






(很好的文章!和上一篇帖子里让模型自己在数据集上学习的方法不一样,这篇一下子达到幻觉的内在原理上,实验也很详细,每一步都有n个实验佐证)
ReDeEP: Detecting Hallucination in Retrieval-Augmented Generation via Mechanistic Interpretability
原文链接:https://arxiv.org/pdf/2410.11414
Retrieval-Augmented Generation (RAG) 模型通过引入外部知识来减少由于内部参数化知识不足而导致的幻。然而,即使检索到的内容是准确且相关的,RAG 模型仍可能生成与检索信息相矛盾的幻觉。要检测这些幻觉,需要解析大语言模型(LLM)如何利用外部知识和内部参数化知识。然而,现有的检测方法往往仅关注其中一种机制,或者没有有效地解耦二者的相互影响,导致检测精度受限。因此,本文研究了 RAG 场景下幻觉产生的内部机制。
研究发现,幻觉发生的关键原因在于:LLM 中的知识前馈网络(Knowledge FFNs)在残差流中过度强调参数化知识,而复制头(Copying Heads)未能有效保留或整合检索到的外部知识。基于这一发现,作者提出了一种新方法 ReDeEP,通过解耦 LLM 对外部上下文和参数化知识的利用方式来检测幻觉。实验表明,ReDeEP 在 RAG 幻觉检测方面显著提升了准确率。
此外,作者还提出了 AARF 方法,它通过调节知识前馈网络和复制头的贡献,来缓解幻觉问题。
1. Introduction
检索增强生成(RAG)模型,旨在通过整合从外部知识库检索到的相关信息来提高LLM响应的准确性。尽管使用了准确和相关的检索上下文,RAG模型仍可能产生不受支持或与检索到的信息相矛盾的陈述,这种现象被称为RAG幻觉。如下图所示,这些冲突可能导致幻觉,但并不总是导致幻觉:

图中RAG的两个例子,其中检索到的文档是正确的,但与参数知识冲突。左边的例子显示了基于外部知识的正确反应,而右边的例子则显示了尽管有准确的外部背景,但仍有幻觉。
因此,将RAG幻觉与知识冲突区分开是一个新的研究方向。本文的工作重点是检测RAG幻觉,特别是在检索到的外部背景准确且相关的情况下。
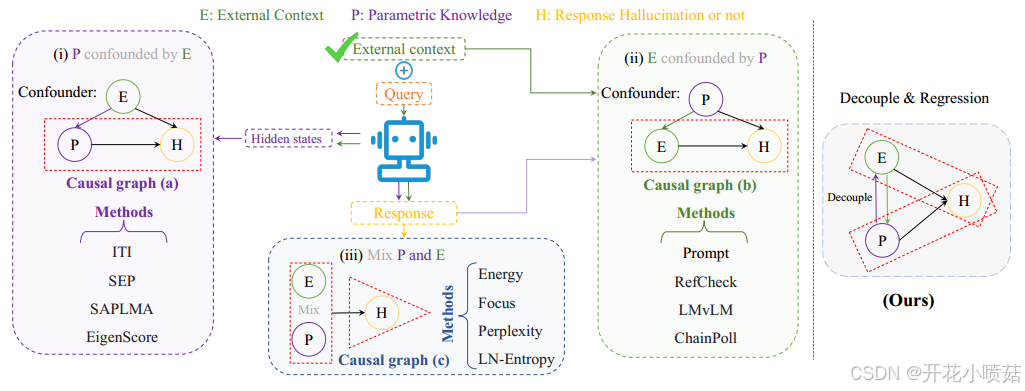
现有的幻觉检测方法可以归类为三种因果框架:
参数化知识 P :指 LLM 内部存储的知识,这些知识以模型参数的形式存在,是模型在训练过程中学到的信息。
外部上下文 E :指检索到的外部信息或背景内容,这部分信息通常由检索模块提供,用来辅助模型生成更加准确、真实的回答。
幻觉 H :指模型生成的不真实或错误的信息,即与真实信息不符的内容。
1. 参数化知识受外部知识混淆(图a)
幻觉检测方法主要依赖于 LLM 的隐藏状态来判断生成内容是否存在幻觉。但由于隐藏状态是由外部上下文 E 和参数化知识 P 共同作用的结果,而 E 同时也是影响幻觉 H 的因素,这就引入了混淆问题(无法判断幻觉的来源)。
因此,仅依赖 P 来预测幻觉是不够准确的,需要考虑如何解耦 E 与 P 的影响,从而更有效地检测和判断幻觉的产生。
2. 外部知识受参数化知识混淆 (图b)
该方法主要利用外部上下文 E 和模型响应进行幻觉检测。
同上,由于模型的生成结果不可避免地受到 P 的影响,即使 E 提供了正确的信息,模型仍可能因 P 产生幻觉。同样需要考虑如何解耦 E 与 P 的影响。
3. 混合参数化知识与外部知识 (图c)
