





一、类型转换
a=input()
print(a.lower()) #全小写
print(a.upper()) #全大写
print(a.title()) #首字母大写
a=int(input())
print(hex(a)) #十进制转换十六进制
print(bin(a)) #十进制转化二进制
print(ord(a)) #字母转数字
str = input()
print(str.isalpha()) #是否只包含字符
print(str.isdigit()) #是否只包含数字
print(str.isspace()) #是否只包含空格
a=float(input())
print(round(a,2)) #保留两位小数
二、列表
list.insert(0,'a') #在list的第一个位置插入a
list.reverse() #将list的元素倒置
a in list1 #查询a是否在list1中
b=[int(i) for i in a] #将列表a中的字符串变成数字
三、字典
operator_dict={'<':'less than','==':'equal'} #设置字典
print('Here is the original dict:')
for x in sorted(operator_dict):
print(f'Operator {x} means {operator_dict[x]}.')
print(" ")
operator_dict['>']='greater than' #添加到字典中
print("The dict was changed to:")
for x in sorted(operator_dict):
print(f'Operator {x} means {operator_dict[x]}.') #operator_dict[x]是输出字典的值
result_dict={'Allen': ['red', 'blue', 'yellow'],'Tom': ['green', 'white', 'blue'],'Andy': ['black', 'pink']}
for i in sorted(result_dict):
print(f"{i}'s favorite colors are:")
for j in result_dict[i]:
print(j)
name=input().split()
langue=input().split()
dict1=zip(name,langue)
print(dict(dict1))
#zip () 函数用于将可迭代的对象作为参数,将对象中对应的元素打包成一个个元组,
#然后返回由这些元组组成的列表.得到列表,将列表转化为字典
dict1 = {
"a": ["apple", "abandon", "ant"],
"b": ["banana", "bee", "become"],
"c": ["cat", "come"],
"d": "down",
}
letter = input()
word = input()
if letter in dict1:
dict1[letter].append(word) #将值word添加到键letter中
print(dict1)
else:
dict1.update({letter: word}) #添加键值对0
print(dict1)
四、类函数
hasattr(object, name) #描述:hasattr() 函数用于判断对象是否包含对应的属性。
#返回值:如果对象有该属性返回 True,否则返回 False。
setattr(object, name, value) #用于设置属性值,该属性不一定是存在的。
object -- 对象。
name -- 字符串,对象属性。
value -- 属性值。
return None
getattr(object, name, [default]) #用于返回一个对象属性值。
object -- 对象。
name -- 字符串,对象属性。
default -- 默认返回值,如果不提供该参数,在没有对应属性时,将触发 AttributeError。
五、爬虫
5.1 re模块
5.1.1正则表达式的写法
什么是正则表达式
正则表达式是可以匹配文本片段的模式。最简单的正则表达式就是普通字符串,可以匹配其自身。换包话说,正则表达式’python’ 可以匹配字符串’python’ 。你可以用这种匹配行为搜索文本中的模式,并且用计算后有值并发特定模式,或都将文本进行分段。
**** 通配符**
正则表达式可以匹配多于一个的字符串,你可以使用一些特殊字符创建这类模式。比如点号(.)可以匹配任何字符。在我们用window 搜索时用问号(?)匹配任意一位字符,作用是一样的。那么这类符号就叫 通配符。
**** 对特殊字符进行转义**
通过上面的方法,假如我们要匹配“python.org”,直接用用‘python.org’可以么?这么做可以,但这样也会匹配“pythonzorg”,这可不是所期望的结果。
好吧!我们需要对它进行转义,可以在它前面加上发斜线。因此,本例中可以使用“python\.org”,这样就只会匹配“python.org”了。
**** 字符集**
我们可以使用中括号([ ])括住字符串来创建字符集。可以使用范围,比如‘[a-z]’能够匹配a到z的任意一个字符,还可以通过一个接一个的方式将范围联合起来使用,比如‘[a-zA-Z0-9]’能够匹配任意大小写字母和数字。
反转字符集,可以在开头使用字符,比如‘[abc]’可以匹配任何除了a、b、c之外的字符。
**** 选择符**
有时候只想匹配字符串’python’ 和 ’perl’ ,可以使用选择项的特殊字符:管道符号(|) 。因此, 所需模式可以写成’python|perl’ 。
**** 子模式**
但是,有些时候不需要对整个模式使用选择符—只是模式的一部分。这时可以使用圆括号起需要的部分,或称子模式。 前例可以写成 ‘p(ython | erl)’
**** 可选项**
在子模式后面加上问号,它就变成了可选项。它可能出现在匹配字符串,但并非必须的。
r’(heep://)?(www.)?python.org’
只能匹配下列字符:
‘http://www.python.org’
‘http://python.org’
‘www.python.org’
‘python.org’
**** 重复子模式**
(pattern)* : 允许模式重复0次或多次
(pattern)+ : 允许模式重复1次或多次
(pattern){m,n} : 允许模式重复m~ n 次
5.1.2 函数
import re
print(result.span()) #返回找到的内容的位置
print(result.group()) #使用group提取到匹配的内容
#从源字符串的起始位置匹配一个模式 若第一位匹配不到 则输出none
#语法:re.match(pattern, string, flag)
#第一个参数代表对应的正则表达式,第二个参数代表对应的源字符,第三个参数是可选参数,代表对应的标志位,可以放模式修正符等信息
import re
string = "ipythonajsoasaoso"
pattern = ".python." #可在末尾加$ 绝对匹配
result = re.match(pattern, string)
result1 = re.match(pattern, string).span()
print("结果1:%s" % result)
print(result1) # (0,8)
#扫描整个字符串进行匹配
#语法:re.search(pattern, string, flag)
import re
string = "helloipythonajsoasaoso"
pattern = ".python."
result1 = re.match(pattern, string)
result2 = re.search(pattern, string)
print("结果1:%s" % result1) #None
print("结果2:%s" % result2) #<re.Match object; span=(5, 13), match='ipythona'>
re.sub(pattern,repl,string,count)
#功能:将匹配到的字符以指定的repl进行替换并且返回替换后的结果
#pattern:正则表达式
#repl:用以替换的内容
#string:被匹配替换的字符串
#count:指定替换次数,若不指定则默认全部替换
re.split(pattern,string,maxsplit,flags)
#功能:以指定的正则表达式对string进行切片,并且将切片后的结果作为列表返回。
#pattern:正则表达式
#string:被匹配的字符串
#maxsplit:指定最大切片次数,若不指定,默认全部切片
#flags:标志位
#将符合模式的全部内容都匹配出来
#(1)使用re.compile()对正则表达式进行预编译
#(2)编译后使用findall()根据正则表达式从原字符串中将匹配的解决全部找出
import re
string = "helloipythonajsoasaospythono"
pattern = re.compile(".python.") #预编译 python左右两边的点是字符串中python两侧的字符
result = pattern.findall(string) #找出符合模式的所有结果
print("结果1:%s" % result) #结果1:['oipythonaj']
六、数据分析
pandas是python的一个数据库,在使用数据库的时候需要输入 import pandas as pd 引入
Series序列 输出类型为Series Series:一维数组,与Numpy中的一维array类似。二者与Python基本的数据结构List也很相近。Series能保存不同种数据类型,字符串、boolean值、数字等都能保存在Series中。
DataFrame数据框 输出类型为DataFrame 二维的表格型数据结构,输出内容与mysql类似,有列名以及行索引。可以将DataFrame理解为Series的容器。
6.1 pd ead_csv的函数用法
| 数据类型 | 说明 | 使用方法 | |
|---|---|---|---|
| 1 | csv, tsv, txt | 可以读取纯文本文件 | pd.read_csv |
| 2 | excel | 可以读取.xls .xlsx 文件 | pd.read_excel |
| 3 | mysql | 读取关系型数据库 | pd.read_sql |
read_csv(
reader: FilePathOrBuffer, *,
sep: str = ...,
delimiter: str | None = ...,
header: int | Sequence[int] | str = ...,
names: Sequence[str] | None = ...,
index_col: int | str | Sequence | Literal[False] | None = ...,
usecols: int | str | Sequence | None = ...,
squeeze: bool = ...,
prefix: str | None = ...,
mangle_dupe_cols: bool = ...,
dtype: str | Mapping[str, Any] | None = ...,
engine: str | None = ...,
converters: Mapping[int | str, (*args, **kwargs) -> Any] | None = ...,
true_values: Sequence[Scalar] | None = ...,
false_values: Sequence[Scalar] | None = ...,
skipinitialspace: bool = ...,
skiprows: Sequence | int | (*args, **kwargs) -> Any | None = ...,
skipfooter: int = ..., nrows: int | None = ..., na_values=...,
keep_default_na: bool = ..., na_filter: bool = ...,
verbose: bool = ..., skip_blank_lines: bool = ...,
parse_dates: bool | List[int] | List[str] = ...,
infer_datetime_format: bool = ...,
keep_date_col: bool = ...,
date_parser: (*args, **kwargs) -> Any | None = ...,
dayfirst: bool = ..., cache_dates: bool = ...,
iterator: Literal[True],
chunksize: int | None = ...,
compression: str | None = ...,
thousands: str | None = ...,
decimal: str | None = ...,
lineterminator: str | None = ...,
quotechar: str = ...,
quoting: int = ...,
doublequote: bool = ...,
escapechar: str | None = ...,
comment: str | None = ...,
encoding: str | None = ...,
dialect: str | None = ...,
error_bad_lines: bool = ...,
warn_bad_lines: bool = ...,
delim_whitespace: bool = ...,
low_memory: bool = ...,
memory_map: bool = ...,
float_precision: str | None = ...)
