








前言:Hello大家好,我是小哥谈。PyTorch是一个开源的深度学习框架,它基于Python语言,并提供了高级的神经网络接口,可以用于构建和训练各种深度学习模型。它的设计理念是灵活性和易用性,并且提供了动态图的特性,使得用户可以根据需要自由地定义和修改计算图。本节课就给大家介绍一下PyTorch框架及其安装步骤,希望大家学习之后能够有所收获!🌈
目录

🚀1.PyTorch介绍
PyTorch是一个开源的Python机器学习库,其前身是2002年诞生于纽约大学的Torch。它是美国Facebook公司使用Python语言开发的一个深度学习的框架,2017年1月,Facebook人工智能研究院(FAIR)在GitHub上开源了PyTorch。PyTorch不仅能够实现强大的GPU加速,同时还支持动态神经网络,这一点是现在很多主流框架如TensorFlow都不支持的。
PyTorch基于Python语言,并提供了高级的神经网络接口,可以用于构建和训练各种深度学习模型。它的设计理念是灵活性和易用性,并且提供了动态图的特性,使得用户可以根据需要自由地定义和修改计算图。在PyTorch中,计算图由张量(Tensor)和函数(Function)组成。张量是一种多维数组,类似于NumPy的数组,可以在GPU上进行加速计算。函数则表示张量之间的操作,当张量通过函数进行计算时,会构建一个计算图。这个计算图可以自动求导,即计算张量对于某个变量的导数,这对于训练神经网络非常重要。
PyTorch还提供了丰富的工具和库,用于数据加载、模型构建、优化器、损失函数等等,使得用户可以快速地构建和训练各种深度学习模型。此外,PyTorch也支持分布式训练和部署到生产环境中。
PyTorch提供了两个高级功能:
🍀(1)具有强大 的GPU加速的张量计算(如Numpy);
🍀(2)包含自动求导系统的深度神经网络。
