






 文章介绍了χ2分布的起源、应用、定义和性质,包括在卡方检验、拟合优度检验等统计分析中的作用。通过Python代码动态展示了χ2分布的概率密度函数和概率分布函数随自由度变化的情况,并添加了期望值和下侧分位点的可视化,增强了对χ2分布的理解。
文章介绍了χ2分布的起源、应用、定义和性质,包括在卡方检验、拟合优度检验等统计分析中的作用。通过Python代码动态展示了χ2分布的概率密度函数和概率分布函数随自由度变化的情况,并添加了期望值和下侧分位点的可视化,增强了对χ2分布的理解。
概率论与数理统计:卡方分布
引言
在概率统计A这门课上, χ 2 \chi ^{2} χ2分布是我们在第七章统计总体与样本的第三节中所讲到,同时讲解了正态总体样本的线性函数的分布、t分布、F分布,这三种分布都与 χ 2 \chi ^{2} χ2分布有着千丝万缕的联系,虽说并不全由其构成,但 χ 2 \chi ^{2} χ2分布仍是较为重要的一种分布,其中的许多性质值得我们研究与学习。(假装有教材链接~~~)
χ 2 \chi ^{2} χ2 分布的介绍
起源介绍
χ
2
\chi ^{2}
χ2分布在数理统计中具有重要意义。
χ
2
\chi ^{2}
χ2分布是由阿贝(Abbe)于1863年首先提出的,后来由海尔墨特(Hermert)和现代统计学的奠基人之一的卡·皮尔逊(C K.Pearson)分别于1875年和1900年推导出来,是统计学中的一个非常有用的著名分布。 1
(原文from度娘)
应用介绍
在本书内容中, χ 2 \chi ^{2} χ2分布主要运用于其他分布的构成、假设检验等。此外在其他方面有广泛应用:
- 卡方检验:卡方分布被广泛用于卡方检验,用于比较观察值与期望值之间的差异。卡方检验可以用于判断两个变量之间是否存在相关性或者是否符合某种分布模型。它在医学、社会科学、市场调研等领域经常被使用。
- 拟合优度检验:卡方分布可用于拟合优度检验,用于检验观察值是否与某个理论分布相吻合。通过比较观察频数与期望频数的差异,可以评估数据是否符合预期的分布模型。
- 置信区间构建:卡方分布可以用于构建参数的置信区间。在回归分析和其他统计模型中,卡方分布可用于估计参数的不确定性范围。
- 因子分析:在因子分析中,卡方分布可用于评估因子的适合度。通过计算卡方拟合度指标,可以确定因子模型是否适合观察数据。
- 遗传学:卡方分布在遗传学中广泛应用,例如在遗传连锁分析、基因型频率分析和遗传关联研究中。
除了上述应用,卡方分布还在其他领域中发挥重要作用,例如贝叶斯统计学、数据挖掘、生物统计学等。其灵活性和广泛性使得卡方分布成为统计学中的重要工具之一。
χ 2 \chi ^{2} χ2分布的定义及性质
χ 2 \chi ^{2} χ2分布的定义是建立在n个相互独立的标准正态分布的随机变量的基础上的。
定义
设
X
1
,
X
2
,
X
3
,
.
.
.
,
X
n
X_{1} ,X_{2} ,X_{3} ,...,X_{n}
X1,X2,X3,...,Xn相互独立,且都服从N(0,1),则随机变量
χ
2
=
∑
i
=
1
n
X
i
2
\chi ^{2} = \sum_{i= 1}^{n}X_{i}^{2}
χ2=i=1∑nXi2 的概率密度为
f
(
y
)
=
{
1
2
n
2
Γ
(
n
2
)
y
n
2
−
1
e
−
y
2
,
y
>
0
0
,
y
≤
0
f(y) =\left\{\begin{matrix} \frac{1}{2^{\frac{n}{2}} \Gamma(\frac{n}{2} ) }y^{\frac{n}{2}-1 } e^{-\frac{y}{2} } ,y>0 \\0,y\le0 \end{matrix}\right.
