






针对LLMs幻觉问题,本文提出了一种全新的预检测自评估技术,称为 SELF-FAMILIARITY(自熟悉度),该方法的核心思想是在模型生成回复之前,评估其对输入指令中涉及概念的熟悉程度。如果模型对某些概念不熟悉,则在零资源(即没有外部真实信息或背景知识可用)的情况下,选择不生成回答。
此外,本文还提出了一个新的数据集 Concept7,专门研究由模型内部知识受限所导致的幻觉问题。通过在四种不同的大语言模型上进行实验,验证了 SELF-FAMILIARITY 的有效性,并表明其在一致性和准确性上优于现有方法。研究结果强调了在LLM助手中采用预防性策略来缓解幻觉的重要性,并有望提升模型的可靠性、适用性和可解释性。
原文链接:https://arxiv.org/abs/2309.02654
1. Introduction
近年来,针对 LLMs 在开放对话中生成幻觉性回答的问题,研究者提出了多种检测、修正的方法,这些方法大致可分为两类:
- 基于外部知识库的方法:
这类方法依赖第三方知识库,并结合思维链 (CoT) 技术,来识别并纠正可能存在幻觉的回答。 - 基于参数的检测方法:
这类方法主要利用困惑度 (perplexity) 等特定指标来评估回答的正确性。
这些方法在一定程度上可以检测幻觉性回答,但由于缺乏对模型内部知识的考量,它们在解决幻觉问题上仍存在显著不足:
- 只能后检测,无法预防:
大多数方法都是后处理手段,即在回答生成后检查其幻觉程度。这意味着它们无法阻止模型在生成阶段就避免幻觉,导致整体可靠性降低。而人类通常能通过意识到自身知识不足,来避免生成不准确的回答。 - 易受 prompt 风格和模型特性的影响:
现有方法的效果依赖于具体的指令技巧和模型风格,这导致其在不同对话场景下的鲁棒性难以保证。例如,对于二元问答,模型往往生成较短的回答,这会使基于困惑度的评估结果与长文本回答的评估结果出现较大偏差。
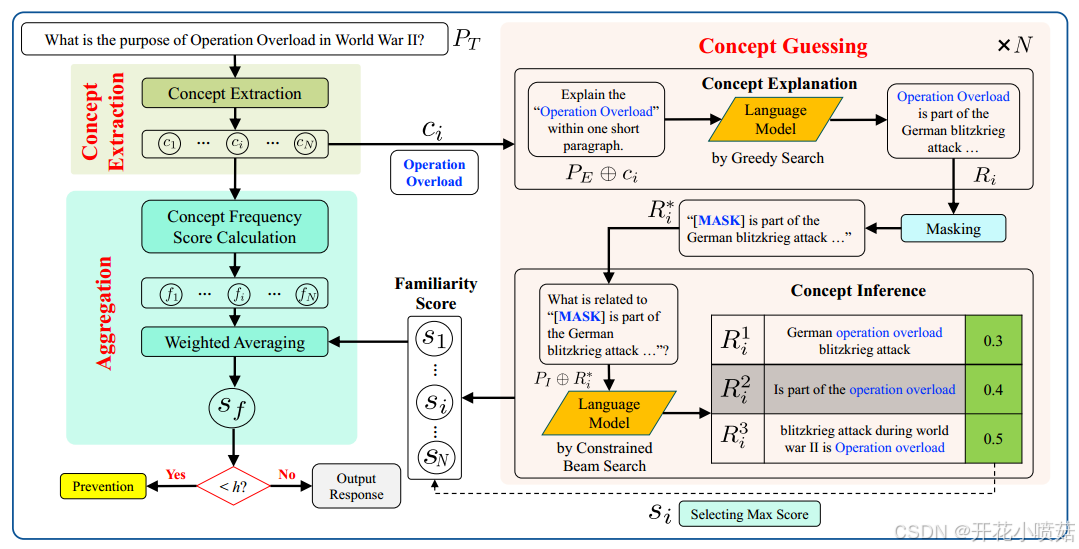
本文提出了一种零资源的预检测方法,称为 SELF-FAMILIARITY。该方法模拟人类的自我评估能力,通过避免讨论不熟悉的概念,从而降低生成幻觉性信息的风险。具体流程如下:
- 概念提取阶段(Concept Extraction)
从输入指令中提取出涉及的概念实体,作为后续评估的对象。 - 概念评估阶段(Concept Guessing)
采用 Prompt Engineering,对每个提取出的概念进行单独测试,获取模型对该概念的熟悉度评分。 - 评分聚合阶段(Aggregation)
将所有概念的熟悉度评分进行汇总,生成最终的指令级熟悉度评分,用于评估模型是否应当回答该指令。
与现有方法相比,SELF-FAMILIARITY 具有以下优势:
- 结合了 CoT 方法和参数化方法的优点
与思维链(CoT)方法类似,该方法能够识别模型不熟悉的概念,进而判断是否回答。但它仅依赖提示工程,不需要模型具备强大的推理能力,避免了 CoT 方法的不足,同时保留其优点。 - 不受指令风格和类型的影响,具有更强的鲁棒性
现有方法容易受到指令格式和模型风格的影响,导致性能不稳定,而SELF-FAMILIARITY 方法则能够适应不同类型的输入指令,提高可靠性。 - 具有预防性,能够主动规避幻觉的产生
现有方法主要依赖后检测,即生成回答后再判断是否存在幻觉,而 SELF-FAMILIARITY 在生成前就能评估模型是否熟悉相关概念,从而主动避免幻觉回答的产生。 - 无需外部知识,适用于零资源环境
