







2021 ICLR 2021 Workshop on Distributed and Private Machine Learning (DPML), 2021,文章中加粗标绿的技术后续需要深入学习、加粗标红的是该文idea的关键点、下划线的也是一些该文值得注意的点。倾斜标黄是补充内容
标题:FedGraphNN:图神经网络的联邦学习基准系统------ 2021联邦图神经开山之作
摘要
图神经网络(GNN)在从图结构数据中学习分布式表示的能力使其研究迅速发展。然而,由于隐私问题、监管限制和商业竞争,将大量真实世界的图形数据集中用于GNN训练是令人望而却步的。联邦学习(FL)是一种趋势分布式学习范式,它在保护数据隐私的同时提供了解决这一挑战的可能性。尽管最近在视觉和语言领域取得了进展,但没有合适的平台用于gnn的FL。为此To this end,我们引入了FedGraphNN,这是一个开放的FL基准系统,可以促进联邦gnn的研究。fedgraphhnn建立在图形FL的统一表述 unified formulation上,包含来自不同领域的广泛数据集,流行的GNN模型和FL算法,具有安全高效的系统支持。特别是对于数据集,我们从7个领域收集,预处理和划分了36个数据集,包括公开可用的数据集和专门获得的数据集,如hERG和腾讯。我们的实证分析展示了我们的基准系统的效用,同时暴露了图FL中的重大挑战:联邦gnn在大多数具有非iid分裂的数据集中比集中式gnn表现更差;在集中设置中获得最佳结果的GNN模型可能无法在FL设置中保持not maintain其优势。这些结果意味着需要更多的研究努力来揭开联合gnn背后的神秘面纱unravel the mystery behind federated GNNs。此外,我们的系统性能分析表明,FedGraphNN系统对大规模图形数据集具有计算效率和安全性。我们在https://github.com/FedML-AI/FedGraphNN上维护源代码。
一、介绍
图神经网络(gnn)是最先进的模型,可以从各种领域的复杂图结构数据中学习表示,如药物发现[68,75,93]、社交网络[26,87,29,99]、推荐系统[85,49,22,96]和交通流建模[83,12]。然而,由于隐私问题、监管限制和商业竞争,在现实世界中,图形数据分散的情况非常普遍。例如,在基于人工智能的药物发现行业中,制药研究机构pharmaceutical research institutions 将从其他机构的数据中获益良多,但由于商业原因,双方都无法承担披露自己的私人数据的费用。
联邦学习(FL)是一种分布式学习范例,可以解决这种数据隔离问题data isolation problem。在FL中,培训是多个客户之间的协作行为,不需要集中的本地数据[54,39]。尽管FL在计算机视觉[32,48,37,36]和自然语言处理[27,22,46]等领域得到了成功的应用,但在图数据机器学习领域还没有得到广泛的应用。原因有很多:
1. 目前文献literature,中缺乏对各种图FL设置和任务的统一表述,这使得专注于基于sgd的联邦优化算法的研究人员难以理解联邦gnn中的基本essential挑战;
2. 正如[33]所总结的那样,现有的FL库不支持不同的数据集和学习任务来基准测试不同的模型和训练算法。考虑到图数据的复杂性Given the complexity of graph data,在FL环境下训练gnn的动态可能与训练视觉或语言模型不同。一个具有标准化开放数据集和参考实现的公平和易于使用的基准对于开发新的图形FL模型和算法至关重要;