目前,很多知名公司都在使用PyTorch,除了Facebook之外,Twitter、GMU和Salesforce等机构也都采用了PyTorch。TensorFlow和Caffe都是命令式的编程语言,而且是静态的,即首先必须构建一个神经网络,然后一次又一次地使用相同的结构,如果想要改变网络的结构,就必须从头开始。但是对于PyTorch,通过反向求导技术,可以让你零延迟地任意改变神经网络的行为,而且其实现速度快。正是这一灵活性是PyTorch对比TensorFlow的最大优势。另外,PyTorch的代码对比TensorFlow而言,更加简洁直观,底层代码也更容易看懂,这对于使用它的人来说肯定是一件令人激动的事。
PyTorch特点:
(1)简洁:PyTorch的设计追求最少的封装,尽量避免重复造轮子,简洁的设计带来的另外一个好处就是代码易于理解。PyTorch的源码只有TensorFlow的十分之一左右,更少的抽象、更直观的设计使得PyTorch的源码十分易于阅读。
(2)速度:PyTorch的灵活性不以牺牲速度为代价,在许多评测中,PyTorch 的速度表现胜过 TensorFlow和Keras 等框架。
(3)易用:PyTorch是所有的框架中面向对象设计的最优雅的一个。PyTorch的面向对象的接口设计来源于Torch,而Torch的接口设计以灵活易用而著称,Keras作者最初就是受Torch的启发才开发了Keras。PyTorch继承了Torch的衣钵,尤其是API的设计和模块的接口都与Torch高度一致。PyTorch的设计最符合人们的思维,它让用户尽可能地专注于实现自己的想法,即所思即所得,不需要考虑太多关于框架本身的束缚。
PyTorch优势:
(1)支持GPU
(2)灵活,支持动态神经网络
(3)底层代码易于理解
(4)命令式体验
(5)自定义扩展
