






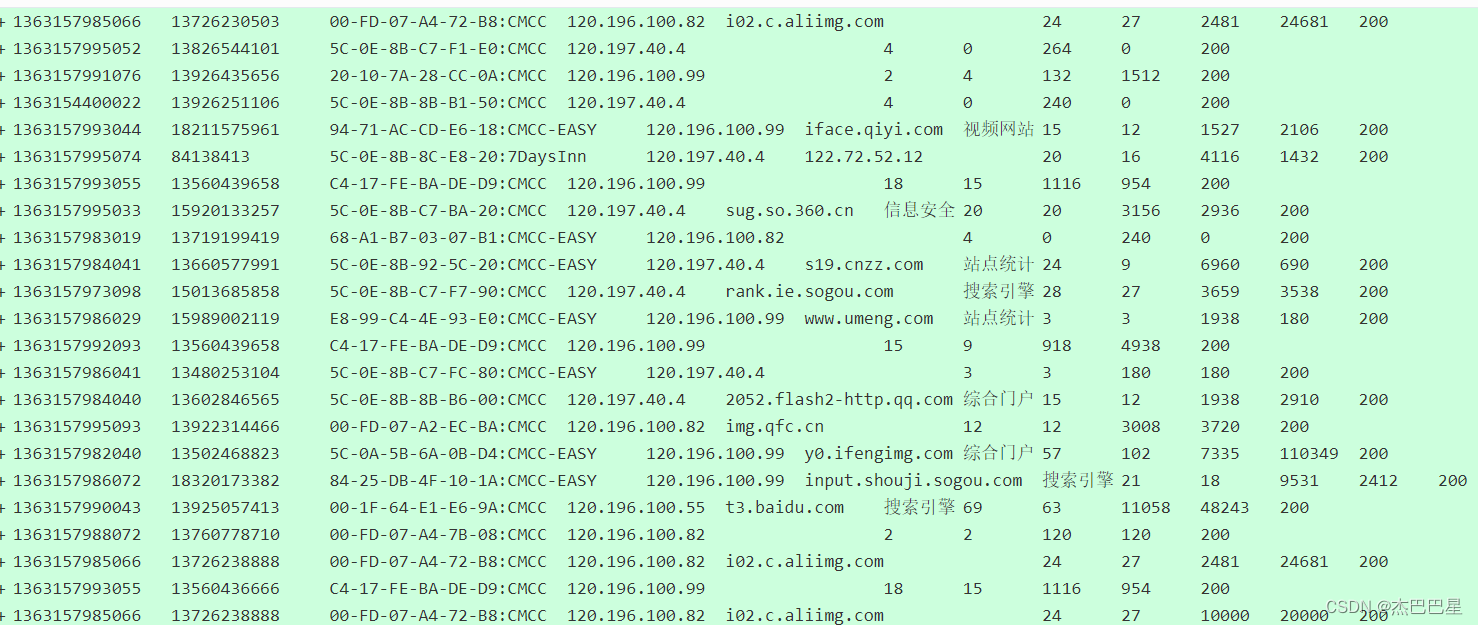
手机流量统计(部分代码)
FlowHDFSApp.java
// An highlighted block
package org.bigdata.wc;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.FileSystem;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
import java.net.URI;
public class FlowHDFSApp {
public static void main(String[] args) throws Exception{
System.setProperty("HADOOP_USER_NAME", "root");
Configuration configuration = new Configuration();
configuration.set("fs.defaultFS","hdfs://192.168.88.104:9000");
// 创建一个Job
Job job = Job.getInstance(configuration);
// 设置Job对应的参数: 主类
job.setJarByClass(FlowHDFSApp.class);
// 设置Job对应的参数: 设置自定义的Mapper和Reducer处理类
job.setMapperClass(WCMapper.class);
job.setReducerClass(WCReducer.class);
// 添加Combiner的设置即可
job.setCombinerClass(WCReducer.class);
// 设置Job对应的参数: Mapper输出key和value的类型
job.setMapOutputKeyClass(Text.class);
job.setMapOutputValueClass(IntWritable.class);
// 设置Job对应的参数: Reduce输出key和value的类型
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(IntWritable.class);
// 如果输出目录已经存在,则先删除
FileSystem fileSystem = FileSystem.get(new URI("hdfs://192.168.10.131:9000"),configuration, "root");
Path outputPath = new Path("/wordcount/output");
if(fileSystem.exists(outputPath)) {
fileSystem.delete(outputPath,true);
}
// 设置Job对应的参数: Mapper输出key和value的类型:作业输入和输出的路径
FileInputFormat.setInputPaths(job, new Path("/wordcount/input"));
FileOutputFormat.setOutputPath(job, outputPath);
// 提交job
boolean result = job.waitForCompletion(true);
System.exit(result ? 0 : -1);
}
}
WCMapper.java
package org.bigdata.wc;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Mapper;
import java.io.IOException;
import java.util.Locale;
/*
KEYIN: Mapper输入的键类型,偏移量(LongWritable)
VALUEIN:Mapper输入的值类型,一行内容,字符串类型(Text)
KEYOUT:Mapper输出的键类型,单词,字符串类型(Text)
VALUEOUT:Mapper输出的值类型,1(IntWritable)
这些类型都实现了Writable接口
*/
public class WCMapper extends Mapper<LongWritable, Text,Text, IntWritable> {
@Override
protected void map(LongWritable key, Text value, Context context) throws IOException, InterruptedException {
String[] words = value.toString().split("\t");
for (String word: words){
context.write(new Text(word.toLowerCase()),new IntWritable(1));
}
}
}
WCReducer.java
package org.bigdata.wc;
