







论文信息:
#期刊:Q2区 《International Journal of Data Science and Analytics》2023(Springer)出版、文章中加粗标绿的技术后续需要深入学习、加粗标红的是该文idea的关键点、下划线的也是一些该文值得注意的点。
绿标:倾斜的内容是对论文中提及内容的补充
论文内容:
摘要
推荐系统是现代用户体验不可或缺的一部分。他们了解用户的偏好,并通过创建个性化推荐来帮助用户发现有意义的内容。随着政府法规的出台和用户隐私意识的增强,如今获取所需数据是一项具有挑战性的任务。联邦学习是分布式机器学习的一种新方法,它可以保护用户的隐私。在联合学习中,参与的同伴一起训练一个全球模型,但个人数据永远不会离开设备或筒仓。最近,推荐系统和联邦学习的结合在研究界引起了越来越大的兴趣。创建了一种新的推荐类型——联邦推荐系统(federated recommender system)。本调查全面概述了该领域的当前研究,包括联邦算法、体系结构设计和联邦设置中的隐私机制。并指出了当前面临的挑战和未来值得进一步研究的方向。
Keywords Recommender systems · Federated learning · Federated recommender systems
一、介绍
推荐系统(RSs)今天是现代信息门户(portals)、流媒体网站和电子商务解决方案(ecommerce solutions)的一个组成部分。追溯到信息检索(information retrieval, IR)领域[1],用户通过信息获取、预订假期、消费多媒体内容或购买物品。像亚马逊这样的电子商务网站列出了超过1200万种可供用户选择的产品,甚至Netflix上的14000部电影和电视剧也给客户带来了决策挑战。RSs提供了一种机制,通过对符合用户偏好和需求的项目提出建议,支持用户进行导航和决策。他们分析用户的行为并生成配置文件,这些配置文件将用户的兴趣映射到称为用户配置文件(user profile)的内部表示。此外,RSs创建的个性化推荐通过推动销售和为消费者引入新内容提供了显著的业务效益。亚马逊大约30%的观看量来自于推荐[2],Netflix超过80%的观看活动是由个性化推荐创造的[3]。
RSs捕获用户行为、社会关系或用户的人口统计数据以生成推荐。这种收集可能对用户的隐私构成严重威胁。虽然这种系统的参与者愿意分享个人数据以改进推荐,但他们同时担心系统收集了过多的信息,甚至将其用于恶意目的(malicious purposes)[4]。这一事实的概念被称为个性化隐私“悖论(paradox)”[5]、“权衡(trade-off)”[6]和“困境(dilemma)”[7],同时使个性化和隐私的愿望相互冲突。用户对隐私方面的意识,例如他当前的位置或身份,被认为是开发RSs的最大挑战之一[8]。
在此类系统中,对隐私的感知或实际威胁来自三个不同的实体(entities)[9]:系统可以捕获个人数据,这些数据不需要用于其直接操作或进行定向广告。其他用户可以利用推荐来推断目标用户的私人信息。外部同行(External peers)可以访问存储的个人数据或干扰(interfere)用户与系统之间的交互。
意识到用户对其数据的敏感性,政府和基金会开始实施关于个人数据如何被捕获以及如何处理的法规和政策。作为最早的指导方针之一,经济合作与发展组织(OECD)于20世纪80年代初发布了数据最小化原则,该原则自那时以来一直在不断更新[10]。虽然该指导方针仅具有建议意义,但欧盟在2017年决定了欧盟委员会的《通用数据保护条例》(GDPR)[11],该条例今天使隐私成为数字世界中的一项人权。这些法规和法律必须遵守,使得隐私意识在现代RS中的实施成为强制性的[12]。
出于这些隐私问题的考虑,谷歌引入了一种分散的机器学习方法,称为联邦学习(FL)[13]。它的架构保证训练数据保留在个人设备上,而用户协同训练共享模型。客户端只将模型更新发送到中心实例,聚合特定的结果并将该模型的全局模型或更新传输回参与者。这个步骤重复几次,直到达到理想的精度,或者系统不断适应用户的交互。虽然模型的训练计算量很大,不能由第一批个人设备执行,但今天的旗舰智能手机(flagship smartphones)可以训练具有数百万个参数的深度神经网络[14]。
当涉及到隐私时,FL是一种很有前途的方法,因为它的设计已经捕获了RS中对隐私的不同技术考虑。个性化直接发生在设备上,并且只有对行为的解释才能以模型的形式在同行(peers)之间共享。没有直接的个人数据离开实现行为混淆(behavior obfuscation)的设备,可以通过添加噪声来确保(安全)。此外,参与设备的性能可能足以(be sufficient enough to)在不牺牲可伸缩性(sacrificing scalability)的情况下将加密方法(cryptographic methods)应用于该过程。
除了为这种系统的用户提供隐私方面的好处外,FL还使不同的定制(custom-tailored)在线服务提供商之间的协作成为可能,例如Netflix或Amazon等多媒体内容的在线流媒体解决方案。这些公司捕捉用户操作,如浏览(browsing)商品(item)库、交互模式和观看行为。因此,客户数据非常宝贵[15],可以为公司的战略决策(strategic decisions)提供见解和支持(insights and support)[16],而这些公司的价值与其用户群的价值直接相关,这使得他们不愿意与竞争对手分享这些数据。
用户在本地训练了个人资料,但为全球模型做出了贡献,用户可以隐藏自己的偏好,但仍然受益于群体智慧(Wisdom of the Crowd)[17]。同时,提供商可以保留捕获的交互数据,而无需与竞争对手共享用户交互并从中获利。
从第一次实现和FL在隐私挑战方面的有希望的好处开始,很明显,研究社区开始研究将FL合并(incorporation)到RSs中。这种组合被称为联邦推荐系统(federalrecommendsystem, FedRec)[18]。与传统的单片RSs相反,FedRecs通过将数据分散到本地设备或数据孤岛来确保用户的隐私,并通过对数据和通信应用隐私方法来保护数据安全。
到目前为止,在FedRec背景下进行的研究很少[19],但FL显示出其解决捕获敏感个人数据的隐私问题的潜力。第一项调查由Yang等人发表[18]。它展示了FedRec领域的早期工作,并定义了不同类型的FedRec体系结构的分类(taxonomy)。Alamgir等人[20]发表了一项新的调查,其中概述了最新的算法,它们的应用领域,特别是它们使用的数据集。
