










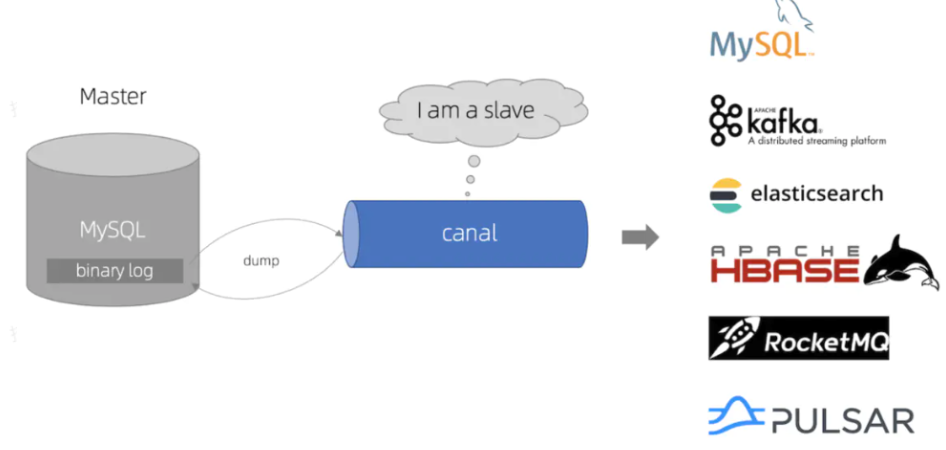
Canal 是一个由阿里巴巴开源的,基于 Java 的数据库变更日志解析的中间件,其原理是基于Binlog订阅的方式实现,模拟一个MySQL Slave 订阅Binlog日志,从而实现CDC,主要用于实现 MySQL 数据库的增量数据同步。它主要的使用场景包括数据库备份、实时数据同步、以及构建数据湖等。Canal 通过模拟 MySQL Slave 的行为,连接到 MySQL Master,实时地解析 Master 节点的 Binlog 日志,然后提取出数据变更信息,支持将数据变更同步到多种类型的下游系统,如 Kafka、ElasticSearch、HBase 等。
为什么要选Canal来进行数据同步
MySQL向ES(elasticsearch)做数据同步其实同步数据有很多方式,有双写同步数据,异步同步数据:前者双写同步数据我们肯定不用的,它实现原理是同时向MVSQL和ES中写入数据,这种性能慢不说,还存在二者还涉及到了分布式事务了,无法保证数据一致性问题,而且还将业务深深耦合起来了,无法做扩展,因此pass。后者异步同步数据方案比较多,比如目前市面上比较火的阿里的Canal和Debezium工具等等,他们都是利用的CDC(数据抓取变更),监听binlog日志做的同步。由于后者Debezium需要集成Kafka,而且需要手写Kafka消费者代码去同步,使得系统更加复杂,实现起来相对Canal比较复杂,因此采用了阿里Canal去做数据同步。
主从复制原理
MySQL的主从复制是依赖于 binlog,也就是记录 MySQL 上的所有变化并以二进制形式保存在磁盘上二进制日志文件。
主从复制就是将 binlog 中的数据从主库传输到从库上,一般这个过程是异步的,即主库上的操作不会等待 binlog 同步地完成。