6.1.1. FilePathOrBuffer
#可以是文件路径,可以是网页上的文件,也可以是文件对象,实例如下:
# 文件路径读取
file_path=r"E:\VSCODE\2_numpy_pandas\pandas\Game_Data.csv"
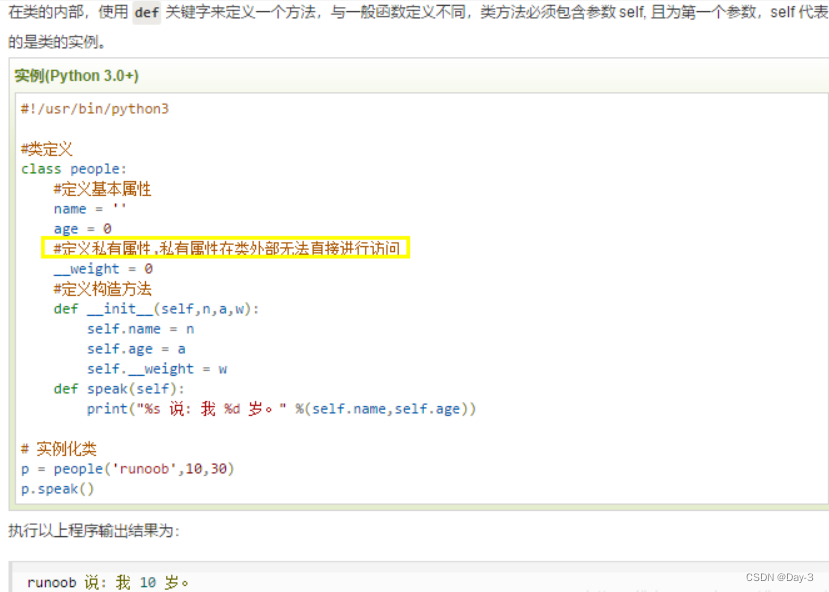
f_df = pd.read_csv(file_path,sep=",|:|;",engine="python",header=0,encoding='gbk')
print(f_df)
# 网页上的文件读取
f_df = pd.read_csv("http://localhost/data.csv")
# 文件对象读取
f = open(r"E:\VSCODE\2_numpy_pandas\pandas\Game_Data.csv", encoding="gbk")
f_df = pd.read_csv(f)
6.1.2. sep
#读取csv文件时指定的分隔符,默认为逗号。
#注意:“csv文件的分隔符” 和 “我们读取csv文件时指定的分隔符” 一定要一致。多个分隔符时,应该使用 | 将不同的分隔符隔开
f_df = pd.read_csv(file_path,sep=":|;",engine="python",header=0)
6.1.3. delim_whitespace(不常用)
#所有的空白字符,都可以用此来作为间隔,该值默认为False, 若我们将其更改为 True 则所有的空白字符:空格,\t, \n 等都会被当做分隔符;和sep功能相似;
6.1.4.header 和 names
#这两个功能相辅相成,header 用来指定列名,例如header =0,则指定第一行为列名;若header =1 则指定第二行为列名;
#有时,我们的数据里没有列名,只有数据,这时候就需要names=[], 来指定列名;详细说明如下:
#1.csv文件有表头并且是第一行,那么names和header都无需指定;
#2.csv文件有表头、但表头不是第一行,可能从下面几行开始才是真正的表头和数据,这个时候指定header即可;
#3.csv文件没有表头,全部是纯数据,那么我们可以通过names手动生成表头;
#4.csv文件有表头、但是这个表头你不想用,这个时候同时指定names和header。先用header选出表头和数据,然后再用names将表头替换掉,其实就等价于将数据读取进来之后再对列名进行rename;
#举例如下 names 没有被赋值,header 也没赋值:
file_path=r"E:\VSCODE\2_numpy_pandas\pandas\Game_Data.csv"
df=pd.read_csv(file_path,sep=",|:|;",engine="python",header=0,encoding='gbk')
print(df)
# 我们说这种情况下,header为变成0,即选取文件的第一行作为表头
这个相当于先不看names,只看header,我们说header等于0代表什么呢?显然是把第一行当做表头,下面的当成数据,好了,然后再把表头用names给替换掉。
6.1.5. index_col
#我们在读取文件之后,生成的 DataFrame 的索引默认是0 1 2 3…,我们当然可以 set_index,但是也可以在读取的时候就指定某个列为索引。
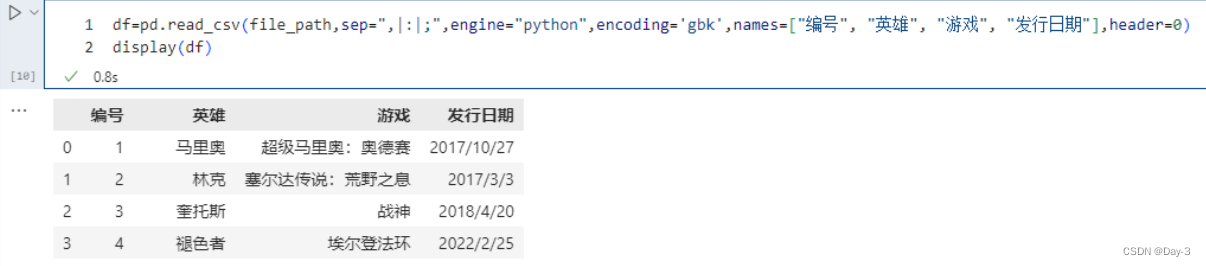
pd.read_csv(file_path,engine="python",encoding='gbk',header=0,index_col="角色")
这里指定 “name” 作为索引,另外除了指定单个列,还可以指定多个列,比如 [“id”, “name”]。并且我们除了可以输入列的名字之外,还可以输入对应的索引。比如:“id”、“name”、“address”、“date” 对应的索引就分别是0、1、2、3。
6.1.6. usecols
#如果列有很多,而我们不想要全部的列、而是只要指定的列就可以使用这个参数。
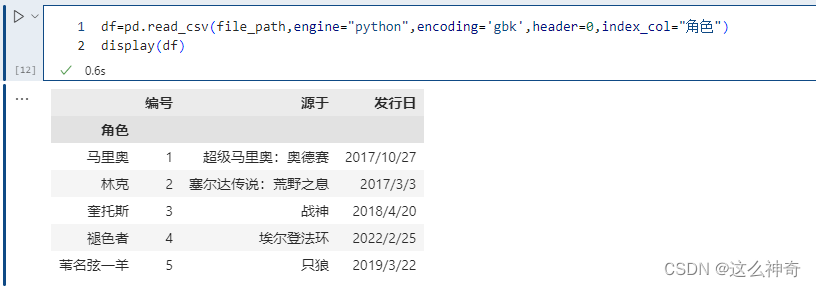
pd.read_csv(file_path,encoding='gbk',usecols=["角色", "发行日"])
#同 index_col 一样,除了指定列名,也可以通过索引来选择想要的列,比如:usecols=[1, 3] 也会选择 “角色” 和 “发行日” 两列,因为 “角色” 这一列对应的索引是 1、“发行日” 对应的索引是 3。
#此外 use_cols 还有一个比较好玩的用法,就是接收一个函数,会依次将列名作为参数传递到函数中进行调用,如果返回值为真,则选择该列,不为真,则不选择。
# 选择列名的长度等于 3 的列,显然此时只会选择 发行日 这一列
pd.read_csv(file_path,encoding='gbk',usecols=lambda x:len(x)==3)
6.1.7. mangle_dupe_cols
实际生产用的数据会很复杂,有时导入的数据会含有重名的列。参数 mangle_dupe_cols 默认为 True,重名的列导入后面多一个 .1。如果设置为 False,会抛出不支持的异常:
# ValueError: Setting mangle_dupe_cols=False is not supported yet
6.1.8. prefix
#prefix 参数,当导入的数据没有 header 时,设置此参数会自动加一个前缀。比如:
在这里插入图片描述
6.1.9. dtype
有时候,工作人员的id都是以0开头的,比如0100012521,这是一个字符串。但是在读取的时候解析成整型了,结果把开头的0给丢了。这个时候我们就可以通过dtype来指定某个列的类型.

6.1.10. engine
pandas解析数据时用的引擎,pandas 目前的解析引擎提供两种:c、python,默认为 c,因为 c 引擎解析速度更快,但是特性没有 python 引擎全。如果使用 c 引擎没有的特性时,会自动退化为 python 引擎。
比如使用分隔符进行解析,如果指定分隔符不是单个字符、或者"\s+“,那么c引擎就无法解析了。我们知道如果分隔符为空白字符的话,那么可以指定delim_whitespace=True,但是也可以指定sep=r”\s+"。
# 我们指定的\s{0}相当于没指定,\s+\s{0}在结果上等同于\s+。
# 但是它不是单个字符,也不是\s+,因此此时的C引擎就无法解决了,而是会退化为python引擎
pd.read_csv(file_path,encoding='gbk',sep=r"\s+\s{0}")
我们看到虽然自动退化,但是弹出了警告,这个时候需要手动的指定engine="python"来避免警告。这里面还用到了encoding参数,这个后面会说,因为引擎一旦退化,在Windows上不指定会读出乱码。这里我们看到sep是可以支持正则的,但是说实话sep这个参数都会设置成单个字符,原因是读取的csv文件的分隔符是单个字符。
6.1.11. converters
可以在读取的时候对列数据进行变换:
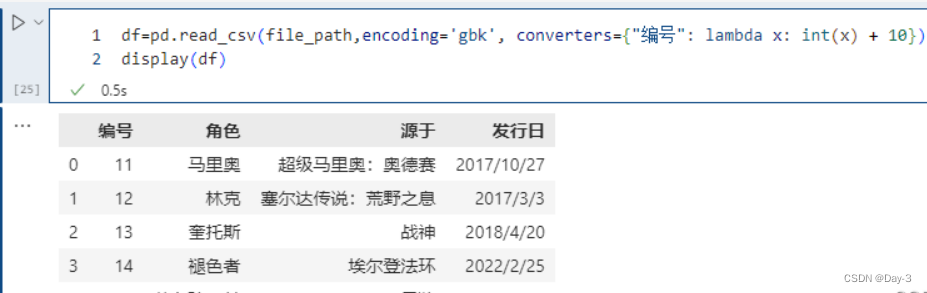
将id增加10,但是注意 int(x),在使用converters参数时,解析器默认所有列的类型为 str,所以需要显式类型转换。
6.1.12. true_values和false_value
指定哪些值应该被清洗为True,哪些值被清洗为False。
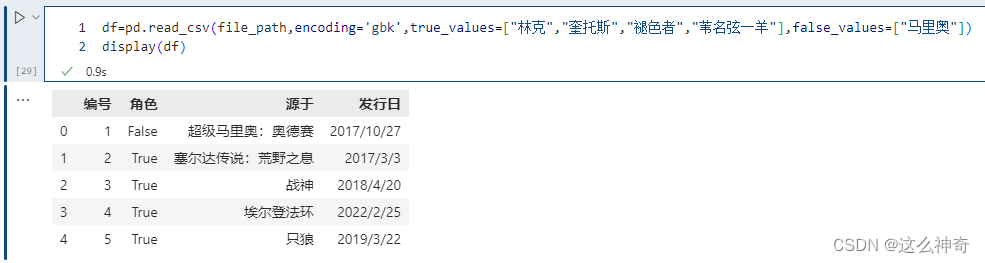
注意这里的替换规则,只有当某一列的数据全部出现在true_values + false_values里面,才会被替换。例如执行以下内容,不会发生变化;
pd.read_csv(file_path,encoding='gbk',true_values=["林克"],false_values=["马里奥"])
这样就不会被替换
6.1.13. skiprows
skiprows 表示过滤行,想过滤掉哪些行,就写在一个列表里面传递给skiprows即可。注意的是:这里是先过滤,然后再确定表头,比如:
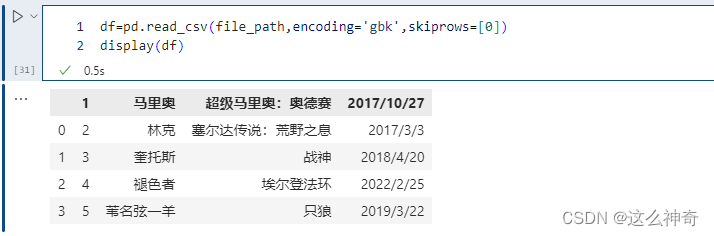
我们把第一行过滤掉了,但是第一行是表头,所以过滤掉之后,第二行就变成表头了。如果过滤掉第二行,那么只相当于少了一行数据,但是表头还是原来的第一行。
当然里面除了传入具体的数值,来表明要过滤掉哪些行,还可以传入一个函数。
由于索引从0开始,凡是索引2等于1的记录都过滤掉。索引大于0,是为了保证表头不被过滤掉。
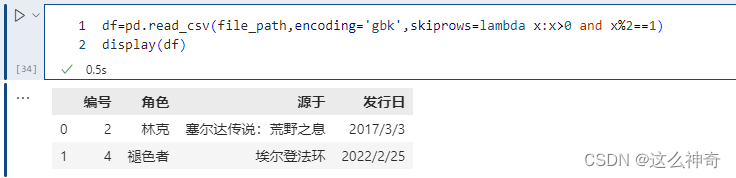
6.1.14. skipfooter
#从文件末尾过滤行,解析引擎退化为 Python。这是因为 C 解析引擎没有这个特性。
pd.read_csv(file_path,encoding='gbk',skipfooter=2)
#如果不想报以上的Warning, 可以将Engine 指定为Python, 如下:
pd.read_csv(file_path,encoding='gbk',skipfooter=2,engine='python')
#skipfooter接收整型,表示从结尾往上过滤掉指定数量的行,因为引擎退化为python,那么要手动指定engine=“python”,不然会警告。
6.1.15. nrows
#nrows 参数设置一次性读入的文件行数,它在读入大文件时很有用,比如 16G 内存的PC无法容纳几百 G 的大文件。
pd.read_csv(file_path,encoding='gbk',nrows=4)
#很多时候我们只是想看看大文件内部的字段长什么样子,所以这里通过nrows指定读取的行数。
6.1.16. na_values
#na_values 参数可以配置哪些值需要处理成 NaN,这个是非常常用的。
pd.read_csv(file_path,encoding='gbk',na_values=['马里奥','战神'])
#我们看到将 ‘马里奥’ 和 ‘战神’ 设置成了NaN,当然我们这里不同的列,里面包含的值都是不相同的。但如果两个列中包含相同的值,而我们只想将其中一个列的值换成NaN该怎么做呢?通过字典实现只对指定的列进行替换。以下的例子可以看到,战神并没有被替换成NaN, 因为在角色里没有这个值
pd.read_csv(file_path,encoding='gbk',na_values={"角色":['马里奥','战神'],'编号':[2]})
6.1.17. keep_default_na
我们知道,通过 na_values 参数可以让 pandas 在读取 CSV 的时候将一些指定的值替换成空值,但除了 na_values 指定的值之外,还有一些默认的值也会在读取的时候被替换成空值,这些值有: “-1.#IND”、“1.#QNAN”、“1.#IND”、“-1.#QNAN”、“#N/A N/A”、“#N/A”、“N/A”、“NA”、“#NA”、“NULL”、“NaN”、“-NaN”、“nan”、“-nan”、“” 。尽管这些值在 CSV 中的表现形式是字符串,但是 pandas 在读取的时候会替换成空值(真正意义上的 NaN)。不过有些时候我们不希望这么做,比如有一个具有业务含义的字符串恰好就叫 “NA”,那么再将它替换成空值就不对了。
这个时候就可以将 keep_default_na 指定为 False,默认为 True,如果指定为 False,那么 pandas 在读取时就不会擅自将那些默认的值转成空值了,它们在 CSV 中长什么样,pandas 读取出来之后就还长什么样,即使单元格中啥也没有,那么得到的也是一个空字符串。但是注意,我们上面介绍的 na_values 参数则不受此影响,也就是说即便 keep_default_na 为 False,na_values 参数指定的值也依旧会被替换成空值。举个栗子,假设某个 CSV 中存在 “NULL”、“NA”、以及空字符串,那么默认情况下,它们都会被替换成空值。但 “NA” 是具有业务含义的,我们希望保留原样,而 “NULL” 和空字符串,我们还是希望 pandas 在读取的时候能够替换成空值,那么此时就可以在指定 keep_default_na 为 False 的同时,再指定 na_values 为 [“NULL”, “”]
6.1.18. na_filter