这项调查提供了近年来联邦RS的最新发展和RS的典型分类的全面概述。在这项调查中,作者重点介绍了联邦RS发展的每个算法方面和不同类型的隐私保证方法(privacy-assuring methods)的最受欢迎的论文。
本文的结构如下。在第二节中,简要介绍了FL的训练过程。在此基础上,介绍了FedRec的研究现状及其RS方法的类型、体系结构和各种隐私保证方法。最后提出了FedRecs未来可能的研究方向。
二、联邦学习
在传统的集中式深度学习(DL)方法中,设备收集的数据在基于云的服务器或数据中心上集中上传和处理。模型被更新,然后使用这些数据(例如,图像、位置信息或传感器值)在参与者之间进行分发。现在,当涉及到用户数据时,这种方法不再可持续(sustainable)。
FL是一种保护隐私的机器学习范式,允许参与者协作和分布式地训练机器学习模型,将任何训练数据暴露给训练伙伴[21](这里应该是作者说错了,应该是不会暴露,这是FL默认的setting)。机器学习(ML)的训练模型需要大量数据。然而,公司有充分的理由对他们的数据保密,私人用户对披露他们的个人数据变得敏感,比如他们的位置和浏览行为。由于公民对隐私的担忧和前面提到的政府法规,数据收集在今天是一项极具挑战性的任务。理论上可以用于下一代RS的数据被锁定在数据筒仓或个人设备中,无法用于培训。FL可以解决这一基本挑战,并允许对现代RS模型进行私人/安全培训。
2.1Federated learning setup
普通FL的设置通常由三个主要部分组成:在训练/操作过程中拟合的ML模型,中央管理实例(instance,)和任意(arbitrary)数量的参与同行(peers):
- ML模型:机器学习模型是一组算法及其参数,它们被安排在一个特定的结构中,以根据收集到的数据计算预测。虽然算法和体系结构是预先定义的,但必须在模型的迭代训练期间调整参数,以便模型创建所需质量的预测。人工神经网络(ann)和矩阵分解(MF)方法已经成功地应用于联邦环境中。
- Central instance:中心实例(也就是服务器)管理peers(也就是客户端)之间的协调(coordination)。它为当前的培训轮选择一个客户子集,这些客户将在下一轮(in the upcoming round)中做出贡献。这些活动客户端将它们对当前模型的更新传输到中心实例,中心实例将这些信息合并到新模型中,然后将其分发到网络中。所有其他客户端保持被动状态(passive),直到中央实例在未来一轮中选择它们参与。
- Participating peers : 每个参与的peers都使用其本地模型对其数据执行推断。如果该peer处于活动状态,它将使用其本地数据执行预定义数量的训练步骤。完成该任务后,客户端将其整个调整后的模型或更新(例如梯度)发送回中心实例,在中心实例中收集所有信息并将其聚合到新模型中。peers可以是任何可以连接到中心实例并具有足够的计算能力来训练模型的设备。最常见的客户机是个人设备,如手机,但它们也可以是专用服务器。
2.2联邦学习训练过程
在FL中,模型的训练不是集中进行的。每个选定的客户端都有自己的训练数据和网络访问权限,并对模型进行训练。这个过程以轮为单位进行组织,每轮有三个独立的阶段(separate phases):
- 模型分发从中心实例到参与的客户端
- 模型训练,由选定的客户端在本地执行,并将更新发送到中心实例
- 模型聚合通过中心实例进行
2.2.1 阶段1:模型分发
中心实例通过从可用的peers中选择一定数量的参与客户端来开始每一轮新的培训。每个被选中的peers将使用其本地可用的数据进行培训。通常,peers的集合是随机生成的。但是,中心实例可以根据连接的可靠性、贡献质量或以前(former)参与轮次等进一步信息来选择客户机。一旦确定了对等点,中心实例就会将当前模型传输给它们。中心实例可以请求对整个模型进行更新,也可以为它们提供更新掩码并只请求部分更新。此外,中心实例可以向peers提供本地数据的进一步元信息,例如已经从新闻文章中派生的主题。
2.2.2 阶段2:模型训练
对于每个选定的客户端,模型的训练阶段包括两个步骤:首先,用本地可用的数据拟合最近的模型,然后,将更新的数据传输回中心实例。一旦选择一个peer参与当前的训练轮并接收当前模型、其参数和可选元数据,它就开始在自己的本地可用数据上拟合模型。这种方法有两个进一步的含义:首先,除了本地信息外,活跃的peers还需要所有必需的数据来帮助训练。这意味着中心实例提供公开可用的信息,或者客户端必须执行数据预处理。由于数据预处理会对以后的模型性能产生巨大的(enormous)影响,因此预处理管道必须对所有客户机都是相同的。其次,peers还负责管理他们的培训、验证和测试数据,特别是在操作期间捕获新信息时。因此,peers需要足够的计算和存储资源来对数据进行预处理和存储,从而为模型训练做出贡献。
一旦客户端完成其本地训练,它将请求的更新发送回中央实例,以便将其更新聚合到其他对等体的模型。由于存在这种情况(For that exists),两种不同的设计选项——返回整个模型(FedAVG)[21]或返回梯度(FedSGD)[22]——具有不同的优缺点。虽然用FedA VG训练的模型比FedSGD[13]具有更高的精度,但在最新的最先进的模型上更新数百万个浮点参数,如BERT[23],很容易超过可用的网络带宽、存储或计算资源。FedSGD仅传输梯度,如果环境需要一定尺寸的模型,则必须接受精度损失。
PS:我个人感觉上述有关模型参数和梯度上传的说法值得商榷,以下是我的见解:
- 传输模型参数通常更为简单直接,通信开销也较低;传输梯度的开销可能更大,尤其是在需要频繁上传的情况下。理由:由于梯度的维度与模型参数一致,传输梯度的通信开销与传输模型参数相当,但在有些场景下,由于额外的计算,梯度可能包含更多信息。
- 传输梯度在优化和灵活性上具有一定优势,因为它允许服务器在全局更新过程中更加精细地调整策略。理由:①传输模型参数:服务器直接聚合这些模型参数。在非独立同分布(non-IID)数据的场景下,客户端上传的模型可能存在较大差异,影响全局模型的收敛效率。②传输梯度:通过传输梯度,可以更加灵活地控制模型的更新过程。服务器可以通过聚合梯度来更新全局模型,相比直接传输模型,这种方式可能对收敛速度更敏感,尤其是在调整学习率和梯度的聚合策略时。
- 综合考虑:如果重点在于减少通信开销和简化实现,且本地数据较为独立同分布,那么传输模型参数更为合适。如果需要更高的优化灵活性,或者要应对数据非独立同分布的挑战,且通信开销不是主要瓶颈,那么传输梯度可能是更好的选择,尤其是在引入梯度剪枝、差分隐私等技术时优势更为明显。
2.2.3 阶段3:模型聚合