当然,现今任何一个深度学习框架都有其缺点,PyTorch也不例外,对比TensorFlow,其全面性处于劣势,目前PyTorch还不支持快速傅里叶、沿维翻转张量和检查无穷与非数值张量;针对移动端、嵌入式部署以及高性能服务器端的部署,其性能表现有待提升;其次因为这个框架较新,使得他的社区没有那么强大,在文档方面其C库大多数没有文档。
总的来说,PyTorch是一个功能强大、灵活易用的深度学习框架,被广泛应用于学术界和工业界。它提供了丰富的功能和接口,使得用户可以更加方便地进行深度学习研究和应用开发。
解释:♨️♨️♨️
动态图:编好程序即可执行。
静态图:先搭建计算图,后运行;允许编译器进行优化,另外静态图代码编程复杂,调试不乐观。
说明:♨️♨️♨️
PyTorch官网:PyTorch
PyTorch文档:主页 - PyTorch中文文档
🚀2.PyTorch主要模块
| torch模块 | 包含激活函数和主要的张量操作 |
| torch.Tensor模块 | 定义了张量的数据类型(整型、浮点型等),另外张量的某个类方法会返回新的张量,如果方法后缀带下划线,就会修改张量本身。比如Tensor.add是当前张量和别的张量做加法,返回新的张量。如果是ensor.add_就是将加和的张量结果赋值给当前张量。 |
| torch.cuda | 定义了CUDA运算相关的函数。如检查CUDA是否可用及序号,清除其缓存、设置GPU计算流stream等。 |
| torch.nn | 神经网络模块化的核心,包括卷积神经网络nn.ConvNd和全连接层(线性层)nn.Linear等,以及一系列的损失函数。 |
| torch,nn.functional | 定义神经网络相关的函数,例如卷积函数、池化函数、log_softmax函数等部分激活函数。torch.nn模块一般会调用torch.nn.functional的函数。 |