是否进行空值检测,默认为 True,如果指定为 False,那么 pandas 在读取 CSV 的时候不会进行任何空值的判断和检测,所有的值都会保留原样。因此,如果你能确保一个 CSV 肯定没有空值,则不妨指定 na_filter 为 False,因为避免了空值检测,可以提高大型文件的读取速度。另外,该参数会屏蔽 keep_default_na 和 na_values,也就是说,当 na_filter 为 False 的时候,这两个参数会失效。
从效果上来说,na_filter 为 False 等价于:不指定 na_values、以及将 keep_default_na 设为 False。
6.1.19. skip_blank_lines
skip_blank_lines 默认为 True,表示过滤掉空行,如为 False 则解析为 NaN。
6.1.20. parse_dates
指定某些列为时间类型,这个参数一般搭配下面的date_parser使用。
6.1.21. date_parser
#是用来配合parse_dates参数的,因为有的列虽然是日期,但没办法直接转化,需要我们指定一个解析格式:
from datetime import datetime
pd.read_csv(file_path,encoding='gbk',parse_dates=['发行日'],date_parser=lambda x:datetime.strptime(x,'%Y/%m/%d'))
6.1.22. infer_datetime_format
infer_datetime_format 参数默认为 False。如果设定为 True 并且 parse_dates 可用,那么 pandas 将尝试转换为日期类型,如果可以转换,转换方法并解析,在某些情况下会快 5~10 倍。
6.1.23. iterator
#iterator 为 bool类型,默认为False。如果为True,那么返回一个 TextFileReader 对象,以便逐块处理文件。这个在文件很大、内存无法容纳所有数据文件时,可以分批读入,依次处理。
df=pd.read_csv(file_path,encoding='gbk',iterator=True)
display(df.get_chunk(2))
"""
编号 角色 源于 发行日
0 1 马里奥 超级马里奥:奥德赛 2017/10/27
1 2 林克 塞尔达传说:荒野之息 2017/3/3
"""
print(chunk.get_chunk(1))
"""
编号 角色 源于 发行日
2 3 奎托斯 战神 2018/4/20
"""
# 文件还剩下三行,但是我们指定读取10,那么也不会报错,不够指定的行数,那么有多少返回多少
print(chunk.get_chunk(10))
"""
编号 角色 源于 发行日
3 4 褪色者 埃尔登法环 2022/2/25
4 5 苇名弦一羊 只狼 2019/3/22
"""
try:
# 但是在读取完毕之后,再读的话就会报错了
chunk.get_chunk(5)
except StopIteration as e:
print("读取完毕")
# 读取完毕
6.1.24. chunksize
#chunksize 整型,默认为 None,设置文件块的大小。
chunk = pd.read_csv(file_path, sep="\t", chunksize=2)
# 还是返回一个类似于迭代器的对象
# 调用get_chunk,如果不指定行数,那么就是默认的chunksize
print(chunk.get_chunk())
"""
编号 角色 源于 发行日
0 1 马里奥 超级马里奥:奥德赛 2017/10/27
1 2 林克 塞尔达传说:荒野之息 2017/3/3
"""
# 但也可以指定
print(chunk.get_chunk(100))
"""
编号 角色 源于 发行日
2 3 奎托斯 战神 2018/4/20
3 4 褪色者 埃尔登法环 2022/2/25
4 5 苇名弦一羊 只狼 2019/3/22
"""
try:
chunk.get_chunk(5)
except StopIteration as e:
print("读取完毕")
# 读取完毕
6.1.25. compression
#compression 参数取值为 {‘infer’, ‘gzip’, ‘bz2’, ‘zip’, ‘xz’, None},默认 ‘infer’,这个参数直接支持我们使用磁盘上的压缩文件。
# 直接将上面的.csv添加到压缩文件,打包成game_data.zip
pd.read_csv('game_data.zip', compression="zip",encoding='gbk')
6.1.26. thousands
千分位分割符,如 , 或者 .,默认为None。
6.1.27. encoding
encoding 指定字符集类型,通常指定为 ‘utf-8’。根据情况也可能是’ISO-8859-1’,本文中所有的encoding=‘gbk’ ,主要原因为:我的数据是用Excel 保存成.CSV的,默认的编码格式为GBK;
6.1.28. error_bad_lines和warn_bad_lines
#如果一行包含过多的列,假设csv的数据有5列,但是某一行却有6个数据,显然数据有问题。那么默认情况下不会返回DataFrame,而是会报错。
#我们在某一行中多加了一个数据,结果显示错误。因为girl.csv里面有5列,但是有一行却有6个数据,所以报错。
#在小样本读取时,这个错误很快就能发现。但是如果样本比较大、并且由于数据集不可能那么干净,会很容易出现这种情况,那么该怎么办呢?而且这种情况下,Excel基本上是打不开这么大的文件的。这个时候我们就可以将error_bad_lines设置为False(默认为True),意思是遇到这种情况,直接把这一行给我扔掉。同时会设置 warn_bad_lines 设置为True,打印剔除的这行。
pd.read_csv(file_path,encoding='gbk',error_bad_lines=False, warn_bad_lines=True)
6.2pandas的其他函数
6.2.1数据的查询
import pandas as pd
Nowcoder = pd.read_csv('Nowcoder.csv',sep=',',dtype=object)
print(Nowcoder.head(6))
print(Nowcoder.loc[a])或者 loc[a:b,'aaa']
#df = pd.read_csv('文件路径',分节符):这是利用pandas数据库读取CSV文件的方法,
#如果读取EXCEL文件或者其他文件,csv文件换成其他文件的格式。
#sep=',' 是以逗号为分节符
#df.dtypes:如果在文件中有字符型数据返回object
#df.head(n):表示将前n行数据显示出来,默认是显示前五行
#df.tail(n):表示将后n行数据显示出来,默认后五行
#df.loc[,:] 表示第几行 a,或者从第几行到第几行 a:b中的aaa项
6.2.2数据索引
import pandas as pd
df= pd.read_csv('Nowcoder.csv',sep=',',dtype=object)
print(df[df['Language']=='Python'])
#查询df中language为python的其他数据
print(df.loc[df.index[-5:], ["Nowcoder_ID", "Level", "Achievement_value", "Language"]])
#查询df中后5行中"Nowcoder_ID", "Level", "Achievement_value", "Language"的数据
import pandas as pd
Nowcoder = pd.read_csv('Nowcoder.csv',sep=',')
pd.set_option('display.width', 300) # 设置字符显示宽度
pd.set_option('display.max_rows', None) # 设置显示最大行
pd.set_option('display.max_columns', None) # 设置显示最大列
#想输出全部的数据 就加上这个三段代码
df.set_index([["一","二","三","四","五"]],inplace=True) #添加行的数
#print((Nowcoder['Graduate_year']==2020) & (Nowcoder['Language']=='Java')) #和
#print(Nowcoder.loc[(Nowcoder.Language=='C')|(Nowcoder.Language=='CPP'),:]) #或
# &一定要加括号分隔
print(Nowcoder.query("Graduate_year==2020 & Language=='Java'")) #和
print(Nowcoder.query("Language in ['CPP','C']")) #或
#外面用双引号,里面字符串用单引号
#并集在pandas中不用and,而是用数学运算符& 和 | 来表示与和或,这就是所谓的位运算符。
# Nowcoder.query(" ")可以寻找对应的数据
Nowcoder['Num_of_exercise'] == Nowcoder.Num_of_exercise
6.2.3中级函数
import pandas as pd
df = pd.read_csv("Nowcoder.csv", sep=",")
print(df["Language"].value_counts()) #value_counts默认降序排序,每个语言的数量
value_counts(values,sort=True, ascending=False, normalize=False,bins=None,dropna=True)
#sort=True: 是否要进行排序;默认进行排序
#ascending=False: 默认降序排列;
#normalize=False: 是否要对计算结果进行标准化并显示标准化后的结果,默认是False。
#bins=None: 可以自定义分组区间,默认是否;
#dropna=True:是否删除缺失值nan,默认删除
print(df.isnull().any()) #空值
print(df.dropna(how='any') #去掉信息不全的用户
print(round(df[df["Language"] == "Python"]["Number_of_submissions"].mean(), 1))
#python用户的平均提交次数 mean(,1) 对各列求均值;mean(,0)对各行求均值
print(df["Language"].nunique()) #nunique()去重统计个数
print(df["Language"].unique()) #unique()显示去重列表
print(int(df[df['Num_of_exercise']>=10]['Level'].median())) #等级的中位数
print(df.duplicated(subset=None, keep='first'))#返回true或false
print(df.drop_duplicates()) #删除重复值
a=nowcoder.groupby("date") #将date的内容放在一个“群组”里
print(df.Language.tolist()) #将language的内容以列表呈现出来
print(df.loc[:,['Level']].mode()) #最多的用户等级
#mode函数只能对数据框使用,注意loc第二个参数加[]的数据类型是数据框,不加是series。
print(df[['Num_of_exercise','Number_of_submissions']].quantile(q=0.75)) #四分之三
print(round(Nowcoder['Num_of_exercise'].var(),2)) #刷题量的方差
print(round(Nowcoder['Num_of_exercise'].std(),2)) #提交代码次数的标准差
print(df.duplicated()) #输出每一行是否有重复
print(df.drop_duplicates()) #输出去重后的全部信息
df['Last_submission_time']=pd.to_datetime(df['Last_submission_time'],format='%Y-%m-%d') #统一时间格式
6.2.4fillna函数
#inplace参数的取值:True、False
#True:直接修改原对象
#False:创建一个副本,修改副本,原对象不变(缺省默认)
