






 文章介绍了如何使用Python脚本从抖音个人收藏夹中无水印下载视频和图片,包括优化的特性如重复文件检测、文件组织和简化URL获取方法。
文章介绍了如何使用Python脚本从抖音个人收藏夹中无水印下载视频和图片,包括优化的特性如重复文件检测、文件组织和简化URL获取方法。
功能展示
功能实现:将某个 个人收藏夹里面的 视频/图文 都无水印的下载下来
最新优化:
1.对文件夹内已经下载过的url 进行 md5编码压缩保存,下载前将会比对,即遇到相同的视频/图片将不会重复下载
2.对同个 博主的 内容 将 放在同个文件夹内
3.将收藏夹url简化,只需要获取收藏夹id即可
4.解决只能获取收藏夹里前10个视频/url的问题
展示:
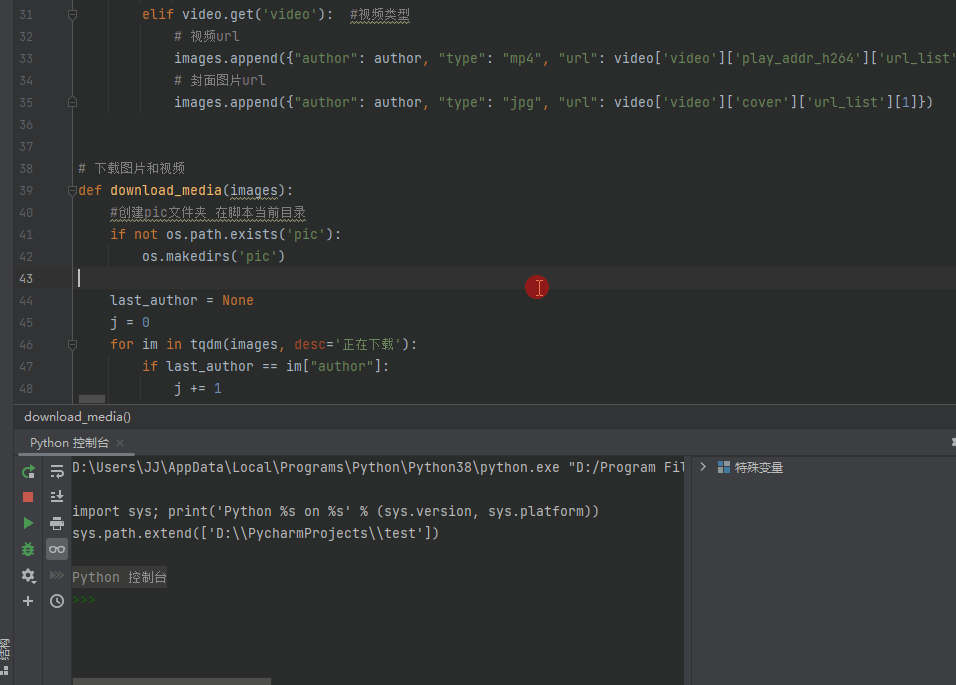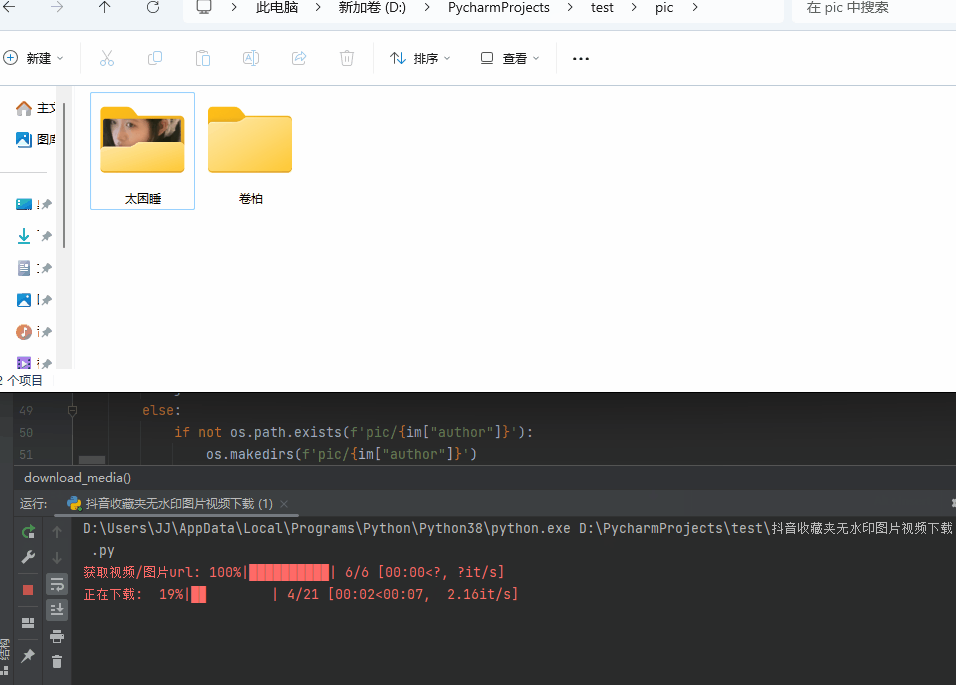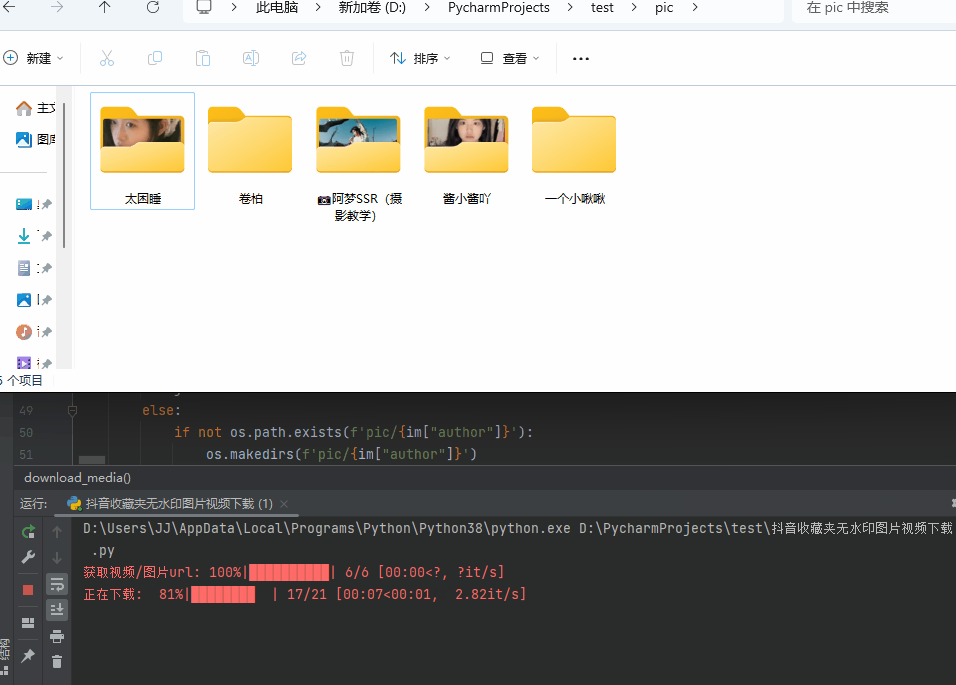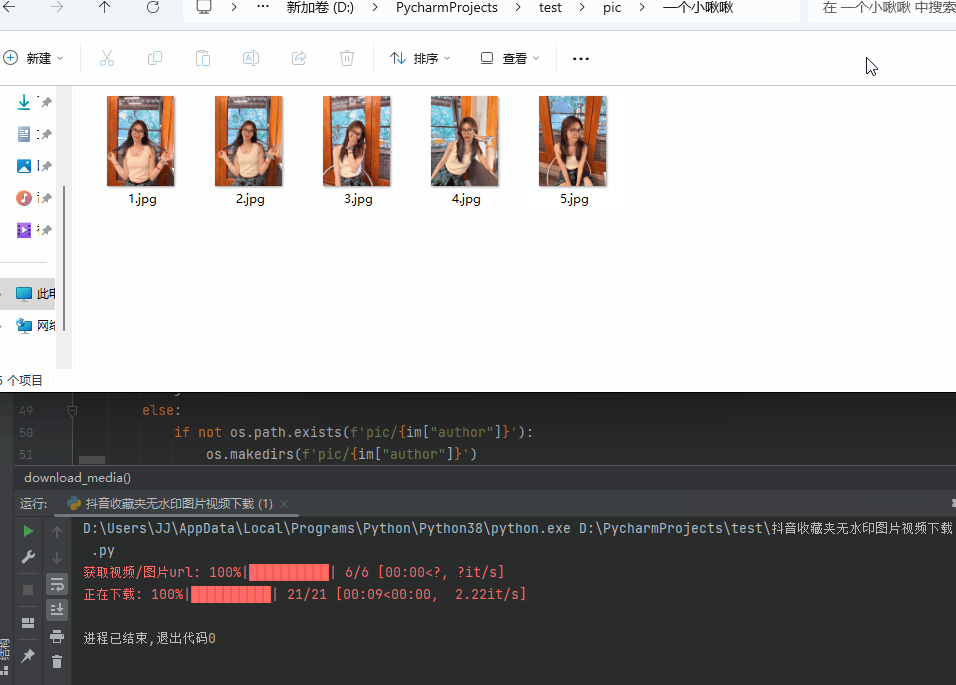
代码
import requests
from tqdm import tqdm
import json
import os
import hashlib
# 收藏夹请求头
header = {
"User-Agent": "",
"Referer": "",
"Cookie": ""
}
# 收藏夹id
collects_id = ''
# 指针
cursor = 0