| torch.nn.init | 权重初始化模块。包括均匀初始化torch.nn.init.uniform_和正态分布归一化torch.nn.init.normal_(_表示直接修改原张量的数值并返回) |
| torch.optim | 定义一系列优化器,如optim.SGD、optim.Adam、optim.AdamW等。以及学习率调度器torch.optim.lr_scheduler,并可以实现多种学习率衰减方法等。具体参考官方教程。 |
| torch.autograd | 自动微分算法模块。定义一系列自动微分函数,例如torch.autograd.backward反向传播函数和torch.autograd.grad求导函数(一个标量张量对另一个张量求导),以及设置不求导部分。 |
| torch.distributed | 分布式计算模块,设定并行运算环境。 |
| torch.distributions | 强化学习等需要的策略梯度法(概率采样计算图) 无法直接对离散采样结果求导,这个模块可以解决这个问题 |
| torch.hub | 提供一系列预训练模型给用户使用。torch.hub.list获取模型的checkpoint,torch.hub.load来加载对应模型。 |
| torch.random | 保存和设置随机数生成器。manual_seed设置随机数种子,initial_seed设置程序初始化种子。set_rng_state设置当前随机数生成器状态,get_rng_state获取前随机数生成器状态。设置统一的随机数种子,可以测试不同神经网络的表现,方便进行调试。 |
| torch.jit | 动态图转静态图,保存后被其他前端支持(C++等)。关联的还有torch.onnx(深度学习模型描述文件,用于和其它深度学习框架进行模型交换) |
| torch.utils.benchmark | 记录深度学习模型中各模块运行时间,通过优化运行时间,来优化模型性能 |