该方法完全基于模型的内部知识进行评估,不依赖搜索引擎或知识库,因此可以适用于外部资源受限的场景。
2. Related Work
2.1 幻觉检测和修正方法
以往的幻觉检测与纠正研究主要集中在特定任务的条件文本生成,例如摘要生成、图像字幕生成、对话生成、机器翻译、表格到文本生成等。这些方法通常针对特定的文本生成任务设计,而非用于应对开放性、无约束的对话环境,因此无法直接应用于 LLM 在开放对话中的幻觉预防任务。
在开放对话 (Open Conversation) 环境下,现有方法主要可分为两大类:
- 基于 CoT 或提示工程的检测与修正方法:
这一类方法利用思维链 (CoT) 或提示工程 (Prompt Engineering) 来评估和修正模型的回答,直接让模型自我评估输出的真实性,无需依赖外部知识库。
但这些方法往往针对特定类型的回答定制化设计,泛化能力有限。且由于依赖模型的内部推理能力,如果模型本身对某些概念理解不足,评估结果可能不可靠。由于算法的输出通常是自由文本,难以设定明确的分类阈值,导致幻觉检测的标准不够稳定。 - 基于语言模型参数的检测方法
这一类方法关注语言模型的内部参数,通过计算 token 概率序列等方式来衡量幻觉程度。
这类方法泛化能力更强,可以适用于不同的任务场景。可生成数值评分,相比自由文本输出,更便于量化幻觉程度。
但这种方法解释性较差,相比 CoT 方法,模型难以给出可读的推理过程,使得人类难以理解其决策逻辑。
2.2 幻觉检测数据集(Hallucination Detection Datasets)
目前用于开放对话中的幻觉检测数据集,主要侧重于后检测 (post-detection) 场景,具有一定局限性:
- 现有数据集仅关注后检测,即检测已生成的回答是否存在幻觉,但现实中LLM 可能不会生成这些数据集中包含的错误回答,无法模拟真实场景。
- 不同幻觉成因混杂,难以评估缺乏知识导致的幻觉。现有数据集通常包含多种幻觉来源的混合场景,例如由于推理错误、逻辑漏洞、知识缺失等产生的幻觉。
为了验证模型在零资源环境下的预检测 (pre-detection) 能力,需要专门评估因知识不足导致的幻觉,因此需要创建一个新的数据集:
- 针对预检测,区别于以往仅关注后检测的数据集
- 衡量模型在概念理解不足时的幻觉检测能力(知识缺乏型幻觉)
- 支持零资源环境下的预检测实验
本文提出 Concept-7 数据集,专门用于评估模型在缺乏内在知识情况下的幻觉预防能力。
3. Methodology
本研究的目标是在零资源环境下,通过评估 LLM 对指令中概念的熟悉程度,判断目标指令是否可能引发幻觉。
流程如上所说,先概念提取阶段,从输入指令中提取出涉及的概念实体,作为后续评估的对象;然后进行概念评估,采用 Prompt Engineering,对每个提取出的概念进行单独测试,获取模型对该概念的熟悉度评分;最后评分聚合,将所有概念的熟悉度评分进行汇总,生成最终的指令级熟悉度评分,用于评估模型是否应当回答该指令。
3.1 概念提取 (Concept Extraction)
通过抽取 prompt 中的概念实体,可以减少评估结果受到 prompt 文体风格和格式的影响。
本文使用命名实体识别 (NER) 来实现这种抽取,即
[
c
1
,
c
2
,
.
.
.
,
c
N
]
=
N
E
R
(
P
T
)
[c_1, c_2, ... , c_N]=NER(PT)
[c1,c2,...,cN]=NER(PT)
其中
c
1
,
c
2
,
.
.
.
,
c
N
c_1, c_2, ... , c_N