# 收藏夹url
url = 'https://www.douyin.com/aweme/v1/web/collects/video/list/?device_platform=webapp&aid=6383&channel=channel_pc_web&collects_id={}&cursor={}'
# 收藏夹
images = []
# 处理数据
def Date():
# 指针
cursor = 0
#意味着 最多扫描 10*30 个视频
for i in range(10):
_url = url.format(collects_id=collects_id, cursor = cursor)
dy_rs = requests.get(url=_url, headers=header)
if dy_rs.json()['aweme_list'] is None or dy_rs.ok is False:
return
else:
getUrl(dy_rs.json())
cursor += 30
# 获取视频/图片url
def getUrl(res_json):
for video in tqdm(res_json['aweme_list'], desc='获取视频/图片url'):
# print(json.dumps(video, sort_keys=True, indent=2))
# 获取作者 name
author = video['author']['nickname']
# 获取文案
# ptitle = video['desc']
if video.get('images'): # 图文类型
for img in video['images']:
images.append({"author": author, "type": "jpg", "uri": img['uri'], "url": img['url_list'][0]})
elif video.get('video'): # 视频类型
# 视频url
images.append({"author": author, "type": "mp4", "uri": video['video']['play_addr_h264']['uri'],
"url": video['video']['play_addr_h264']['url_list'][0]})
# 封面图片url
images.append({"author": author, "type": "jpg", "uri": video['video']['cover']['uri'],
"url": video['video']['cover']['url_list'][1]})
# 下载图片和视频
def download_media(images):
if len(images) == 0:
print("未获取到 视频url")
return
# 创建抖音收藏夹下载文件夹 在脚本当前目录
if not os.path.exists('抖音收藏夹下载'):
os.makedirs('抖音收藏夹下载')
for im in tqdm(images, desc='正在下载'):
# 创建 博主文件夹,存放同个博主的内容
if not os.path.exists(f'抖音收藏夹下载/{im["author"]}'):
