






 文章详细描述了作者在三次作业中对代码的改进过程,从Parser类的高复杂度问题出发,分析了由于大量调用Lexer,if-else结构和递归解析导致的问题。在重构过程中,作者通过调整类结构,如Expr、Term、CustomFunction等,以及引入新的方法如changeTerm()和removeDerivation(),来降低代码复杂度。同时,文章提到了在处理自定义函数和求导计算时遇到的挑战和解决方案。
文章详细描述了作者在三次作业中对代码的改进过程,从Parser类的高复杂度问题出发,分析了由于大量调用Lexer,if-else结构和递归解析导致的问题。在重构过程中,作者通过调整类结构,如Expr、Term、CustomFunction等,以及引入新的方法如changeTerm()和removeDerivation(),来降低代码复杂度。同时,文章提到了在处理自定义函数和求导计算时遇到的挑战和解决方案。
一、基于度量看代码
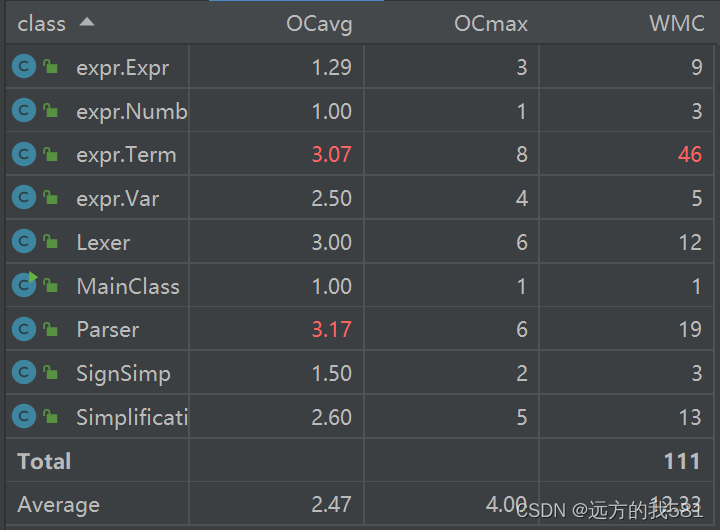
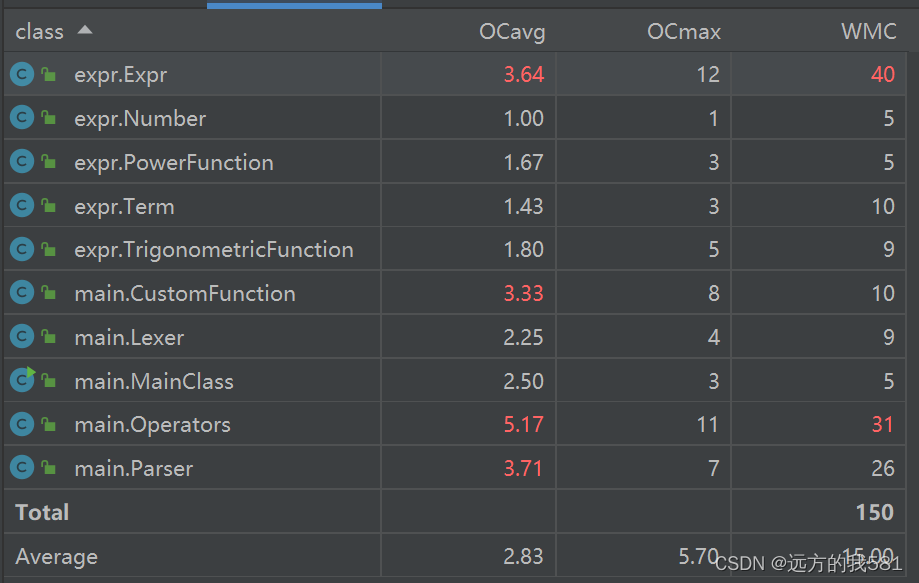
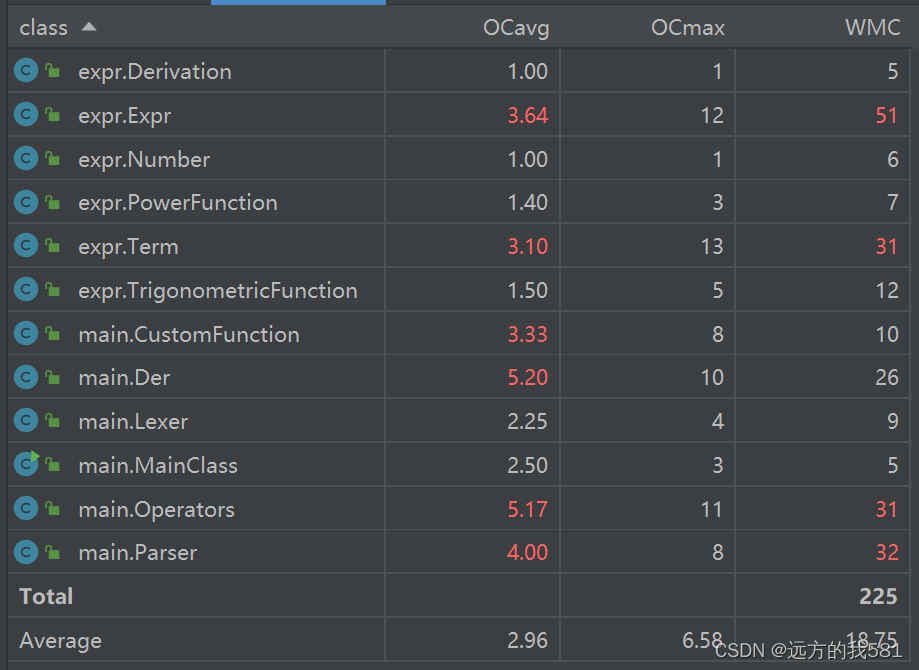
Parser 类的复杂度在三次作业中普遍偏高,原因大概是在Parser中大量调用Lexer中的next()方法,if-else次数较多,同时,在会存在递归解析表达式的情况,所以复杂度较高。
第一次作业我还依然不太了解什么是面向对象,采用的实际上大多数还是面向过程的方式,Term类中代码行数接近200行,仅toString一个方法就接近60行,实现了所有情况的判断,这种判断不仅复杂,而且为第二次作业的重构埋下了祸根。
第二次作业为了实现递归下降解析表达式,我对Expr类进行了较大的改动,其中循环去括号化简的过程使得该类的复杂度明显增大。而对于自定义函数的处理,我采用的是逐个字符扫描并判断的方式,所以可能使得CustomFunction和Operation两个方法的复杂度增大。
第三次作业整体代码相对于第二次变化不大,仅增加了一个求导因子类和一个处理求导因子的类,Der这个类就是处理求导因子的类,在这个类中,相当于需要处理一个新的表达式,所以之前的Expr类等都会用到,其复杂度自然很大。
二、从UML类图中看迭代及重构过程
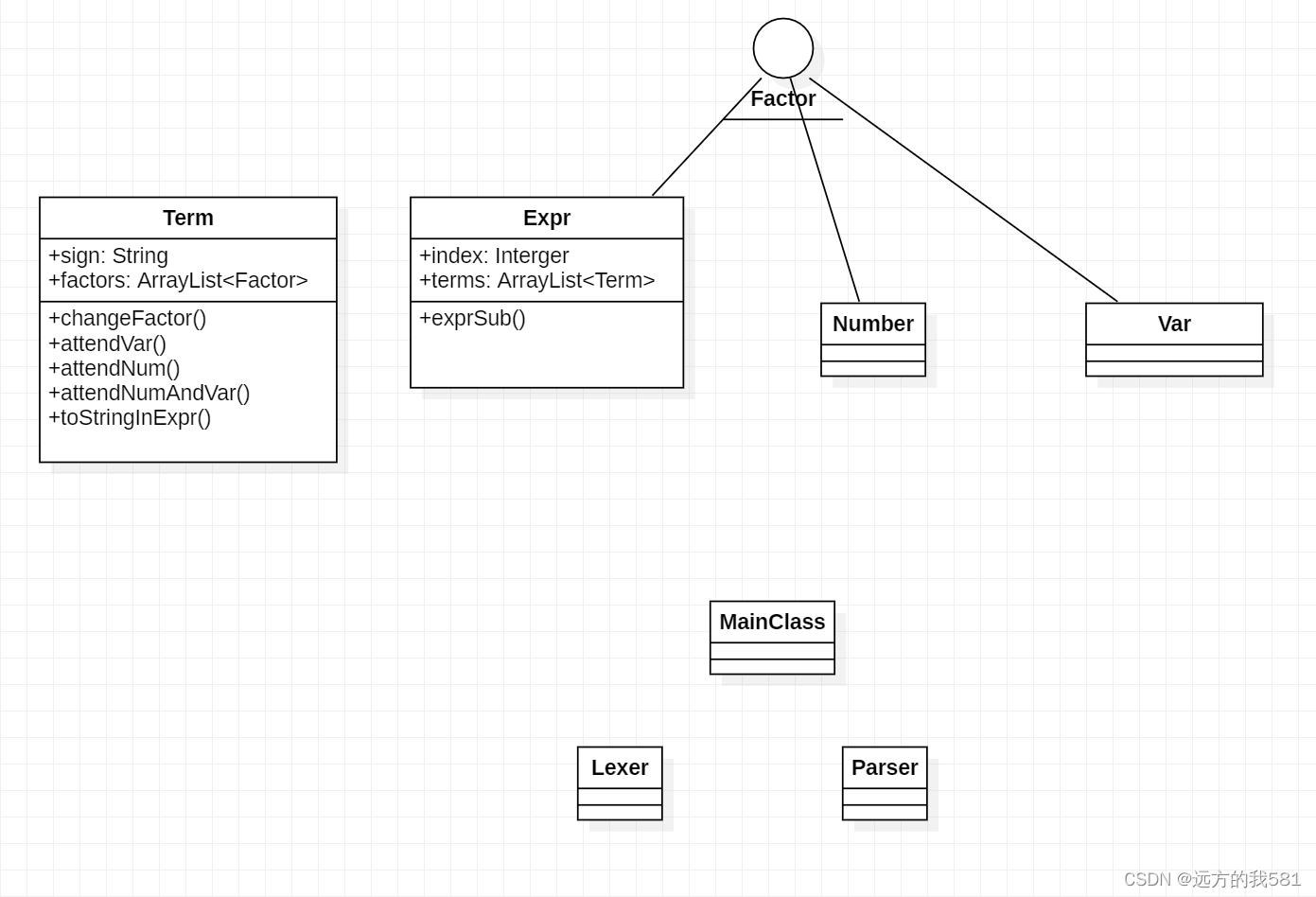
Expr类中的exprSub()方法在这里的主要作用是逐一输出表达式中的各个项;
