






递归神经网络(RNN),是基于输入的信息,从前向后进行建模,相当于就是从历史到现在。
举个例子,一个古诗填空,递归神经网络就相当于给出了上一句,让你填写下一句。而双向递归神经网络就是相当于给出了前一句和后一句,让你填写中间的一句。
当然这个功能就是联系上下文的作用,在语音识别,情感分析,机器翻译这些方面都有着重要的作用。因为相比于只看你上一句说什么,知道你前一句和后一句来推断中间这一句,会显得更为准确。当然了,显而易见的一点就是准确度虽会提高,但是这个工作量也是大了一倍。(当然不止一倍,只是表面来看)。
一 了解双向递归神经网络
1.1核心思想
通过两个独立的RNN层实现正向和反向的信息处理,所以呢这就要求我们的这个数据已经是完整的不需要再添加的,数据量是一定的了。
然后我们一次前向传播,一次后向传播。获取两次传播的隐藏状态。前向隐藏状态和后向隐藏状态。什么叫隐藏状态呢,就是现在的这一时间步的隐藏状态,依赖于之前所有的历史信息,只能看见来时的路,不能看见未来的路。
所以我们把前向隐藏状态(依赖于从历史到现在)和后向隐藏状态(依赖于从未来到现在)相结合,进行拼接输出。
1.2数学表达
前向隐藏状态:
后向隐藏状态:
拼接:
加权和:
二 应用场景
自然语言处理:命名实体识别、情感分析,捕捉语法特征。
语音识别:音频信号到文本的转换。
蛋白质结构预测:氨基酸序列分析,双向序列匹配。
机器翻译:编码器中上下文jian'mo,理解源语言句子结构。
三 优势与劣势
3.1优势
(1)上下文感知能力强:同时使用过去和未来的信息
(2)特征更加丰富:两个RNN会提取更多特征
(3)任务性能提升
3.2劣势
(1)计算复杂度提升
(2)实时处理困难:需要输入完整的序列
(3)序列长度敏感:长序列会导致梯度问题。
四 代码应用
我使用了单向递归和双向递归对IMDB情感分析数据集进行分析。
IMDB(Internet Movie Database)情感分析数据集是自然语言处理(NLP)领域的经典数据集,广泛用于文本分类任务的基准测试。
4.1单向递归
# -*- coding: utf-8 -*-
import tensorflow as tf
from tensorflow.keras.datasets import imdb
from tensorflow.keras.preprocessing import sequence
from tensorflow.keras.models import Sequential
from tensorflow.keras.layers import Embedding, SimpleRNN, Dense
# 1. 加载数据集
num_words = 10000 # 仅保留最常见的10,000个单词
(X_train, y_train), (X_test, y_test) = imdb.load_data(num_words=num_words)
# 2. 填充/截断序列至统一长度
max_review_length = 500 # 每条评论限制为500个单词
X_train = sequence.pad_sequences(X_train, maxlen=max_review_length)
X_test = sequence.pad_sequences(X_test, maxlen=max_review_length)
# 3. 构建单向RNN模型
model = Sequential()
# 嵌入层:将单词索引映射为密集向量
model.add(Embedding(input_dim=num_words, output_dim=32, input_length=max_review_length))
# 单向RNN层(使用64个隐藏单元)
model.add(SimpleRNN(64)) # 可以替换为 LSTM(64) 或 GRU(64)
# 输出层(二分类)
model.add(Dense(1, activation='sigmoid'))
# 4. 编译模型
model.compile(
loss='binary_crossentropy', # 二元交叉熵损失
optimizer='adam', # 默认优化器
metrics=['accuracy'] # 监控准确率
)
# 5. 训练模型
history = model.fit(
X_train, y_train,
batch_size=64, # 每批64条样本
epochs=10, # 训练10轮
validation_split=0.2 # 20%训练数据用作验证
)
# 6. 评估测试集
test_loss, test_acc = model.evaluate(X_test, y_test)
print(f"测试集准确率: {test_acc:.4f}")
运行结果为:
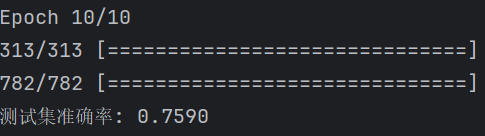
4.2双向递归神经网络
# -*- coding: utf-8 -*-
import tensorflow as tf
from tensorflow.keras.datasets import imdb
from tensorflow.keras.preprocessing import sequence
from tensorflow.keras.models import Sequential
from tensorflow.keras.layers import Embedding, Dense, Bidirectional, SimpleRNN
# 1. 加载数据集
num_words = 10000 # 保留最常见的10,000个单词
(X_train, y_train), (X_test, y_test) = imdb.load_data(num_words=num_words)
# 2. 填充/截断序列至统一长度
max_review_length = 500
X_train = sequence.pad_sequences(X_train, maxlen=max_review_length)
X_test = sequence.pad_sequences(X_test, maxlen=max_review_length)
# 3. 构建双向RNN模型
model = Sequential()
model.add(Embedding(input_dim=num_words, output_dim=32, input_length=max_review_length))
# 双向RNN层(前向 + 后向)
model.add(Bidirectional(SimpleRNN(64))) # 替换为 Bidirectional(LSTM(64)) 或 Bidirectional(GRU(64)) 效果更好
model.add(Dense(1, activation='sigmoid'))
# 4. 编译模型
model.compile(
loss='binary_crossentropy',
optimizer='adam',
metrics=['accuracy']
)
# 5. 训练模型
history = model.fit(
X_train, y_train,
batch_size=64,
epochs=10,
validation_split=0.2
)
# 6. 评估测试集
test_loss, test_acc = model.evaluate(X_test, y_test)
print(f"测试集准确率: {test_acc:.4f}")
上述代码运行后输出为:
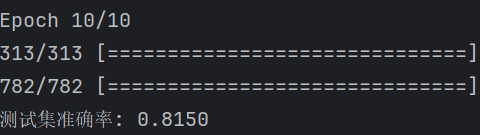
可以看出准确率有明显的提升。
五 后续优化方案
5.1模型结构优化
(1)SimpleRNN 难以捕捉长时依赖,可以使用LSTM和GRU
| RNN类型 | 参数量 | 长时依赖能力 | 训练速度 |
| SimpleRNN | 低 | 弱 | 快 |
| LSTM | 高 | 强 | 慢 |
| GRU | 中 | 中 | 较快 |
(2)堆叠多层双向RNN,提取更复杂的特征
(3)添加注意力机制
5.2防止过拟合
(1)Dropout & 正则化:在RNN层内部和全连接层添加随机失活。
(2)早停法:监控验证集损失,提前终止训练。
5.3训练策略
(1)动态学习率:使用学习率调度器
from tensorflow.keras.optimizers import Adam
from tensorflow.keras.callbacks import LearningRateScheduler
def lr_scheduler(epoch):
return 0.001 * (0.9 ** epoch) # 每轮衰减10%
model.compile(optimizer=Adam(), ...)
history = model.fit(..., callbacks=[LearningRateScheduler(lr_scheduler)])
(2)增大批次大小:批次越大训练越稳定,但可能降低泛化能力。
5.4 高级混合模型
(1)CNN+Bi-RNN 混合架构:用CNN提取局部特征,Bi-RNN捕获长程依赖。
(2)Transformer+Bi-RNN 结合:通过Transformer捕捉全局依赖,Bi-RNN细化局部时序。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