f(y)={22nΓ(2n)1y2n−1e−2y,y>00,y≤0,则称
χ
2
\chi ^{2}
χ2服从自由度为n的
χ
2
\chi ^{2}
χ2分布,记作
χ
2
\chi ^{2}
χ2~
χ
2
(
n
)
\chi ^{2}(n)
χ2(n)
性质
-
若 X X X~ χ 2 ( n ) \chi ^{2}(n) χ2(n),则 X X X的数学期望和方差分别是:
E ( X ) = n , D ( X ) = 2 n . E(X) = n,D(X) = 2n. E(X)=n,D(X)=2n. -
若 X 1 X_{1} X1~ χ 2 ( n 1 ) \chi ^{2}(n_{1}) χ2(n1), X 2 X_{2} X2~ χ 2 ( n 2 ) \chi ^{2}(n_{2}) χ2(n2)吗,且 X 1 X_{1} X1与 X 2 X_{2} X2相互独立,则
X 1 + X 1 X_{1}+X_{1} X1+X1~ χ 2 ( n 1 + n 2 ) \chi ^{2}(n_{1}+n_{2}) χ2(n1+n2) -
设 X 1 , X 2 , X 3 , . . . , X n X_{1} ,X_{2} ,X_{3} ,...,X_{n} X1,X2,X3,...,Xn相互独立,且都服从 N ( μ , σ 2 ) N(\mu ,\sigma ^{2} ) N(μ,σ2),则
1)样本均值 X ˉ \bar{X} Xˉ和样本方差 S 2 S^{2} S2相互独立
2) ( n − 1 ) σ 2 S 2 ∼ χ 2 ( n − 1 ) \frac{(n-1)}{\sigma ^{2}} S^{2}\sim \chi ^{2}(n-1) σ2(n−1)S2∼χ2(n−1) -
不同的自由度决定不同的 χ 2 \chi ^{2} χ2分布,自由度越小,分布越偏斜。
-
χ 2 \chi ^{2} χ2分布在第一象限内,卡方值都是正值,呈正偏态(右偏态),随着参数的增大,分布趋近于正态分布;卡方分布密度曲线下的面积都是1.
-
χ 2 \chi ^{2} χ2分布的均值与方差可以看出,随着自由度n的增大, χ 2 ( n ) \chi ^{2}(n) χ2(n)分布向正无穷方向延伸(因为均值n越来越大),分布曲线也越来越低阔(因为方差2n越来越大)。
查表
χ
2
\chi ^{2}
χ2分布上侧(右侧)分位点表:(这里的
α
\alpha
α也就是我们假设检验的显著性水平
α
\alpha
α)
图形化展示
由于本人就读于自动化科学与电气工程学院,因此具有一定的代码基础,在面对一些并不常见的函数或者分布时,我们可以利用程序这一工具对代码进行具象化,更有利于我们学习和理解。
现有的静态图
在百度百科和一系列搜索引擎中你可以很轻易的搜索到有关
χ
2
\chi ^{2}
χ2分布的概率密度函数,如下图所示(原文from度娘):
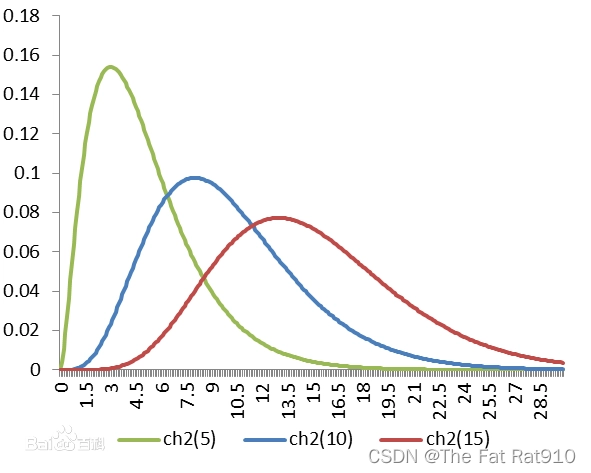
在现有的图像中虽然能够看出一定的概率密度函数随自由度变化而变化的,但变化的过程仍然不够明显,所以我决定利用程序让他实现变化的过程。
让概率函数动起来!!!(附代码)
效果展示
我们首先来看看昨晚变化的效果,我在每次变化的时候加上了颜色的变化,能够更明显的展示曲线的变化趋势,并且相应的自由度也打印到屏幕上,方便实时看到当前曲线所对应的自由度:

我将x轴取[0,50],y轴取[0,0.5],自由度取[1,19],这样取值不仅可以将自由度在19之前的概率密度最大点包括在内,还可以不失去整体形状的显示。
效果增强
虽然上图已经满足了一定的学习需求但是!这个图中只是定性的体现出了概率密度函数的变化,这并不能满足我们的学习需求,我们还需要知道密度最大的X值、下侧分位点、概率分布函数等等。于是我在原来的基础上对这个曲线进行了一些处理,让他能够进行一定量的定量显示,虽然显示的精度并没有那么高,但仍可以进一步的提高学习时的直观性和准确性。改进后的概率密度函数图像如下:

概率密度函数源码
拿!都可以拿!
import numpy as np
import matplotlib.pyplot as plt
from matplotlib.animation import FuncAnimation