c1,c2,...,cN 是从目标指令 (PT) 中抽取出的概念实体组。
由于 NER 模型可能存在噪声,本文增加后续的处理步骤来优化提取结果:
- 概念合并 (Concept Grouping)
针对抽取的概念不完整、概念被过度分割的情况,使用概念合并:
按照概念的原始顺序逐一合并,并检查合并后的结果是否在原始 PT 中出现,若出现则认为合并后的结果是一个完整概念并保留。
示例:
对于短语 “2023 United States debt-ceiling crisis”
被错误分割为 [“2023”, “United States”, “debt-ceiling crisis”]
逐步检查 “2023 United States”、“2023 United States debt-ceiling crisis” 是否在原PT中出现
- 概念过滤 (Concept Filtering)
某些提取出的概念过于简单或常见,例如 “year”、“age”,它们对于模型来说是基础知识,继续分析它们会降低效率。针对这种情况,使用概念过滤:
从维基词典中提取最常用的单词,构建常见概念列表,然后把这些概念从抽取的概念实体组中剔除。
示例:
提取出的概念可能包括:[“2023”, “gravity”, “age”, “quantum entanglement”]
其中 “age” 是常见概念,因此会被剔除,最终剩下的概念是:[“2023”, “gravity”, “quantum entanglement”]
3.2 概念猜测 (Concept Guessing)
这一阶段是用一种新的自评估技术,在零资源设置下,评估语言模型对于已提取概念的熟悉程度。
- 首先提示模型为给定的概念生成解释。向模型提供一个概念,并让它基于自身知识 生成一段解释。
- 然后,通过 prompt engineering 让模型根据这一解释重建原始概念。
- 计算匹配程度。如果模型成功生成初始概念,说明它对该概念的理解较好。通过 计算生成的概念序列的概率得分,我们可以量化模型对该概念的熟悉程度,这一概率得分可作为概念的熟悉度分数 (familiarity score) 。
如果一个语言模型能够从其生成的解释中熟练地推导出原始概念,这不仅表明了解释的充分性,也反映了模型对概念的熟练程度。
重要的是,这种方法不需要获得该概念来自于外部知识库的标准定义。
对于上述三个步骤,具体流程如下:
3.2.1 概念解释 (Concept Explanation)
本阶段旨在让语言模型生成对概念的解释,并确保模型不能简单地复制概念来“作弊”。
i) 使用标准解释提示 P E P_E PE 引导模型生成解释
首先,定义一个标准的解释提示格式或模板
P
E
P_E
PE,并将目标概念
c
i
c_i
ci 插入到提示中,形成一个完整的查询内容:
R
i
=
G
r
e
e
d
y
S
e
a
r
c
h
(
L
M
(
P
E
⊕
c
i
)
)
R_i=GreedySearch(LM(P_E \oplus c_i))
Ri=GreedySearch(LM(PE⊕ci))
其中,
⊕
\oplus
⊕ 表示在prompt模板
P
E
P_E
PE 的预定义位置插入
c
i
c_i
ci,即让模型在特定的上下文中进行回答。
GreedySearch 即让LM每次都选择概率最高的下一个词,直到遇到句子结束标记或达到最大长度
目标概念 ci:光合作用
标准提示 PE:“请解释一下什么是[概念]。”
插入后的完整查询:“请解释一下什么是光合作用?”