import org.apache.hadoop.mapreduce.Reducer;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Reducer;
import java.io.IOException;
/**
11
* Reducer接收到形如:hello==>(1,1,1) 如果存在Combiner,则形如:hello==>(2,3,1)
12
* KEYIN:shuffle输出的key的类型(在本例中是单词字符串类型Text)
13
* VALUEIN:迭代集合中每个元素的类型(在本例中是IntWritable类型)
14
* KEYOUT:Reducer的输出键类型(在本例中是单词字符串类型Text)
15
* VALUEOUT:Reducer的输出值类型(在本例中是每个单词出现的次数,IntWritable类型)
16
*/
public class WCReducer extends Reducer<Text, IntWritable,Text,IntWritable> {
@Override
protected void reduce(Text key, Iterable<IntWritable> values, Context context) throws IOException, InterruptedException {
int count=0;
for(IntWritable value:values){
count += value.get(); // 累加某个单词出现的次数
}
context.write(new Text(key),new IntWritable(count)); // 将Reducer统计的某个单词出现的频率输出
}
}
mapreduce/Access.java
// An highlighted block
package org.mapreduce;
import org.apache.hadoop.io.Writable;
import java.io.DataInput;
import java.io.DataOutput;
import java.io.IOException;
//1实现writable方法
public class Access implements Writable{
private long upflow;
private long downflow;
private long sumflow;
//必须要有空参构造,为了以后反射用
public Access() {
super();
}
public Access(long upflow, long downflow) {
super();
this.upflow = upflow;
this.downflow = downflow;
this.sumflow = upflow+downflow;
}
public void set(long upflow, long downflow) {
this.upflow = upflow;
this.downflow = downflow;
this.sumflow = upflow+downflow;
}
//序列化的方法
@Override
public void write(DataOutput out) throws IOException {
out.writeLong(upflow);
out.writeLong(downflow);
out.writeLong(sumflow);
//反序列化方法
//注意序列化方法和反序列化方法顺序必须保持一致
}
@Override
public void readFields(DataInput in) throws IOException {
this.upflow=in.readLong();
this.downflow=in.readLong();
this.sumflow=in.readLong();
}
@Override
public String toString() {
return upflow + "\t" + downflow + "\t" + sumflow;
}
public void setUpflow(long upflow) {
this.upflow = upflow;
}
public long getUpflow() {
return upflow;
}
public long getDownflow() {
return downflow;
}
public void setDownflow(long downflow) {
this.downflow = downflow;
}
public long getSumflow() {
return sumflow;
}
public void setSumflow(long sumflow) {
this.sumflow = sumflow;
}
}
















 344
344

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