Term类中的三个attend()方法是对不同类型的因子分别进行输出,changeFactor()方法主要是用于对表达式因子括号去除过程中,能更加方便地改变原来的Term。
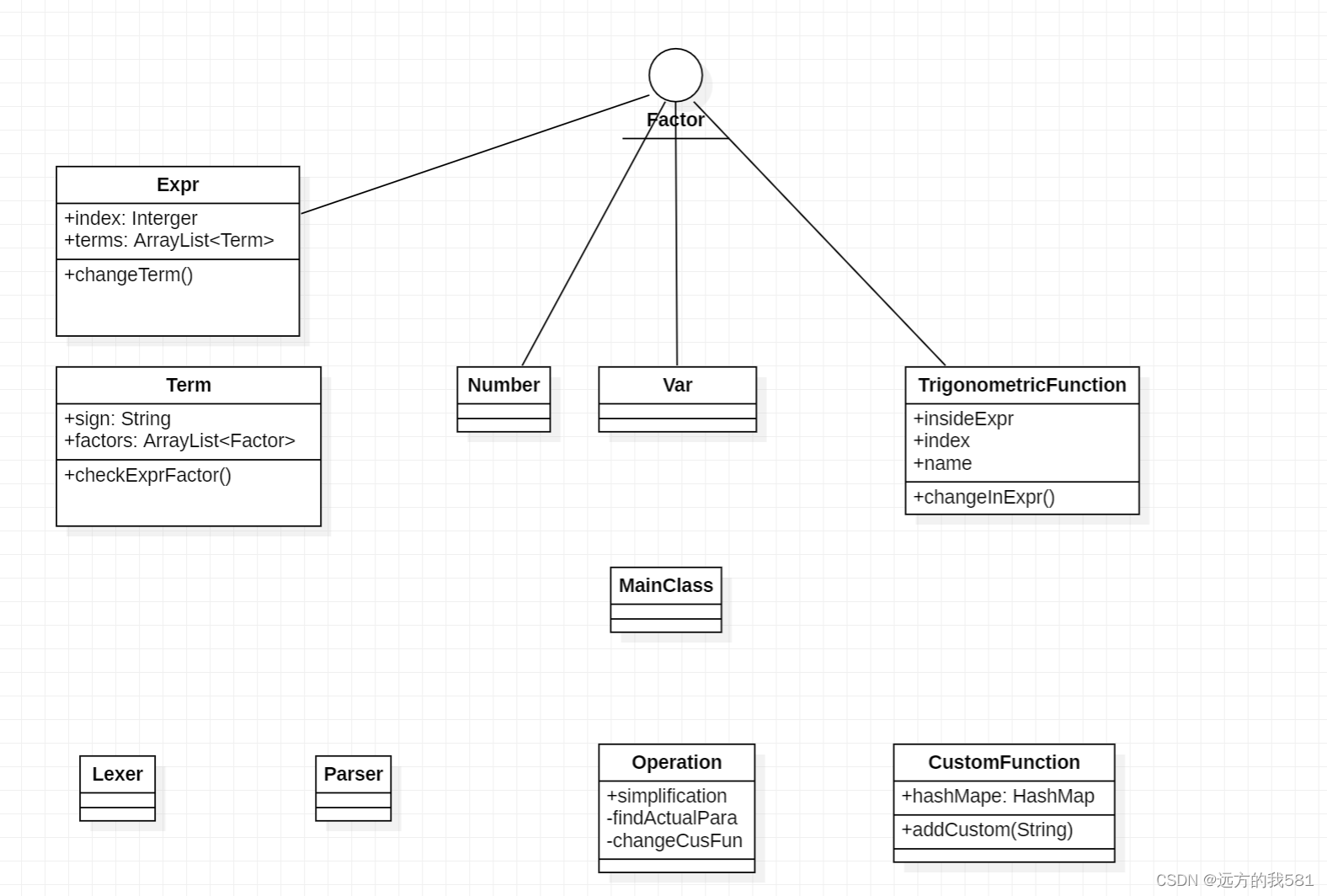
这次作业的主要方法是位于Expr类当中的changeTerm()方法,这个方法的目的在于,循环去掉含有表达式因子的项;
而Term类中的checkExprFactor()方法的作用就在于检查该项中是否含有表达式因子;
新增加的TrigonometricFunction类是三角函数类,内部的方法changeInExpr()的作用是化简三角函数内部的表达式;
Operation类主要的作用是进行自定义函数的替换,其中的findActualPara()方法的作用是找到表达式中的实参,changeCusFun()的作用就是替换自定义函数;
CustomFunction类是自定义函数类,用来存放自定义函数。
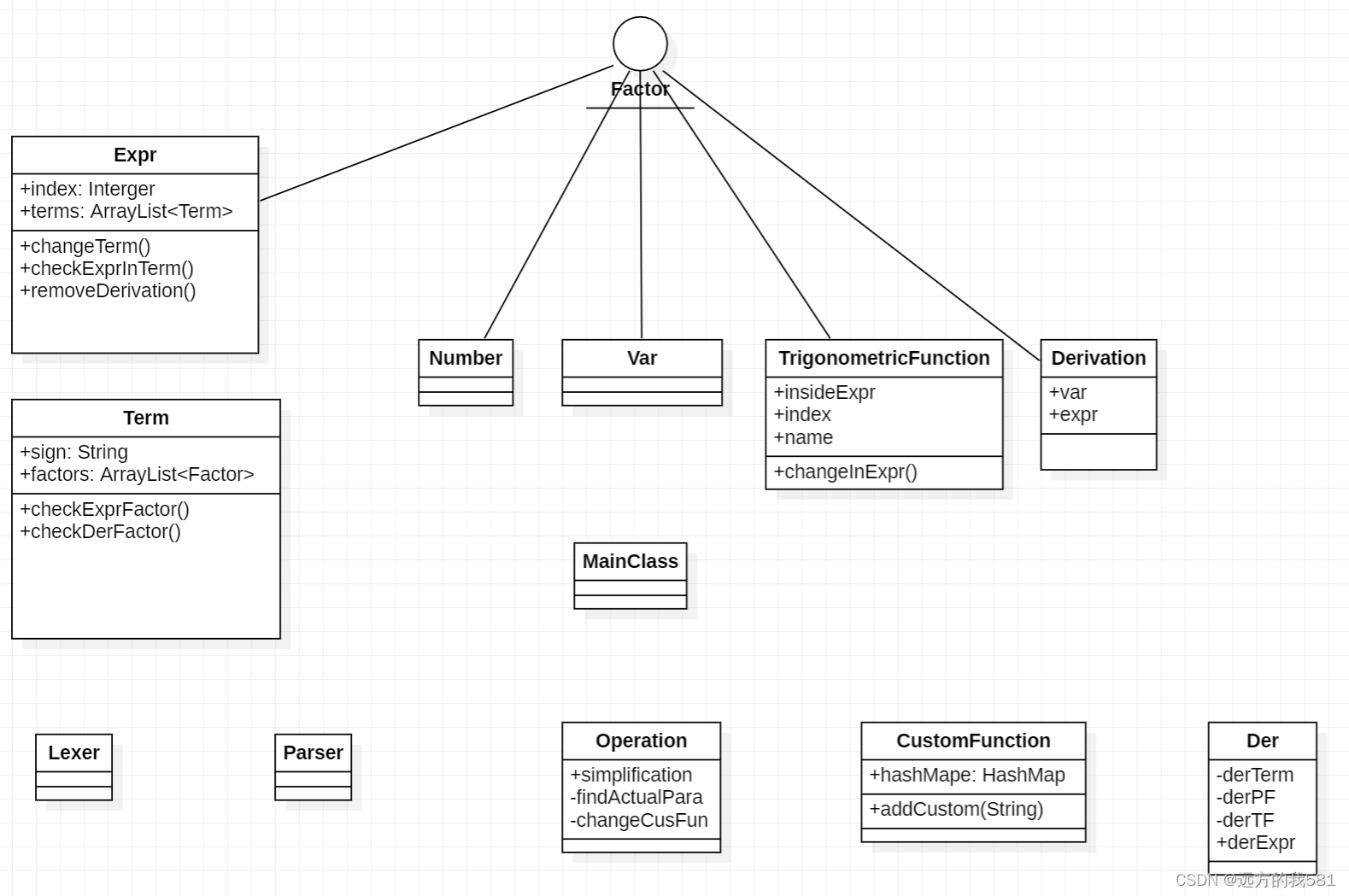
Expr类中新增了两个方法,checkExprInTerm()的作用和之前Term类中的checkExprFactor()方法一样,removeDerivation()方法的作用在于化简表达式中的求导因子;
而要实现化简求导因子的功能,就要用到新增的Der这个类,通过递归下降的方式逐层进行求导。
(属性和方法仅写了比较重要的,通用的方法如toString()等没有写入UML)
可以看出,从第一次作业到第二次作业整个框架的变化还是很大的,原因在于,第二次作业新增了很多新的词法,更主要的是,括号的层数从一层变成了不限制层数,这成了我完成第二次作业的一个主要难点,而从图中可以看出,我第一次作业的主要操作是在Term一个类中进行的:
public String toString() {
classify();
if (exprs.size() != 0) {
for (int i = exprs.size() - 1; i > 0; i--) {
Expr expr1 = exprs.get(i);
Expr expr2 = exprs.get(i - 1);
Expr expr = new Expr();
Iterator<Term> iterator1 = expr1.getTerms().iterator();
for (int j = 0; j < expr1.getTerms().size(); j++) {
Term term1 = iterator1.next();
Iterator<Term> iterator2 = expr2.getTerms().iterator();