3. 面向仿真的联邦训练系统对于跨竖井设置cross-silo settings的大规模私有图数据集的联邦gnn研究效率低下且不安全。由于缺乏针对各种GNN模型和FL算法量身定制的constrained模块化modularized联合训练系统,Disruptive破坏性的研究思想可能受到限制constrained。
为了解决这些问题,我们提出了一个用于GNN的开放式FL基准系统,称为fedgraphhnn,它包含来自不同领域的各种图数据集,并简化eases了各种GNN模型和FL算法的训练和评估。我们首先制定了图FL,为联邦gnn提供了一个统一的框架(第2节)。我们根据实际应用场景介绍了各种具有合成分区的图形数据集(第3节)。设计并实现了一个高效安全的FL系统,以支持流行的GNN模型和FL算法,并为定制研究和工业部署提供低级可编程api(第4节)。广泛的实证分析证明Extensive empirical analysis demonstrates了我们系统的实用性和效率,并指出indicates需要对图FL进行进一步研究(第5节)。我们根据新兴的emerging相关工作(第6节)以及基于FedGraphNN的未来方向(第7节)总结了图FL的开放挑战。
二、联邦图神经网络(FedGraphNN)
我们考虑一个分布式图场景,其中单个图被分割,或者多个图分散在多个边缘服务器上,由于隐私或监管限制,这些服务器无法集中进行训练。然而,对分散dispersed数据的协同训练可以帮助aid形成the formulation of更强大和可推广的图模型。在这项工作中,我们重点关注图神经网络(gnn)作为图模型,并将其他领域的神经网络模型上的联邦学习(FL)的新兴研究扩展到gnn。
在我们统一的FedGraphNN框架中,我们假设分布式图场景中有K个客户端,第K个客户端有自己的数据集D(K):= (G(K), Y(K)),其中G(K) = (V(K), E (K))是D(K)中的图(s),其顶点和边缘特征集X(K) = {X(K)m}m∈V(K), Z(K) = {E (K)m,n}m,n∈V(K), Y(K)是G(K)的标签集。每个客户端都有一个GNN模型来学习图表示并进行预测。多个客户都有兴趣通过服务器协作来改进他们的GNN模型,而不必暴露他们的图形数据集。

我们在图2中说明了FedGraphNN的公式。在不损失通用性的情况下Without loss of generality,我们使用消息传递神经网络(MPNN)框架[24,69]。大多数spatial-based基于空间的GNN模型[41,79,26]都可以统一can be unified into 到这个框架中,其中向前传递 forward pass有两个阶段:消息传递阶段message-passing phase和读出阶段 readout phase。
GNN阶段1:消息传递(对所有任务都一样)。消息传递阶段包含两个步骤:(1)模型收集和转换gathers and transforms邻居的消息;(2)模型使用聚合的消息更新节点的隐藏状态。在数学上Mathematically,对于客户端k和层索引l= 0,…L−1时,一个L层MPNN形式化如下:
其中h(k,0) i = x(k) i为第k个客户端的节点特征,‘为层索引,AGG为聚合函数(例如,在GCN模型中,聚合函数为简单的SUM运算),Ni为节点i的邻居集,M (k, ’ +1) θ(·)为以当前节点hi的隐藏状态、邻居节点hj的隐藏状态和边缘特征zi,j为输入的消息生成函数。U (k, ' +1) φ(·)是接收聚合特征m(k, ' +1) i的状态更新函数。

解释:



GNN阶段2:读出(不同任务不同)。在通过L层MPNN传播后,读出阶段从最后一层MPNN的隐藏状态计算特征向量,并对下游任务进行预测,即
请注意,为了处理不同的下游任务,S可以是单个节点(节点分类),节点对(链接预测),节点集(图分类)等等,Rδ可以是连接函数或池化函数,例如SUM加上单层或多层感知器。



GNN with FL:为了表示FL设置,我们定义W = {Mθ, Uφ, Rδ}为客户k的GNN中总的可学习权值,因此,我们将fedgraphhnn表示为一个分布式优化问题,公式如下:
其中![]() 是第k个客户端的局部目标函数,用于测量具有N (k)个数据样本的图数据集D(k)的局部经验风险。L为全局GNN模型的损失函数。要解决这个问题,最直接的算法3是fedavg[54]。这里需要注意的是,在fedavg中,服务器上的聚合函数仅仅是对模型参数求平均值。我们归纳地使用gnn(即,模型独立于它所训练的图的结构)。因此,在参数聚合期间,服务器上不需要任何客户机上的图的拓扑信息。其他高级算法,如FedOPT[62]、FedGKT[32]和Decentralized FL[28,35]也可以应用。
是第k个客户端的局部目标函数,用于测量具有N (k)个数据样本的图数据集D(k)的局部经验风险。L为全局GNN模型的损失函数。要解决这个问题,最直接的算法3是fedavg[54]。这里需要注意的是,在fedavg中,服务器上的聚合函数仅仅是对模型参数求平均值。我们归纳地使用gnn(即,模型独立于它所训练的图的结构)。因此,在参数聚合期间,服务器上不需要任何客户机上的图的拓扑信息。其他高级算法,如FedOPT[62]、FedGKT[32]和Decentralized FL[28,35]也可以应用。



在FedGraphNN的统一框架下,我们根据图形跨筒仓分布的方式,将现实应用驱动的各种分布式图形场景组织为三种设置,并在每种设置中为相应的典型任务提供支持。
- 图级FedGraphNN:每个客户端持有一组图,其中典型的任务是图分类/回归。现实世界的场景包括分子试验[68]、蛋白质发现[101]等,由于昂贵的实验费用,每个研究所可能持有一组有限的带有真值标签的图。
- 子图级FedGraphNN:每个客户端持有一个更大的全局图的子图,其中的典型任务是节点分类和链接预测。现实世界的场景包括推荐系统[102]、知识图谱完成[10]等,其中每个机构institute可能持有用户-物品交互数据user-item interaction data 或实体/关系数据的子集 entity/relation data。
- 节点级FedGraphNN:每个客户端持有一个或多个节点的自我网络ego-networks,其中典型的任务是节点分类和链接预测。现实场景包括社交网络[108]、传感器网络[103]等,其中每个节点在大图中只能看到其k-hop邻居及其连接。
支持GNN模型和FL算法。FedGraphNN的最新版本支持GCN [41], GA T [79], GraphSage [26], SGC[86]和GIN[91]的GNN模型,通过PyTorch Geometric[17]实现。对于FL算法,除了fedavg[54]之外,FedML库[33]还支持FedOPT[62]等其他高级算法。有关支持的GNN基线的更多细节,请参阅附录A。
三、FedGraphNN开放数据集
FedGraphNN围绕三种基于图数据在现实场景中分布方式的联合GNN设置,涵盖了图FL的广泛领域、任务和挑战。具体而言,它包括来自7个领域的36个数据集,如分子、蛋白质、知识图、推荐系统、引文网络和社交网络。在这里,为了便于清晰地理解facilitate各种图形FL设置,我们在三种联合GNN设置中组织并介绍了现实世界数据集的示例。数据集的确切来源和统计数据见表1,更详细的信息见附录B。