#method参数的取值 : {‘pad’, ‘ffill’,‘backfill’, ‘bfill’, None}, default None
#pad/ffill:用前一个非缺失值去填充该缺失值
#backfill/bfill:用下一个非缺失值填充该缺失值
#None:指定一个值去替换缺失值(缺省默认这种方式)
#limit参数:限制填充个数
#axis参数:修改填充方向
DataFrame.fillna(value=None, method=None, axis=None, inplace=False, limit=None, downcast=None)
#value 用于填充的值
一、不指定任何参数的填充
df1.fillna(100) #常数填充
df1.fillna({0:10,1:20,2:30}) #字典填充
二、指定inplace参数的填充
df1.fillna(0,inplace=True)
三、指定method参数的填充
df2.fillna(method='ffill') #method = 'ffill'/'pad':用前一个非缺失值去填充该缺失值
df2.fillna(method='bfill') #method = 'bflii'/'backfill':用下一个非缺失值填充该缺失值
四、指定limit参数
df2.fillna(method='bfill', limit=2) #只填充两个
五、指定axis参数
df2.fillna(method="ffill", limit=1, axis=1) #只填充一列
6.2.5json
import pandas as pd
import json
pd.set_option('display.width', 300) #设置字符显示宽度
pd.set_option('display.max_rows', None) #设置显示最大行
pd.set_option('display.max_columns', None)
with open('Nowcoder.json', 'r') as f: #r文件的读操作 w文件的写操作
data = json.loads(f.read()) #加载读取信息赋值给变量
print(pd.DataFrame(data)) #信息转化为数据框
r: 以只读方式打开文件。文件的指针将会放在文件的开头。这是**默认模式**。
rb: 以二进制格式打开一个文件用于只读。文件指针将会放在文件的开头。这是默认模式。
r+: 打开一个文件用于读写。文件指针将会放在文件的开头。
rb+:以二进制格式打开一个文件用于读写。文件指针将会放在文件的开头。
w: 打开一个文件只用于写入。如果该文件已存在则将其覆盖。如果该文件不存在,创建新文件。
wb: 以二进制格式打开一个文件只用于写入。如果该文件已存在则将其覆盖。如果该文件不存在,创建新文件。
w+: 打开一个文件用于读写。如果该文件已存在则将其覆盖。如果该文件不存在,创建新文件。
wb+:以二进制格式打开一个文件用于读写。如果该文件已存在则将其覆盖。如果该文件不存在,创建新文件。
a: 打开一个文件用于追加。如果该文件已存在,文件指针将会放在文件的结尾。也就是说,新的内容将会被写入到已有内容之后。如果该文件不存在,创建新文件进行写入。
ab: 以二进制格式打开一个文件用于追加。如果该文件已存在,文件指针将会放在文件的结尾。也就是说,新的内容将会被写入到已有内容之后。如果该文件不存在,创建新文件进行写入。
a+: 打开一个文件用于读写。如果该文件已存在,文件指针将会放在文件的结尾。文件打开时会是追加模式。如果该文件不存在,创建新文件用于读写。
ab+:以二进制格式打开一个文件用于追加。如果该文件已存在,文件指针将会放在文件的结尾。如果该文件不存在,创建新文件用于读写。
file.read([size]) 将文件数据作为字符串返回,可选参数size控制读取的字节数
file.readlines([size]) 返回文件中行内容的列表,size参数可选
file.write(str) 将字符串写入文件
file.writelines(strings) 将字符串序列写入文件
file.close() 关闭文件
file.closed 表示文件已经被关闭,否则为False
file.mode Access文件打开时使用的访问模式
file.encoding 文件所使用的编码
file.name 文件名
file.newlines 未读取到行分隔符时为None,只有一种行分隔符时为一个字符串,当文件有多种类型的行结束符时,则为一个包含所有当前所遇到的行结束的列表
file.softspace 为0表示在输出一数据后,要加上一个空格符,1表示不加。这个属性一般程序员用不着,由程序内部使用
6.2.6去重函数
DataFrame.drop_duplicates(subset=None, keep='first', inplace=False)
#subset : column label or sequence of labels, optional用来指定特定的列,默认所有列
#keep : {‘first’, ‘last’, False}, default ‘first’删除重复项并保留第一次出现的项
#inplace : boolean, default False是直接在原来数据上修改还是保留一个副本
这个drop_duplicate方法是对DataFrame格式的数据,去除特定列下面的重复行。
返回删除重复行的 DataFrame。 考虑某些列是可选的。索引(包括时间索引)将被忽略。
6.2.7merge函数
pd.merge(df1,df2,left_on='datal',right_index=True,suffixes=('_df1,'_df2))

默认参数how是inner内连接,并且会按照相同的字段key进行合并,即等价于on=‘key’。
当采用outer外连接时,会取并集,并用NaN填充。外连接其实左连接和右连接的并集。左连接是左侧DataFrame取全部数据,右侧DataFrame匹配左侧DataFrame。(右连接right和左连接类似)

6.2.8位置取值
iloc:根据标签的所在位置,从0开始计数,先选取行再选取列
loc:根据DataFrame的具体标签选取行列,同样是先行标签,后列标签
一、当每列已有column name时,用 df [ ‘a’ ] 就能选取出一整列数据。如果你知道column names 和index,且两者都很好输入,可以选择 .loc
二、如果column name太长,输入不方便,或者index是一列时间序列,更不好输入。那就可以选择 .iloc了。
三、.ix 的功能十分强大,它允许我们混合使用下标和名称进行选取。
6.2.9值排名
对于值排名,使用函数df.sort_values(by= , axix=,ascending= , inplace=,na_postion=)。
注意: by参数指定要排序的列,
axis=0表示按照行进行排名,axis=1表示按照列进行排名,默认0;
ascending=True表示升序,ascending=False表示降序,默认True.
**inplace **代表是否要更改原数据,true代表修改原数据。false代表新建副本,在副本修改
**na_position**参数用于设定缺失值的显示位置,first表示缺失值显示在最前面,last表示缺失值显示在最后面
reset_index用来重置索引,因为有时候对dataframe做处理后索引可能是乱的。
drop=True就是把原来的索引index列去掉,重置index。
drop=False就是保留原来的索引,添加重置的index。
6.2.10导出文件
1.导出excel文件
#使用to_excel()函数将dataframe写入到excel文件中,语法如下:
DataFrame.to_excel(excel_writer, sheet_name='Sheet1', na_rep='', float_format=None, columns=None, header=True, index=True, index_label=None, startrow=0, startcol=0, engine=None, merge_cells=True, encoding=None, inf_rep='inf', verbose=True, freeze_panes=None, storage_options=None)
#excel_writer:接收文件路径或现有ExcelWriter对象。
#sheet_name:接收字符串,默认为’Sheet1’。
#na_rep:接收字符串,默认为’'。缺失值表示。
#float_format:接收字符串,浮点数的格式字符串。例如:float_format=“%.2f”。
#columns:接收序列或者字符串列表,需要写入的列。
#header:接收布尔值,或字符串列表,默认为True。写入列名。
#index:接收布尔值,默认为True。是否写入行名。
#index_label:接收字符串或序列。如果需要,可选索引列的列标签。如果未指定,并且 header和index为 True,则使用整数索引。
无返回值。
2.导出csv文件
panda.DataFrame或pandas.Series提供To_csv()方法。
df.to_csv('./data/34/to_csv_out.csv',columns=[],header=False, index=False,sep='',float_format='%.3f')
#path_or_buf:接收字符换或者路径对象,写入保存文件的路径和文件名。
#sep:接收字符串,默认为逗号。
#na_rep:接收字符串,默认为空字符串,空值的表现。
#columns:接收序列,要写入的列。
#header:接收布尔值或者字符串构成的列表,输出的列名。
#index:接收布尔值,默认为True,是否写入行索引。
#index_label:接收字符串或者序列,或者False,默认为None。
#mode:接收字符串,Python写入模式,默认’w’。
#encoding:接收字符串,编码格式,默认’utf-8’。
6.2.题
import pandas as pd
df=pd.read_csv('nowcoder.csv',parse_dates=True,index_col='date')
a=df.groupby('date')['question_id'].count()
print(a)
import pandas as pd
df = pd.read_csv('nowcoder.csv')
df['year-month-day'] = pd.to_datetime(df['date']).dt.date
num = df.groupby(['result','year-month-day'])['year-month-day'].count()
print(num)
import pandas as pd
from datetime import timedelta
nowcoder = pd.read_csv('nowcoder.csv')
#将年月和日分开,因为数据来自同一个月,所以可以直接吧日分开
nowcoder['date1']=pd.to_datetime(nowcoder['date']).dt.strftime('%Y-%m')
nowcoder['date2']=pd.to_datetime(nowcoder['date']).dt.strftime('%d')
nowcoder['date2']=nowcoder['date2'].astype('int')
#可能有重复的日期,去重(一天多个提交记录)
dup=nowcoder[['user_id','date2']].drop_duplicates(['user_id','date2'],inplace=False)
#分组,将数据按照‘user_id’分组
group_df=dup.groupby(['user_id'])
#空列表
l=[]
#建立循环:用户登录日期数少于三个的略过
#登录多于三个的进行判断
#如果索引对应日期和索引-2对应的日期相差2天(满足连续三天)
#将日期加入到列表中
#最后分组索引得到想要的输出结果形式
for a,b in group_df:
if b.date2.count()-3 <0:
continue
else:
for c in range(b.date2.count()):
if b['date2'].iloc[c]==b['date2'].iloc[c-2]+2:
l.append(a)
break