详细流程如下:
1.主库写 binlog:主库的更新 SQL(update、insert、delete) 被写到 binlog;
2.主库发送 binlog:主库创建一个 log dump 线程来发送 binlog 给从库;
3.从库写 relay log:从库在连接到主节点时会创建一个 IO 线程,以请求主库更新的 binlog,并且把接收到的 binlog 信息写入一个叫做 relay log 的日志文件;
4.从库回放:从库还会创建一个 SQL 线程读取 relay log 中的内容,并且在从库中做回放,最终实现主从的一致性。
Canal工作原理
- 模拟 Slave:Canal 服务端模拟 MySQL 的 Slave,通过 MySQL 提供的dump协议连接到 MySQL 的 Master 节点。
- 读取和解析Binlog:MySQL 的 master 节点接收到 dump 请求后推送 Binlog 日志给 Canal 服务端,解析 Binlog 对象(原始为byte 流)转成 Json 格式;
- 数据同步:Canal 客户端通过 TCP 协议或 MQ 形式监听 Canal 服务端,将解析后的数据变更信息推送到配置的下游系统或应用(Kafka、ElasticSearch、HBase),如通过 Canal Client API 拉取数据变更,或者配置 Canal Adapter 自动同步到特定的数据存储系统。
工作流程
- 配置 MySQL:开启 MySQL 的 Binlog 日志记录,并配置 Canal 连接 MySQL 的权限,确保 Canal 可以作为 Slave 连接到 MySQL Server。
- 启动 Canal Server:部署并启动 Canal Server,Canal Server 会连接到 MySQL Server,开始监听 Binlog 日志的变更。
- 数据解析:Canal Server 解析 Binlog 日志文件,识别数据变更事件,并将这些事件转换为内部数据格式。
- 数据同步:通过 Canal Client API 或者配置 Canal Adapter,将解析后的数据变更同步到 ElasticSearch。这一步可以根据实际业务需求定制数据同步的逻辑,例如根据数据变更类型(插入、更新、删除)更新 ElasticSearch 的索引。
- 实时搜索:随着 ElasticSearch 索引的实时更新,搜索服务能够提供基于最新数据的搜索结果,保证了搜索的准确性和高效性。
术语补充解释:
Canal Server:Canal的服务端组件,负责连接到MySQL服务器,实时读取并解析MySQL的Binlog日志,然后将解析后的数据变更信息提供给Canal Client或同步到其他中间件。
Canal Adapter:Canal的适配器组件,用于将Canal Server解析出的数据变更信息同步到各种类型的下游系统或中间件中,如Elasticsearch、Kafka等。
instance:实例,在这里通常指Canal的一个运行实例,对应于MySQL中的一个数据库或一组数据库。每个instance独立工作,可以有自己的配置和同步逻辑。
Relay Log:在 MySQL 的主从复制架构中,中继日志(Relay Log)是从服务器(Slave)上的一个关键组件。中继日志用于存储从主服务器(Master)复制过来的二进制日志(Binary Log)事件。这些日志文件在从服务器上被重放(执行),以此来确保从服务器的数据与主服务器保持一致。
操作流程
要在本地使用 Canal 实现 MySQL 数据库和 Elasticsearch 的同步,需要先部署 Canal 和配置 Elasticsearch,然后通过 Canal Adapter 实现数据的同步。
增量同步指的是仅同步自上次同步以来在数据库中发生变更的数据,而不是每次都同步全部数据。
步骤概述
- 部署 Canal Server:首先需要在本地安装并启动 Canal Server,使其连接到你的 MySQL 数据库,并开始监听 Binlog 日志。
- 配置 Elasticsearch:确保本地已经安装并启动 Elasticsearch。
- 使用 Canal Adapter:Canal 提供了官方的 Adapter,用于将数据同步到 Elasticsearch。需要配置 Adapter 以连接到你的 Elasticsearch 实例。
示例配置
1. Canal Server 配置
在 Canal 的配置文件 instance.properties 中,配置 MySQL 数据源信息,以及开启的 Binlog 文件和位置:
canal.instance.master.address=127.0.0.1:3306
canal.instance.dbUsername=canal
canal.instance.dbPassword=canal
canal.instance.connectionCharset=UTF-8
canal.instance.tsdb.enable=true
canal.instance.gtidon=false2. Canal Adapter 配置
在 application.yml 中配置 Elasticsearch 的连接信息:
spring:
jackson:
date-format: yyyy-MM-dd HH:mm:ss
time-zone: GMT+8
server:
port: 8081
logging:
level:
com.alibaba.otter: DEBUG
canal.conf:
canalServerHost: 127.0.0.1:11111
flatMessage: true
canalInstances:
- instance: example # Canal instance 名称
groups:
- outAdapters:
- key: es
hosts: 127.0.0.1:9200 # Elasticsearch 地址
properties:
cluster.name: elasticsearch还需要在 src/main/resources/es/mapping 目录下配置同步的表和索引的映射关系。例如,如果你想同步 mydb.user 表到 Elasticsearch,你需要创建一个对应的映射文件 user.yml:
dataSourceKey: defaultDS
destination: example
groupId: g1
esMapping:
_index: user_index
_type: _doc
_id: _id
sql: "SELECT id as _id, name, age FROM user"
commitBatch: 30003. 启动 Canal Adapter
配置好之后,启动 Canal Adapter。它会自动连接到 Canal Server 和 Elasticsearch,根据配置的映射关系同步数据。
增量同步说明
Canal 通过监听 MySQL 的 Binlog 来实现增量数据同步。当在 MySQL 中对数据进行 INSERT、UPDATE、DELETE 操作时,这些变更会被记录在 Binlog 中。Canal Server 解析 Binlog,获取这些变更,然后 Canal Adapter 根据配置将变更的数据同步到 Elasticsearch。这个过程只同步变更的数据,而不是数据库中的全部数据,因此被称为增量同步。
注意:本示例的配置和代码只是一个基本的指导,具体细节(如版本兼容性、安全设置等)需要根据你的实际环境和需求进行调整。
使用场景
- 数据库同步:实现从一个数据库实时同步数据到另一个数据库,常见于主从复制、读写分离等场景。
- 数据迁移与备份:在不影响源数据库性能的前提下,实时备份数据,用于灾备或者数据迁移。
- 数据仓库构建:将业务数据库的增量数据实时同步到数据仓库中,用于后续的数据分析和挖掘。
- 搜索引擎索引更新:实时将数据库中的变更同步到搜索引擎(如 ElasticSearch),保持搜索数据的实时性和准确性。
优势
- 实时性:Canal 基于 Binlog 的增量数据同步机制,能够实现接近实时的数据同步。
- 低侵入性:Canal 通过模仿 MySQL Slave 的方式进行数据同步,无需修改 MySQL Server 的任何配置(只需开启 Binlog)。
- 灵活性:Canal 支持多种数据源和数据目的地的同步,用户可以根据需要灵活配置同步任务。
- 高可用性:Canal 支持集群部署,通过负载均衡和故障转移机制,提高数据同步的稳定性和可靠性。















 703
703











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