from scipy.stats import chi2
# 设置自由度范围
degrees_of_freedom = np.arange(1, 20)
# 定义颜色列表
colors = ['b', 'g', 'r', 'c', 'm', 'y', 'k', 'purple', 'orange']
# 生成 x 值范围
x = np.linspace(0, 50, 500)
# 创建画布和轴
fig, ax = plt.subplots()
# 初始化线条对象
line, = ax.plot([], [])
# 初始化文本框对象
text = ax.text(0.7, 0.9, '', transform=ax.transAxes)
# 设置坐标轴范围
ax.set_xlim(0, 50)
ax.set_ylim(0, 0.5)
# 初始化最大点标记
max_point = ax.plot([], [], 'ro', markersize=8)[0]
# 初始化文本框显示最大点坐标
coord_text = ax.text(0.2, 0.8, '', transform=ax.transAxes, fontsize=12)
# 更新函数,用于每帧更新数据和曲线
def update(frame):
n = degrees_of_freedom[frame] # 获取当前自由度值
pdf = chi2.pdf(x, n) # 计算当前自由度下的概率密度函数值
line.set_data(x, pdf) # 更新曲线数据
if frame > 8: # 取模进行循环,防止越界
frame = frame % 8
line.set_color(colors[frame])
text.set_text(f'n={n}') # 更新文本框内容
text.set_fontsize(16)
text.set_color(colors[frame])
ax.set_title('Chi-Square Distribution') # 更新标题
# 找到概率密度函数的最大值索引
max_index = np.argmax(pdf)
max_x = x[max_index]
max_y = pdf[max_index]
# 更新最大点的坐标
max_point.set_data(max_x, max_y)
coord_text.set_text(f'Max Coordinate: ({max_x:.2f}, {max_y:.2f})')
return line, text, max_point, coord_text
# 创建动画
ani = FuncAnimation(fig, update, frames=len(degrees_of_freedom), interval=500, blit=True)
# 显示动画
plt.xlabel('X')
plt.ylabel('Probability Density')
plt.grid(True)
plt.show()
在概率密度函数中我加入了密度最大点的坐标,我们可以清楚的看到其随着n的增加逐渐增大,这也能对应其期望和方差的公式n和2n。由于概率密度函数并不能直观的显示我们所学的下侧分位点 χ 1 − α 2 ( n ) \chi_{1-\alpha }^{2}(n) χ1−α2(n),于是我对概率密度曲线进行积分,并用程序将其画出来,并同样标记出了其中斜率最大的点(即概率密度最大的点 d F χ 2 ( n ) ( x ) d x = f χ 2 ( n ) ( x ) \frac{\mathrm{d} F_{\chi ^{2}(n) } (x)}{\mathrm{d} x} =f_{\chi ^{2}(n)}(x) dxdFχ2(n)(x)=fχ2(n)(x)),其图像如下:

在这两张图片中,x轴依然给到了[0,50]的范围,但是y轴由于含义不一样,所需要的取值范围也不一样,在概率密度函数中由于最大值一直小于0.5而在概率分布函数中,概率取值为[0,1]。在上面的两张图像中我们可以清楚的看到两张图片中的max coordinate的x坐标是几乎相同的,证明两种方法所求出的特征点是一样的,均随着n的增加逐渐增大,但始终小于n。
概率分布函数源码
继续拿!