s = nowcoder.groupby('user_id')['question_id'].apply(pd.Series.count)[l] #分组聚合,索引符合条件的用户id
print(s)
import pandas as pd
Nowcoder = pd.read_csv("Nowcoder.csv", sep=",")
print(Nowcoder.groupby("Graduate_year")["Achievement_value"].apply(max))
import pandas as pd
signup = pd.read_csv('signup.csv')
signup1 = pd.read_csv('signup1.csv')
items = pd.read_csv('items.csv')
signup_pro = signup.merge(signup1,how='outer')
new = items.merge(signup_pro,on='item_id',how='left')
print(new.groupby('item_name')['employee_id'].count())
七、Matplotlib
1.1 Figure
在任何绘图之前,我们需要一个Figure对象,可以理解成我们需要一张画板才能开始绘图。
import matplotlib.pyplot as plt
fig = plt.figure()
1.2 Axes
在拥有Figure对象之后,在作画前我们还需要轴,没有轴的话就没有绘图基准,所以需要添加Axes。也可以理解成为真正可以作画的纸。
fig = plt.figure()
ax = fig.add_subplot(111)
ax.set(xlim=[0.5, 4.5], ylim=[-2, 8], title='An Example Axes',
ylabel='Y-Axis', xlabel='X-Axis')
plt.show()
matpltlib.pyplot.figure(
num = None, # 设定figure名称。系统默认按数字升序命名的figure_num(透视表输出窗口)e.g. “figure1”。可自行设定figure名称,名称或是INT,或是str类型;
figsize=None, # 设定figure尺寸。系统默认命令是rcParams["figure.fig.size"] = [6.4, 4.8],即figure长宽为6.4 * 4.8;
dpi=None, # 设定figure像素密度。系统默命令是rcParams["sigure.dpi"] = 100;
facecolor=None, # 设定figure背景色。系统默认命令是rcParams["figure.facecolor"] = 'w',即白色white;
edgecolor=None, frameon=True, # 设定要不要绘制轮廓&轮廓颜色。系统默认绘制轮廓,轮廓染色rcParams["figure.edgecolor"]='w',即白色white;
FigureClass=<class 'matplotlib.figure.Figure'>, # 设定使不使用一个figure模板。系统默认不使用;
clear=False, # 设定当同名figure存在时,是否替换它。系统默认False,即不替换。
**kwargs)
上的代码,在一幅图上添加了一个Axes,然后设置了这个Axes的X轴以及Y轴的取值范围(这些设置并不是强制的,后面会再谈到关于这些设置),效果如下图:
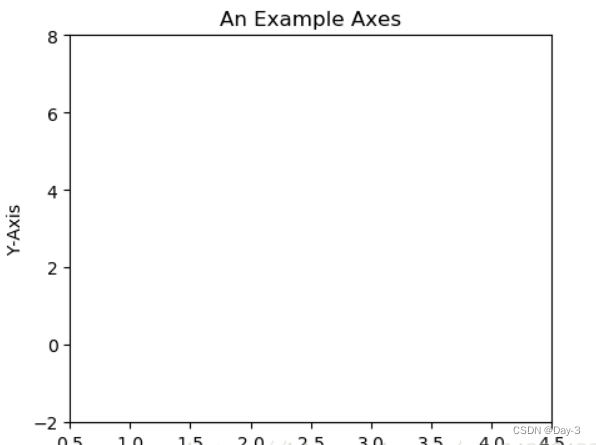
对于上面的fig.add_subplot(111)就是添加Axes的,参数的解释的在画板的第1行第1列的第一个位置生成一个Axes对象来准备作画。也可以通过fig.add_subplot(2, 2, 1)的方式生成Axes,前面两个参数确定了面板的划分,例如 2, 2会将整个面板划分成 2 * 2 的方格,第三个参数取值范围是 [1, 2*2] 表示第几个Axes。如下面的例子:
fig = plt.figure()
ax1 = fig.add_subplot(221)
ax2 = fig.add_subplot(222)
ax3 = fig.add_subplot(224)
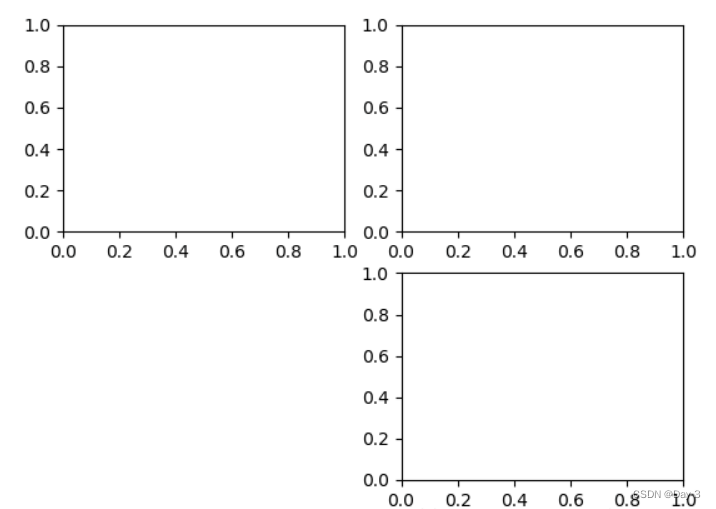
1.3 Multiple Axes
可以发现我们上面添加 Axes 似乎有点弱鸡,所以提供了下面的方式一次性生成所有 Axes:
fig, axes = plt.subplots(nrows=2, ncols=2)
axes[0,0].set(title='Upper Left')
axes[0,1].set(title='Upper Right')
axes[1,0].set(title='Lower Left')
axes[1,1].set(title='Lower Right')
fig 还是我们熟悉的画板, axes 成了我们常用二维数组的形式访问,这在循环绘图时,额外好用。
1.4 Axes Vs .pyplot
相信不少人看过下面的代码,很简单并易懂,但是下面的作画方式只适合简单的绘图,快速的将图绘出。在处理复杂的绘图工作时,我们还是需要使用 Axes 来完成作画的。
plt.plot([1, 2, 3, 4], [10, 20, 25, 30], color='lightblue', linewidth=3)
plt.xlim(0.5, 4.5)
plt.show()
2.1 线
plot()函数画出一系列的点,并且用线将它们连接起来。看下例子:
x = np.linspace(0, np.pi)
y_sin = np.sin(x)
y_cos = np.cos(x)
ax1.plot(x, y_sin)
ax2.plot(x, y_sin, 'go--', linewidth=2, markersize=12)
ax3.plot(x, y_cos, color='red', marker='+', linestyle='dashed')
在上面的三个Axes上作画。plot,前面两个参数为x轴、y轴数据。ax2的第三个参数是 MATLAB风格的绘图,对应ax3上的颜色,marker,线型。
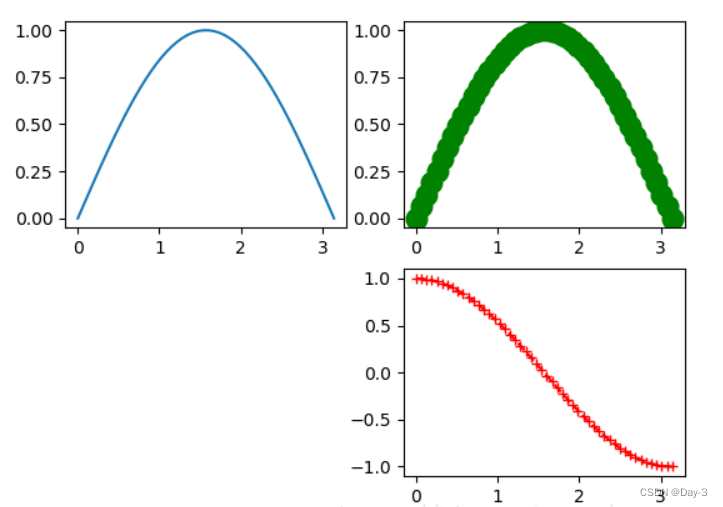
另外,我们可以通过关键字参数的方式绘图,如下例:
x = np.linspace(0, 10, 200)
data_obj = {'x': x,
'y1': 2 * x + 1,
'y2': 3 * x + 1.2,
'mean': 0.5 * x * np.cos(2*x) + 2.5 * x + 1.1}
fig, ax = plt.subplots()
#填充两条线之间的颜色
ax.fill_between('x', 'y1', 'y2', color='yellow', data=data_obj)
# Plot the "centerline" with `plot`
ax.plot('x', 'mean', color='black', data=data_obj)
plt.show()
发现上面的作图,在数据部分只传入了字符串,这些字符串对一个这 data_obj 中的关键字,当以这种方式作画时,将会在传入给 data 中寻找对应关键字的数据来绘图。

2.2 散点图
只画点,但是不用线连接起来。
x = np.arange(10)
y = np.random.randn(10)
plt.scatter(x, y, color='red', marker='+')
plt.show()
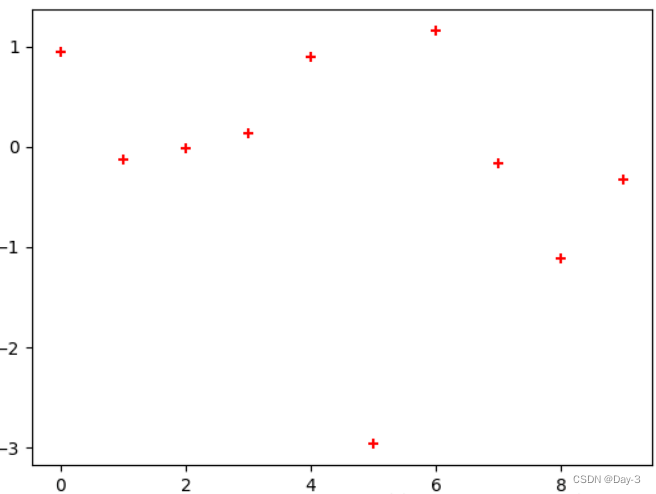
2.3 条形图
条形图分两种,一种是水平的,一种是垂直的,见下例子:
np.random.seed(1)
x = np.arange(5)
y = np.random.randn(5)
fig, axes = plt.subplots(ncols=2, figsize=plt.figaspect(1./2))
vert_bars = axes[0].bar(x, y, color='lightblue', align='center')
horiz_bars = axes[1].barh(x, y, color='lightblue', align='center')
#在水平或者垂直方向上画线
axes[0].axhline(0, color='gray', linewidth=2)
axes[1].axvline(0, color='gray', linewidth=2)
plt.show()
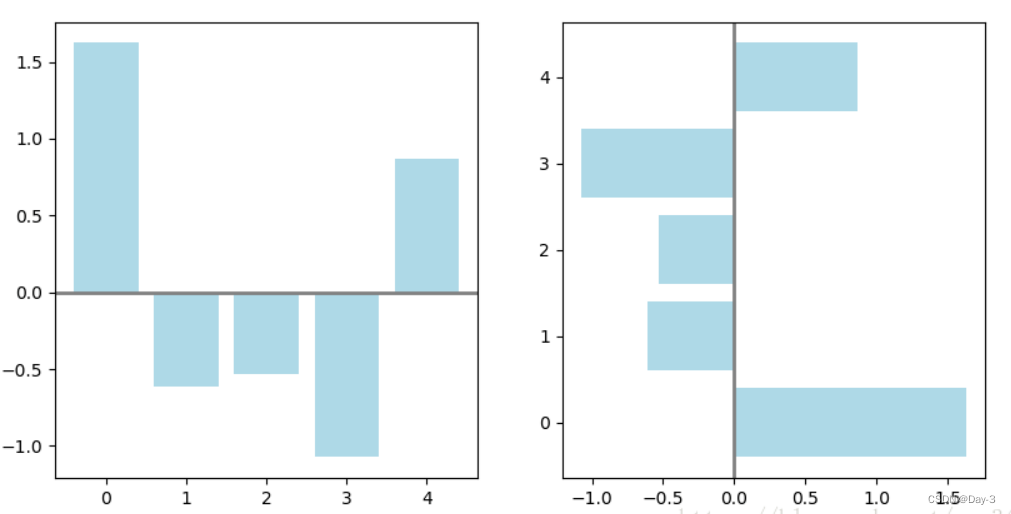
条形图还返回了一个Artists 数组,对应着每个条形,例如上图 Artists 数组的大小为5,我们可以通过这些 Artists 对条形图的样式进行更改,如下例:
fig, ax = plt.subplots()
vert_bars = ax.bar(x, y, color='lightblue', align='center')
# We could have also done this with two separate calls to `ax.bar` and numpy boolean indexing.
for bar, height in zip(vert_bars, y):
if height < 0:
bar.set(edgecolor='darkred', color='salmon', linewidth=3)
plt.show()
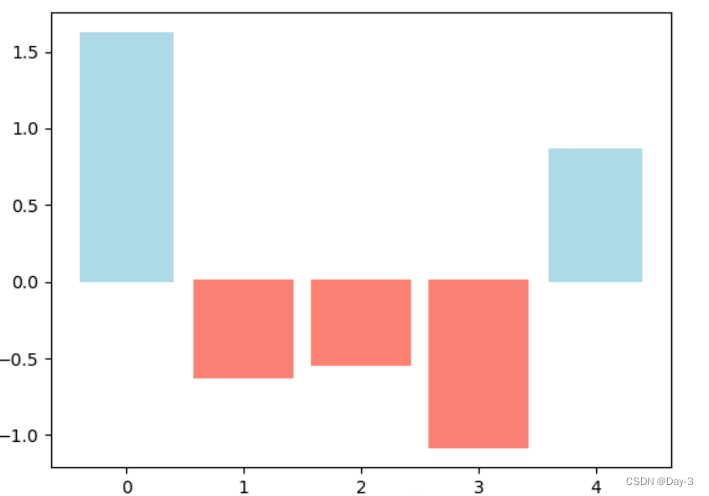
2.4 直方图
直方图用于统计数据出现的次数或者频率,有多种参数可以调整,见下例:
np.random.seed(19680801)
n_bins = 10
x = np.random.randn(1000, 3)
fig, axes = plt.subplots(nrows=2, ncols=2)
ax0, ax1, ax2, ax3 = axes.flatten()
colors = ['red', 'tan', 'lime']
ax0.hist(x, n_bins, density=True, histtype='bar', color=colors, label=colors)
ax0.legend(prop={'size': 10})
ax0.set_title('bars with legend')
ax1.hist(x, n_bins, density=True, histtype='barstacked')
ax1.set_title('stacked bar')
ax2.hist(x, histtype='barstacked', rwidth=0.9)
ax3.hist(x[:, 0], rwidth=0.9)
ax3.set_title('different sample sizes')
fig.tight_layout()
plt.show()
参数中density控制Y轴是概率还是数量,与返回的第一个的变量对应。histtype控制着直方图的样式,默认是 ‘bar’,对于多个条形时就相邻的方式呈现如子图1, ‘barstacked’ 就是叠在一起,如子图2、3。 rwidth 控制着宽度,这样可以空出一些间隙,比较图2、3. 图4是只有一条数据时。
2.5 饼图
labels = 'Frogs', 'Hogs', 'Dogs', 'Logs'
sizes = [15, 30, 45, 10]
explode = (0, 0.1, 0, 0) # only "explode" the 2nd slice (i.e. 'Hogs')
fig1, (ax1, ax2) = plt.subplots(2)
ax1.pie(sizes, labels=labels, autopct='%1.1f%%', shadow=True)
ax1.axis('equal')
ax2.pie(sizes, autopct='%1.2f%%', shadow=True, startangle=90, explode=explode,
pctdistance=1.12)
ax2.axis('equal')
ax2.legend(labels=labels, loc='upper right')
plt.show()
饼图自动根据数据的百分比画饼.。labels是各个块的标签,如子图一。autopct=%1.1f%%表示格式化百分比精确输出,explode,突出某些块,不同的值突出的效果不一样。pctdistance=1.12百分比距离圆心的距离,默认是0.6.