- 图级设置:在现实世界中,生物医学机构可能拥有他们自己的一组图,比如分子和蛋白质,社交网络公司可能拥有他们自己的一组社区图。这些图可能构成constitute用于GNN训练的大型和多样化的数据集,但它们不能直接跨筒仓silos共享。为了模拟这样的场景,我们利用来自分子机器学习[88]、生物信息学[8,71,26]和社会计算[92]领域的数据集,我们还引入了一个新的大规模数据集,称为hERG[19],用于联邦药物发现。
- 子图级设置:子图级FL的第一个现实场景是推荐系统,其中用户可以与不同商店或部门拥有的物品进行交互,这使得每个数据所有者只持有全局用户-物品图的一部分。为了模拟这些场景,我们使用了来自公开来源[77,64]和内部来源[30]的推荐数据集,它们具有高质量的元数据信息。另一个现实的场景是知识图,由于关注特定的领域,不同的组织或部门可能只拥有整个知识的子集。我们整合了FB15k-237[15]、WN18RR[78]和Y AGO3-10[50]数据集,其中可以根据关系类型构建子图来区分专业领域或社区,以区分焦点实体。
- 节点级设置:在社交网络中,每个用户的个人数据可能是敏感的,只有他/她的k-hop邻居才能看到(例如在Instagram中,私人账户的内容k = 1,链接k = 2)。因此,在客户端持有用户自我网络的社交网络中考虑节点级FL是很自然的。为了模拟这种情况,我们使用开放的社交网络[73]和出版网络[53,5,23,72,76],并将它们划分为自我网络集。
在图挖掘任务方面,FedGraphNN支持图分类、节点分类和链接预测这三种常见任务。有些任务在某些图形FL设置中自然是重要的,而其他任务则不是,我们也用下面的实际示例来澄清
- 图分类:该任务是根据图的结构和总体信息对不同类型的图进行分类。与其他任务不同,这需要描述characterize整个输入图的属性property。这个任务在图级FL中自然是重要的,有真实的例子,如分子性质预测、蛋白质功能预测和社会群体分类。
- 链路预测:该任务是估计estimate图中任意两个节点之间的链路概率。它在子图级FL中很重要,例如,在推荐系统和知识图中,前者预测链接概率,后者预测关系类型。 for example, in recommendation systems and knowledge graphs, where link probabilities are predicted in the former, and relation types are predicted in the latter. 在节点级别的设置中,这是不太可能的,但仍然是可行的,例如,可以在用户的自我网络中尝试朋友建议和社会关系分析。
- 节点分类:该任务是预测图中单个节点的标签。它在节点级的FL中更为重要,例如根据作者的k-hop合作者来预测他/她的活跃研究领域,或者根据他/她的k-hop朋友来预测用户的习惯。它在亚图级别的FL中也可能很重要,例如基于分散在多个医疗机构的患者网络的疾病感染的协同预测。
数据源。我们详尽地研究和收集了来自7个领域的36个数据集。其中34个来自公开来源,如MoleculeNet[88]和图核数据集[8]。此外,基于我们与腾讯的合作,我们引入了两个新的去识别数据集:hERG[40,20],一个用于对负责心脏毒性的蛋白质分子进行分类的图数据集,以及腾讯[29],一个表示用户和群体之间关系的大型二部图。更多细节及其具体的预处理程序可在附录B.1和B.2中找到。我们计划通过积极收集开放数据集和与工业伙伴的合作,在未来不断丰富可用的数据集。
