以使用哈希表记录每一行、每一列和每一个小九宫格中,每个数字出现的次数。只需要遍历数独一次,在遍历的过程中更新哈希表中的计数,并判断是否满足有效的数独的条件即可。
class Solution {
public boolean isValidSudoku(char[][] board) {
int[][] row = new int [9][9];
int[][] column = new int [9][9];
int[][][] jiugongge = new int [3][3][9];
for(int i = 0;i < 9;i++){
for(int j = 0;j < 9;j++){
char c = board [i][j];
if(c != '.'){//只要存在数字
int index = c - '1';//把数字-1化成索引下标,c是字符串要减去字符串,-1会报错。
row[i][index]++;//这个时候++意思是第i行这个c值次数+1,默认row第二位就是{1-9}-1;每一行都有可能是1-9
//例如现在是第一行第一列是9,就在row[1][8]号位置+1
column[index][j]++;
jiugongge[i/3][j/3][index]++;
if(row[i][index] > 1 || column[index][j] > 1|| jiugongge[i/3][j/3][index] > 1) return false;
}
}
}
return true;
}
}

思路:
思路和算法
我们可以用两个标记数组分别记录每一行和每一列是否有零出现。
具体地,我们首先遍历该数组一次,如果某个元素为 ,那么就将该元素所在的行和列所对应标记数组的位置置为 true。最后我们再次遍历该数组,用标记数组更新原数组即可。
可以用矩阵的第一行和第一列代替原思路中的两个标记数组,以达到 O(1) 的额外空间。但这样会导致原数组的第一行和第一列被修改,无法记录它们是否原本包含 0。因此我们需要额外使用两个标记变量分别记录第一行和第一列是否原本包含 0。
因此只使用一个标记变量记录第一列是否原本存在 0。这样,第一列的第一个元素即可以标记第一行是否出现 0。但为了防止每一列的第一个元素被提前更新,我们需要从最后一行开始,倒序地处理矩阵元素。
class Solution {
public void setZeroes(int[][] matrix) {
int m = matrix.length , n = matrix[0].length;
boolean flagCol0 = false;
for(int i = 0;i < m;i++){
if(matrix[i][0] == 0){
flagCol0 = true;
}
for(int j = 1;j < n;j++){
if(matrix[i][j] == 0){
matrix[i][0] = matrix[0][j] = 0;
}
}
}
for(int i = m - 1;i >= 0;i--){
for(int j = 1;j < n;j++){
if(matrix[i][0] == 0||matrix[0][j]==0){
matrix[i][j] = 0;
}
}
if(flagCol0){
matrix[i][0] = 0;
}
}
}
}














 657
657











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