一旦中央实例收集了当前轮中参与节点的所有本地更新,它就会将这些信息合并到模型的全局更新中。根据网络的设计决策,中心实例有两种更新模型的选择:将收集到的模型权重平均到一个新模型中(FedA VG)[21],或将客户端的传输梯度平均(FedSGD)[22],并将新梯度应用于存储的全局模型。在集中式深度学习中,标准的随机梯度下降(SGD)已被自适应优化算法广泛取代,最近也被移植到FL中[24]。
三、联邦推荐系统(Federated recommender systems)
Yang等人首先提出(coin)了联邦推荐系统(federalrecommendsystem, FedRec)的概念(notion)[18]。它是各种RS方法中的一种与FL方法的组合,以实现分散和隐私保证的RS。在FedRec中,peers(用户或公司)将其数据保存在本地,例如交互模式、评级或用户配置文件。在RS的培训和操作期间,他们不会与同行peers共享此类信息。此外,每一方通常都可以访问有关项目的公开信息,例如它们的描述、特征或类别。本节以下内容以FedRec的算法和架构为基础,并以FedRec中的不同隐私方法为结尾。每个小节都展示了FedRec中最近工作的各种示例,并在实际场景中使用相应的方法。本节最后简要概述了FedRecs可以应用的领域,并介绍了这些领域最流行的数据集。
3.1联邦推荐系统的推荐方法
在为用户计算推荐值时,应用了各种技术。它们在所需的投入和处理方式方面存在根本差异。每种方法都有不同的优点和缺点。因此,每种技术都有其最适合的特定领域。所有方法都有一个共同点,即创建描述单个用户的概要文件(profile)。然而,在特定类型的RS中,该profile的建模和开发方式有所不同。根据RS的操作方法,RS可分为两种类型[25]:
- 基于内容的过滤(Content-based filtering,CBF): 其中,系统找到与过去喜欢的项目相似的项目[26]。
- 协同过滤(Collaborative filtering,CF):在这种情况下,系统只根据同伴的行为生成推荐,而不考虑物品的特征[27]
此外,CBF和CF可以合并为一个RS,称为混合型RS[28]。FedRecs可以被视为CF系统,因为几个peers通常在共享模型中协作训练。FedRecs的一些实现是混合RSs,其中包含和分析项目的过程,从而用比简单交互模式更有意义的信息丰富用户配置文件。表1概述了FedRecs中实现的不同算法。
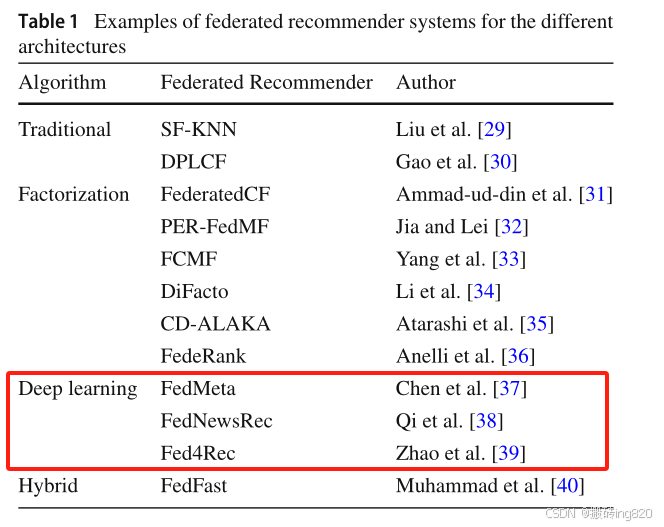
(这篇综述论文是23年的,所以暂时以22年论文截至。上述[37][38][39]最新也就到22年。所以最新的之后看这三篇论文的“被引论文”来找)
3.1.1 传统方法
传统RS的最初实现是基于IR领域的统计方法[1],分别用统计矩阵计算用户项目之间的相似性。在CBF中,提取的特征(the extracted features)形成一个项目(item)描述向量(describing vector),并衍生出与用户最感兴趣的特征具有相同结构的用户向量最相似的项目(在基于内容的推荐系统中,提取的特征构成了一个物品描述向量,这些物品是通过与用户具有相同结构的向量进行比较得出的,其中包含用户最感兴趣的特征)。基于cf的系统应用相同的相似性度量,但比较了用户的配置文件,RS推荐相似用户喜欢的项目。这些方法应用聚类方法,如k近邻[41]来创建相似项目的邻域,分别是用户。
Federated clustering 在多种应用中,一个众所周知的传统方法是k近邻算法。Liu等[29]使用这种方法对推荐进行评级。最近邻分别根据评级的余弦相似度和欧几里得距离来定义。邻居越近,权重越大,然后计算一个总和,衡量每个邻居对下一个评级的重要性。评分高的项目之后可以作为推荐。
Gao等人提供了另一种简单的协同过滤方法[30]。在这种方法中,peers只将它们的扰动数据(pertubated data)发送到中心实例,只有在服务器上进行模型训练,然后将建议发送回客户端。服务器计算从客户端发送的所有已知项目的相似度,类似于传统的item-toitem CF[42]。对于推荐,服务器计算邻域(neighborhood)并向客户端广播具有相似值的项目。
3.1.2 Factorization-based approaches 基于分解的方法
后来,RS在Netflix的竞赛中[43]取得了巨大的成功,他们应用了分解方法[44]。他们推导(derive)出系统中用于计算推荐的items的密集低维表示。因子分解技术以主题建模方法(topic modeling approaches)的形式捕获文档(documents)的隐藏语义特征(hidden semantic features),例如概率潜在语义索引(pLSI)[45]或潜在狄利let分配(LDA)[46]。这些主题是从简单的关键字层次抽象出来的,对内容有更高层次的理解,允许根据文档的实际语义对文档进行比较[47]。由于用户评分和交互在CF中形成了一个大而稀疏的矩阵(a large but sparse matrix),因此该方法被转移到RS中。潜在因素(Latent factors)类似地表示物品特征和用户偏好[48]。Koren将这一概念细化为MF svd++,并提交给Netflix竞赛[49]。因子分解机(FMs)是前面提到的MF的扩展,它的发展是为了解决稀疏数据的问题[50]。他们将支持向量机(svm)与分解方法结合起来,将用户的评分以及用户与系统交互的进一步上下文信息映射到同一空间中。特别是当用户的可用数据很少时,它们的性能优于传统方法。
Federated factorization approaches MF是RS最常用的方法之一。在联邦设置中,最早实现的方法之一是在每个客户端上全局训练item矩阵和局部训练用户矩阵[31]。中心实例首先初始化全局项目矩阵,所有客户端下载该矩阵并初始化其用户特征矩阵。客户机更新它们的用户矩阵,并将派生的梯度返回给中心实例。然后,它将所有梯度聚合并更新全局模型,并对已经部分训练的模型重复此过程。在本系统中,个人资料不会离开个人设备。通过对传输数据应用加密解决方案,进一步扩展了隐私保证[32,33]。
【31】:
Question 1:怎么结合利用服务器保存并更新的物品因子矩阵(Y)和用户设备本地更新的用户因子矩阵(X)进行推荐呢?
Answer: 评分预测值=X*Y



Q2:每个用户如何更新自己的用户因子矩阵(X)呢?
Answer:更新X就是Loss=(P-) 【评分预测值
=X*Y】Y是服务器下发的,再由随机梯度下降,便可更新用户因子矩阵X




Q3:服务器如何利用上传的梯度信息更新物品因子矩阵(Y)?