该方法直接结合参数化知识 P 和外部知识 E 进行幻觉检测,通常使用不确定性估计或采样技术 (如 token 概率) 来判断幻觉。然而,这种方法没有有效区分 E 和 P 的作用,使得二者的独立贡献变得模糊,影响了幻觉检测的精确性。
为了解决 RAG 模型幻觉检测的挑战,本文首先利用机械可解释性(mechanistic interpretability)来解耦 LLM 对参数化知识和外部上下文的使用方式。通过研究分析 RAG 场景下幻觉产生的内部机制,并提出两个衡量指标:
- 外部上下文评分:利用注意力头量化模型对外部上下文的使用程度。
- 参数化知识评分:基于前馈网络评估 LLM 对参数化知识的依赖程度(§ 3.1)。
相关性分析和因果干预揭示了幻觉通常发生在以下情况:
- 知识前馈网络(Knowledge FFNs,主要位于 LLM 后期层)在残差流中过度添加参数化知识,导致模型生成基于 P 而非 E 的内容。
- 复制头(Copying Heads,即具有复制行为的注意力头)未能有效保留检索到的外部知识,或者 LLM 在生成过程中丢失了复制头关注的重要信息(§ 3.2)。
ReDeEP 用于 LLM 结合 RAG 进行幻觉检测。该方法将参数化知识 P 和外部上下文 E 作为协变量,从而解决混淆问题。
AARF 通过增强注意力机制(增加 Copying Heads 关注外部知识的权重)和抑制知识前馈网络对参数化知识的过度贡献,在残差流中优化信息整合,从而减少幻觉(§ 4)。
实验结果表明,在 RAGTruth 和 Dolly (AC) 数据集上,ReDeEP 的幻觉检测能力明显优于现有方法。
AARF 能够提升 LLaMA 模型生成内容的真实性(truthfulness)(§ 5)。
2. Background and Related Work
2.1 Background
本研究基于机械可解释性,旨在解析 LLMs 的内部组件如何影响最终预测结果。
本文主要关注被广泛应用的仅包含 decoder 的 Transformer 结构(GPT 类模型)。这类模型依赖残差连接(每一层的注意力头和前馈神经网络都会向隐藏状态添加信息),这些信息通过残差流累积并最终影响模型的输出。
Transformer 关键组件
1. 注意力头
在 Transformer 中,通过关注前序 token 来调整当前 token 的表征,并更新残差流。
其中,一类特殊的注意力头被称为 “复制头”,通过 output-value circuits 将信息从一个 token 复制到另一个 token,用于保留之前关注的 token 信息,并将其传递到后续的计算中,使模型可以更有效地利用检索到的外部内容。
复制头可以通过分析 OV 矩阵的正特征值来检测。(OV 矩阵的正特征值较大表示这个注意力头更倾向于直接传递信息,而不是创建新的信息)
如果复制头未能正确保留或整合检索到的信息,LLM 可能会忽略外部知识 E,而过度依赖内部参数化知识P,从而导致幻觉。
2. 前馈神经网络 (FFNs)
FFNs 主要负责存储和调用模型内部参数化知识 P。
每个 FFN 层会对隐藏状态进行变换,本质上是在不同的 key-value pairs 之间进行线性组合:
(键 (key) 是编码特定知识的触发条件(例如,某个概念或问题);值 (value) 代表该知识的具体输出)
研究表明,FFN 在 LLM 的参数化知识利用过程中,决定了模型是否能够有效调用并整合存储的知识。
如果 FFN 过度添加参数化知识 P 到残差流中,可能会覆盖外部上下文信息 E,导致模型输出不符合外部检索内容的幻觉。