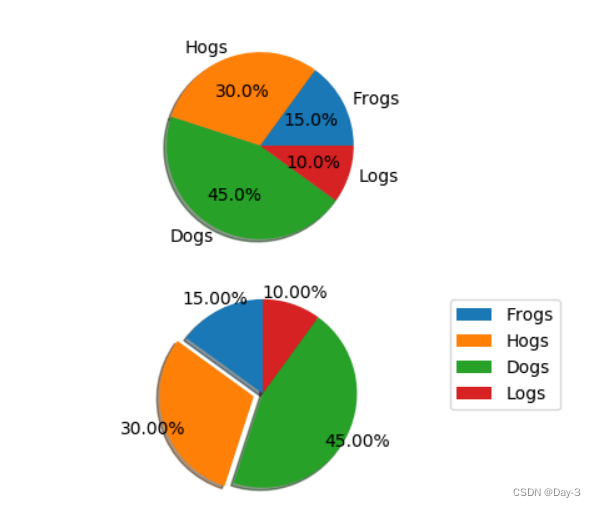
2.6 箱形图
为了专注于如何画图,省去数据的处理部分。 data 的 shape 为 (n, ), data2 的 shape 为 (n, 3)。
fig, (ax1, ax2) = plt.subplots(2)
ax1.boxplot(data)
ax2.boxplot(data2, vert=False) #控制方向
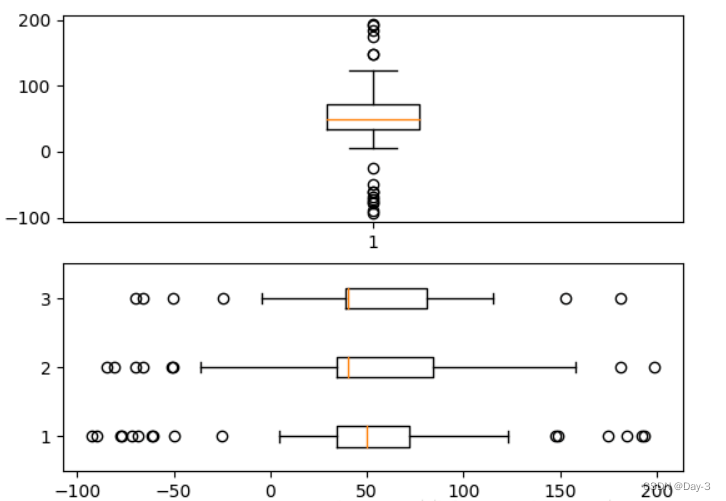
2.7 泡泡图
散点图的一种,加入了第三个值 s 可以理解成普通散点,画的是二维,泡泡图体现了Z的大小,如下例:
np.random.seed(19680801)
N = 50
x = np.random.rand(N)
y = np.random.rand(N)
colors = np.random.rand(N)
area = (30 * np.random.rand(N))**2 # 0 to 15 point radii
plt.scatter(x, y, s=area, c=colors, alpha=0.5)
plt.show()
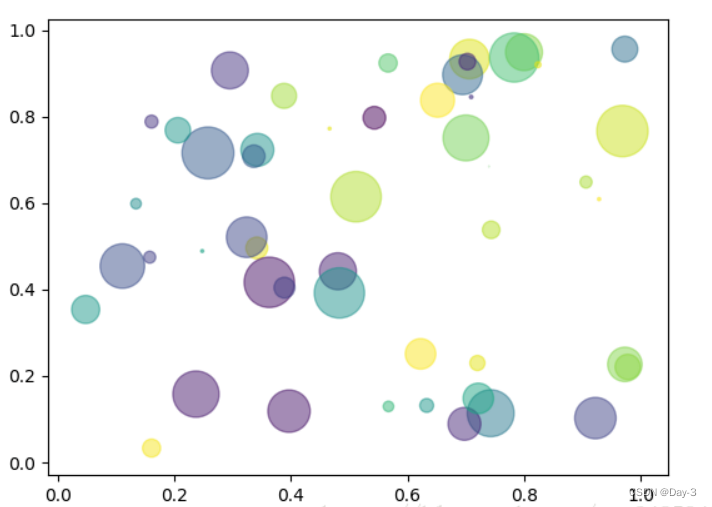
2.8 等高线(轮廓图)
有时候需要描绘边界的时候,就会用到轮廓图,机器学习用的决策边界也常用轮廓图来绘画,见下例:
fig, (ax1, ax2) = plt.subplots(2)
x = np.arange(-5, 5, 0.1)
y = np.arange(-5, 5, 0.1)
xx, yy = np.meshgrid(x, y, sparse=True)
z = np.sin(xx**2 + yy**2) / (xx**2 + yy**2)
ax1.contourf(x, y, z)
ax2.contour(x, y, z)
上面画了两个一样的轮廓图,contourf会填充轮廓线之间的颜色。数据x, y, z通常是具有相同 shape 的二维矩阵。x, y 可以为一维向量,但是必需有 z.shape = (y.n, x.n) ,这里 y.n 和 x.n 分别表示x、y的长度。Z通常表示的是距离X-Y平面的距离,传入X、Y则是控制了绘制等高线的范围。
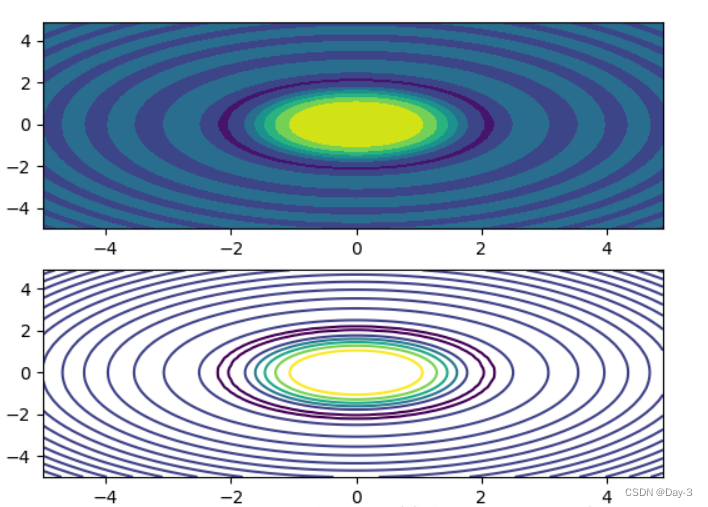
3.1区间上下限
当绘画完成后,会发现X、Y轴的区间是会自动调整的,并不是跟我们传入的X、Y轴数据中的最值相同。为了调整区间我们使用下面的方式:
ax.set_xlim([xmin, xmax]) #设置X轴的区间
ax.set_ylim([ymin, ymax]) #Y轴区间
ax.axis([xmin, xmax, ymin, ymax]) #X、Y轴区间
ax.set_ylim(bottom=-10) #Y轴下限
ax.set_xlim(right=25) #X轴上限
具体效果见下例:
x = np.linspace(0, 2*np.pi)
y = np.sin(x)
fig, (ax1, ax2) = plt.subplots(2)
ax1.plot(x, y)
ax2.plot(x, y)
ax2.set_xlim([-1, 6])
ax2.set_ylim([-1, 3])
plt.show()
可以看出修改了区间之后影响了图片显示的效果。
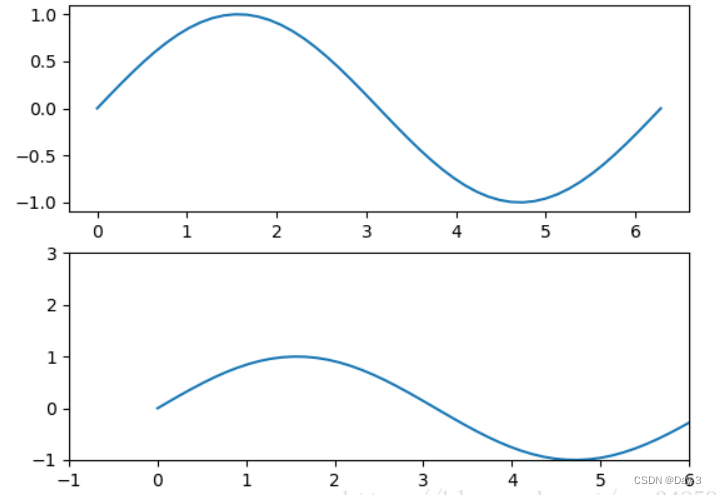
3.2 图例说明
我们如果我们在一个Axes上做多次绘画,那么可能出现分不清哪条线或点所代表的意思。这个时间添加图例说明,就可以解决这个问题了,见下例:
fig, ax = plt.subplots()
ax.plot([1, 2, 3, 4], [10, 20, 25, 30], label='Philadelphia')
ax.plot([1, 2, 3, 4], [30, 23, 13, 4], label='Boston')
ax.scatter([1, 2, 3, 4], [20, 10, 30, 15], label='Point')
ax.set(ylabel='Temperature (deg C)', xlabel='Time', title='A tale of two cities')
ax.legend()
plt.show()
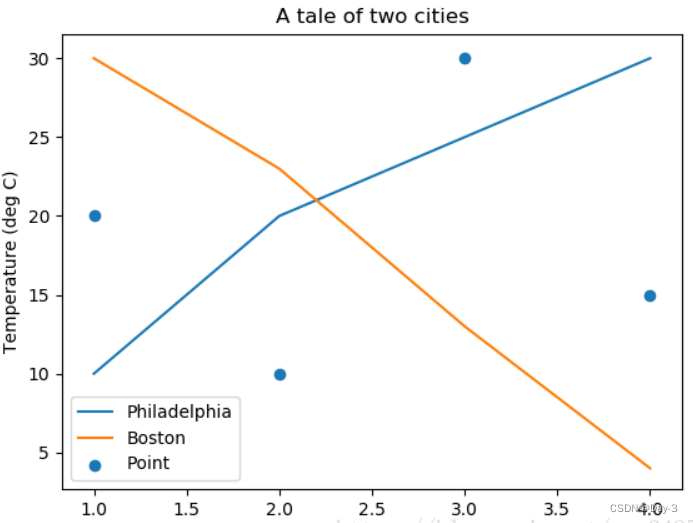
在绘图时传入 label 参数,并最后调用ax.legend()显示体力说明,对于 legend 还是传入参数,控制图例说明显示的位置:
3.3 区间分段
默认情况下,绘图结束之后,Axes 会自动的控制区间的分段。见下例:
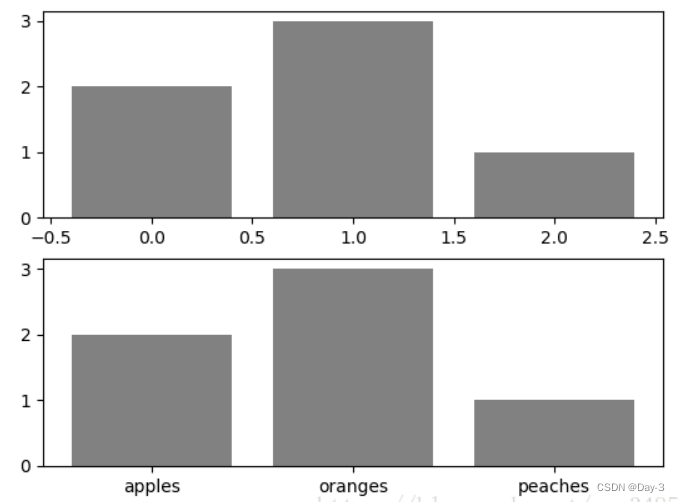
data = [('apples', 2), ('oranges', 3), ('peaches', 1)]
fruit, value = zip(*data)
fig, (ax1, ax2) = plt.subplots(2)
x = np.arange(len(fruit))
ax1.bar(x, value, align='center', color='gray')
ax2.bar(x, value, align='center', color='gray')
ax2.set(xticks=x, xticklabels=fruit)
#ax.tick_params(axis='y', direction='inout', length=10) #修改 ticks 的方向以及长度
plt.show()
上面不仅修改了X轴的区间段,并且修改了显示的信息为文本。
3.4 布局
当我们绘画多个子图时,就会有一些美观的问题存在,例如子图之间的间隔,子图与画板的外边间距以及子图的内边距,下面说明这个问题:
fig, axes = plt.subplots(2, 2, figsize=(9, 9))
fig.subplots_adjust(wspace=0.5, hspace=0.3,
left=0.125, right=0.9,
top=0.9, bottom=0.1)
#fig.tight_layout() #自动调整布局,使标题之间不重叠
plt.show()
通过fig.subplots_adjust()我们修改了子图水平之间的间隔wspace=0.5,垂直方向上的间距hspace=0.3,左边距left=0.125 等等,这里数值都是百分比的。以 [0, 1] 为区间,选择left、right、bottom、top 注意 top 和 right 是 0.9 表示上、右边距为百分之10。不确定如果调整的时候,fig.tight_layout()是一个很好的选择。之前说到了内边距,内边距是子图的,也就是 Axes 对象,所以这样使用 ax.margins(x=0.1, y=0.1),当值传入一个值时,表示同时修改水平和垂直方向的内边距。
观察上面的四个子图,可以发现他们的X、Y的区间是一致的,而且这样显示并不美观,所以可以调整使他们使用一样的X、Y轴:
fig, (ax1, ax2) = plt.subplots(1, 2, sharex=True, sharey=True)
ax1.plot([1, 2, 3, 4], [1, 2, 3, 4])
ax2.plot([3, 4, 5, 6], [6, 5, 4, 3])
plt.show()
3.5 轴相关
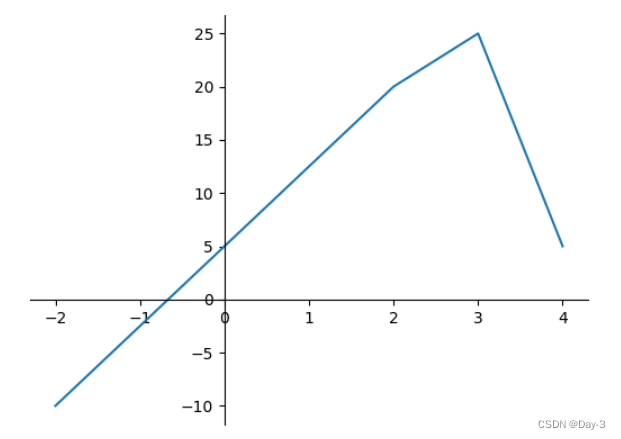
改变边界的位置,去掉四周的边框:
fig, ax = plt.subplots()
ax.plot([-2, 2, 3, 4], [-10, 20, 25, 5])
ax.spines['top'].set_visible(False) #顶边界不可见
ax.xaxis.set_ticks_position('bottom') # ticks 的位置为下方,分上下的。
ax.spines['right'].set_visible(False) #右边界不可见
ax.yaxis.set_ticks_position('left')
# "outward"
# 移动左、下边界离 Axes 10 个距离
#ax.spines['bottom'].set_position(('outward', 10))
#ax.spines['left'].set_position(('outward', 10))
# "data"
# 移动左、下边界到 (0, 0) 处相交
ax.spines['bottom'].set_position(('data', 0))
ax.spines['left'].set_position(('data', 0))
# "axes"
# 移动边界,按 Axes 的百分比位置
#ax.spines['bottom'].set_position(('axes', 0.75))
#ax.spines['left'].set_position(('axes', 0.3))
plt.show()
八、Numpy
NumPy 是一个 Python 包。 它代表 “Numeric Python”。 它是一个由多维数组对象和用于处理数组的例程集合组成的库。
使用NumPy,开发人员可以执行以下操作:
- 数组的算数和逻辑运算。
- 傅立叶变换和用于图形操作的例程。
- 与线性代数有关的操作。 NumPy 拥有线性代数和随机数生成的内置函数。
np.newaxis
np.newaxis 的功能是增加新的维度,但是要注意 np.newaxis 放的位置不同,产生的矩阵形状也不同。
np.newaxis 放在哪个位置,就会给哪个位置增加维度
x[:, np.newaxis] ,放在后面,会给列上增加维度
x[np.newaxis, :] ,放在前面,会给行上增加维度
用途: 通常用它将一维的数据转换成一个矩阵,这样就可以与其他矩阵进行相乘。
numpy.array(object, dtype = None, copy = True, order = None, subok = False, ndmin = 0)
序号 参数及描述
1. object 任何暴露数组接口方法的对象都会返回一个数组或任何(嵌套)序列。
2. dtype 数组的所需数据类型,可选。
3. copy 可选,默认为true,对象是否被复制。
4. order C(按行)、F(按列)或A(任意,默认)。
5. subok 默认情况下,返回的数组被强制为基类数组。 如果为true,则返回子类。
6. ndmin 指定返回数组的最小维数。
8.1数据类型
| 序号 | 数据类型及描述 |
|---|---|
| 1. | bool_ 存储为一个字节的布尔值(真或假) |
| 2. | int_ 默认整数,相当于 C 的long,通常为int32或int64 |
| 3. | intc 相当于 C 的int,通常为int32或int64 |
| 4. | intp 用于索引的整数,相当于 C 的size_t,通常为int32或int64 |
| 5. | int8 字节(-128 ~ 127) |
| 6. | int16 16 位整数(-32768 ~ 32767) |
| 7. | int32 32 位整数(-2147483648 ~ 2147483647) |
| 8. | int64 64 位整数(-9223372036854775808 ~ 9223372036854775807) |
| 9. | uint8 8 位无符号整数(0 ~ 255) |
| 10. | uint16 16 位无符号整数(0 ~ 65535) |
| 11. | uint32 32 位无符号整数(0 ~ 4294967295) |
| 12. | uint64 64 位无符号整数(0 ~ 18446744073709551615) |
| 13. | float_ float64的简写 |
| 14. | float16 半精度浮点:符号位,5 位指数,10 位尾数 |