Answer: 根据客户端上传的梯度f(u,i)计算得到的梯度,然后更新





回到综述原文:
DiFacto[34]提出了一种联邦方法FM。由于数据通常非常稀疏(sparse)且具有高维数high dimensionality(特征数),作者引入了数据的嵌入embedding来降低decrease维数dimension.。这样,模型的收敛性更好converges better,计算也更简单。Li等人使用异步asynchronous随机stochastic梯度下降gradient descent来解决tackle联邦通信问题。每个客户端在本地计算模型,并将梯度顺序sequentially发送到服务器,聚合并发送回来。
sequentially:客户端不会同时向服务器发送梯度,而是一个接一个地进行梯度传递和更新。这种按顺序的通信方式可能是为了避免服务器处理多个客户端同时发送的梯度带来的冲突或负载
为了解决比实际数据点高得多的维度问题,[35]利用因式分解机器中的ANOVA内核[51]将数据映射到较低维度的特征空间并计算推荐。在这里,每个客户机计算其本地ANOVA内核的值并将其发送给目标方。目标方升级其模型并生成推荐。
ANOVA内核:在诸如推荐系统等应用中,数据集可能包含高维特征,而ANOVA核通过将数据映射到低维空间,帮助模型提取重要的特征,忽略冗余信息。这样可以减少数据维度,同时保留有用的交互信息。ANOVA核通过对特征组合进行多项式分解(通常是二阶或高阶),从而更精确地捕捉特征交互的贡献。它能根据特征的贡献度分离出各个维度的影响,这样可以为模型提供更加细腻的特征表示。ANOVA核通过引入特征之间的非线性交互,提升了模型的表达能力,尤其在推荐系统或其他需要捕捉复杂交互特征的任务中具有优势。它通过特征降维的方式,将数据映射到一个更具代表性的空间,从而提高模型的预测效果。
FedeRank[36]使用MF方法基于隐式评级生成推荐。无论用户是否与特定项目交互,每个用户的设备都保存着他的个人数据。此外,每个客户端都有自己的本地用户特征矩阵,而中心实例保存item的特征矩阵。每个客户端生成自己的local元组训练集,元组由未知和已经交互的items组成。在每个training epoch中,使用元组的随机分数fraction来更新本地用户矩阵。然后,在将更新发送到中心实例之前,客户端决定他的哪些本地信息应该贡献给全局项目特征矩阵。
3.1.3深度学习方法
最近,RSs开始使用深度学习方法对CBF中的item进行预处理,或者在CF方法中捕捉用户与其首选项目preferred items之间的非线性关系[52]。卷积神经网络(cnn)[53]分析图像,能够在被分析图像的实际内容层面上找到定义特征,从而定义它们之间的相似度度量。例如,作为一种方法,我们选择了CNN来实现一个时尚推荐,它使用服装图像来提出风格和颜色匹配的配饰[54]。在CF中存在应用DL方法的各种可能性。一种方法是用人工神经网络ANN模拟分解方法mimic factorization methods 。由于MF发现了用户users和项目items特征的低维表示,这一事实可以被视为编码问题encoding problem,使得自动编码器autoencoders(ae)[55]——一种独特的人工神经网络架构——适合于这一挑战。AutoRec[56]是一个RS,它在推荐任务上部署了这样的AE。V -国家自编码器(V - AEs)具有与AE相似的架构结构,但相反,用于重建reconstruct输入数据的概率分布probabilistic distribution[57]。它们优于Outperforming传统的AE,在推荐精度方面被认为是最先进的state of the art[58]。此外,递归神经网络(RNN),如门控递归单元(GRU)[59],作为DL模型的架构顺序,已成功应用于基于会话的推荐系统(sbrs),其中交互顺序对下一个用户的决策有很强的影响,并用于创建一个全面的概要[60]。
Federated DL-based approaches 物品item推荐可以看作是一个分类任务[61]。该模型预测一个类,表示与该物品item相关的可能评级。每个用户训练一个由多个前馈层组成的局部深度神经网络。该神经网络的输入是所有可用的用户信息all available user information、物品关联item associations和交互interactions。计算出的梯度将被发送到包含相同神经网络副本的中心实例。中心实例使用所有传入梯度更新模型,并将副本发送回peers。
Polato等人提出的系统将集中式VAE转移到联邦设置中,在那里它获得了与集中式V AE方法相似的性能[62]。此外,新的联邦系统保留了原始实现中的dropout layer。Dropout层是一种防止过拟合的现代方法[63]。除了防止过拟合,这些层对输入信息实现了数据扰动,混淆了用户信息,进一步增强了FL的隐私保障[64]。
基于初始化的元学习算法,如MAML[65],对于泛化和快速适应新任务特别有用,使其非常适合推荐任务。在MAML中,对模型进行了制定,以便通过元训练方法首先用许多任务(为用户生成推荐)训练参数化算法。然后,只需要进行一些更新,就可以在本地使其适应个性化的新任务(用户)。可以从MAML的角度研究联邦设置,其中中心实例管理全局算法。然后,每个客户端在其私有数据上本地调整特定于任务的算法[37]。该系统用实际工业数据对移动服务推荐任务进行了评估,对用户来说收敛速度更快,并且比普通的ANN算法在移动推荐任务中获得更高的准确率。
FedNewsRec是一种利用深度学习的方法。骨干架构分为两个不同的模型[38]。第一个是items.的特征提取。它由嵌入层mbedding layer、卷积层convolutional layer和注意层attention layer组成。以FedNewsRec新闻为例,该模型从单词中提取特征。第二个模型提取用户user特征。该模型的输入是用户的物品历史记录。该模型由序列感知层sequence-aware layers组成。注意层attention layer和GRU层(GRU layer)是并行的,分别创建长期和短期用户嵌入。两个输出最终在最后一个注意层合并。每个客户端在本地计算项目特征item feature和用户特征嵌入user feature embeddings,并将梯度发送给服务器。中心实例聚合传入的梯度并更新全局模型,然后将其传输回对等节点。
Fed4Rec是一个网页推荐系统,它将gru与MAML方法相结合[39]。考虑到用户的最后一次交互,作者使用RNN对每个用户的页面访问序列进行建模。通用模型是用公开可用的概要文件初始化的,每个客户机训练其本地模型以使其适应用户的首选项。
3.1.4不同ML方法的组合
此外,存在分解方法 factorization approaches和深度学习方法的组合来平衡每个缺点shortcoming。神经矩阵分解(Neural matrix factorization, NeuMF)基于传统的MF,但重构原始矩阵的标量积被多层感知器(multilayer perceptron, MLP)所取代,该感知器能够捕捉用户与物品之间的非线性关系[66]。DeepFM将FM与MLP相结合,并进行并行训练[67]。