for (int k = 0; k < expr2.getTerms().size(); k++) {
Term term2 = iterator2.next();
Term term = new Term();
Iterator<Factor> factorIterator1 = term1.factors.iterator();
Iterator<Factor> factorIterator2 = term2.factors.iterator();
changeFactor(term, factorIterator1, factorIterator2);
judgeSign(term1, term2, term);
expr.addTerm(term);
}
}
exprs.remove(i);
exprs.remove(i - 1);
exprs.add(i - 1, expr);
}
exprs.get(0).setIndex(1);
}
StringBuilder sb = new StringBuilder();
if (!exprs.isEmpty()) {
for (Term value : exprs.get(0).getTerms()) {
String sign;
value.classify();
sign = judgeSign2(value);
sb.append(sign);
attendNumAndVar(sb);
sb.append(value.toStringInExpr());
}
} else {
String sign;
int numbersNum = getNumbersNum();
sign = judgeSign3(numbersNum);
sb.append(this.sign);
attendNum(sb);
if (numbers.size() > 0 && vars.size() > 0) {
sb.append("*");
}
attendVar(sb);
}
return sb.toString();
}在Term类的toString方法中我将所有的因子逐一输出,遇到表达式因子就展开,但只能展开一次;同时,对于符号的判断也比较复杂。
第二次作业中,我将对于括号的处理放在了Expr这个类当中,通过changeTerm()这个方法进行处理:
public void changeTerm() {
ArrayList<Term> newTerms = new ArrayList<>();
for (Term term: terms) {