生成联邦学习数据集。与传统的机器学习基准数据集不同,图形数据集和现实世界的图形可能会显示非i.i.d。-由结构和特征异质性等来源引起的异质性[97,98,95]。再加上FL,非i - i的多种来源。d是无法区分的。在这里,我们的重点是如何产生可重复的和统计的(基于样本的)非i.i.d。生成基于样本的非id。因此,我们采用不平衡分区算法潜狄利克雷分配(Latent Dirichlet Allocation, LDA)[33]对数据集进行分区,该方法可以应用于任何数据域。此外,研究人员和从业人员也可以合成非i.i.d。使用我们可用的额外元数据。附录中的图6显示了几个数据集的非i.i.d。使用LDA方法生成的分布。代表性数据集的LDA alpha值可以在附录E.3的表2、3、4和20中找到。Y等,深度解耦和量化非i.i.d。联邦gnn中的-ness仍然是一个开放的问题[84,89]。
综上所述,我们针对图FL数据收集和基准测试中的几个挑战提供了全面的研究和解决方案:(1)收集、分析和分类大量公共的、真实的数据集到不同的联邦GNN设置中,并进行相应的典型任务;(2)规范非身份证合成程序。通过提供一种新的分区方法和关联元数据,实现了所有图结构数据集的数据分布。
四、 FedGraphNN基准测试系统:高效、安全、模块化
我们已经为FedGraphNN发布了一个开源的分布式培训系统。该系统是为图形FL的基准测试和促进算法创新而量身定制的,在FL的背景下,有三个关键的优势设计尚未被现有的面向仿真的基准测试和库[33]所支持。
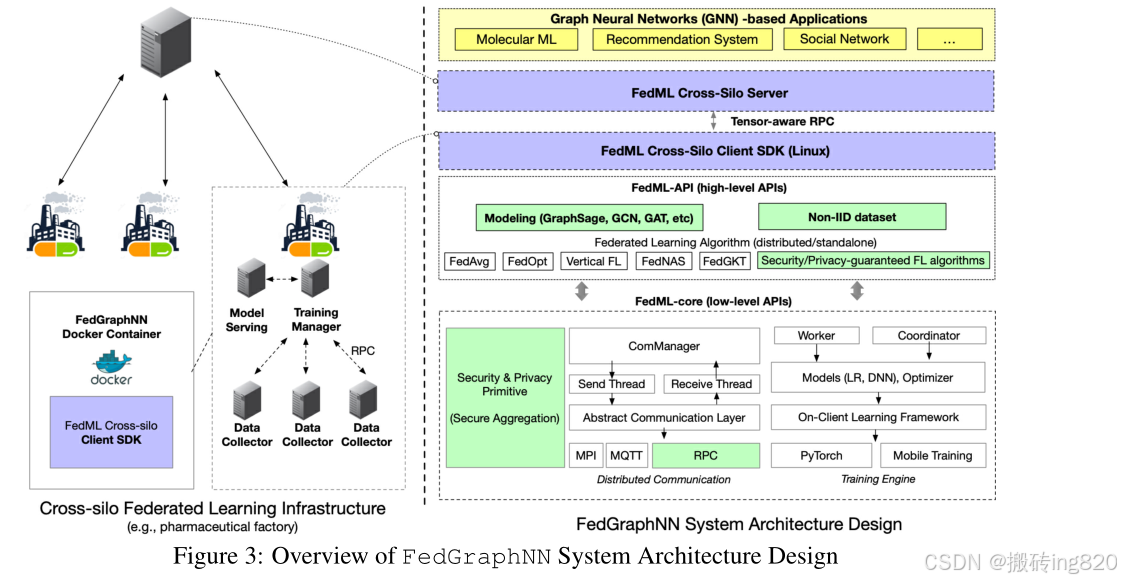
以高效可部署的分布式系统设计增强评估的现实性。考虑到FedGraphNN主要在跨筒仓设置中执行,其中每个FL客户端代表属于组织的边缘服务器,而不是智能手机或物联网设备,我们设计的培训系统支持多个边缘服务器中的现实分布式计算。如图3所示,系统架构由三层组成:fedml核心层、fedml api层和应用层。fedml核心层同时支持RPC(远程过程调用)和MPI(消息传递接口),实现了位于不同数据中心的边缘服务器之间的通信。更特别的是,RPC API是面向张量的,这意味着它在客户端之间的权重或梯度传输比使用gpu直接通信的na¨ıve gRPC要快得多(例如,来自不同AWS EC2帐户的数据所有者可以利用此功能进行更快的训练)。通信原语被封装为抽象通信api(即图3中的ComManager),以简化FedML-API层中不同FL算法请求的消息定义和传递(详见附录C)。从部署角度来看,FL客户端库应该与异构硬件和操作系统配置兼容。为了实现这一目标,我们提供了Docker容器来简化联邦训练的大规模部署。
在上述设计的帮助下,研究人员可以在多个组织(例如AWS EC2中的边缘服务器)中位于多个CPU/GPU服务器的并行计算环境中运行实际评估。因此,对于中小规模的图数据集,训练只需几分钟即可完成。对于大规模图形数据集,研究人员还可以测量系统性能(通信和计算成本),以便在准确性和系统效率之间进行切实的权衡。基于docker的部署进一步简化了扩展到众多边缘服务器(FL客户端)的过程。