Combining FMs with DL :Khalil Muhammad等人对[66]引入的转基因食品进行了扩展,将其用于联邦环境[40]。该方法结合了MF和ANNs。与常见的MF方法一样,两个随机初始化矩阵生成评级矩阵rating matrix:用户特征矩阵user feature matrix和物品特征矩阵item feature matrix。对分解矩阵decomposed matrices进行矩阵乘法,得到一个近似的评级矩阵。这个矩阵将被压平,并被推入一个完全连接的神经网络。通过这种方法,可以从MF中学习线性依赖关系,也可以从人工神经网络中学习非线性依赖关系。为了降低通信成本,该方法的范例不使用所有客户端的所有梯度,而只使用所有用户的采样量。服务器接收梯度,更新全局模型,并将新模型发送给所有客户端。
3.2联邦推荐系统的架构
FL可分为水平FL(horizontal FL)、垂直FL(vertical FL)和转移FL( transfer FL)三种[68]。在水平FL或基于样本的FL中,每个分布式数据具有相同的特征空间,但peers具有不同的样本。在垂直FL或基于特征的FL中,peers共享相同的样本,但具有不同的特征空间。在迁移FL中,不同的peers既没有共同的特征,也没有共同的样本。每个参与者都必须使用小数据重叠作为不同孤岛之间的桥梁来扣除缺失的信息。在FedRecs中应用FL的情况下,特征空间表示item,样本空间表示FedRecs的用户。
给定的用例use case、领域domain、可用数据源available data sources或RS的目标定义了所需的体系结构。如果所有的items都属于相同的domain,或者用相同的信息结构structure描述,并且每个peer只属于一个人,那么horizontal FL将是合适的体系结构决策。假设RS的目标是从不同的数据源生成跨领域的推荐。在这种情况下,transfer FL是这种FedRec的匹配架构。表2概述了应用这些体系结构的不同系统。
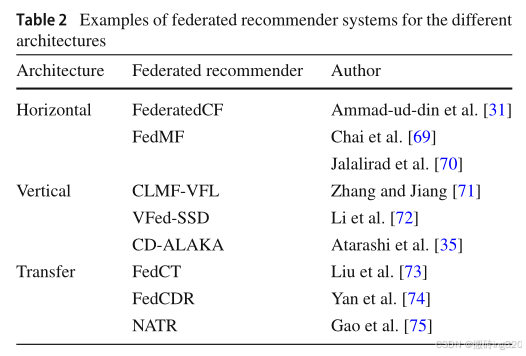
3.2.1横向联合推荐系统
水平FL是目前研究FedRec最常用的方法。peers共享一个相同的item空间。所有客户端上的项目属于同一domain,并且具有相同的形状(shape)。例如,它们具有相同维度(dimension)和语义的特征(semantic meaning)嵌入(feature embeddings)。每个客户机的用户集是不同的。它可以扩展到每个客户端只代表一个用户。在其操作中,横向FedRecs与参与的同行数量一起缩放(scales with),因为推荐是在本地计算的。横向FedRec的一个例子是来自单个公司的移动电影RS,其中每个用户在其个人设备上都有自己的用户配置文件,并且所有用户都可以访问相同的电影集合。
由于MF方法在RS中的广泛使用(widespread)以及它们易于分离用户数据和参与者分布,因此将MF应用于水平FedRec的联邦设置是很自然的。mad-ud-din等人创建了联邦MF的首批实现之一[31]。中心实例存储public item feature matrix,每轮将其传递给peers,每个peer额外持有其用户特征向量(user feature vector)。这两个部分的特征用通用的ALS方法进行细化(refined),每轮之后,peers将它们的局部项矩阵(local item matrix)细化梯度(refining gradients)发送到中心实例进行聚合(aggregation)。然后,中央实例更新全局项目特征矩阵(global item feature matrix),然后将其分发给下一轮的peers。通过对其传输梯度应用摄动方法(perturbation methods),可以进一步保证(assured)peers的隐私性[69]。
在Jalalirad等人的工作中,每个客户端都有一个本地模型,中心实例只管理训练轮和返回梯度的聚合[70]。首先,客户端在每个历元中进行局部训练,并将其梯度传递给中心实例。它聚合它们并将结果返回给对等节点。这一步骤将不断重复,直到达到预定义的全局历元数。然后,每个客户端将全局梯度应用于其模型(没有全局模型,单独是全局梯度去更新局部模型),并使用其本地数据对其进行重新训练。与对所有节点使用相同全局模型的解决方案相比,该局部改进步骤提高了预测精度。
3.2.2垂直联合推荐系统Vertical federated recommender systems
垂直FedRec描述了跨多个数据孤岛分布的异构数据上的联邦模型训练。peers具有相同的用户集,但每个节点提供不同的推荐项目或关于不同项目特性的详细信息。它是将这些特征聚集在一个隐私保证过程中,以协作地创建一个包含来自各方信息的模型的过程。这些方可以是共享相同用户群的不同域的RS。这种系统的一个例子是来自不同领域的两家公司的共享RS:一家负责服装,一家负责配饰。他们拥有相同的用户基础,包括客户的姓名和地址,并且希望创建一个新的组合RS,以获得更好的用户体验,而不共享客户的详细信息。
CLMF-VFL模型[71]采用垂直(Vertical)FedRec。该体系结构的主干是联邦矩阵分解方法(federated matrix factorization approach)。每个客户端都有自己的项目特征矩阵和用户特征矩阵。每个客户端的项目特征矩阵在任何时候都不会被共享,但用户特征矩阵是与所有用户交换的。
Li等人[72]声称广告模型包含的未标记数据多于标记数据。因此,他们应用垂直分割学习[76],基本假设标记数据来自源域,并用于在自监督中将知识转移到未标记的目标域。每个用户都有两个用于训练的小模型,一个用于标记数据,另一个用于未标记数据。这两个模型将被聚合以计算输出。带有用户相关信息的标记数据留在客户端,仅在本地用于训练标记的模型。未标记的模型处理与项目相关的数据,该模型的输出将与所有用户共享,以生成协作模型。
在[35]中,使用了高阶分解机。ANOVA核是根据所有特征信息计算并分发到所有客户端的。个人资料将由客户保管,不会被分享。
3.2.3迁移(Transfer)联邦推荐系统
Transfer FedRecs用于这样的场景:节点的数据不仅在用户空间中不同,而且在项目空间中也不同。例如,来自不同业务和地点的两家公司希望在不泄露其私人数据的情况下构建新的共享RS。由于地理距离的关系,两家公司的用户集只有很小的重叠(intersection)。由于它们的领域fields不同,它们所提供的项只存在一个很小的特征空间交集。在这种情况下,通过迁移学习技术学习两个空间之间的共同表示[77]。有限的常见用户/项目user/item组合形成了一个桥梁bridge,仅从一侧获取功能来生成推荐。
FedCT基于VAE方法生成跨域推荐模型cross-domain recommendation[73]。每个领域在每个个人设备上都有一个独立的编码器-解码器对encoder–decoder pair ,由peers.协作训练。用户对每个域都有自己的表示用户编码。他所谓的个人空间充当了连接的桥梁,收集、学习、转移和汇总他在各个领域的信息。对于建议,使用了相应的局部域模型,并且表明FedCT有效地解决了用户与尚未探索的域交互时的冷启动挑战。