| torch.utils.checkpoint | 以计算时间换空间,优化模型性能。因为反向传播时,需要保存中间数据,大大增加内存消耗。此模块可以记录中间数据计算过程,然后丢弃中间数据,用的时候再重新计算。这样可以提高batch_size,使模型性能和优化更稳定。 |
| torch.utils.data | 主要是Dataset和DataLoader。 |
| torch.utils.tensorboard | pytorch对tensorboard的数据可视化支持工具。显示模型训练过程中的损失函数和张量权重的直方图,以及中间输出的文本、视频等。方便调试程序。 |
🚀3.PyTorch安装步骤
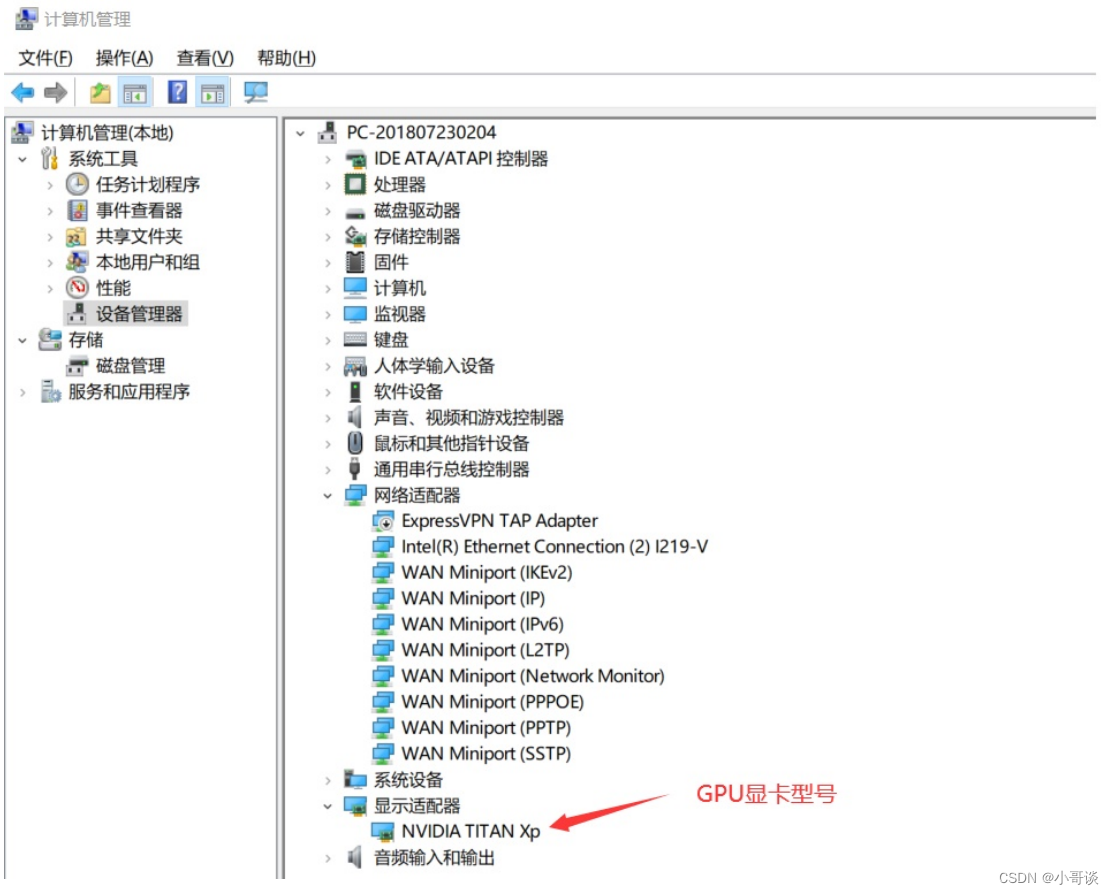
💥💥步骤1:下载和安装nvidia显卡驱动
首先要在设备管理器中查看你的显卡型号,比如在这里可以看到我的显卡型号为Titan XP。
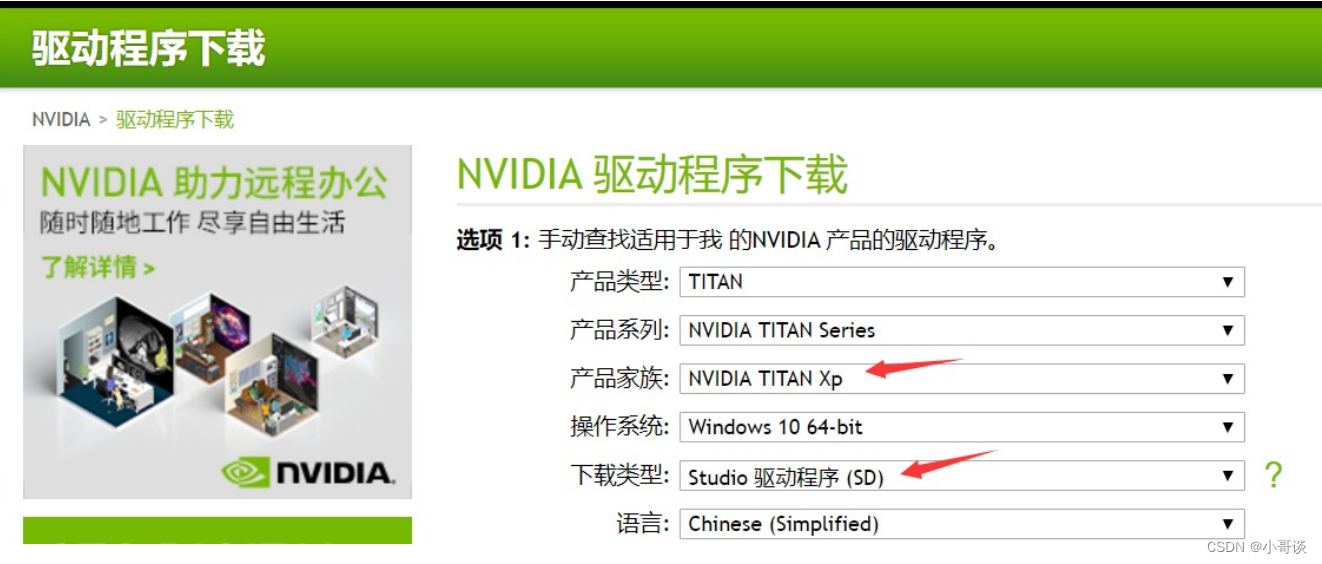
NVIDIA 驱动下载:官方驱动 | NVIDIA
下载对应你的英伟达显卡驱动。
下载之后就是简单的下一步直到完成。
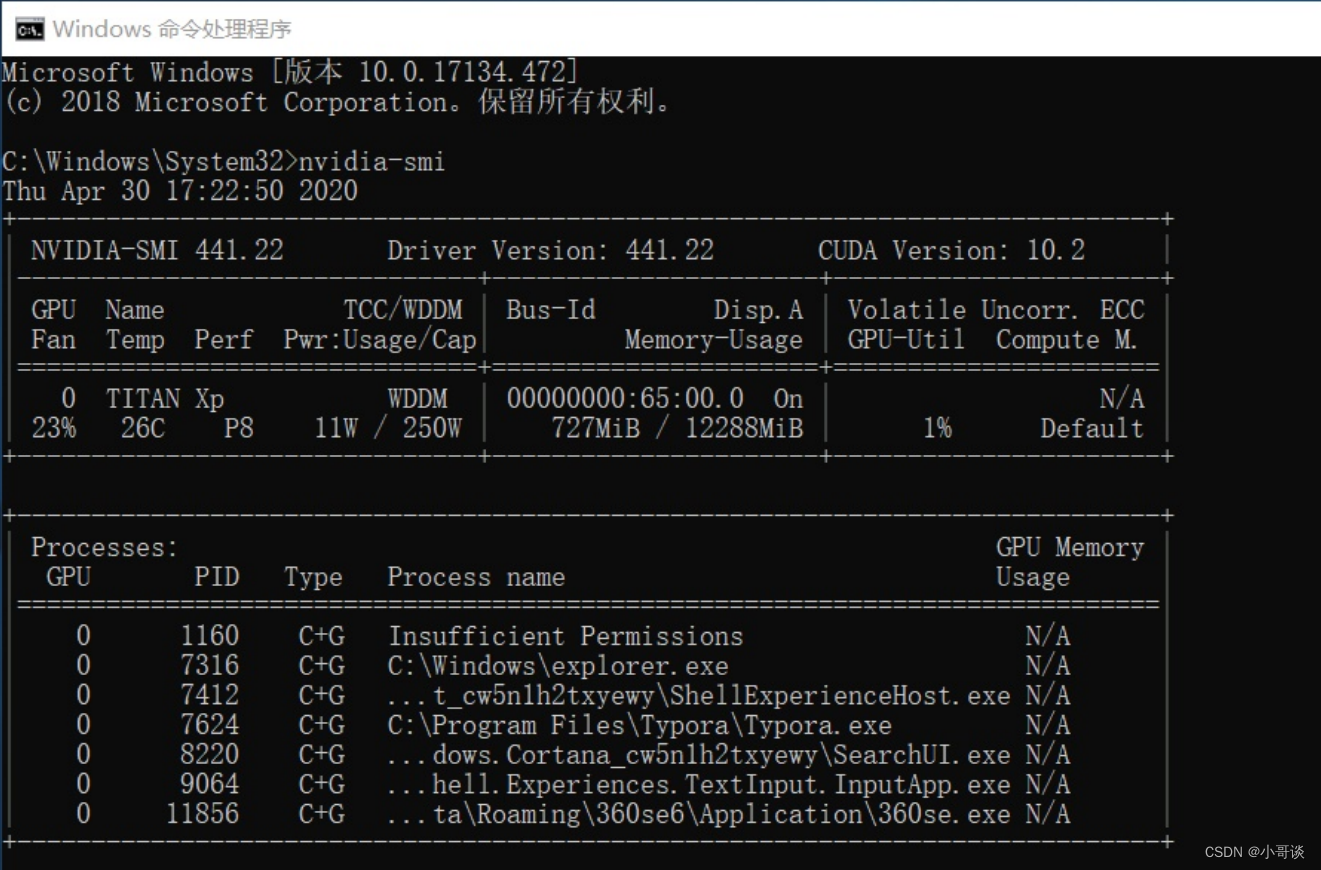
完成之后,在cmd中输入执行:👇
nvidia-smi
如果有错误: 'nvidia-smi' 不是内部或外部命令,也不是可运行的程序 或批处理文件。
把C:\Program Files\NVIDIA Corporation\NVSMI添加到环境变量的path中。再重新打开cmd窗口。
如果输出下图所示的显卡信息,说明你的驱动安装成功。👇
💥💥步骤2:下载CUDA
CUDA下载链接:CUDA Toolkit 12.2 Update 2 Downloads | NVIDIA Developer