使用轻量级安全聚合启用安全基准测试。行业内的研究人员可能还需要与其他组织一起在他们的私人客户数据集上探索FL。然而,来自客户端的模型权重仍然存在隐私泄露的风险[110]。因此,法律和监管部门通常不允许在没有强大安全性保证的情况下对私人客户数据集进行FL研究。为了打破这一障碍,我们将安全聚合(SA)算法集成到FedGraphNN系统中。机器学习研究人员不需要掌握安全相关知识,还可以享受安全的分布式训练环境。更具体地说,我们用LightSecAgg支持FedGraphNN, LightSecAgg是我们团队开发的最先进的SA算法(附录D.2)。在高级理解中,LightSecAgg通过生成单个随机掩码来保护客户端模型,并允许在服务器聚合时取消它们。因此,服务器只能看到来自每个客户机的聚合模型,而不能看到原始模型。LightSecAgg的设计和实现跨越了系统架构中的FedML-core和FedML-API,如图3所示。还支持SecAgg[7]和SecAgg+[3]等基线。
通过不同的数据集、GNN模型和FL算法促进算法创新。FedGraphNN还旨在为未来的算法创新提供灵活的定制。为了支持不同的数据集、GNN模型和FL算法,我们对API和组件设计进行了模块化。所有数据加载器都遵循相同的输入和输出参数格式,这与不同的模型和算法兼容,并且易于支持新数据集。模型和训练器的定义方法与集中式训练保持一致,降低了分布式训练框架开发的难度。对于新的FL算法开发,面向工人的编程降低了消息传递和定义的难度(详细信息在附录C中介绍)。多种算法实现可作为未来算法创新的参考源代码。面向用户的界面(主训练脚本)被简化为图4所示的示例代码,其中几行代码可以在跨竖井云环境中启动联邦训练。
五、fedgraphn实证Empirical分析
5.1实验设置
我们的实验是在多台GPU服务器上进行的,每台服务器配备8台NVIDIA Quadro RTX 5000 (16GB GPU内存)。超参数是通过我们内置的高效参数扫描功能从附录E.1中列出的范围中选择的。我们展示了图分类的ROC-AUC度量和图回归的RMSE & MAE,链接预测的MAE, MSE和RMSE以及节点分类的micro-F1的结果。FedGraphNN支持的更多评估指标见附录E.2。
5.2基准性能分析
我们报告了使用fedavg最广泛使用的FL算法训练的几个流行的GNN模型的实验结果,以举例说明FedGraphNN的实用性。更多具有不同基线、超参数、评估指标和可视化的结果正在更新,并在附录E.3中给出。在超参数调优之后,我们在表2、3和4中给出了主要的性能结果和运行时。
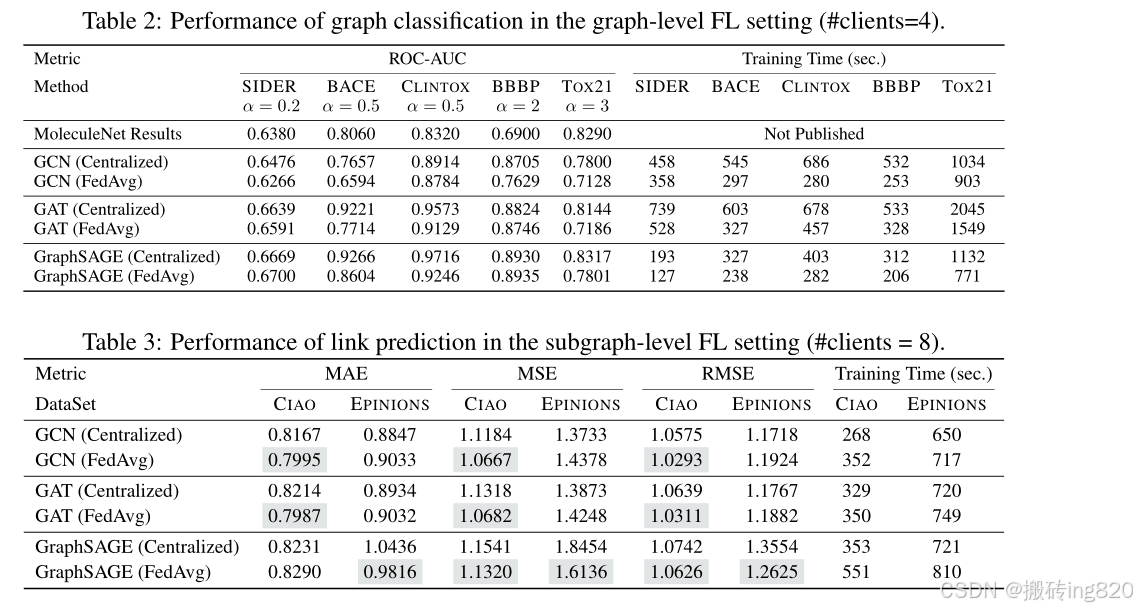
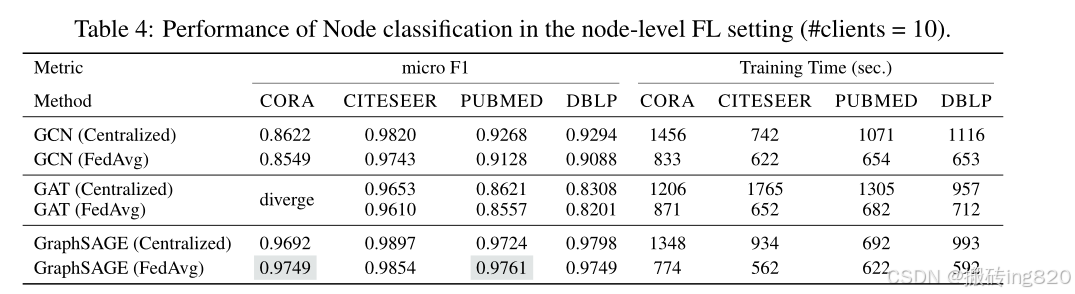
除了展示FedGraphNN的实用性之外,这些结果还有很多值得注意的地方:
- 当图数据集很小时,FL的准确率通常与集中式学习相当。
-
当数据集规模增长时,FL的准确率明显低于集中式学习。我们推测这是复杂的非身份证。在较大的数据集中导致准确性下降的图形的性质。
- 在联邦环境中训练gnn的动态不同于训练联邦视觉或语言模型。我们的研究结果表明,集中式设置的最佳模型可能不一定是FL设置的最佳模型。
- 反直觉现象(上表中突出显示)进一步增加了联邦图神经网络的神秘性:在图级实验中,GA T在9个数据集中的5个上遭受最大的性能妥协;在子图级和节点级FL中,一些数据集(CIAO, CORA, PubMed)上的结果甚至可能比集中训练的结果略高;GA T在节点级FL(如CORA数据集)中不能达到合理的精度等。
这些结果表明了FedGraphNN中基线的局限性,并激发了进一步的研究,以理解FL设置中的细微差别并改进训练gnn。
系统效率和安全性评估。我们提供了关于系统性能评估的其他结果,这些结果总结在附录D.1中。根据图数据的大小,FedGraphNN可以高效地完成训练。训练时间从几分钟到1小时左右不等,即使是大规模的图。在安全性方面,LightSecAgg的主要结果在附录D.2中提供。关键的好处是,它不仅获得了与最先进的(SecAgg[7]和SecAgg+[3])相同级别的隐私保证,而且还大大降低了聚合复杂性(因此训练速度要快得多)。