PS:冷启动挑战:

FedCDR使用GMF实现图书和电影的跨域FedCDR[74]。每个域都按照分解方法对peers上的用户项矩阵进行分解。只有peers参与每个特定领域的那些培训轮,它们具有该领域的本地可用交互数据。这样,客户端就可以协作地训练全局模型,而无需共享本地交互数据和创建本地用户嵌入。在模型收敛后,它们被扰动并发送到中心实例,中心实例使用这些嵌入来训练基于mlp的模型进行嵌入转换。在该模型的训练过程中,那些在不同领域进行交互的用户充当了源领域和目标领域之间的信息桥梁。基于该模型,系统首先从用户已经交互的域中转换用户嵌入。然后,使用转换后的嵌入从目标域向它们推荐项目。作者使用来自不同领域的数据集进行的评估表明,与基线算法相比,FedCDR需要更少的桥接用户来为冷启动用户生成高质量的推荐[78]。
3.3联邦推荐系统中的隐私方法
解决RS中的隐私挑战的第一次尝试使用匿名化技术anonymization techniques来隐藏特定用户的个人数据,例如发生信息泄漏leak。不能从这些数据集推断出任何个人信息。尽管如此,随着Netflix挑战赛数据集的发布,链接外部数据源以获得详细信息的研究得到了普及。Narayanan等人通过将匿名评分映射到IMDB电影评分,可以重新识别该数据集中99%的用户[79],显示出这种方法的弱点。即使没有外部数据,也可以创建仅由用户行为组成的指纹,以超过40%的准确率在数百万用户中识别特定的人[80,81]。
因此,需要架构或算法的解决方案来确保用户在系统层面的隐私,而这类信息很难甚至不可能公开[82]。Kobsa等人[83]在他们的分类法中确定了三种不同的方法来获得用户的隐私保护:
- Client-side personalization客户端个性化
- Usage data perturbation such as differential privacy 使用数据扰动,如差异隐私
- Usage of cryptographic methods such as homomorphic encryption 使用密码方法,如同态加密
随着用户对隐私敏感性的提高,通过引入基于用户的过滤器user-based filters[84],扩展了以前描述的不同隐私技术的分类。这使得系统的参与者可以定义他们自己的规则,以及他们愿意与哪一方分享什么信息。然而,先前的研究发现,用户对隐私的陈述意见与他们捕获的行为之间存在严重的不一致[85],这使得该方法对一般有保障的系统隐私存在风险。
客户端个性化[86]描述了一系列常见的不同方法:用户配置文件在其个人设备上进行本地保存和管理,该设备携带所有个性化。它可以分为两类[87]:客户端执行推荐生成,例如,使用用户定义的规则[88],而不与外部实例通信,或者个性化代码在客户端运行。因此,客户端在没有中央实例[89]或使用中央管理实例[90]来计算推荐的情况下交换数据。在这种情况下,信息可以分为个人资料信息,这些信息永远不会离开个人设备,以及关于项目特征的公开非敏感信息,例如分布式矩阵分解MF[91]。
FedRecs已经在其架构设计中融入了客户端个性化的方法。进一步的隐私保护可以通过使用诸如安全多方计算(SMC)或同态加密(HE)之类的加密方法来实现,也可以通过正则化技术或使用差分隐私(DP)机制添加随机噪声来扭曲更新。表3概述了应用这些隐私保护机制的不同方法和系统。

3.3.1密码方法Cryptographic approaches
基于密码学的解决方案在敏感数据上应用HE等加密机制,或者使参与者能够在不共享其私有数据的情况下共同计算结果。这些方法以一定的计算开销避免了个人信息的泄露。在RS背景下对该领域寻找隐私保护解决方案的研究显示了其在各个领域的潜力[99]。
同态加密Homomorphic encryption HE[100,101],如Pallier加密方案[102],可以直接对密文进行算术运算,而不需要解密,如果对明文进行计算,则会得到等效的解。然而,这些类型的操作需要更高的内存和处理时间成本以及通信开销,使得在具有大量参与者或需要实时处理的环境中部署此类方法变得复杂[103]。
例如,HE用于对item嵌入embeddings进行加密[69]或对矩阵分解方法的user嵌入embeddings进行加密[71]。这种方法的应用在与其他用户或第三方共享数据的同时保护了隐私。HE使诸如矩阵乘法之类的数学运算能够直接作用于加密数据[92]。这些加密不会干扰矩阵的数据,并且系统仍然可以处理稀疏数据。
安全多方计算Secure multiparty computation SMC使具有私有数据的客户端能够一起计算结果,而无需向彼此透露其输入[104]。它确保了唯一可以推断的信息是聚合结果的信息,使得不可能将数据点与特定参与者联系起来,这意味着除了大量参与者子集的聚合之外,任何一方都无法了解任何其他信息。然而,不能保证防止特定信息的泄漏,因此,SMC必须依靠其他机制来应对这些挑战。
[93]的作者声称使用SMC以比使用HE更少的计算成本实现隐私保护聚合。在这种方法中,模型的计算权值被SMC掩盖,并且可以在保持隐私约束的情况下进行分布。[94]中介绍了CF方法中的多个SMC协议。项目和评级预测在不忽视隐私或预测准确性的情况下完成。
3.3.2数据扰动方法Data pertubation approaches
数据扰动方法[105]在数据或模型更新中以可控的方式添加了特定类型的失真,从而避免了将个人数据重构为特定的统计不确定性。由于这些方法通常不对输入数据应用计算密集型操作(就加密而言),因此它们的主要优点是效率高,从而支持可扩展的系统。然而,增加的噪声以推荐的准确性换取隐私,导致推荐的质量较差。
DP[106]最初是为集中式设置设计的,但最近也应用于分布式设置[107]。对于每个查询,中心实例都使用应用了预定义随机化的结果进行应答。这种扭曲可以在一定程度上从答案中去除,产生与正确答案相似的结果,但经过足够的改变,无法推断出任何私人信息。与前面提到的加密方法相比,DP以结果的准确性和可扩展性为代价,因为噪声可以在计算上有效地应用[108]。DP可分为集中式、本地式和分布式DP三类[109]。
Centralized DP 联邦学习中的集中式DP假设了一个值得信赖的中心实例,这在将聚合模型发送给客户端之前为其添加了噪声,从而确保了记录级别的隐私[110]。假设一个可信的中心实例会造成单点故障,在不可信和分布式的场景中,首选本地或分布式DP[103,111]。然而,该方法是为许多参与者设计的,因此不能对少数客户实现令人满意的准确性。
PrivRec是一个FedRec,它利用集中式DP来保护参与者免受隐私泄露攻击[95]。每个peer将更新后的本地模型发送到中心实例,使用fedavg算法将本地更新聚合到新的全局模型。在将新的全局模型发送回peers之前,系统将噪声添加到新的全局模型中。这可以保护FedRec免受恶意客户端的攻击,恶意客户端使用高级攻击,如成员推理攻击[112]来披露训练数据中特定数据样本的存在。
Local DP 本地DP[113]创建了更强的隐私保证,因为模型更新等数据在发送到中心实例之前在客户端节点本地受到干扰[114]。由于与中央DP相比,所施加的噪声要高得多[115],因此安全性的准确性大大降低。虽然中心的噪声随着参与者的数量保持不变,但随着参与者数量的增加,它需要变得更强,这使得它不适用于数百万个节点。过去可以证明,为了从计算中删除一个不可信的中心实例并确保每个参与者的隐私,这种差距是必要的[116]。