这一过程完全依赖于模型的自身知识生成对概念的解释。
ii) 防止模型“作弊”
在某些情况下,模型可能会直接把原始概念复制到解释中,从而避免真正进行概念理解。
为了 防止这种“抄袭”问题,需要在生成的解释中屏蔽(Mask)掉原始概念
c
i
c_i
ci,以确保后续的概念重建任务不会被“作弊信息”干扰。即:
R
I
∗
=
M
a
s
k
(
R
i
)
R^*_I=Mask(R_i)
RI∗=Mask(Ri)
3.2.2 概念推理 (Concept Inference)
对于生成的解释,重新推理原始概念,从而确定模型对概念的熟悉度。
与前一步类似,构造一个标准的概念推理提示格式或模板 P I P_I PI,然后要求模型根据屏蔽后的解释 R i ∗ R^∗_i Ri∗,推理出原始概念 c i c_i ci。
本文使用束搜索 (beam search) 进行优化。具体来说,生成多个候选答案,并返回每个答案的概率分数。在此期间,要求生成的答案中必须包含原始概念
c
i
c_i
ci,并通过模型生成包含
c
i
c_i
ci的最优结果的概率作为打分,从而衡量答案的质量。
[
<
R
i
1
,
s
i
1
>
,
.
.
.
,
<
R
i
T
B
,
s
i
T
B
>
]
=
C
o
n
s
B
e
a
m
S
e
a
r
c
h
(
L
M
(
P
I
⊕
R
i
∗
)
,
c
i
)
[<R^1_i,s^1_i>,...,<R^{T_B}_i,s^{T_B}_i>]=ConsBeamSearch(LM(P_I \oplus R^*_i),c_i)
[<Ri1,si1>,...,<RiTB,siTB>]=ConsBeamSearch(LM(PI⊕Ri∗),ci)
其中, R i j R^j_i Rij 表示生成的包含 c i c_i ci的第 j j j个回答, s i j s^j_i sij 是对应的概率得分。 T B T_B TB是束搜索的大小
从生成的候选答案中,选出概率最高的那个答案作为最终的输出,其对应的概率值
s
i
s_i
si 就表示模型对该概念
c
i
c_i
ci 的熟悉度分数。
s
i
=
m
a
x
(
s
i
1
,
s
i
2
,
.
.
.