| 15. | float32 单精度浮点:符号位,8 位指数,23 位尾数 |
| 16. | float64 双精度浮点:符号位,11 位指数,52 位尾数 |
| 17. | complex_ complex128的简写 |
| 18. | complex64 复数,由两个 32 位浮点表示(实部和虚部) |
| 19. | complex128 复数,由两个 64 位浮点表示(实部和虚部) |
8.2数据类型对象 (dtype)
数据类型对象描述了对应于数组的固定内存块的解释,取决于以下方面:
- 数据类型(整数、浮点或者 Python 对象)
- 数据大小
- 字节序(小端或大端)
- 在结构化类型的情况下,字段的名称,每个字段的数据类型,和每个字段占用的内存块部分。
- 如果数据类型是子序列,它的形状和数据类型。
字节顺序取决于数据类型的前缀<或>。 <意味着编码是小端(最小有效字节存储在最小地址中)。 >意味着编码是大端(最大有效字节存储在最小地址中)。
numpy.dtype(object, align, copy)
Object:被转换为数据类型的对象。
Align:如果为true,则向字段添加间隔,使其类似 C 的结构体。
Copy :生成dtype对象的新副本,如果为flase,结果是内建数据类型对象的引用。
以下示例定义名为 student 的结构化数据类型,其中包含字符串字段name,整数字段age和浮点字段marks。
此dtype应用于ndarray对象。
import numpy as np
student = np.dtype([('name','S20'), ('age', 'i1'), ('marks', 'f4')])
a = np.array([('abc', 21, 50),('xyz', 18, 75)], dtype = student)
print a
输出 [('abc', 21, 50.0), ('xyz', 18, 75.0)]
每个内建类型都有一个唯一定义它的字符代码:
- ‘b’:布尔值
- ‘i’:符号整数
- ‘u’:无符号整数
- ‘f’:浮点
- ‘c’:复数浮点
- ‘m’:时间间隔
- ‘M’:日期时间
- ‘O’:Python 对象
- ‘S’, ‘a’:字节串
- ‘U’:Unicode
- ‘V’:原始数据(void)
8.3数组属性
ndarray.shape
这一数组属性返回一个包含数组维度的元组,它也可以用于调整数组大小。
NumPy 也提供了reshape函数来调整数组大小。
ndarray.ndim
这一数组属性返回数组的维数。
numpy.itemsize
这一数组属性返回数组中每个元素的字节单位长度。
numpy.flags
ndarray对象拥有以下属性。这个函数返回了它们的当前值。
| 序号 | 属性及描述 |
|---|---|
| 1. | C_CONTIGUOUS © 数组位于单一的、C 风格的连续区段内 |
| 2. | F_CONTIGUOUS (F) 数组位于单一的、Fortran 风格的连续区段内 |
| 3. | OWNDATA (O) 数组的内存从其它对象处借用 |
| 4. | WRITEABLE (W) 数据区域可写入。 将它设置为flase会锁定数据,使其只读 |
| 5. | ALIGNED (A) 数据和任何元素会为硬件适当对齐 |
| 6. | UPDATEIFCOPY (U) 这个数组是另一数组的副本。当这个数组释放时,源数组会由这个数组中的元素更新 |
数组创建例程
numpy.empty
它创建指定形状和dtype的未初始化数组。 它使用以下构造函数:
numpy.empty(shape, dtype = float, order = 'C')
序号 参数及描述
1. Shape 空数组的形状,整数或整数元组
2. Dtype 所需的输出数组类型,可选
3. Order 'C'为按行的 C 风格数组,'F'为按列的 Fortran 风格数组
numpy.zeros
返回特定大小,以 0 填充的新数组。
numpy.zeros(shape, dtype = float, order = 'C')
序号 参数及描述
1. Shape 空数组的形状,整数或整数元组
2. Dtype 所需的输出数组类型,可选
3. Order 'C'为按行的 C 风格数组,'F'为按列的 Fortran 风格数组
numpy.ones
返回特定大小,以 1 填充的新数组。
来自现有数据的数组
这一章中,我们会讨论如何从现有数据创建数组。
numpy.asarray
此函数类似于numpy.array,除了它有较少的参数。 这个例程对于将 Python 序列转换为ndarray非常有用。
numpy.asarray(a, dtype = None, order = None)
序号 参数及描述
1. a 任意形式的输入参数,比如列表、列表的元组、元组、元组的元组、元组的列表
2. dtype 通常,输入数据的类型会应用到返回的ndarray
3. order 'C'为按行的 C 风格数组,'F'为按列的 Fortran 风格数组
numpy.frombuffer
此函数将缓冲区解释为一维数组。 暴露缓冲区接口的任何对象都用作参数来返回ndarray
numpy.frombuffer(buffer, dtype = float, count = -1, offset = 0)
九、Sklearn
9.1决策树
9.1.1tree.DecisionTreeClassifier
八个参数:Criterion,两个随机性相关的参数(random_state,splitter),五个剪枝参数(max_depth,
min_samples_split,min_samples_leaf,max_feature,min_impurity_decrease)
一个属性:feature_importances_
四个接口:fit,score,apply,predict
、杂谈
i = 0
j = 12
try:
n = j/i
except ZeroDivisionError as e:
print("except:",e)
i = 1
n = j/i
except ValueError as value_err: #可以写多个捕获异常
print("ValueError")
finally:
print("final print")
#输出结果为:
except: division by zero
final print
12.0
#如果实在不知道是什么错误类型,或者想偷懒也可以捕获所有的错误类型:
except Exception as e:
print("except:",e)
总结:
1,try...except...finally,可能出错的代码写在try后,对错误的处理写在except后
2,无论是否发生了异常,只要提供了finally语句,以上try/except/else/finally代码块执行的最后一步总是执行finally所对应的代码块。
3,except 可以监听多个错误类型,也可以写多个except对不同的错类型分开处理;
4,如果不知道什么错误类型,可以写Exception来监听所有错误类型
map(int,a) #将a的类型变成int
for i in range(3) : #循环三次
for i in arr :
print(i,end=' ') #末尾不换行且加空格(若arr中为3,3,3,3;则输出3333)
if bool(a) :
print(a) #a是否为布尔值,若是则输出a
print(list1[0], list1[-1]) #print输出两个时要用逗号隔开
ls1 = list(input()) #输入的字符串变成一个个的单词
print(input().replace('a','ab')) #将a更换为ab
def fun(n):
if n==1:
return 2
elif n==2:
return 3
else:
return fun(n-1)+fun(n-2)
i=int(input())
print(fun(i))
import pandas as pd
df=pd.read_csv('Nowcoder.csv',sep=',')
a=len(df) #行
b = len(df.columns) #列
print((a,b))
#lambda函数是匿名的:所谓匿名函数,通俗地说就是没有名字的函数。lambda函数没有名字。
#lambda函数有输入和输出:输入是传入到参数列表argument_list的值,输出是根据表达式expression计算得到的值。
#lambda函数一般功能简单:单行expression决定了lambda函数不可能完成复杂的逻辑,只能完成非常简单的功能。由于其实现的功能一目了然,甚至不需要专门的名字来说明
#下面是一些lambda函数示例:
lambda x, y: x*y #函数输入是x和y,输出是它们的积x*y
lambda:None #函数没有输入参数,输出是None
lambda *args: sum(args) #输入是任意个数的参数,输出是它们的和(隐性要求是输入参数必须能够进行加法运算)
lambda **kwargs: 1 #输入是任意键值对参数,输出是1
时间处理模块
1、datetime模块
datatime模块是在time模块的基础之上做了封装,提供了更多更好用的类供我们使用,常用的有date、time、datetime、timedelta、tzinfo。但是为了更灵活的处理时间,最好是将time模块和datetime模块中的精髓学习到。
import datetime form
① date类:主要用于处理年、月、日;
② time类:主要用于处理时、分、秒;
③ datetime类:date类和time类的综合使用,可以处理年、月、日、时、分、秒;
④ timedelta类:主要用于做时间加减的;
⑤ tzinfo类:时区类;
注意:tzinfo类用的不多,也就不专门讲述了,如果有需要,可以自行学习。
1.1.timedelta类
使用timedelta可以很方便的在日期上做天days,小时hour,分钟minute,秒second,毫秒millisecond,微妙的时间计算microsecond。如果要进行年、月的加减,则需要另外的办法。
但是这个类的使用,一定要结合date类的对象 或 datetime类的对象使用。也就是说,一定是基于这两个类的对象,进行时间的加、减。
注意:timedelta不能单独和time类的对象结合使用,这个下面会做演示。
1)案例说明:分别创建date类、datetime类的对象,然后进行时间的加减;
① 分别创建date类、datetime这两个类的对象;
from datetime import *
d = date(2012,12,12)
display(d)
dt = datetime(2012,12,12,23,59,59)
display(dt)
#datetime.date(2012, 12, 12)
#datetime.datetime(2012, 12, 12, 23, 59, 59)
② 利用date类的对象,配合timedelta,进行时间的加减;
date类主要是用于处理年、月、日的,因此对该对象进行时间的加、减,主要是做“日(天数)”的加减。
from datetime import *
d = date(2012,12,12)
display(d)
# 昨天
d1 = d + timedelta(days=-1)
display(d1)
# 明天
d2 = d + timedelta(days=1)
display(d2)
#datetime.date(2012, 12, 12)
#datetime.date(2012, 12, 11)
#datetime.date(2012, 12, 13)
③ 利用datetime类的对象,配合timedelta,进行时间的加减;
datetime类主要是用于处理年、月、日、时、分、秒、毫秒、微妙的,因此对该对象进行时间的加、减,主要做“日(天数)”、“时”、“分”、“秒”、“毫秒”、“微秒”、的加减。