局部DP用于多种科学方法。在[96]中,Local DP用于离散CF环境中每个用户的梯度。此外,在像[97]这样的系统中,每个代理都相互联系,本地DP被用来保护隐私。Chen等人[98]生成随机矩阵,并使用它们在客户端转换数据。给出了不同的变换,都是完全填充局部DP。
Distributed DP 分布式DP将噪声的添加与SMC等加密方法相结合[117]。它消除了对可信中心实例的需求,同时无论客户端节点的数量如何,都需要更少且持续的噪声。不幸的是,只有单个更新的总和是私有的,因为每个客户机的噪声不足以防止信息泄露。相反,SMC保护客户端不被披露,但允许访问聚合结果。因此,结合这两种方法可以避免对中心实例的信任需求,同时保持客户端数据的私密性[118]。
FCMF利用了分布式DP[33]。作者在这项工作中推荐使用MF算法的项目。用户只共享项目特征矩阵,不共享直接用户信息。然而,从这个矩阵中读取信息是可能的。服务器端采用HE对数据进行加密,防止信息泄露。所有用户都从服务器获得公钥和加密数据,以训练他们的私有模型。由于用户获得了加密密钥来处理数据,因此他们仍然可以详细说明有关这些数据的相关信息。在这种情况下,服务器通过添加一定分布的噪声来扰动数据。
3.4联邦推荐系统的数据集和应用
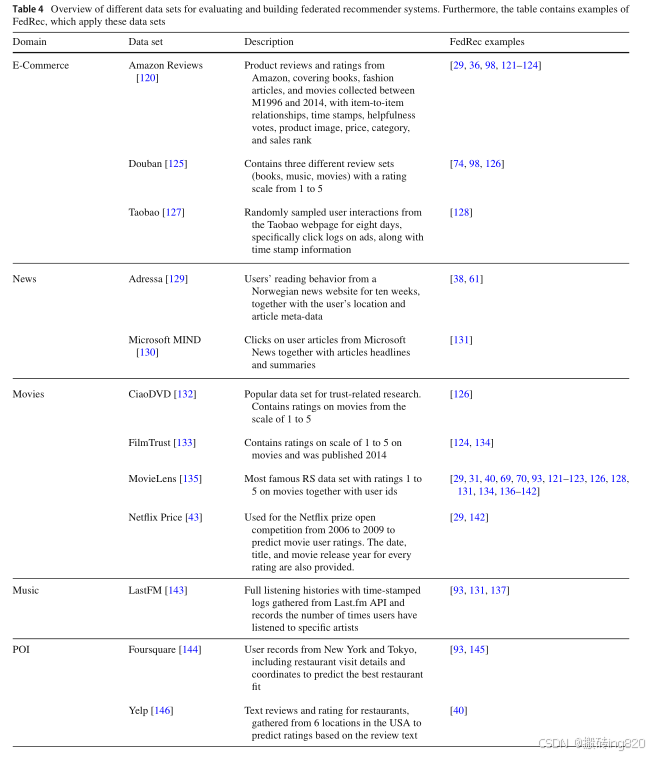
由于合成数据集synthetic data sets的缺点,真实用户数据的必要性是一个众所周知的挑战[119]。随着企业对RS的兴趣日益浓厚,最近发布了几个不同领域的数据集,这些数据集捕获了用户的浏览和消费行为。表4概述了FedRec研究中最常用的数据集以及因此调查的领域。该表还包含了FedRec算法的列表,这些算法在训练和评估中使用了这些数据。FedRecs可能的领域如下:
- E-Commerce:在电子商务领域,RSs通常使用由产品/游戏评论或用户点击组成的数据集来构建。这些交互发生在收集数据的网页上。评论数据集通常用于情感分析,而点击数据集更适合于预测点击概率和生成下一项建议。
- News: 在新闻预测方面,RSs旨在建议用户接下来可能会感兴趣的文章和文本。为了实现这一目标,采用了各种方法,导致不同的数据集具有不同的结构。一些数据集强调文章的内容和主题,而其他数据集捕获用户偏好、他们的环境和交互模式。
- Movies:对于电影推荐,RSs在实验、性能评估和算法优化方面严重依赖电影数据集。这些数据集通常使用从1到5的评分量表,允许观察用户的电影偏好。这些数据集通常包含数千部电影和数以万计的用户,其中著名的MovieLens数据集是该领域使用最广泛和最受认可的数据集之一。
- Music:在音乐推荐中,数据集与电影数据集有很大的不同,因为它们不是基于简单的评级。相反,音乐数据集专注于捕捉用户行为,特别是他们的收听模式,以深入了解各种歌曲、艺术家和流派之间的相似之处。这些见解是生成音乐推荐的基础。通常,这些数据集中的项目数据点表示侦听事件,可能需要预处理步骤将其转换为有意义的交互会话,以构建有效的RSs。
- POI (Points of Interest) :在基于位置或兴趣点的推荐领域,数据集在开发空间RSs中起着至关重要的作用。这些系统旨在预测相关位置或其他兴趣点,使其对旅游或移动推荐等应用程序有价值。例如,根据时间和地点推荐餐馆,或者预测理想的度假地点。这些数据集中的数据点总是包含空间信息,但它们的格式差异很大,包括地理坐标、自由文本描述或其他数据类型。
四、联邦推荐系统的开放性挑战与未来研究方向
本节介绍了FedRec可能的研究方向。虽然最近出现了用于集中式RSs的新算法、概念和范例,并已部署在实际应用程序中,但也应该在联邦设置中研究这些成功的方法。虽然传统的方法,如MF和FM已经在FedRec中进行了评估,但现代最先进的深度学习模型,如transformers,在FedRec的设置中仍未被探索(22 23年的角度,近年来应该有新的)。除了算法选择之外,在federc可以部署到实际场景之前,还需要解决诸如网络成本、性能需求或生产就绪库的可用性等技术方面的问题。
4.1迁移transfer联邦推荐系统
横向FedRec是FedRec研究中最早也是最主要的领域,因为数据以单个用户配置文件的形式分布,并且现有库中对各种隐私方法的支持使得这种方法成为自然的选择。另一方面,Vertical FedRec允许组织创建跨域RS,这是推荐业务中的常见任务。因此,垂直和转移联邦快递之间存在着难以界定的明显区别。尽管对Transfer FedRec的研究开始了,但它仍然是一个相对未开发的领域,有很多机会,而且据笔者所知,只有少数出版物存在(后续可以调研一下最新工作)。Pan等人的工作对不同的迁移学习方法进行了全面概述[77]。FedRec可以被看作是一个传递性的迁移学习环境。对于RS,模型的任务是相同的,但是标签、数据和域不同。
此外,将知识转移到新模型中可以称为特征表示转移feature representation transfer,因为目标是学习一个“好的”特征表示。从源领域的用户交互中获取的知识转移到目标领域,然后被编码为用户和项目的新特征表示。迁移学习成功地应用于使用不同数据源的跨领域推荐,如书籍推荐[147]或电影推荐[148]。最近关于迁移FedRec的研究只涵盖了迁移学习方法的一小部分。因此,如何将这些中心化的内容应用到联邦联邦的设置中,是未来需要全面探索的问题。
4.2Federated multiarm bandits
RS用于推断用户偏好,预测他的下一步,并提出有价值的物品。与多臂强盗(MAB)方法类似,它们在计算推荐值时也面临勘探-开采的挑战。他们需要利用用户以前喜欢的物品的信息,同时探索用户认为在他的交互中有用的新物品。凭借其稳定的探索方法,他们可以解决新用户和新项目的冷启动挑战,这解释了mab在推荐研究界日益增长的兴趣[149]。Shi和Shen[150]使用流行的MovieLens数据集[151]对联邦环境下MAB的组合进行了首次评估。作者的第一步可以为其他领域和不同数据集的进一步研究提供一个有趣的方向。
4.3基于会话的联邦推荐系统
基于会话的推荐系统(sbrs)是最先进的方法,可以在用户对其偏好的了解有限的情况下为用户生成推荐。sbrs广泛部署在门户网站中,其中捕获的信息主要由短会话组成,sbrs独立处理每个交互流,因此能够生成高质量的推荐,甚至可以向匿名用户推荐[152]。虽然第一种方法依赖于传统方法,但现代算法基于深度学习模型,如GRU4Rec[60],或者最近的transformer架构,如STAMP或BERT[153,154]。这些模型已经扩展到联邦环境中,并在案例研究中成功地进行了评估[155,156]。最近发表了基于GRU的顺序推荐的第一个实现[157],但据我们所知,没有基于transformer的SBRS FedRec。因此,基于前面提到的方法的sbrs如何在具有顺序域数据的FL设置中执行仍然是一个悬而未决的问题。
4.4非iid的挑战