os.makedirs(f'抖音收藏夹下载/{im["author"]}')
open(f'抖音收藏夹下载/{im["author"]}/log.txt', "w").close()
# 判断 当前url是否已经下载过
downloaded = False
md5 = f'{get_md5(im["uri"])}\n'
with open(f'抖音收藏夹下载/{im["author"]}/log.txt', 'r', encoding='utf-8') as f:
file_lines = f.readlines()
for _md5 in file_lines:
if _md5 == md5:
downloaded = True
break
# 如果没下载过则下载
if not downloaded:
num_png = len(os.listdir(f'抖音收藏夹下载/{im["author"]}'))
img_req = requests.get(url=im["url"]).content
with open(f'抖音收藏夹下载/{im["author"]}/{num_png}.{im["type"]}', 'wb') as f:
f.write(img_req)
with open(f'抖音收藏夹下载/{im["author"]}/log.txt', 'a', encoding='utf-8') as f:
f.write(f'{md5}\n')
def get_md5(url):
# 因为python3运行内存中编码方式为unicode,所以将url md5压缩之前首先需要编码为utf8。
if isinstance(url, str):
url = url.encode("utf-8")
m = hashlib.md5()
m.update(url)
return m.hexdigest()
Date()
download_media(images)
注意:需要的参数数据
个人建议专门创建一个收藏夹 ,以后将想要下载 无水印的视频/图片就扔进去
#收藏夹请求头
header = {
"User-Agent": "",
"Referer":"",
"Cookie":""
}
# 收藏夹id
collects_id = ''
这两个参数需要自己去获取,这里我简单说一下怎么获取:
收藏夹id
- 进入收藏夹页面
- 刷新页面
- f12 --> 网络(network) --> 筛选器输入
list/? - 将 想要下载的收藏夹名字 一个一个试着搜索,搜索到了的文件就是对应收藏夹url响应内容
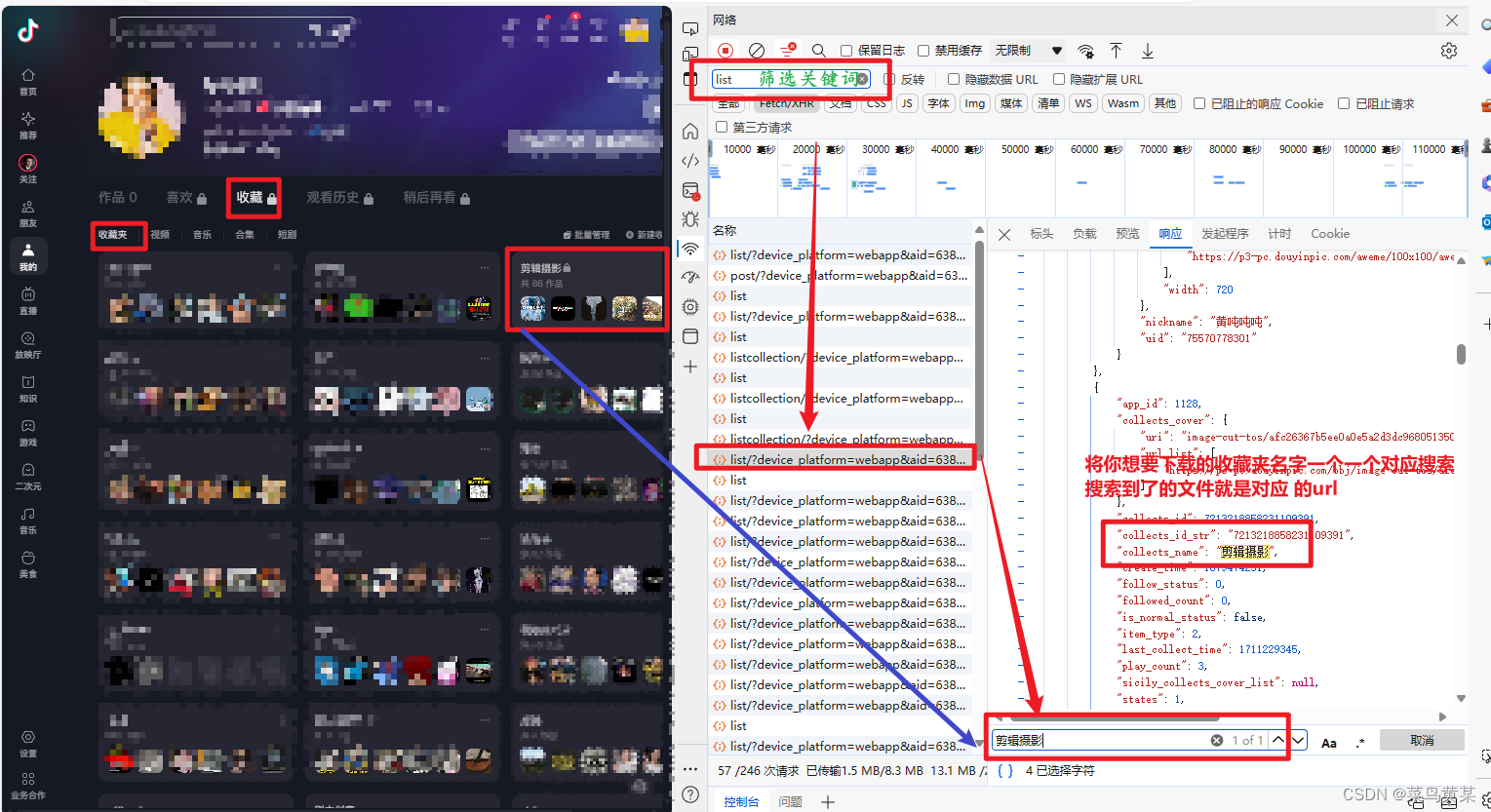
复制收藏夹id,填入代码中

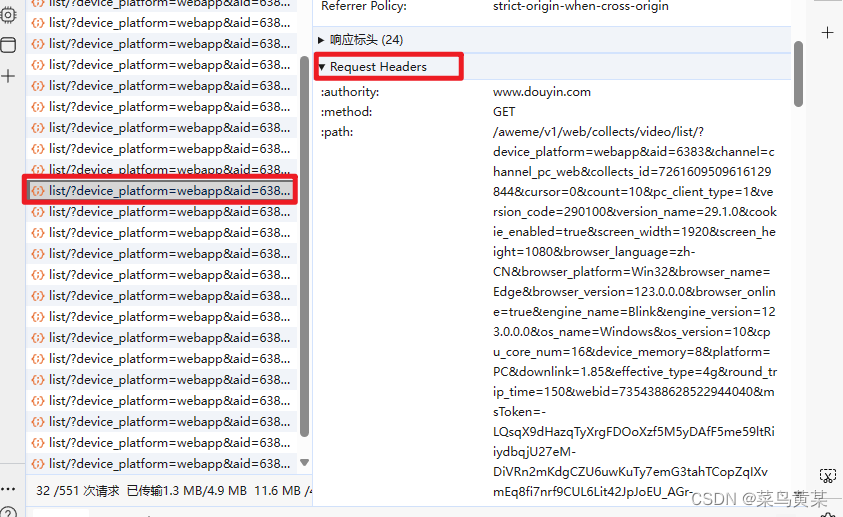
收藏夹请求头
仍然是那个文件 ,找到请求头里对应下面的3个数据复制进代码里 即可享用
#收藏夹请求头
header = {
"User-Agent": "",
"Referer":"",
"Cookie":""
}


















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









