







文章目录
编码
计算机底层存储0/1。编码:一些比特位的值,与文字符号映射出编码表。
计算机如何存储文字呢?
编码表(底层还是0/1)。
1.ascii
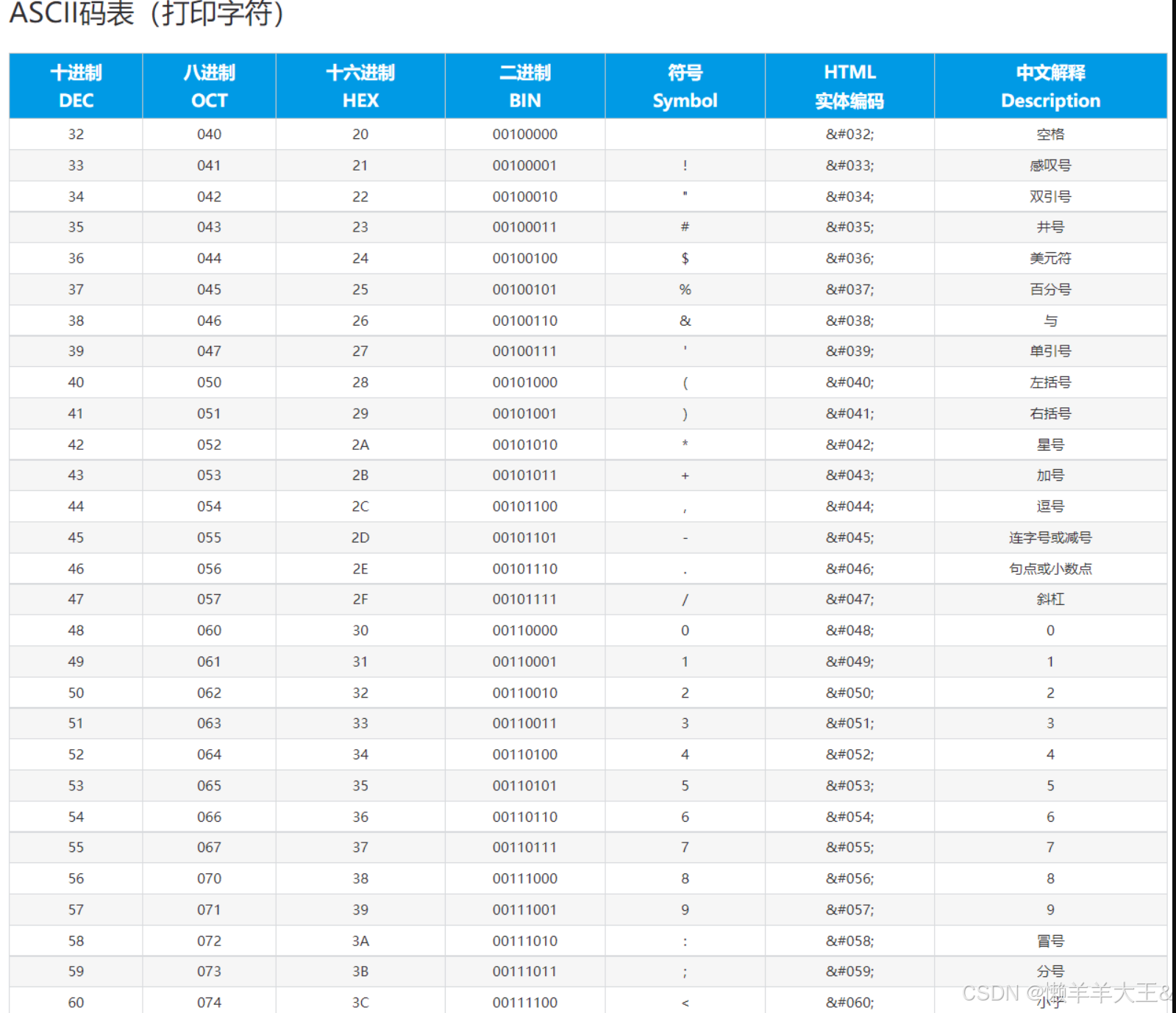
ASCII(American Standard Code for Information Interchange,美国信息互换标准代码)是一套基于拉丁字母的字符编码,共收录了 128 个字符,用一个字节就可以存储,它等同于国际标准 ISO/IEC 646。(如下图)
1byte
-128~127
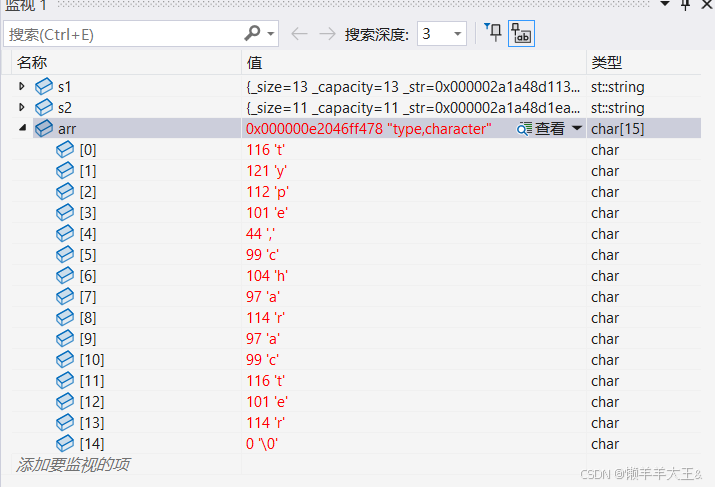
char arr[] = "type,character";
字符串用ascii码在内存中的存放(如下图)
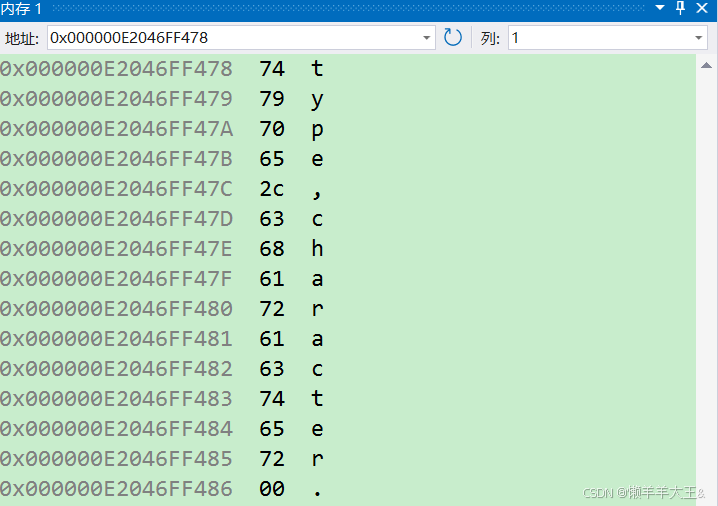
2、unicode(统一码/万国码):为世界上所有的文字和符号提供一个统一且唯一的编码的标准。
万国码又分为3种UTF-32;UTF-16;UTF-8。
2.1、UTF-8(最常用的)
UTF-8: 是一种变长字符编码,被定义为将码点编码为 1 至 4 个字节,具体取决于码点数值中有效二进制位的数量
UTF-8 的编码规则:
(1)对于单字节的符号,字节的第一位设为 0,后面 7 位为这个符号的 Unicode 码。因此对于英语字母,UTF-8 编码和 ASCII 码是相同的, 所以 UTF-8 能兼容 ASCII 编码,这也是互联网普遍采用 UTF-8 的原因之一
(2)对于 n 字节的符号( n > 1),第一个字节的前 n 位都设为 1,第 n + 1 位设为 0,后面字节的前两位一律设为 10 。剩下的没有提及的二进制位,全部为这个符号的 Unicode 码
编码格式(如下图):


2.2 UTF-16
UTF-16 也是一种变长字符编码, 这种编码方式比较特殊, 它将字符编码成 2 字节 或者 4 字节。
具体的编码规则如下:
(1)对于 Unicode 码小于 0x10000 的字符, 使用 2 个字节存储,并且是直接存储 Unicode 码,不用进行编码转换
(2)对于 Unicode 码在 0x10000 和 0x10FFFF 之间的字符,使用 4 个字节存储,这 4 个字节分成前后两部分,每个部分各两个字节,其中,前面两个字节的前 6 位二进制固定为 110110,后面两个字节的前 6 位二进制固定为 110111, 前后部分各剩余 10 位二进制表示符号的 Unicode 码 减去 0x10000 的结果
(3)大于 0x10FFFF 的 Unicode 码无法用 UTF-16 编码