if (term.checkExprFactor()) {
//在此处将该项展开为若干项,需要注意新项的符号!!!
ArrayList<Number> numbers = new ArrayList<>();
ArrayList<PowerFunction> powerFunctions = new ArrayList<>();
ArrayList<TrigonometricFunction> trigonometricFunctions = new ArrayList<>();
ArrayList<Expr> exprs = new ArrayList<>();
classify(term, numbers, powerFunctions, trigonometricFunctions, exprs);
//然后参考第一次作业
for (int i = exprs.size() - 1; i > 0; i--) {
Expr expr1 = exprs.get(i);
Expr expr2 = exprs.get(i - 1);
Expr expr = new Expr();
for (int j = 0; j < expr1.getTerms().size(); j++) {
Term term1 = expr1.getTerms().get(j);
for (int k = 0; k < expr2.getTerms().size(); k++) {
Term term2 = expr2.getTerms().get(k);
Term term3 = new Term();
Iterator<Factor> factorIterator1 = term1.getFactors().iterator();
Iterator<Factor> factorIterator2 = term2.getFactors().iterator();
changeFactor(term3, factorIterator1, factorIterator2);
judgeSign(term1, term2, term3);
expr.addTerm(term3);
}
}
exprs.remove(i);
exprs.remove(i - 1);
exprs.add(i - 1, expr);
}
if (exprs.get(0).getTerms().size() == 0) {
System.out.println("exprs.get(0) == 0 !!!!!!!!!");
}
//加入新的项