3. Logit Lens
Logit Lens 是一种分析 LLM 内部状态的技术,用于直接将某一层的隐藏状态映射回词汇分布,以解释模型的行为。
在一个 Transformer 模型中,每一层都会生成一个隐藏状态
x
l
x^l
xl ,它代表了当前层对输入的处理结果。隐藏状态包含了大量的语义和上下文信息,但这些信息并不直接告诉我们模型是如何最终决定生成某个 token 的。
为了使这些隐藏状态更具可解释性,我们可以将它们解码成模型的输出分布,这就是 Logit Lens 的关键步骤:
-
LayerNorm 层归一化对隐藏状态进行标准化处理
-
Unembedding 矩阵 W U W_U WU 是一个反嵌入矩阵,将隐藏状态转换为实际的词汇分布。在生成过程中,模型会使用这个矩阵将当前的隐藏状态映射到一个向量,这个向量表示当前生成 token 的概率分布。
L o g i t L e n s ( x l ) = L a y N o r m ( x l ) W U LogitLens(x^l)=LayNorm(x^l)W_U LogitLens(xl)=LayNorm(xl)WU得到模型的预测分布 (logits),即模型对于当前 token 的生成概率。
通过 Logit Lens,可以追踪不同 Transformer 层中的隐藏状态如何影响最终预测,从而分析 FFN 和注意力头(特别是复制头)在预测中的作用,更好地解释LLMs 在 RAG 场景下如何利用外部知识 E 和参数化知识 P,并找出幻觉的根源。
2.2 Related Work
3. Empirical Study
实验设置:
模型: Llama2-7B-chat
数据集:RAGTruth
RAGTruth 是一个高质量的、手工注释的 RAG 幻觉数据集,专门用于研究 RAG 模型中的幻觉现象。
RAGTruth 中每个数据点包含以下几个部分:
- 查询 (query) q = ⟨ t 1 , . . . , t q ⟩ q = ⟨t_1, ..., t_q⟩ q=⟨t1,...,tq⟩:模型需要回答的问题。
- 检索到的上下文 c = ⟨ t q + 1 , . . . , t c ⟩ c = ⟨t_{q+1}, ..., t_c⟩ c=⟨tq+1,...,tc⟩:从外部检索系统中获得的相关信息,用于辅助模型回答查询。
- 部分生成的响应 r ^ = ⟨ t c + 1 , . . . , t n ⟩ \widehat{r} = ⟨t_{c+1}, ..., t_n⟩ r =⟨tc+1,...,tn⟩:模型已经生成的部分答案,通常在生成过程中逐步扩展。
- 生成的响应 r:模型生成的答案。
- 幻觉标签 h:标签值为 0 时表示响应是真实的,为 1 时表示生成的响应存在幻觉(与实际检索内容不符)
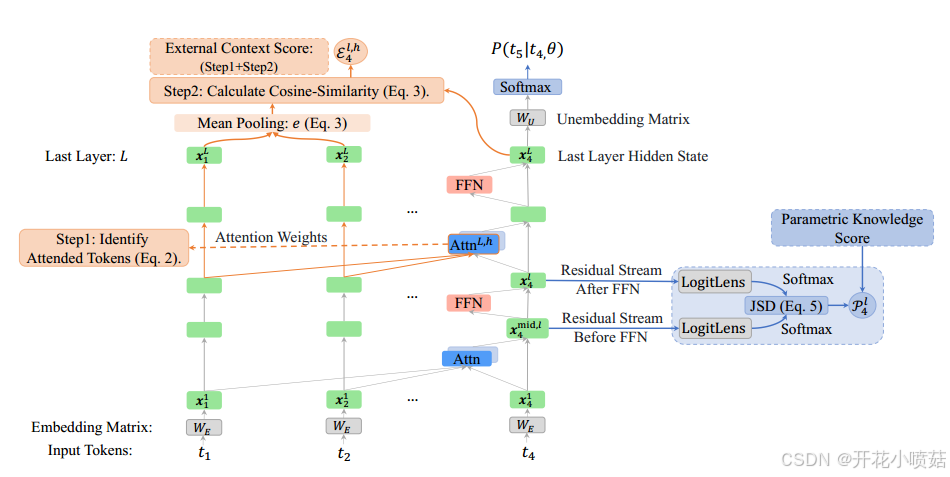
3.1 LLMs 使用外部上下文和参数化知识的度量
本文设计了两项具体的度量指标,分别用于评估模型在生成过程中如何利用外部信息和内部知识,从而量化 LLM 如何使用外部上下文和参数化知识。
1. 外部上下文的度量
重点在于,注意力头是否关注了正确的上下文、模型是否有效地保留并在生成过程中利用了这些信息。
为了评估 LLM 对外部上下文的利用,本文定义了一个基于上下文语义差异的度量方法:
对于最后一个 token t n t_n tn ,注意力权重 a n , q : c l , h a^{l,h}_{n,q:c} an,q:cl,h 表示模型在生成过程中特别关注外部上下文的程度。
由于注意力机制通常是高度稀疏的(即,大部分注意力集中在少数几个 token 上),我们选择关注度最高的前
k
k%
k 个 token 作为模型最重要的参考信息:
I
n
l
,
h
=
a
r
g
m
a
x
t
o
p
k
%
(
a
n
,
q
:
c
l
,
h
)
I^{l,h}_n=argmax_{topk\%}(a^{l,h}_{n,q:c})
Inl,h=argmaxtopk%(an,q:cl,h)
将注意力关注的 token
I
n
l
,
h
I^{l,h}_n
Inl,h 的隐藏状态取均值 (mean-pooling) 来表示它们的综合语义:
e
=
1
∣
I
n
l
,
h
∣
∑
j
∈
I
n
l
,
h
x
j
L
e=\frac{1}{|I^{l,h}_n|}\sum_{j\in I^{l,h}_n}x^L_j
e=∣Inl,h∣1j∈Inl,h∑xjL
其中, x j L x_j^L xjL 表示在 LLM 的最后一层隐藏状态中,第 j j j 个 token 的表征。
通过计算最后生成的 token
t
n
t_n
tn 的隐藏状态
x
n
L
x_n^L
xnL 与关注的上下文表示
e
e
e 之间的余弦相似度,可以衡量 LLM 在生成该 token 时是否有效地利用了关注的外部信息:
E
n
l
,
h
=
e
⋅
x
n
L
∣
∣
e
∣
∣
⋅
∣
∣
x
n
L
∣
∣
E^{l,h}_n=\frac{e\cdot x^L_n}{||e||\cdot ||x^L_n||}
Enl,h=∣∣e∣∣⋅∣∣xnL∣∣e⋅xnL
余弦相似度的取值范围在 [ − 1 , 1 ] [-1,1] [−1,1] 之间,值越大,表示生成的内容和检索到的上下文越相似,表明模型充分利用了外部上下文。
每生成一个新的 token,就会计算该 token 的 ECS。最终,将整个生成的回答
r
r
r 的所有 token 的得分取平均值,得到响应级别的外部上下文分数(ECS):
E
r
l
,
h
=
1
∣
r
∣
∑
t
∈
r
E
t
l
,
h
E^{l,h}_r=\frac{1}{|r|}\sum_{t\in r}E^{l,h}_t
Erl,h=∣r∣1t∈r∑Etl,h
这个指标衡量了 LLM 在整个回答生成过程中,是否充分利用了外部检索到的信息。
2. 内部知识参数化的度量
考虑到 FFN 层主要用于存储参数知识,本文使用 LogitLens 将 FFN 层之前(即
x
n
m
i
d
,
l
x^{mid,l}_ n
xnmid,l)和之后(即
x
n
l
x^l_n
xnl)的残差流状态映射到词汇分布。
二者词汇分布的差异表示 FFN 层添加到残差流中的参数知识,由 Jensen Shannon 散度 (JSD) 测量,给出了 token-level 参数知识得分 (PKS)
P
n
l
=
J
S
D
(
q
(
x
n
m
i
d
,
l
)
∣
∣
q
(
x
n
l
)
)
P^l_n=JSD(q(x^{mid,l}_n)||q(x^l_n))
Pnl=JSD(q(xnmid,l)∣∣q(xnl))
其中, q ( x ) = s o f t m a x ( L o g i t L e n s ( x ) ) . q(x)= softmax(LogitLens(x)). q(x)=softmax(LogitLens(x)).