,
s
i
T
B
)
s_i=max(s^1_i,s^2_i,...,s^{T_B}_i)
si=max(si1,si2,...,siTB)
3.3 聚合 (Aggregation)
这一阶段,根据不同概念的重要性合并为熟悉度分数,以生成最终的指令级别的结果。
3.3.1 概念频率得分
本文提出了一种基于概念中包含的单词的频率排名来计算得分的方法,期望包含不常见单词的概念对应的得分较低。
对目标概念 c i c_i ci 中的每一个单词 j j j,从维基词典中检索该单词的频率排名 p j i p_{j_i} pji。(如果该单词不在字典中或是大写字母开头的单词,我们将其频率排名设为字典长度)
计算概念
c
i
c_i
ci 的最终频率得分
f
i
f_i
fi:
f
i
=
M
i
∏
j
=
1
M
i
e
x
p
{
−
p
j
i
H
}
f_i=M_i \prod^{M_i}_{j=1}exp\{-\frac{p_{j_i}}{H}\}
fi=Mij=1∏Miexp{−Hpji}
其中,由于单词分布通常遵循长尾分布(即大多数单词出现频率较低,少数单词出现频率较高),使用指数函数对频率排名进行转换,再与概念 c i c_i ci 中单词数量 M i M_i Mi 相乘。 H H H 是归一化因子。
3.3.2 加权聚合 (Weighted Aggregation)
计算 prompt 的幻觉水平
s
f
=
∑
i
=
1
N
(
r
θ
(
f
i
)
)
−
1
s
i
∑
i
=
1
N
(
r
θ
(
f
i
)
)
−
1
sf=\frac{\sum^N_{i=1}(r^{\theta(f_i)})^{-1}s_i}{\sum^N_{i=1}(r^{\theta(f_i)})^{-1}}
sf=∑i=1N(rθ(fi))−1∑i=1N(rθ(fi))−1si
其中, θ ( f i ) \theta(f_i) θ(fi) 表示将 f i f_i fi 递增排序后的排名位置; r r r 是比例因子,控制递减速度; s i s_i si 是第 i i i 个概念的熟悉度得分; N N N 是概念总数量。
排名越靠前的概念(即频率越小的概念)会有更高的权重,确保它们在最终得分中贡献更多。
对于指令的幻觉水平得分 s f sf sf,如果低于预设的阈值 h h h,则认为该指令有潜在的幻觉问题,并停止响应生成过程。
(再来看流程图就很清楚了)
4. Experiment
4.1 数据集 (Dataset)
大多数现有数据集主要集中在对幻觉性回答的分类上。为了有效评估 SELF-FAMILIARITY 方法,本文引入了 Concept-7 数据集,该数据集专注于由模型有限的内在知识引起的潜在幻觉性指令的分类。
下图为数据集 Concept-7 的构成。

- 192个基础概念:选择依据维基百科上的热门页面以及领域多样性,被认为是所有语言模型普遍已知的,用作分类熟悉概念的基准。
- 106个测试概念:从七个专家领域(医学、金融、音乐、艺术、法律、物理学和历史)中选择。
- 74个虚构概念:基于真实概念虚假构建,它们天生对所有语言模型来说都是不熟悉的,用于保持熟悉概念和不熟悉概念之间的平衡。
熟悉度标注:作为评估模型对概念熟悉程度的标准参考。这些标注通过 GPT-4 自动标注,并经过人工核查完成。
指令生成:为了复制一般的对话场景,使用 prompt(具体见下)通过 GPT-3.5 为每个概念生成三条相关问题。这包括两个开放式问题和一个是非题。并筛选掉那些没有提到原始概念的问题,以确保问题的强相关性。包含不熟悉概念的问题被视为幻觉性指令。