Park和Tuzhilin首先将其表述为长尾问题 long-tail problem [158],对于大多数RS算法来说,访问尾部的项目是一个挑战。长尾表示项目的分布,其中只有少数项目具有较高的人气,系统中大多数项目很少被访问[159]。这种分布使得非iid数据问题在FedRec中不可避免,系统的性能也会因为这种偏态分布而下降。在整个客户交互过程中,本地数据之间的距离变得越来越明显,推荐的质量也随之下降。为了应对这一挑战,提出了一种数据共享方法[160],该方法在所有peers之间共享由均匀分布的类组成的全局数据集。每个选定的客户端都使用这些数据及其私有数据在本地训练其模型。另一种方法是FedPer,其中个性化层被本地添加到模型中[161]。模型的基础层形成全局模型,由中心实例使用fedavg算法共享和管理全局模型,每个客户端都有其用于深度分类的私有层。有趣的是,评估显示FedPer在非iid数据上的准确性比在均匀分布的数据上的准确性更高,这使得它成为一种很有前途的FedRec方法。Zhu等人的工作全面概述了解决FL中非iid数据挑战的不同策略[162]。
4.5联邦推荐系统的鲁棒性
CF的开放性和依赖于用户的国际输入,容易受到恶意用户的各种攻击[163]。FedRec面临同样的挑战,通常在这种情况下,用户协作训练一个开放的可访问的ML模型。与在数据中心进行培训的单片RS相比,FedRec的训练和操作依赖于一组不可靠的数据设备,这些设备是私有的,因此无法检查。中心实例不能控制客户的行为,也不能访问客户的私有训练数据。因此,恶意的peers可以通过传输特别修改的或有害的更新来破坏全局模型。在联邦环境中,这类攻击被称为中毒攻击。对这些有害更新的防御可以通过检测它们并在更新步骤中删除它们或通过拜占庭鲁棒聚合算法来实现。FL通常依赖于许多参与者,并且来自恶意客户机的模型更改必须与常规客户机不同,才能产生相当大的影响。异常检测算法(如AE)充当看门人,将它们分类为正确的,允许它们在训练步骤中做出贡献,或将其过滤掉[164]。对于拜占庭鲁棒聚合,像Krum算法[24]这样的方法在当前训练轮中丢弃那些离更新梯度均值最远的更新。然后,对于新模型中的每个新权重,取收集到的更新值,这是最接近平均值的[165]。隐私性和健壮性具有相反的需求和目标。检测恶意客户端需要对数据或模型更新进行调查,这违反了隐私要求。更新的加密使得中央实例很难确定哪个客户机或更新对系统有害。因此,在隐私和健壮性之间总是存在权衡,这一挑战仍然是最先进研究的一部分。
4.6边缘环境下联邦推荐系统的可扩展性
现代智能手机可以存储、训练和操作具有数百万个参数的深度学习模型[14]。然而,最近RSs的大小和计算需求远远超过了此类个人设备可用的本地计算资源。尽管数据中心的性能要高得多,但还是开发了几种方法来解决实际部署中的可伸缩性挑战。使用这些方法减少模型大小并保持类似的性能使得在边缘环境中部署最新模型成为可能。在模型修剪中,将FL模型的神经元去除,这对模型的整体精度影响很小[166]。有几种方法可以确定这些无关紧要的神经元,其中幅度修剪是最广泛的方法[167]。模型修剪已经在FL[168]和RS[169]域中进行了研究,在分离的RS[169]域中,修剪后的模型获得了与相似内存大小的基线模型相当甚至更好的结果。另一种使用与大型模型功能相似的小型模型的方法是知识蒸馏(KD)[170]。在KD中,使用一个更大、更繁琐的训练过的教师模型,通过训练它学习教师模型的软输出,将其知识提炼成一个更小的学生模型。该方法成功地在RS域中进行了评估[171],并且在联邦设置中优于传统方法[172]。模型剪枝和KD可能是在边缘环境中实现大型深度学习模型精度的有前途的工具,进一步研究这种组合将是有益的。
4.7优化通信成本
实现现实世界的FedRec系统的最大挑战之一是在系统的培训和操作阶段的规模方面的通信成本。第一个实现将每个训练回合中的高维项目嵌入发送回客户端。在最先进的聚合方法中,FedAVG是在中心实例和网络对等节点之间双向传输的完整模型。由于现代DL模型的大小很大,达到数百MB,这种方法很容易超过中心实例的I/O能力和客户机的可用带宽。因此,需要减少模型大小的方法。减少模型大小的一种可能性是通过模型修剪,其中不重要的神经元被丢弃,然后在FL设置中不传输[168]。不幸的是,剪枝会损害收敛速度,而具有更高可用带宽和计算资源的设备可以缩短所需的训练时间。在这种情况下,更好地利用本地现有资源的自适应剪枝会对整个系统的通信成本产生积极影响[173]。减少沟通的另一个选择是仔细选择那些应该更新的模型部件。Khan等人的工作应用服务器端MAB在每个训练轮中优先决定哪些项目应该更新其嵌入[131]。然后,中心实例只将这些项目嵌入发送给客户端,peers在返回它们进行中心聚合之前,用它们的本地数据对它们进行调整。在典型的FL场景中,训练轮只包含peers上的一个调整步骤。Wang等人研究了在peers将更新发送回中心实例之前,重复本地调整的影响[140]。重复的局部训练对整体精度影响较小,但显著降低了模型收敛前的传输成本。另一种降低传输成本的方法是梯度压缩。在FastSGD中,梯度首先转换为它们的倒数值,然后对数量化为小整数。然后过滤掉那些对更新影响较小的值。然后,在客户端将剩余的梯度值发送到聚合器之前,将它们映射到键值表示。这与该过程相反,以获得聚合的原始梯度[174]。这种方法被应用在分布式学习中,但是调查它在FedRec中的适用性可能会带来有希望的结果。
4.8对联邦推荐系统的库支持
有几个库使研究人员能够创建他们的FL应用程序,如PySyft,1 TensorFlowFederated,2 FA TE,3或最近的ibm开发。这些库将网络层与训练和推理过程解耦,使开发人员更容易开发,而无需考虑中心实例和对等体之间的通信。此外,许多这些库已经在通信中包含DP和加密方法,以增强隐私,而无需进一步的开发工作。到目前为止,只有FA TE有RS的内置模块。不幸的是,FA TE仅限于分解方法,目前不包含基于dl的FedRecs的预构建方法。最近,Microsoft[175]和Nvidia[176]发布了可扩展和生产库,其中包含最先进的方法来开发其集中式RSs。nvidia的库作为huggingface(为NLP领域开发的成功转换器架构集合[177])的中间件,在sbrs中执行推荐任务。对于FedRec的研究社区来说,创建结合FL和RS库的库是有益的,类似于Nvidia的开发。
五、结论
随着GDPR等政府隐私相关法规的出台,以及用户对披露个人数据的日益敏感,新的RS方法是必要的。FedRecs的设计目的是在不泄露敏感信息的情况下实现ML模型的协作训练。本调查提供了FedRecs最新发展的全面概述,并根据它们的应用方法、体系结构和附加的隐私方法对它们进行了分类。第一次发表的研究主要集中在横向FedRec和用户隐私方面,而纵向和转移FedRec仍然是未开发的研究领域。这两种方法允许来自不同领域的RS操作员进行协作,并通过跨领域推荐和可移植配置文件为用户提供改进的体验。RS的最新进展尚未应用于联邦环境,并且将联邦数据扩展到工业数据规模的技术挑战仍然存在。可以预期的是,FedRec有前途的方法将克服不同公司的边界,使用户能够轻松和个性化地访问全球内容网络,而不必担心分享他的私人信息。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