//System.out.println("exprs.get(0) -> " + exprs.get(0).getTerms());
Expr simExpr = exprs.get(0);
for (int i = 0; i < simExpr.getTerms().size(); i++) {
Term newTerm = new Term();
newTerm.setSign(judgeSign2(term.getSign(),simExpr.getTerms().get(i).getSign()));
for (Number number : numbers) {
newTerm.addFactor(number);
}
for (PowerFunction powerFunction : powerFunctions) {
newTerm.addFactor(powerFunction);
}
for (TrigonometricFunction trigonometricFunction : trigonometricFunctions) {
newTerm.addFactor(trigonometricFunction);
}
for (int j = 0; j < simExpr.getTerms().get(i).getFactors().size(); j++) {
newTerm.addFactor(simExpr.getTerms().get(i).getFactors().get(j));
}
newTerms.add(newTerm);
}
} else {
newTerms.add(term);
}
}
this.terms = newTerms;
//System.out.println("New expr terms -> " + terms);
}在第三次作业中,我的改动较少,主要是在changeTerm()方法中调用了removeDerivation()方法,对求导因子进行化简,而化简求导因子的主要方法还是写在Der这个类当中。
public void changeTerm() {
//在化简表达式因子之前先对求导因子进行化简
removeDerivation();
//System.out.println(this.getTerms());
ArrayList<Term> newTerms = new ArrayList<>();
for (Term term: terms) {
if (term.checkExprFactor()) {
//………private void removeDerivation() {