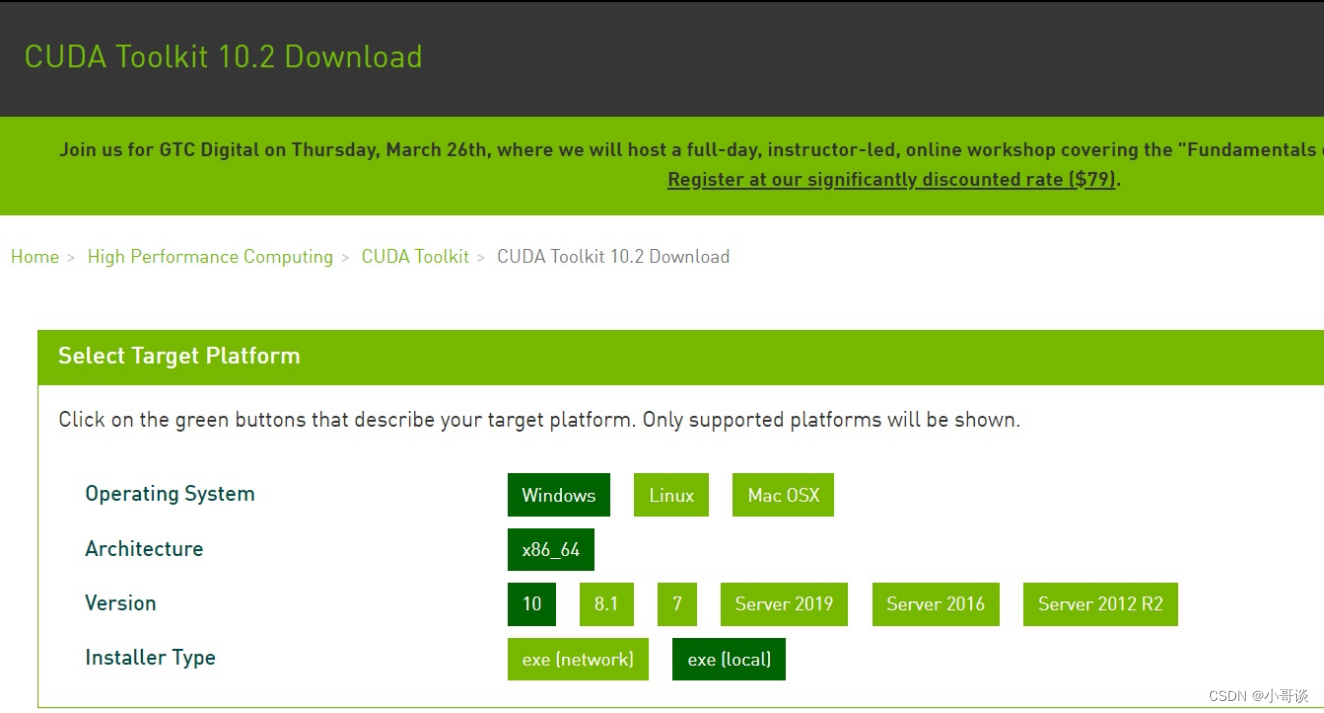
下载后得到文件:cuda_10.2.89_441.22_win10.exe
💥💥步骤3:下载cuDNN
cudnn下载地址:CUDA Deep Neural Network (cuDNN) | NVIDIA Developer
需要有账号
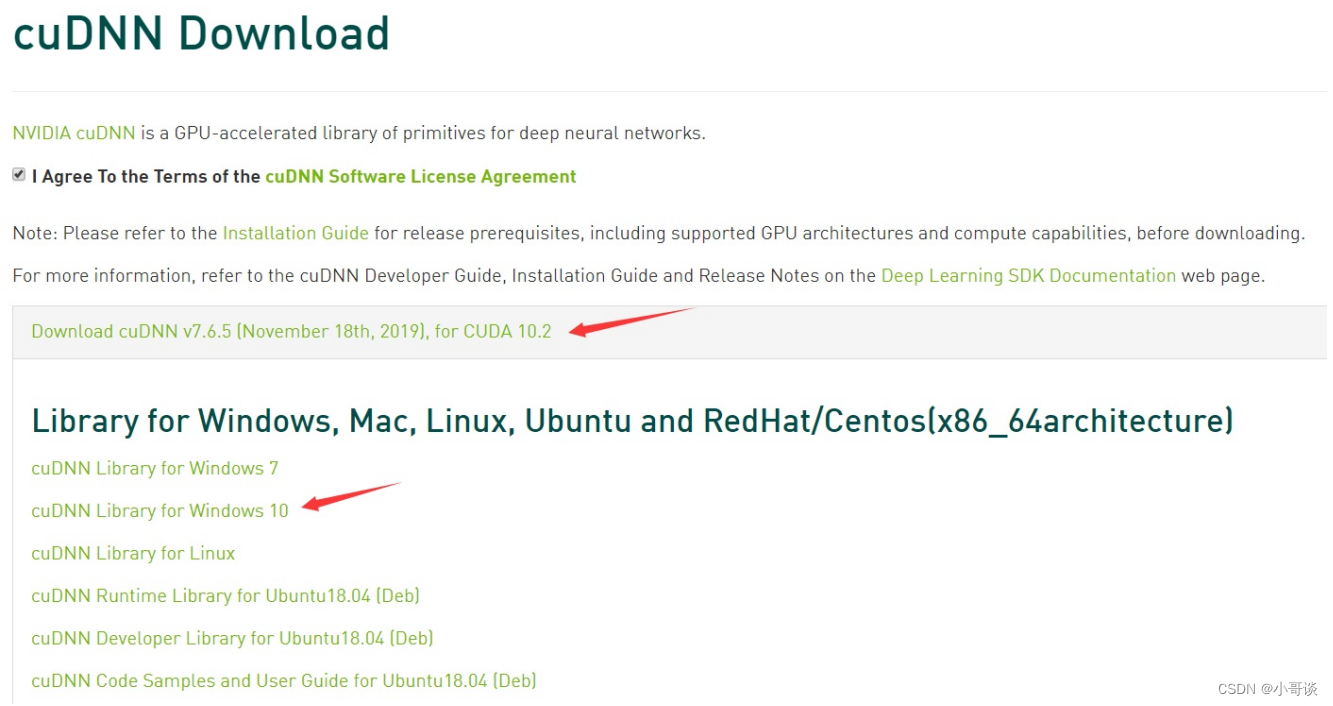
下载后得到文件:cudnn-10.2-windows10-x64-v7.6.5.32.zip
💥💥步骤4:安装cuda
(1) 将cuda运行安装,建议默认路径

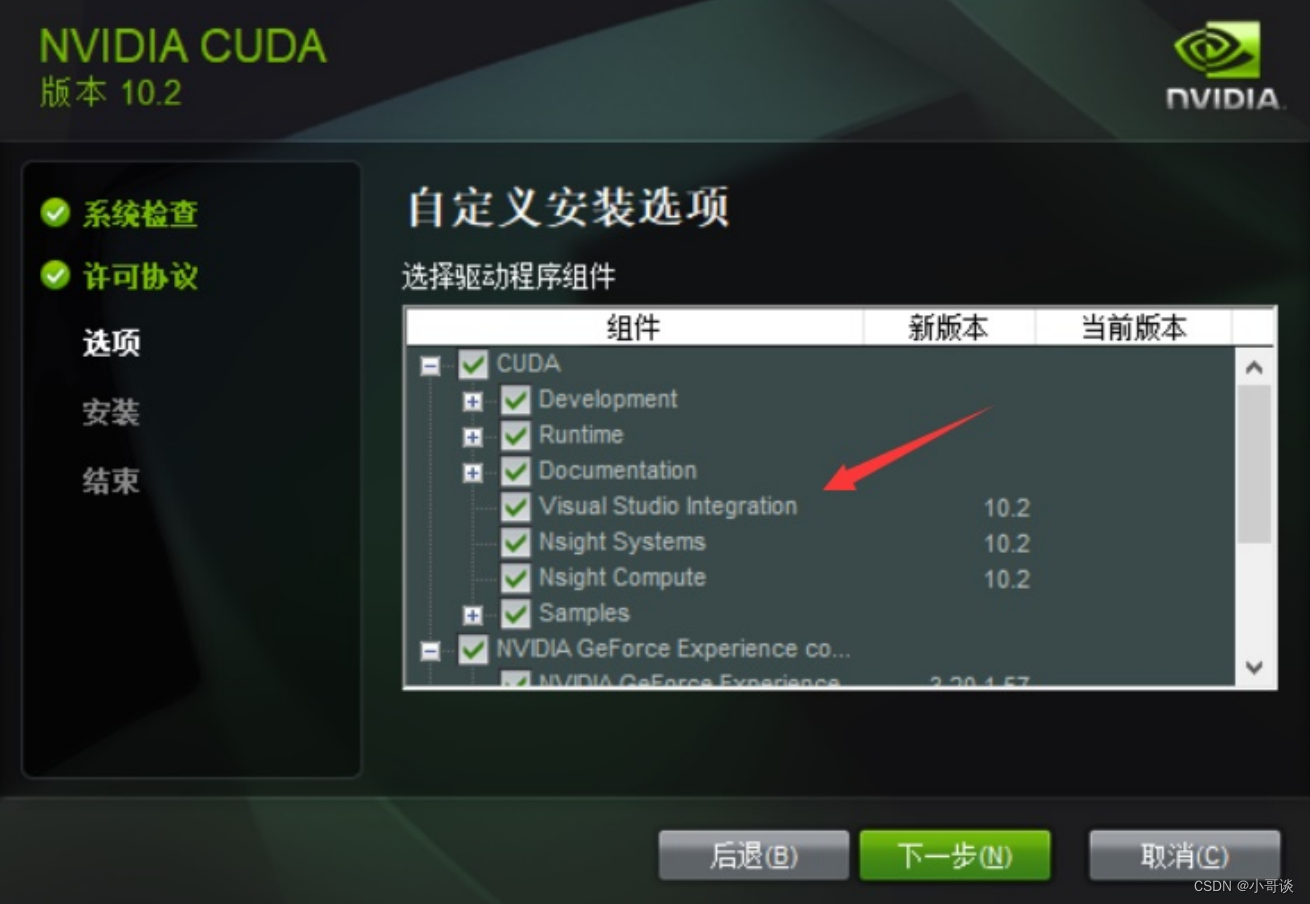
安装时可以勾选Visual Studio Integration
(2) 安装完成后设置环境变量
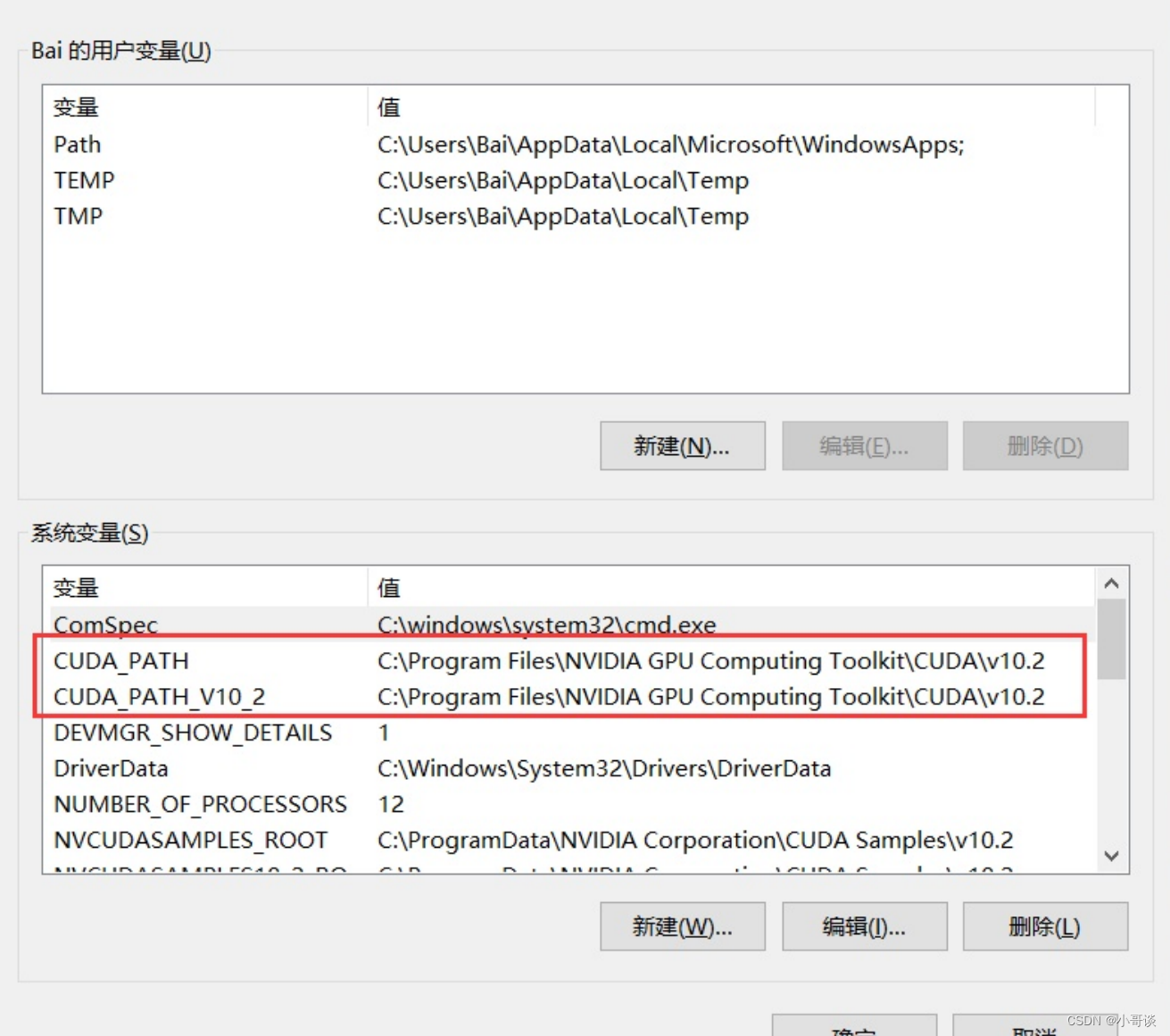
计算机上点右键,打开属性->高级系统设置->环境变量,可以看到系统中多了CUDA_PATH和 CUDA_PATH_V10_2两个环境变量。
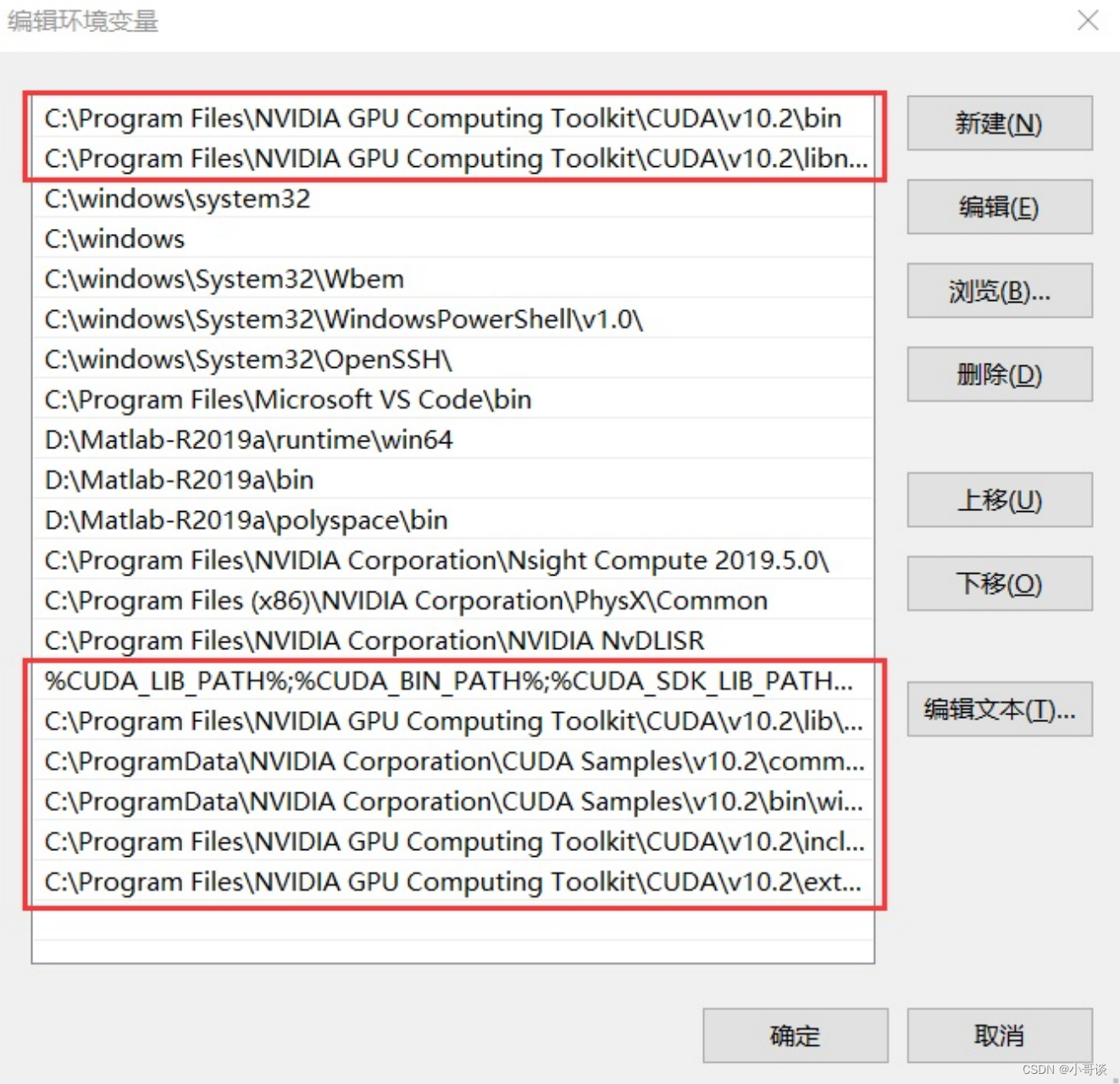
接下来,还要在系统中添加以下几个环境变量: 这是默认安装位置的路径: C:\ProgramData\NVIDIA Corporation\CUDA Samples\v10.2
CUDA_SDK_PATH = C:\ProgramData\NVIDIA Corporation\CUDA Samples\v10.2 CUDA_LIB_PATH = %CUDA_PATH%\lib\x64 CUDA_BIN_PATH = %CUDA_PATH%\bin CUDA_SDK_BIN_PATH = %CUDA_SDK_PATH%\bin\win64 CUDA_SDK_LIB_PATH = %CUDA_SDK_PATH%\common\lib\x64