然后得到 response-level PKS 得分:
P r l = 1 ∣ r ∣ ∑ t ∈ r P t l P^l_r=\frac{1}{|r|}\sum_{t\in r}P^l_t Prl=∣r∣1t∈r∑Ptl
重点:
- 把上下文编码和生成token的编码的余弦相似度 作为判断 LLM 对外部上下文利用的证据
- 把经过 FFN 层前后的编码通过 LogitLens 映射回词汇分布后的差异 作为判断 LLM 对内部知识利用的证据
3.2 Experiment
RQ1. LLM 对外部上下文、参数化知识的利用与幻觉之间的关系
(1) LLM 对外部上下文的利用与 RAG 幻觉的关系
研究者对比了真实响应 (h=0) 和幻觉响应 (h=1) 的外部上下文得分 (ECS):
构建数据集子集:
- D H D^H DH:包含所有幻觉响应 (h=1) 的集合
- D T D^T DT:包含所有真实响应 (h=0) 的集合
按照 3.1 中的方法,计算所有真实响应的外部上下文得分均值,和所有幻觉响应的外部上下文得分均值:
E
T
l
,
h
=
1
∣
D
T
∣
∑
r
∈
D
T
E
r
l
,
h
E
H
l
,
h
=
1
∣
D
H
∣
∑
r
∈
D
H
E
r
l
,
h
E^{l,h}_T=\frac{1}{|D^T|}\sum_{r\in D^T}E^{l,h}_r \\ E^{l,h}_H=\frac{1}{|D^H|}\sum_{r\in D^H}E^{l,h}_r
ETl,h=∣DT∣1r∈DT∑Erl,hEHl,h=∣DH∣1r∈DH∑Erl,h
计算二者的差值:
Δ
E
l
,
h
=
E
T
l
,
h
−
E
H
l
,
h
\Delta E^{l,h}=E^{l,h}_T-E^{l,h}_H
ΔEl,h=ETl,h−EHl,h
表示真实响应相比幻觉响应在外部上下文得分上的提升程度。
实验结果如下(图中是每层每个head上 Δ E l , h \Delta E^{l,h} ΔEl,h 的统计)

如图所示,在Llama2-7B中,1024个注意头中有1006个在真实数据集DT上的外部背景得分高于幻觉数据集 D H D^H DH(即 Δ E l , h > 0 \Delta E^{l,h}>0 ΔEl,h>0)。
可以得出结论,在群体层面,LLM在产生幻觉时利用外部语境信息的程度低于真实响应。
为了进一步验证忽略外部上下文是否会导致 RAG 幻觉,研究者计算了幻觉标签
h
h
h 与 外部上下文得分
E
E
E 之间的 Pearson 相关系数 (PCC)。
由于预期二者为负相关,研究者对幻觉标签
h
h
h 进行了取反,得到
h
‾
=
1
−
h
\overline{h}=1−h
h=1−h。
计算 PCC 来量化幻觉/真实标签 { h ‾ i } i = 1 N \{\overline{h}_i\}^N_{i=1} {hi}i=1N 与 { E i } i = 1 N \{E_i\}^N_{i=1} {Ei}i=1N 之间的关系。
实验结果如下

实验结果中,大多数注意力头的外部上下文得分与幻觉标签呈负相关,表明 LLM 在生成幻觉时往往未能充分利用外部上下文。外部上下文利用不足时,幻觉出现的概率更高。
进一步分析发现,幻觉的主要原因是 LLM 在生成过程中丢失了原本由注意力头关注的重要信息,而不是注意力头本身忽略了外部知识。
再讨论复制头与外部上下文的关系,进一步探究这些注意力头的特性。
计算每个注意力头的复制能力得分
C
l
,
h
C^{l,h}
Cl,h(方法参考文章 A mathematical framework for transformer circuits. ),用来衡量该注意力头在生成过程中是否具备“复制”外部上下文信息的能力。结果如下图。

计算该图和前两张图的 PCC,相关性得分分别为 0.41、0.46,表明幻觉相关的注意力头往往是复制头。
当一个注意力头的复制头得分越高(即越应该起到复制作用),其 ECS 差异越明显,即该头在真实回答中表现得更依赖外部上下文,而在幻觉回答中则表现得不足。
同时,高复制头得分的注意力头,其外部上下文利用情况(ECS)与幻觉标签之间的负相关性更明显,即当这些头未能有效利用外部信息时,幻觉发生的概率更高。
根据上述结果,可以推断出,当这些复制头的 ECS 较低时,有两种可能:它们根本没有关注到正确的外部上下文信息,或者即使关注到了,也没有有效地将这些信息保留或利用起来。
这两种情况都会削弱模型通过复制头来利用外部上下文的能力,从而使模型在生成回答时更多地依赖其内部存储的参数化知识,而缺乏必要的外部验证,导致幻觉产生。
这也解释了为什么我们观察到复制头的 ECS 与幻觉标签呈负相关:即 ECS 越低(外部信息利用越差),幻觉发生的可能性就越大。