ArrayList<Term> newTerms1 = new ArrayList<>();
for (Term term : terms) { //逐项遍历
if (term.checkDerFactor()) { //该项有求导因子
Term newTerm1 = new Term();
for (Factor factor: term.getFactors()) {
if (factor.getClass().equals(Derivation.class)) { //找到该求导因子,就求导
Derivation derivation = (Derivation) factor;
Der der = new Der(derivation.getVar());
Expr exprFromDer = der.derExpr(derivation.getExpr());
newTerm1.addFactor(exprFromDer);
} else { //不是求导因子就直接加入新项
newTerm1.addFactor(factor);
}
}
newTerm1.setSign(term.getSign());
newTerms1.add(newTerm1);
} else {
newTerms1.add(term);
}
}
this.terms = newTerms1;
} public Expr derExpr(String expr) { //返回一个求完导之后的表达式
Lexer lexer = new Lexer(expr);
Parser parser = new Parser(lexer);
Expr oldExpr = parser.parseExpr(); //需要进行求导的表达式,已经去掉了非必要的括号;
Expr newExpr = new Expr();
//对oldExpr的每一个含有var的项分别求导后加入到新的表达式中;
if (!expr.contains(var)) { //整个表达式都不含有var
Number number = new Number();
number.setSign("+");
number.setNum(BigInteger.ZERO);
Term term = new Term();
term.setSign("+");
term.addFactor(number);
newExpr.addTerm(term);
} else {
for (Term term : oldExpr.getTerms()) { //遍历所有的项