from datetime import *
dt = datetime(2012,12,12,23,59,59)
display(dt)
# 昨天
dt1 = dt + timedelta(days=-1)
display(dt1)
# 明天
dt2 = dt + timedelta(days=1)
display(dt2)
# 上一个小时
dt3 = dt + timedelta(hours=-1)
display(dt3)
# 下一个小时
dt4 = dt + timedelta(hours=1)
display(dt4)
# 上一秒
dt5 = dt + timedelta(seconds=-1)
display(dt5)
# 下一秒
dt6 = dt + timedelta(seconds=1)
display(dt6)
#datetime.datetime(2012, 12, 12, 23, 59, 59)
#datetime.datetime(2012, 12, 11, 23, 59, 59)
#datetime.datetime(2012, 12, 13, 23, 59, 59)
#datetime.datetime(2012, 12, 12, 22, 59, 59)
#datetime.datetime(2012, 12, 13, 0, 59, 59)
#datetime.datetime(2012, 12, 12, 23, 59, 58)
#datetime.datetime(2012, 12, 13, 0, 0)
④ 直接利用time类的对象,做时间加、减,会报错;
from datetime import *
t = time(23,59,59)
display(t)
t1 = t + timedelta(hours=-1)
display(t1)
1.2.datetime类
1)静态方法和属性:可以直接通过类名调用;
datetime.min:datetime类所能表示的最小时间。
datetime.max:datetime类所能表示的最大时间。
datetime.resolution:datetime类表示时间的最小单位,这里是1微秒;
datetime.today():返回一个表示当前本地时间的datetime对象;
datetime.now():返回一个表示当前本地时间的datetime对象,如果提供了参数tz,则获取tz参数所指时区的本地时间;
datetime.utcnow():返回一个当前utc时间的datetime对象;#格林威治时间
datetime.fromtimestamp(timestamp):根据时间戮创建一个datetime对象,参数tz指定时区信息;
datetime.utcfromtimestamp(timestamp):根据时间戮创建一个datetime对象;
datetime.combine(date,time):根据datez对象和time对象,创建一个datetime对象;
datetime.strptime(date_string,format):将格式字符串转换为datetime对象;
① 静态属性
from datetime import *
datetime.min
datetime.max
datetime.resolution
② 静态方法
Ⅰ 返回当前时间 或 UTC时间的datetime对象;
from datetime import *
datetime.today()
datetime.now()
datetime.utcnow()
Ⅱ 传入时间戳,返回本地时间 或 UTC时间的datetime对象;
from datetime import *
import time
datetime.fromtimestamp(time.time())
datetime.utcfromtimestamp(time.time())
Ⅲ 合并date类对象,和time类对象,创建一个datetime类对象;
# 注意一个问题:当使用了time()函数,就不要使用import time这句代码;
from datetime import *
date_x = date(2015,11,11)
time_y = time(23,59,59)
datetime.combine(date_x,time_y)
Ⅳ 利用任意一个时间字符串,创建一个datetime对象;
from datetime import *
datetime.strptime("2019,12,12","%Y,%m,%d")
datetime.strptime("2019,11,11 23:59:59","%Y,%m,%d %H:%M:%S")
#strftime:将给定格式的日期时间对象转换为字符串。日期时间对象=>字符串,控制输出格式
#strptime:将字符串解析为给定格式的日期时间对象。字符串=>日期时间对象,解析字符串
datetime.strftime(format)
datetime.strptime(date_string, format)
2)其它常用方法和属性:通过datetime对象才能调用;
"属性"
dt.year、dt.month、dt.day:获取年、月、日;
dt.hour、dt.minute、dt.second、dt.microsecond:获取时、分、秒、微秒;
"方法"
dt.date():获取date对象;
dt.time():获取time对象;
dt.replace():传入指定的year或month或day或hour或minute或second或microsecond,生成一个新日期datetime对象,但不改变原有的datetime对象;
dt.timetuple():返回时间元组struct_time格式的日期;
dt.utctimetuple():返回时间元组struct_time格式的日期; # 这个没什么用
dt.toordinal():返回1年1月1日开始至今的天数; # 了解就行,用处不大
dt.weekday():返回weekday,如果是星期一,返回0;如果是星期2,返回1,以此类推;
dt.isoweekday():返回weekday,如果是星期一,返回1;如果是星期2,返回2,以此类推;
dt.isocalendar():返回(year,week,weekday)格式的元组;
dt.isoformat():返回固定格式如'YYYY-MM-DD HH:MM:SS’的字符串;
dt.ctime():返回一个日期时间的C格式字符串,等效于time.ctime(time.mktime(dt.timetuple())); # 了解就行,用处不大
dt.strftime(format):传入任意格式符,可以输出任意格式的日期表示形式。
先构造一个date对象:
from datetime import *
dt = datetime.fromtimestamp(1334567890)
display(dt)
① dt.year、dt.month、dt.day:获取年、月、日;
dt.hour、dt.minute、dt.second、dt.microsecond:获取时、分、秒、微秒;
dt = datetime.fromtimestamp(1334567890)
display(dt)
display(dt.year,dt.month,dt.day)
display(dt.hour,dt.minute,dt.second,dt.microsecond)
② dt.date():获取date对象;
dt.time():获取time对象;
dt = datetime.fromtimestamp(1334567890)
display(dt)
display(dt.date())
display(dt.time())
#注意:当获取到date对象和time对象后,就可以分别调用date类和time类中的属性和方法了。
③ dt.replace(year=,month=,day=,hour=,minute=,second=,microsecond=):传入指定的year或month或day或hour或minute或second或microsecond,生成一个新日期datetime对象,但不改变原有的datetime对象;
dt = datetime.fromtimestamp(1334567890)
display(dt)
z = dt.replace(year=2015,month=12,hour=22,minute=59)
display(z)
display(dt)
#注意:你可以传入year或month或day或hour或minute或second或microsecond中,任意一个或多个值,将其对应的值进行修改后返回。
④ dt.timetuple():返回时间元组struct_time格式的日期(本地时间);
dt.utctimetuple():返回时间元组struct_time格式的日期(UTC时间);
dt = datetime.fromtimestamp(1334567890)
display(dt)
display(dt.timetuple())
display(dt.utctimetuple())
⑤ dt.toordinal():返回1年1月1日开始至今的天数。
dt = datetime.fromtimestamp(1334567890)
display(dt)
display(dt.toordinal())
⑥ dt.weekday()和dt.isoweekday():在中国,主要以dt.isoweekday()的使用为主;
- dt.weekday():返回weekday,如果是星期一,返回0;如果是星期2,返回1,以此类推;
- dt.isoweekday():返回weekday,如果是星期一,返回1;如果是星期2,返回2,以此类推;
dt = datetime.fromtimestamp(1334567890)
display(dt)
display(dt.weekday())
display(dt.isoweekday())
⑦ dt.isocalendar():返回(year,week,weekday)格式的元组;
- year:表示当前日期的年份;
- week:表示当前日期是一年中的第几周;
- weekday:表示当前日期是星期几;
dt = datetime.fromtimestamp(1334567890)
display(dt)
display(dt.isocalendar())
#注意:dt.isocalendar()函数的返回值较为特殊,需要特别注意。
⑧ dt.isoformat():返回固定格式如’YYYY-MM-DDTHH:MM:SS’的字符串;
dt = datetime.fromtimestamp(1334567890)
display(dt)
display(dt.isoformat())
display(dt.isoformat().split("T"))
⑨ dt.ctime():了解就行,此函数用处不大;
dt = datetime.fromtimestamp(1334567890)
display(dt)
display(dt.ctime())
⑩ dt.strftime(format):传入任意格式符,可以输出任意格式的日期表示形式;
常用的格式符如下所示:

dt = datetime.fromtimestamp(1334567890)
display(dt)
dt = dt.strftime("%Y{y}%m{m}%d{d} %H{H}%M{M}%S{S}").format(y="年",m="月",d="日",H="时",M="分",S="秒")
display(dt)
#注意:dt.strftime(format)函数很有用,要特别注意。只不过在显示中文这里可能会出现问题,我把这个最难的给你处理了。

















 1171
1171

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