(2) LLM 对内部参数化知识的利用与 RAG 幻觉的关系
同上,对比真实响应 (h=0) 和幻觉响应 (h=1) 的外部上下文得分 (PKS)。
观察 LLM 在生成幻觉响应与真实响应时,模型在各层的参数化知识得分 P P P 是否存在差异。
P T l = 1 ∣ D T ∣ ∑ r ∈ D T P r l P H l = 1 ∣ D H ∣ ∑ r ∈ D H P r l P^{l}_T=\frac{1}{|D^T|}\sum_{r\in D^T}P^{l}_r \\ P^{l}_H=\frac{1}{|D^H|}\sum_{r\in D^H}P^{l}_r PTl=∣DT∣1r∈DT∑PrlPHl=∣DH∣1r∈DH∑Prl
计算二者的差值:
Δ
P
l
=
P
H
l
−
E
T
l
\Delta P^{l}=P^{l}_H-E^{l}_T
ΔPl=PHl−ETl
实验结果如下(图中是每层上 Δ P l \Delta P^{l} ΔPl 的统计)

结果显示,在 FFN 模块的后期层中,幻觉回答的参数化知识得分明显高于真实回答,也就是说
Δ
P
l
>
0
\Delta P^{l}>0
ΔPl>0。总体来看,在所有层上幻觉回答的平均参数化知识得分都高于真实回答。
这些结果表明,当 LLM 生成幻觉时,它在后期层(特别是 FFN 模块后期)中引入了更多的参数化知识。也就是说,模型在生成幻觉回答时,更依赖于其内部存储的知识,而这种过度依赖可能会使得生成的回答与外部检索到的信息脱节,从而导致幻觉。
同样,进一步验证内部知识参数化和 RAG 幻觉的相关性,计算幻觉标签 h h h 与 PKS 之间的 PCC 。

FFN 模块的参数化知识得分 (PKS) 在后期层的值更高,并且与幻觉标签 h h h 呈正相关。也就是说,LLM 越依赖后期层 FFN 模块的参数化知识,越容易生成幻觉。
研究人员将这些在后期层中与幻觉高度相关的 FFN 模块称为 “Knowledge FFNs”。
这表明,幻觉的产生与过度依赖知识 FFN 相关。如果 LLM 无法正确利用外部上下文信息,后期层的 FFN 可能会过度填充模型固有的知识,导致幻觉。
RQ2. 是否可以从因果角度验证 RQ1 发现的关系?
在 RQ1 中,研究人员发现:
- 复制头在外部上下文得分低时,无法有效复制外部知识,从而导致幻觉。
- Knowledge FFNs 过度注入参数化知识,导致 LLM 依赖内部知识而非外部上下文,从而增加幻觉的可能性。
为了验证这一发现是否具有因果关系,研究人员使用因果干预 (Causal Intervention) 方法进行实验,过程如下。
对复制头和 Knowledge FFNs 进行人工干预:
- 对复制头施加噪声,破坏其对外部上下文的关注。
- 增强 Knowledge FFNs 对残差流的贡献,使其更依赖内部存储的知识。
同时,研究人员设立对照组:其他注意力头(非复制头)、其他 FFN 模块(非 Knowledge FFNs)。
然后在真实数据集
D
T
D^T
DT 上计算实验组(被干预的 Copying Heads / Knowledge FFNs)和对照组(其他头 / FFNs)两者在负对数似然损失 (NLL) 上的差异。

干预结果表明,实验组在 NLL 变化上的影响显著大于对照组,说明这些组件的作用被干预后,LLM 的生成表现受到显著影响。
结合 4.3 的结果,研究人员得出结论:
知识 FFN 过度注入参数化知识确实会导致幻觉。
复制头负责从外部上下文中提取信息,如果其作用被破坏,LLM 无法有效利用外部知识,从而更容易生成幻觉。
RAG幻觉的发生与两个主要因素有因果关系:
(1)虽然赋值头偶尔会忽略外部环境中的必要知识,但更突出的原因是LLM在生成过程中丢失了赋值头检索到的信息(RQ1-1、RQ2)
(2)LLM内的知识FFN过度将参数知识注入残差流(RQ1-2、RQ2)。
RQ3. 从参数化知识角度分析幻觉行为
本节研究当 LLM 知道或不知道正确答案时,其在生成过程中的幻觉行为,重点关注参数化知识的影响。
构建数据集:
- LLM 知道正确答案的数据集 D ^ T \widehat{D}^T D T:包含 LLM 已掌握的知识,模型可以直接生成准确答案。
- 幻觉数据集 D H D^H DH:包含 LLM 不掌握或容易产生幻觉的知识点。
研究对比 LLM 在这两种情况下的注意力机制和参数化知识利用方式)。

实验结果表明,当 LLM 知道正确答案时:
- 复制头能更准确地捕捉并利用外部知识,确保生成的答案符合真实信息。
- Knowledge FFNs 只会少量添加参数化知识,即更依赖外部检索内容,而非模型内部记忆。
当 LLM 产生幻觉时:
- 复制头的作用下降,导致 LLM 未能有效利用外部检索信息,或者检索到的信息在生成过程中丢失。