- 评分指令:要求根据提供的背景信息,评估参与者对目标概念的理解。

- 问题生成指令:要求为给定的概念生成三个问题,其中两个是开放式问题,另一个是“是/否”问题。

- 命名实体提取指令:要求从给定的问题中提取出命名实体,返回命名实体的顺序应该基于其重要性。

4.2 Baseline Methods
几种不同的基线方法,用于在没有外部知识的情况下评估语言模型对概念的熟悉度,即对概念的理解能力,但它们的侧重点有所不同。
- Greedy-Perplexity:对于每个输入,使用贪婪搜索生成一个响应,然后计算该响应的困惑度(Perplexity)。困惑度越低,说明模型对输入的理解越好。负的困惑度分数被认为是熟悉度分数。
- Greedy-AvgLogp:对于每个输入,使用贪婪搜索生成一个响应,然后计算该响应的平均对数token概率。该概率反映了模型生成该响应的信心,值越大,表示对概念的理解越好。
- Greedy-MinLogp:类似于 Greedy-AvgLogp,但此方法选择生成的响应中最小的概率分数作为熟悉度分数。
- Sample-BERTScore:从提示中采样 TS 个响应,并计算每对句子之间的 BERTScore 相似度(BERTScore 是衡量两个句子语义相似度的一种方法)。选择与其他句子平均相似度最高的句子作为中心句子,最大平均相似度作为熟悉度分数。
- ample-SentenceScore:与 Sample-BERTScore 方法相似,不同之处在于使用 Sentence-BERT (一种用于生成句子嵌入的模型)计算句子嵌入的余弦相似度,以此来评估响应之间的相似性。选择与其他句子最相似的句子作为“代表句子”,并使用其相似度作为熟悉度分数。
- Self-Detection:这种方法基于同义问题一致性。首先从提示中采样多个同义问题,然后计算这些问题的回答一致性分数。如果答案一致,表明模型对该概念有较高的理解。
- Forward-Inference:直接询问语言模型是否认识到指令中的领域相关概念,这种方法类似于 CoT(Chain of Thought)方法。回答为“是”的概率序列被视为熟悉度分数。
- Forward-Self:使用相同的模型来评估其生成的响应是否正确回答了问题。类似于 Forward-Inference,这也通过预测“是”或“否”来评估模型的理解能力。
4.3 测试LLM
为了对不同风格的指令对齐大型语言模型进行深入比较,选择了五个不同的模型进行评估:
- Vicuna-13b-v1.3
- Llama-2-13b-chat
- Falcon-7b-instruct
- mpt7b-instruct
- Alpaca-7b
4.4 评估指标
AUC、ACC、F1、PEA
4.5 实验结果
通过比较各 baseline 和 Self-Familiarity 对于数据集 Concept-7 种概念熟悉度的打分,与数据集 Concept-7 中自带的熟悉度打分得到结果。
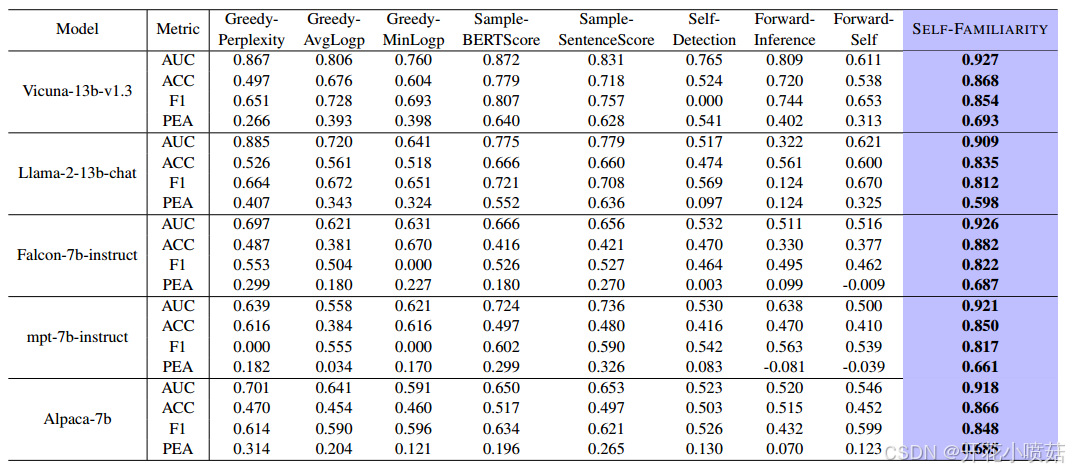
所有baseline方法在不同模型上表现出明显的性能不一致,且不同语言模型偏好的方法也有显著差异。这可能是由于,许多当前的方法容易受到模型风格的影响。这种性能波动使得这些方法在不同设置下的适应性较差。
例如,
Forward-Inference 方法虽然在 Vicuna-13b-v1.3 上表现不错,但在其他模型上效果则较差。
这可能说明,像 CoT 或者 prompt engineering 等方法,虽然能取得很高质量的结果,但它们在很大程度上依赖于模型固有的 CoT 能力。由于许多语言模型并没有专门为这种任务进行微调,这限制了这些方法的广泛适用性。