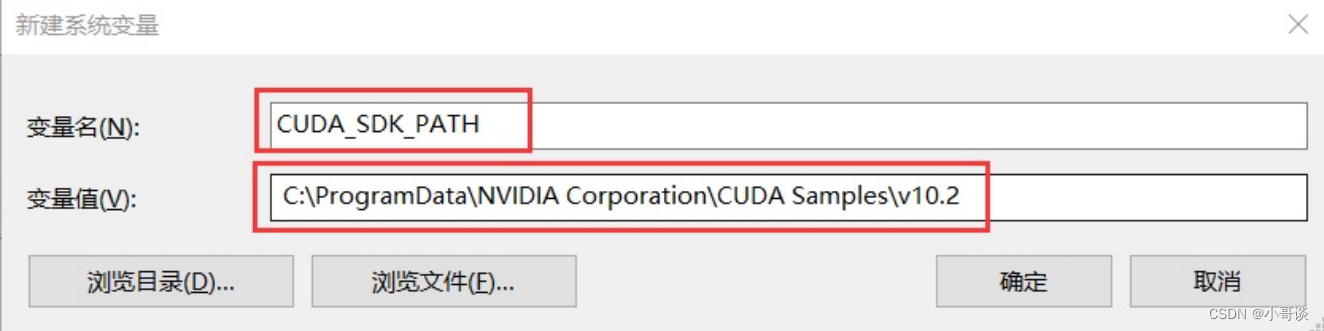
在系统变量 Path 的末尾添加:
%CUDA_LIB_PATH%;%CUDA_BIN_PATH%;%CUDA_SDK_LIB_PATH%;%CUDA_SDK_BIN_PATH%;
再添加如下5条(默认安装路径):
C:\Program Files\NVIDIA GPU Computing Toolkit\CUDA\v10.2\lib\x64 C:\Program Files\NVIDIA
GPU Computing Toolkit\CUDA\v10.2\include C:\Program Files\NVIDIA GPU Computing
Toolkit\CUDA\v10.2\extras\CUPTI\lib64 C:\ProgramData\NVIDIA Corporation\CUDA
Samples\v10.2\bin\win64 C:\ProgramData\NVIDIA Corporation\CUDA
Samples\v10.2\common\lib\x64
💥💥步骤5:安装cuDNN
复制cudnn文件
对于cudnn直接将其解开压缩包,然后需要将bin、include、lib中的文件复制粘贴到cuda的文件夹下。👇
C:\Program Files\NVIDIA GPU Computing Toolkit\CUDA\v10.2
💥💥步骤6:CUDA安装测试
最后测试cuda是否配置成功:
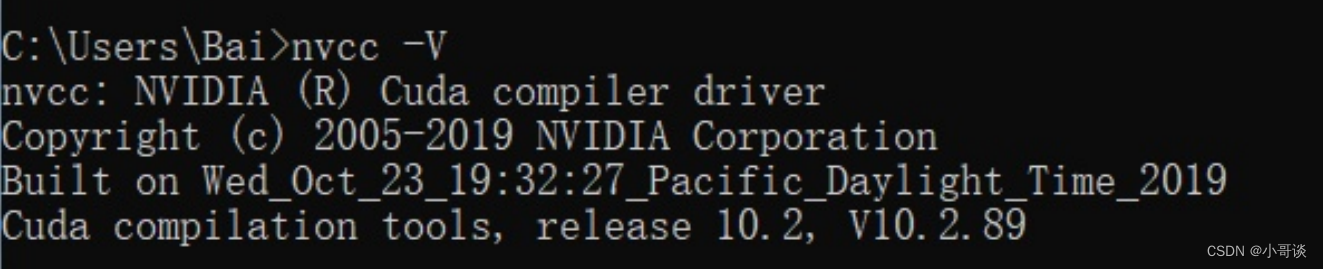
打开cmd执行:
nvcc -V
即可看到cuda的信息
💥💥步骤7:安装Anaconda