import numpy as np
import matplotlib.pyplot as plt
from matplotlib.animation import FuncAnimation
from scipy.stats import chi2
# 设置自由度范围
degrees_of_freedom = np.arange(1, 20)
# 定义颜色列表
colors = ['b', 'g', 'r', 'c', 'm', 'y', 'k', 'purple', 'orange']
# 生成 x 值范围
x = np.linspace(0, 50, 500)
# 创建画布和轴
fig, ax = plt.subplots()
# 初始化线条对象
line, = ax.plot([], [])
# 初始化文本框对象
text = ax.text(0.7, 0.9, '', transform=ax.transAxes)
# 设置坐标轴范围
ax.set_xlim(0, 50)
ax.set_ylim(0, 1)
# 初始化最大点标记
max_point = ax.plot([], [], 'ro', markersize=8)[0]
# 初始化文本框显示最大点坐标
coord_text = ax.text(0.2, 0.8, '', transform=ax.transAxes, fontsize=12)
# 更新函数,用于每帧更新数据和曲线
def update(frame):
n = degrees_of_freedom[frame] # 获取当前自由度值
pdf = chi2.cdf(x, n) # 计算当前自由度下的概率密度函数值
line.set_data(x, pdf) # 更新曲线数据
if frame > 8: # 取模进行循环,防止越界
frame = frame % 8
line.set_color(colors[frame])
text.set_text(f'n={n}') # 更新文本框内容
text.set_fontsize(16)
text.set_color(colors[frame])
ax.set_title('Chi-Square Distribution') # 更新标题
# 找到概率密度函数的导数
derivative = np.gradient(pdf, x)
# 找到导数的最大值索引
max_index = np.argmax(derivative)
max_x = x[max_index]
max_y = pdf[max_index]
# 更新最大点的坐标
max_point.set_data(max_x, max_y)
coord_text.set_text(f'Max Coordinate: ({max_x:.2f}, {max_y:.2f})')
return line, text, max_point, coord_text
# 创建动画
ani = FuncAnimation(fig, update, frames=len(degrees_of_freedom), interval=500, blit=True)
# 显示动画
plt.xlabel('X')
plt.ylabel('Cumulative Probability')
plt.grid(True)
plt.show()
加入期望(下测分位点同理)
由于概率密度峰值点在实际使用中并没有太高的使用频率,所以我改进了一下代码,继续使用chi2的模块进行增加代码片(在update函数里面),实现了如下图的效果,(其中绿色的是mean coordinate也就是期望值,红色的依然是概率密度最大值):

在图中能清楚的看到
E
(
X
)
=
n
E(X) = n
E(X)=n这一性质,mean的横坐标一直等于自由度n,并且由于方差变大,期望点所对应的概率分布函数值逐渐降低,但变化率并不大。
概率分布函数增加期望的代码
# 初始化期望点标记
mean_point = ax.plot([], [], 'go', markersize=8)[0]
# 初始化文本框显示期望点坐标
mean_text = ax.text(0.2, 0.75, '', transform=ax.transAxes, fontsize=12)
# 更新函数,用于每帧更新数据和曲线
def update(frame):
n = degrees_of_freedom[frame] # 获取当前自由度值
pdf = chi2.cdf(x, n) # 计算当前自由度下的概率密度函数值
line.set_data(x, pdf) # 更新曲线数据
if frame > 8: # 取模进行循环,防止越界
frame = frame % 8
line.set_color(colors[frame])
text.set_text(f'n={n}') # 更新文本框内容
text.set_fontsize(16)
text.set_color(colors[frame])
ax.set_title('Chi-Square Distribution') # 更新标题