if (term.toString().contains(var)) { //在这个项中能找到变量,就对项进行求导,否则导数为0则不需要添加;
derTerm(term, newExpr);
}
}
}
if (newExpr.getTerms().isEmpty()) {
Number number = new Number();
number.setSign("+");
number.setNum(BigInteger.ZERO);
Term term = new Term();
term.setSign("+");
term.addFactor(number);
newExpr.addTerm(term);
}
return newExpr;
}以上就是我三次作业的迭代及重构过程。
三、第一次作业到第二次作业重构的原因
我感觉第一次作业比较混乱的原因大致有两个,一是面向对象的基础确实很薄弱,对Java语言本身就不是很熟悉,二是整体结构没有设计好,急于为了追求快写完而忽略了设计的过程。
四、第二次到第三次的迭代
在处理函数嵌套的问题上,我采用的是把新输入的函数表达式就看成是第二次作业中最终的表达式进行处理,把处理好的表达式再存入到自定义函数中去,这样一来,就可以直接使用第二次作业的东西了。至于求导的方法,在前面已经说的差不多了,就不重复啰嗦了。
五、没有优化却依旧Bug不断的问题分析及反思
第一次作业是因为整体设计思路混乱,导致了符号判断出现错误,具体表现在,忽视了出现在“*”后面的负的常数因子的符号,导致整个项的符号都是错的;
第二次作业的bug比较多,一是自定义函数在处理的时候忽视了空白符中的制表符,二是在自定义函数的替换时,出现了错误,没有将实参套括号后再传入,导致运算顺序出错;
第三次作业的bug就比较简单,是因为再写对三角函数求导的时候,当三角函数的指数大于1时,忘记对内部的表达式求导了。
总体来说,一次作业比一次作业的bug更容易修复,因为代码的结构更加的清晰,当知道了测试数据后,哪里出现问题,出现了什么问题都比较清晰。总是出bug的原因有一部分是思路的不清晰,结构的不严谨(比如第一次,第二次),也有向第三次一样的,纯属因为不仔细。
六、“买彩票似”的Hack及对评测机的向往
我Hack别人都是根据形式化表述手动构造数据,尽量构造一些特殊的数据,尽量覆盖表达式中所有的内容,但这依然是凭借“运气”,希望下次作业,我也能用一个更高级的办法进行数据的测试。















 1099
1099











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