另一方面, 即使是基于参数的方法,也会受到鲁棒性问题的影响。
例如,
Greedy-Perplexity 方法虽然在多个模型上表现良好,但在 mpt-7b-instruct 上无法检测到任何幻觉指令,导致其 F1分数为0。
与以往方法相比,本文的方法不仅提供了更优的性能,而且在不同语言模型上的表现保持了一致性。此外, PEA相关系数的得分表明,本文的算法产生的评估结果与基于概念的金标准解释的熟悉度分数高度一致。这些结果凸显了本文提出方法的鲁棒性和可靠性。
4.6 人工评估结果
由人工对 Vicuna-13b-v1.3 模型的生成结果进行概念熟悉度评分,与各方法给出的熟悉度打分比较。结果如下:

4.7 Ablation Study

- 概念实体处理方法消融:
- W/O Grouping(没有概念合并):指在处理过程中不对抽取出的概念进行合并操作。
- W/O Filtering(没有概念过滤):指在处理过程中不剔除那些常见的概念(比如基础知识概念)。
- W/O Ranking(没有概念排序):指不根据概念的频率评分来排序概念,而是按它们在指令中的位置来确定顺序。
任何一种处理方法的缺失都会导致最终性能的下降
- 评分聚合方法消融:
- Minimal Only:选择最小的概念熟悉度分数作为最终的结果。
- Most Infrequent Only:选择频率最少的概念的熟悉度分数作为最终的结果。
从实验结果来看,提出的加权平均方法在除 F1 指标外,其他所有指标中都展现了最佳的整体表现。加权平均方法能够同时考虑到不同概念的重要性排名和整体聚合表现,而其他两种方法则只是关注概念熟悉度分数的某些部分。
4.7 案例研究
下图案例中,红色表示错误信息,绿色表示正确信息。蓝色是概念,金色是生成的解释。测试模型为Vicuna-13b-v1.3。

本文提出的方法不仅能有效预防幻觉问题,还能提供良好的可解释性,并能够作为纠正幻觉性回答的有价值工具。通过结合背景知识,模型能够更准确地理解和生成与概念相关的回答,而不再轻易受到错误信息的干扰。
总之,文章介绍了一种新颖的潜在幻觉指令预检测方法,称为 SELF-FAMILIARITY。该方法通过概念猜测 (Concept Guessing) 来评估模型生成的概念解释的质量,从而判断模型对概念的理解程度。
- SELF-FAMILIARITY 利用自评估方法,在没有额外资源的情况下,检测潜在的幻觉性指令。通过评估模型对概念的理解程度来判断是否存在幻觉指令。这种方法在各类语言模型中表现出色。
-
- 该方法具有优异的可解释性,能够识别导致幻觉产生的具体概念。通过找出触发幻觉的概念,SELF-FAMILIARITY 方法为后期的检测与修正提供了有价值的信息。这使得该方法能够与其他幻觉检测和修正技术结合,提升了其多样性和实用性。
尽管 SELF-FAMILIARITY 方法在处理由不足的内在知识引发的幻觉问题时表现出色,但它并不适用于处理因错误信念或推理错误而产生的幻觉。因此,尽管该方法能应对大多数常见的幻觉情况,但在应对这类幻觉时可能有所局限。
另外,在命名实体抽取失败或存在复杂归因的情况下,可能会遇到挑战。在这种情况下,需要识别并评估指令中提到的所有实体,这可能导致推理时间显著增加。
作者计划在未来的研究中探索如何评估更加细粒度的子概念理解,并计划开发更加复杂的算法,能够有效处理涉及模糊或“模棱两可”实体的情况,进一步扩展方法的适用范围。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