Anaconda 是一个用于科学计算的 Python 发行版,支持 Linux、Mac、Windows,包含了众多流行的科学计算、数据分析的 Python 包。✅
(1)下载安装包
Anaconda下载Windows版:Free Download | Anaconda
(2)然后安装Anaconda
(3)添加Aanaconda国内镜像配置
清华TUNA提供了 Anaconda 仓库的镜像,运行以下命令:
conda config --add channels
https://mirrors.tuna.tsinghua.edu.cn/anaconda/pkgs/free/conda config --add channels
https://mirrors.tuna.tsinghua.edu.cn/anaconda/pkgs/main/conda config --set show_channel_urls yes
💥💥步骤8:安装pyTorch
如果使用YOLOv5版本v4.0以上的代码,PyTorch1.6 改为 PyTorch1.7。
注意:需要安装PyTorch1.7以上的版本
创建虚拟环境,环境名字可自己确定,这里本人使用 pytorch1.7作为环境名:
conda create -n pytorch1.7 python=3.8安装成功后激活PyTorch1.7环境:
conda activate pytorch1.7
在所创建的 PyTorch环境下安装 PyTorch的1.7版本, 执行命令:
conda install pytorch torchvision cudatoolkit=10.2 -c pytorch
注意:10.2处应为自己电脑上的cuda版本号

















 1197
1197











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