# 找到概率密度函数的导数
derivative = np.gradient(pdf, x)
# 找到导数的最大值索引
max_index = np.argmax(derivative)
max_x = x[max_index]
max_y = pdf[max_index]
# 更新最大点的坐标
max_point.set_data(max_x, max_y)
coord_text.set_text(f'Max Coordinate: ({max_x:.2f}, {max_y:.2f})')
# 计算期望值
mean_value = chi2.mean(n)
mean_point.set_data(mean_value, chi2.cdf(mean_value, n))
mean_text.set_text(f'Mean Coordinate: ({mean_value:.2f}, {chi2.cdf(mean_value, n):.2f})')
return line, text, max_point, coord_text, mean_point, mean_text
加入下测分位点
在假设检验和构建区间时i,我们经常用到查表的方法,但同样,下侧分位点我们也可以用程序的方法将其显示在函数图像上面,并且可以对所需要的
α
\alpha
α进行更改。
通过调整quantile_value = chi2.ppf(0.95, n)这句代码中的0.95也就是对
1
−
α
1-\alpha
1−α进行更改,即可得到不同的分位点,与表中值对比,是相符合的。效果如下图所示(其中蓝色的是下册分位点,
1
−
α
=
0.95
1-\alpha=0.95
1−α=0.95):

加入下侧分位点的源码
# 初始化下侧分位点标记
quantile_point = ax.plot([], [], 'bo', markersize=8)[0]
# 初始化文本框显示下侧分位点坐标
quantile_text = ax.text(0.2, 0.7, '', transform=ax.transAxes, fontsize=12)
# 更新函数,用于每帧更新数据和曲线
def update(frame):
n = degrees_of_freedom[frame] # 获取当前自由度值
pdf = chi2.cdf(x, n) # 计算当前自由度下的概率密度函数值
line.set_data(x, pdf) # 更新曲线数据
if frame > 8: # 取模进行循环,防止越界
frame = frame % 8
line.set_color(colors[frame])
text.set_text(f'n={n}') # 更新文本框内容
text.set_fontsize(16)
text.set_color(colors[frame])
ax.set_title('Chi-Square Distribution') # 更新标题
# 找到概率密度函数的导数
derivative = np.gradient(pdf, x)
# 找到导数的最大值索引
max_index = np.argmax(derivative)
max_x = x[max_index]
max_y = pdf[max_index]
# 更新最大点的坐标
max_point.set_data(max_x, max_y)
coord_text.set_text(f'Max Coordinate: ({max_x:.2f}, {max_y:.2f})')
# 计算期望值
mean_value = chi2.mean(n)
mean_point.set_data(mean_value, chi2.cdf(mean_value, n))
mean_text.set_text(f'Mean: ({mean_value:.2f}, {chi2.cdf(mean_value, n):.2f})')
# 计算下侧分位点
quantile_value = chi2.ppf(0.95, n)
quantile_point.set_data(quantile_value, chi2.cdf(quantile_value, n))
quantile_text.set_text(f'Quantile: ({quantile_value:.2f}, {chi2.cdf(quantile_value, n):.2f})')
return line, text, max_point, coord_text, mean_point, mean_text, quantile_point, quantile_text
结语
本次卡方分布的图形化,到此也逐渐完善,希望下次也可以用图形化的方式获得更多收获。
概率统计是一门很有意思的课,老师上课讲解的也很细致,我也在这门课上通过课堂笔记和思维导图学到了很多知识,希望能在以后的学习和科研生涯中,将理论用于实际,获得更多的收获。

















 1816
1816

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