2.3 UTF-32
UTF-32 是固定长度的编码,始终占用 4 个字节,足以容纳所有的 Unicode 字符,所以直接存储 Unicode 码即可,不需要任何编码转换。虽然浪费了空间,但提高了效率。
关于这个三种编码,在c++中的运用
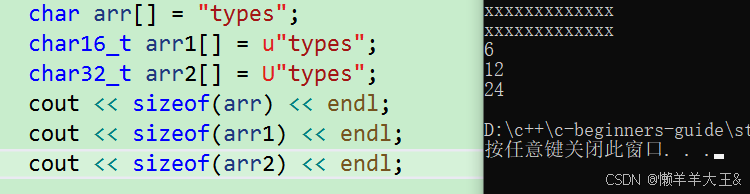
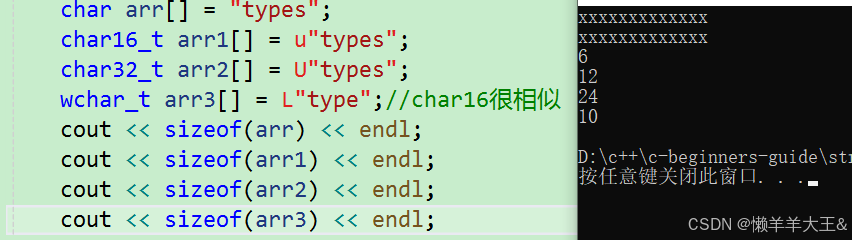
(1)
char arr[] = "types";
char16_t arr1[] = u"types";
char32_t arr2[] = U"types";
cout << sizeof(arr) << endl;
cout << sizeof(arr1) << endl;
cout << sizeof(arr2) << endl;
(2)
char arr[] = "types";
char16_t arr1[] = u"types";
char32_t arr2[] = U"types";
wchar_t arr3[] = L"type";//char16很相似
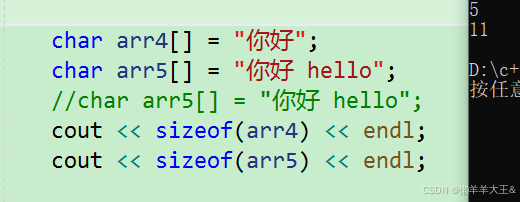
(3)
char arr4[] = "你好";
char arr5[] = "你好 hello";