六、相关工作和公开挑战
FedGraphNN位于gnn和FL的交叉点。我们首先在三种不同的图FL设置的框架下讨论相关工作。(1)图级(图1(a)):我们认为分子机器学习在这种情况下是最重要的应用,其中许多小图分布在多个机构之间,如[35,89]所示。[89]提出了一个专门针对gnn的聚类FL框架来处理特征和结构异质性。[35]开发了一个多任务学习框架,适合在不需要中央服务器的情况下训练联邦图级gnn。(2)子图级(图1(b)):该场景通常适用于整个社交网络、推荐网络或知识图,如[85,105]所示,由于大型公司不同部门之间的数据屏障或不同领域重点的数据平台,需要将其划分为许多更小的子图。[85]提出了一种带有GNN的联邦推荐系统,而[105]提出了FedSage,一种利用变分图自编码器生成伪邻居的子图级联邦GNN。(3)节点级(图1(c)):当图中特定节点的隐私性很重要时,节点级图FL在实践中很有用。物联网设置就是一个很好的例子[107];[81]使用FL和元学习的混合方法解决了去中心化社会网络数据集中的半监督图节点分类问题;[55]尝试使用边缘云划分的GNN模型来保护节点级隐私,用于节点级交通传感器数据集的时空预测任务。
在我们统一的fedgraphhnn系统之前,在联邦设置中训练图神经网络的标准化数据集和基线严重缺乏。以前的平台如LEAF[9]、TensorFlow Federated[2,6]、PySyft[70]和FA TE都不支持图数据集和GNN模型。除了fedgraphhnn的直接目标之外,图FL中的许多开放算法挑战仍有待研究。首先,以一种原则和有效的方式整合gnn的图拓扑和FL的网络拓扑是高度特定于数据集和应用的。其次,对于某些任务,将单个图划分为子图或自我网络会引入数据集偏差和信息丢失,因为缺少跨子图链接[105]。三是对非fdi的多重来源进行解耦和量化。图中特征和结构的一致性对于联邦gnn的合理设计至关重要[89,84]。最后,在通信效率和安全性方面,以前的工作使用了各种方法,包括安全多方计算(SMPC)[109]、同态加密(HE)[109]、安全聚合[38]和Shamir秘密共享[107],但缺乏对它们的比较。
七、结论及未来工作
在这项工作中,我们为gnn设计了一个FL系统和基准,名为FedGraphNN,其中包括开放数据集,基线实现,可编程api,所有这些都集成在大多数研究实验室负担得起的强大系统中。我们希望FedGraphNN可以作为一个易于使用的研究平台,供研究人员探索FL和gnn交叉的重要问题。
在此,我们重点介绍了基于我们的FedGraphNN系统的未来改进和研究方向:支持更多的图形数据集和GNN模型用于不同的应用。可能的应用包括但不限于传感器网络和时空预测[47,94];2.对系统进行优化,进一步加快大型图的训练速度[106,44];3. 设计先进的图FL算法,以减轻非i.i.d数据集的准确性差距。ness,例如裁剪FedNAS[31,34],为单个FL客户搜索个性化的GNN模型;4.探索基于元学习和自我监督等概念的标签高效GNN模型,以利用每个客户端及其协作中的图[90];5. 解决联邦GNN设置下的安全和隐私挑战[16,57 - 59,100,11];6. 提出有效的压缩算法,在保证用户本地数据隐私的同时,根据用户的可用带宽调整压缩级别;7. 组织数据竞赛、主题研讨会、特刊等,传播FedGraphNN;8. 积极讨论道德和社会影响,以避免不必要的负面影响。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