- Knowledge FFNs 过度注入参数化知识,导致 LLM 更倾向于凭内部记忆“编造”内容,而不是依赖真实的外部信息。
这一结果与 Wadhwa et al. (2024) 的研究一致,进一步支持了推理的 RAG 幻觉的发生机制。
4. Methods
提出两种方法来检测和缓解 RAG 任务中的幻觉:
- ReDeEP(Regressing Decoupled External Context and Parametric Knowledge):用于检测 LLM 生成中的幻觉(4.1、4.2)
- AARF(Add Attention Reduce FFN):通过重新调整复制头和 Knowledge FFNs 在残差流中的贡献,来减少幻觉(4.3)
4.1 Token-level Hallucination Detection — ReDeEP (Token)
每个 token
t
t
t 的幻觉分数
H
t
(
t
)
H_t(t)
Ht(t) 由参数化知识贡献与外部上下文贡献的加权差决定:
H
t
(
t
)
=
∑
l
∈
F
α
⋅
P
t
l
−
∑
l
,
h
∈
A
β
⋅
E
t
l
,
h
H_t(t)=\sum_{l\in F}\alpha\cdot P^l_t-\sum_{l,h\in A}\beta\cdot E^{l,h}_t
Ht(t)=l∈F∑α⋅Ptl−l,h∈A∑β⋅Etl,h
对于 LLM 生成的一个完整的响应
r
r
r,其总体幻觉分数
H
t
(
r
)
H_t(r)
Ht(r) 定义为所有 token 级幻觉分数的平均值:
H
t
(
r
)
=
1
∣
r
∣
∑
t
∈
r
H
t
(
t
)
H_t(r)=\frac{1}{|r|}\sum_{t\in r}H_t(t)
Ht(r)=∣r∣1t∈r∑Ht(t)
其中,
α
\alpha
α 和
β
\beta
β 是回归系数,用于建模ECS 和 PKS 对幻觉的影响。若 PKS 高而 ECS 低,则该 token 更可能是幻觉。
这是一种基于回归的 token 级幻觉检测方法,可以更精准地识别 LLM 何时产生幻觉
4.2 Token-level Hallucination Detection — ReDeEP (Chunk)
虽然 ReDeEP (Token) 能提供细粒度的检测结果,但它存在两个主要问题:
- 计算开销大:每个 Token 都需要计算 ECS 和参数化知识得分 PKS,计算量较大。
- 缺乏全局上下文考虑:Token-level 检测仅关注单个 token,可能无法充分捕捉 RAG 任务中的上下文依赖关系。
为了解决这些问题,文章又提出 ReDeEP (Chunk),以提高检测效率和整体准确性。
Chunk-level 检测受 RAG 中常见的分块操作启发。在 RAG 任务中,检索到的外部上下文
c
c
c 和 LLM 生成的回答
r
r
r 都可以被划分为多个可管理的小块(chunks):检索到的上下文块
⟨
c
~
i
⟩
i
=
1
N
\langle\widetilde{c}_i\rangle^N_{i=1}
⟨c
i⟩i=1N、LLM生成的响应块
⟨
r
~
j
⟩
j
=
1
N
\langle\widetilde{r}_j\rangle^N_{j=1}
⟨r
j⟩j=1N,
N
N
N 和
M
M
M 分别是检索上下文和生成回答的 chunk 数量。
这样只需要在 chunk 级别计算 ECS 和 PKS。
Chunk-level 注意力权重 由块内注意力全中均值池化算出:
W
i
,
j
l
,
h
=
M
e
a
n
P
o
o
l
i
n
g
(
A
c
~
i
,
r
~
j
l
,
h
)
W^{l,h}_{i,j}=MeanPooling(A^{l,h}_{\widetilde{c}_i,\widetilde{r}_j})
Wi,jl,h=MeanPooling(Ac
i,r
jl,h)
选取注意力最高的 Chunk 对
(
c
~
,
r
~
)
(\widetilde{c},\widetilde{r})
(c
,r
) 作为核心关注对象,然后使用一个 Embedding 模型 (emb) ,且仍然使用了embed向量的余弦相似度来衡量 Chunk 级 ECS,即响应 Chunk 与对应检索 Chunk 之间的相似性:
E
~
r
~
l
,
h
=
e
m
b
(
r
~
)
⋅
e
m
b
(
c
~
)
∣
∣
e
m
b
(
r
~
)
∣
∣
⋅
∣
∣
e
m
b
(
c
~
)
∣
∣
\widetilde{E}^{l,h}_{\widetilde{r}}=\frac{emb(\widetilde{r})\cdot emb(\widetilde{c})}{||emb(\widetilde{r})||\cdot ||emb(\widetilde{c})||}