//char arr5[] = "你好 hello";
cout << sizeof(arr4) << endl;
cout << sizeof(arr5) << endl;
汉字大约占2.5个byte,一个英文站一个byte,两者在utf-8中是兼容的。
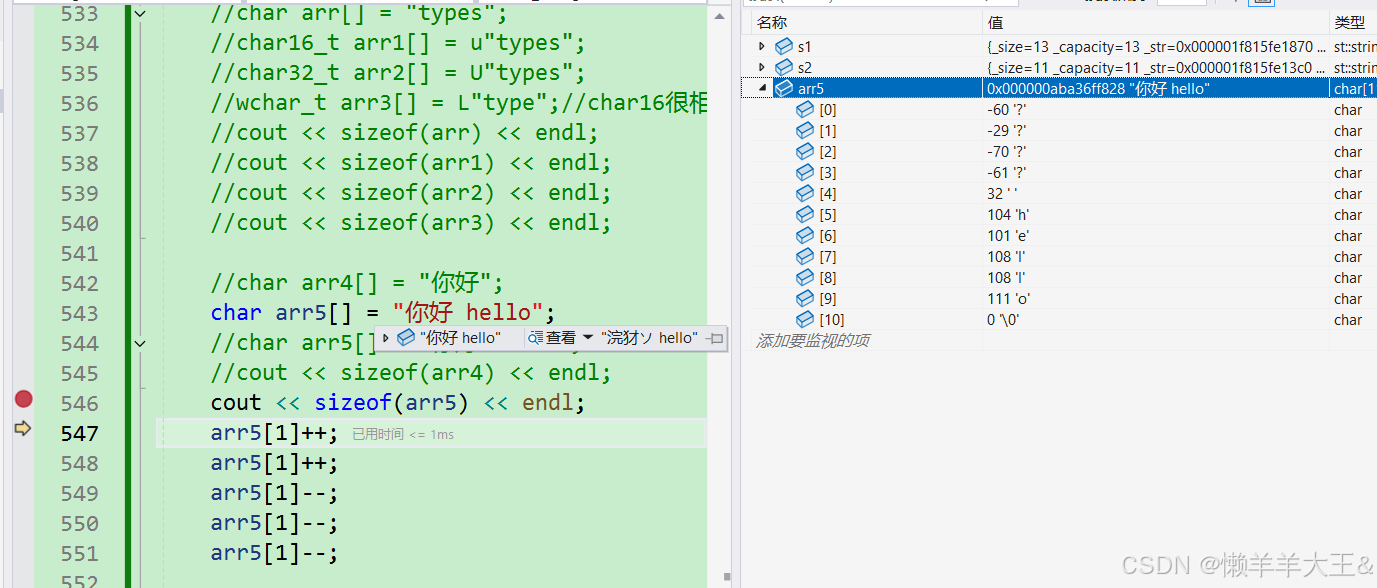
(4)编码不是乱编的,同音词编在一起(eg:禁语)
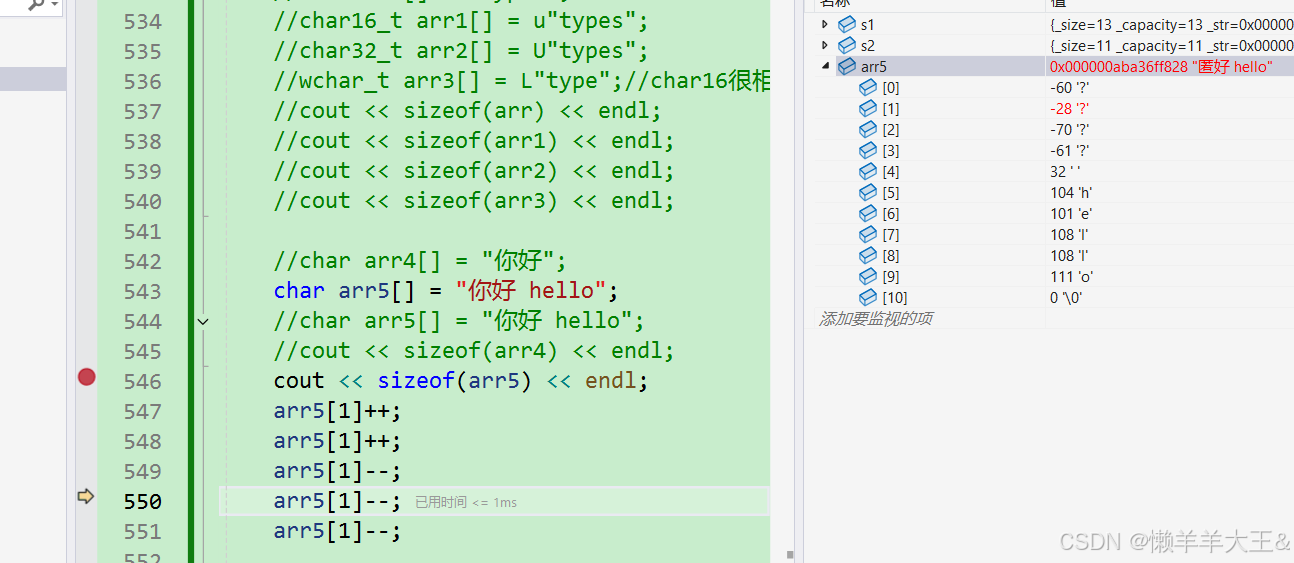
char arr5[] = "你好 hello";
//char arr5[] = "你好 hello";
//cout << sizeof(arr4) << endl;
cout << sizeof(arr5) << endl;
arr5[1]++;
arr5[1]++;
arr5[1]--;
arr5[1]--;
arr5[1]--;
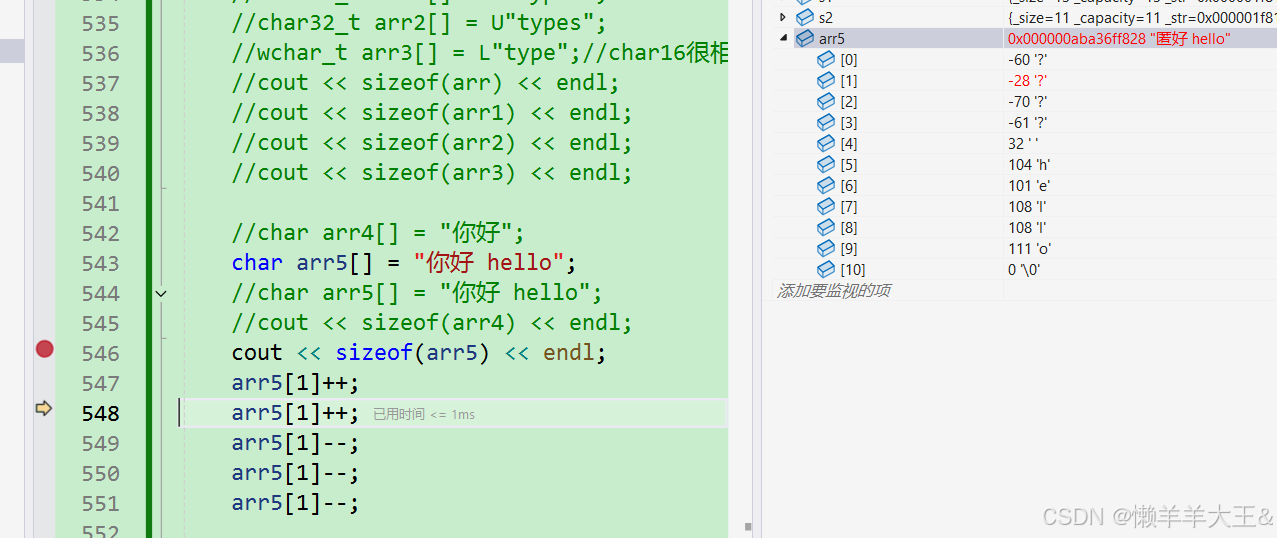
具体调试观察(如下图):
观察‘你’这个字的变化。
总结
以上就是编码的全部内容了,喜欢博主写的内容,可以一键三连。鼓励博主,有什么问题,欢迎在评论区讨论留言。



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