E
r
l,h=∣∣emb(r
)∣∣⋅∣∣emb(c
)∣∣emb(r
)⋅emb(c
)
Chunk-level ESC 通过对所有chunk取均值,计算得到
E
~
r
l
,
h
=
1
M
∑
r
~
∈
r
E
~
r
~
l
,
h
\widetilde{E}^{l,h}_r=\frac{1}{M}\sum_{\widetilde{r}\in r}\widetilde{E}_{\widetilde{r}}^{l,h}
E
rl,h=M1r
∈r∑E
r
l,h
Chunk-level PSK 同样计算每个chunk内的PSK 均值:
P
~
r
~
l
=
1
∣
r
~
∣
∑
t
∈
r
~
P
t
l
\widetilde{P}_{\widetilde{r}}^l=\frac{1}{|\widetilde{r}|}\sum_{t\in \widetilde{r}}P^l_t
P
r
l=∣r
∣1t∈r
∑Ptl
对所有chunk取均值,计算得到
P
~
r
l
=
1
M
∑
r
~
∈
r
P
~
r
~
l
\widetilde{P}_{r}^l=\frac{1}{M}\sum_{\widetilde{r}\in r}\widetilde{P}^l_{\widetilde{r}}
P
rl=M1r
∈r∑P
r
l
综合 Chunk-level ECS 和 PKS,同样通过高斯回归得到 Chunk-level 幻觉得分:
H
c
(
r
)
=
∑
l
∈
F
α
⋅
P
~
r
l
−
∑
l
,
h
∈
A
β
⋅
E
~
r
l
,
h
H_c(r)=\sum_{l\in F}\alpha\cdot\widetilde{P}_{r}^l-\sum_{l,h\in A}\beta\cdot\widetilde{E}^{l,h}_r
Hc(r)=l∈F∑α⋅P
rl−l,h∈A∑β⋅E
rl,h
4.3 Truthful RAG Generation — AARF
为了减少 RAG 幻觉,本文提出了 AARF 方法,通过干预注意力头和 FFN 模块来减少幻觉的生成,而不需要更新模型参数。
AARF 方法在两阶段进行操作:
1. Token-level 幻觉检测
首先对每个 token t n t_n tn 利用 token-level 幻觉得分 H t ( t n ) H_t(t_n) Ht(tn) 和阈值比较,进行检测,判断某个 token 是否可能产生幻觉。
2. 重新加权注意力头和 FFN 模块对残差流的贡献
在检测到幻觉的 token 后,调整模型的权重,使其更加依赖外部上下文,减少对参数化知识的依赖,从而减少幻觉。具体来说:
- 增加复制头的权重,使模型更加依赖外部上下文信息。
- 减少 Knowledge FFNs 权重,降低模型对内部参数化知识的依赖。
f ( x ) = ∑ l = 1 L ∑ h = 1 H A t t n ^ l , h ( X ≤ n l − 1 ) W U + ∑ l = 1 L F F N ^ l ( x n m i d , l ) W U + x n W U f(x)=\sum^L_{l=1}\sum^H_{h=1}\widehat{Attn}^{l,h}(X_{\leq n}^{l-1})W_U+\sum^L_{l=1}\widehat{FFN}^l(x_n^{mid,l})W_U+x_nW_U f(x)=l=1∑Lh=1∑HAttn l,h(X≤nl−1)WU+l=1∑LFFN l(xnmid,l)WU+xnWU
对于注意力头:
- 如果属于复制头 ( ( l , h ) ∈ A (l,h)\in A (l,h)∈A),则将权重放大: A t t n l , h = α 2 ⋅ A t t n l , h Attn^{l,h}=\alpha_2\cdot Attn^{l,h} Attnl,h=α2⋅Attnl,h,其中 α 2 > 1 \alpha_2>1 α2>1。
- 否则,保持原始的注意力权重
对于 FFN 模块:
- 如果属于 Knowledge FFN ( l ∈ F l\in F l∈F),将其权重减小: F F N l = β 2 ⋅ F F N l FFN^l=\beta_2\cdot FFN^l FFNl=β2⋅FFNl,其中 0 < β 2 < 1 0<\beta_2<1 0<β2<1。
- 否则,保持原始的 FFN 权重

















 833
833

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









