






先读表
df = pd.read_csv('ex1data1.txt',names=['人口','利润'])
df.head()#默认读前5行
绘制散点图,观察原始数据,一个蓝点代表一个数据
import matplotlib.pyplot as plt
plt.rcParams['font.sans-serif'] =["SimHei"]#设置字体,防止乱码
sns.lmplot('人口','利润',data=df,height=6,fit_reg = False)
#fit_reg:拟合回归参数,如果fit_reg=True则散点图中则出现拟合直线
plt.show()

到这为止,对现有的数据集已有了大致的了解,接下来我们要通过对现有数据集的训练得到适合我们预测的模型。
首先我们要计算代价函数(目的寻找最合适的参数是使代价函数最小):

其中:h为hypothesis,假设的模型。
![]()
定义代价函数:
def computeCost (X,y,theta):
inner=np.power((X*theta.T)-y,2)
#theta.T就是矩阵theta的转置矩阵
#np.power(A,B) ## 对A中的每个元素求B次方
return np.sum(inner)/(2*len(X))下面对变量进行初始化:
#设置训练值变量X和目标变量y
cols=df.shape[1] #获取表格df的列数,因为shape只有两个元组变量(行和列),所以shape[1]就是列
X=df.iloc[:,0:cols-1] #除最后一列外,取其他列的所有行,即X为O和人口组成的列表,虽然本例子只有一个参数
y=df.iloc[:,cols-1:cols]#取最后一列的所有行,即y为利润代价函数是numpy矩阵,所以我们需要转换X和Y,然后才能使用它们。 我们还需要初始化theta。
X = np.matrix(X.values)
y = np.matrix(y.values)
theta = np.matrix(np.array([0,0]))#设置theta初始值为0调用刚定义的 computeCost 函数计算当前参数(theta=0)时的代价函数:
computeCost (X,y,theta)返回值为:32.072733877455676,此时我们还没有开始训练数据。
接下来使用batch gradient decent(批量梯度下降)算法训练得到合适的参数,梯度下降是一个用来求函数最小值的算法,我们将使用梯度下降算法来求出代价函数 𝐽(𝜃0, 𝜃1) 的最小值。

想象一下你正站立在山的这一点上,站立在你想象的公园这座红色山上,在梯度下降算 法中,我们要做的就是旋转 360 度,看看我们的周围,并问自己要在某个方向上,用小碎步 尽快下山。这些小碎步需要朝什么方向?如果我们站在山坡上的这一点,你看一下周围,你会发现最佳的下山方向,你再看看周围,然后再一次想想,我应该从什么方向迈着小碎步下 山?然后你按照自己的判断又迈出一步,重复上面的步骤,从这个新的点,你环顾四周,并 决定从什么方向将会最快下山,然后又迈进了一小步,并依此类推,直到你接近局部最低点的位置。
批量梯度下降(batch gradient descent)算法的公式为:

描述:对𝜃赋值,使得𝐽(𝜃)按梯度下降最快方向进行,一直迭代下去,最终得到局部最 小值。其中𝑎是学习率(learning rate),它决定了我们沿着能让代价函数下降程度最大的方向向下迈出的步子有多大。
如果𝑎太小了,即我的学习速率太小,结果就是只能这样像小宝宝一样一点点地挪动, 去努力接近最低点,这样就需要很多步才能到达最低点,所以如果𝑎太小的话,可能会很慢, 因为它会一点点挪动,它会需要很多步才能到达全局最低点。 如果𝑎太大,那么梯度下降法可能会越过最低点,甚至可能无法收敛,下一次迭代又移 动了一大步,越过一次,又越过一次,一次次越过最低点,直到你发现实际上离最低点越来越远,所以,如果𝑎太大,它会导致无法收敛,甚至发散。
梯度下降算法代码:
def gradientDescent(X,y,theta,alpha,iters): #alpha是学习率,iters为迭代次数
temp=np.matrix(np.zeros(theta.shape)) #np.zeros(theta.shape)=[0.,0.],然后将temp变为矩阵[0.,0.]
parameters= int(theta.ravel().shape[1])
#theta.ravel():将多维数组theta降为一维,.shape[1]是统计这个一维数组有多少个元
#parameters表示参数
cost=np.zeros(iters) #初始化代价函数值为0数组,元素个数为迭代次数
for i in range(iters): #循环iters次
error=(X*theta.T)-y
for j in range(parameters):
term = np.multiply(error, X[:,j]) #将误差与训练数据相乘,term为偏导数,参考笔记P27
temp[0,j] = theta[0,j] - ((alpha / len(X)) * np.sum(term)) #更新theta
theta=temp
cost[i] = computeCost(X,y,theta) #计算每一次的代价函数
return theta,cost初始化一些附加变量,比如学习速率α和要执行的迭代次数。
alpha=0.01
iters=1500现在让我们运行梯度下降算法来将我们的参数θ适合于训练集。
g, cost = gradientDescent(X, y, theta, alpha, iters) #令g和cost分别等于函数的两个返回值
g
costg的值为:matrix([[-3.63029144, 1.16636235]])
cost的值为:array([6.73719046, 5.93159357, 5.90115471, ..., 4.48343473, 4.48341145, 4.48338826])一共1500个值。
最后,我们可以使用我们拟合的参数计算训练模型的代价函数(误差)。
computeCost(X, y, g) #最小化的低价函数
#输出:4.483388256587726可以与刚开始设置参数(theta=0)时的代价函数对比,训练之后的cost=4.483388256587726 没训练的时候cost=32.072733877455676 差距还是挺大的
代价数据可视化:通过绘图观察代价函数与迭代次数之间的关系
fig, ax = plt.subplots(figsize=(12,8)) #以其他关键字参数**fig_kw来创建图
#figsize=(a,b):figsize 设置图形的大小,b为图形的宽,b为图形的高,单位为英寸
ax.plot(np.arange(iters), cost, 'r') #作图:以迭代次数为x,代价函数值为y,线条颜色为红色
ax.set_xlabel('Iterations') #设置x轴变量
ax.set_ylabel('Cost') #设置y轴变量
ax.set_title('Error vs. Training Epoch') #设置表头
plt.show()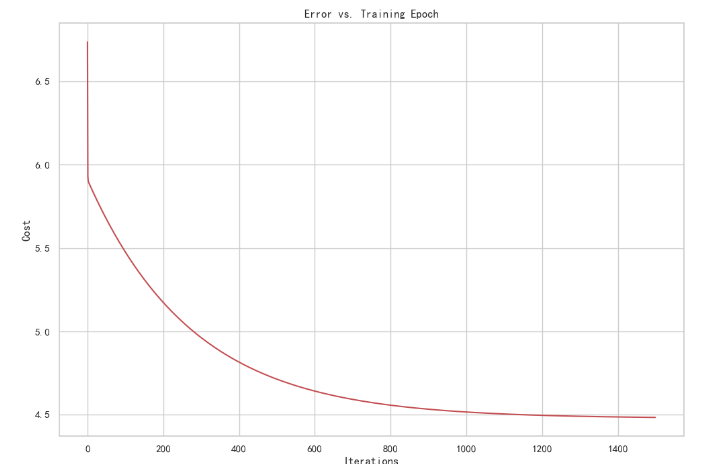
最后我们来绘制线性模型以及数据,直观地看出它的拟合(使用训练得到的参数)。
x = np.linspace(df.人口.min(),df.人口.max(),100)#以人口最小值为起点,最大值为终点,创建元素个数为100的等差数列
f = g[0,0] + (g[0,1] * x) #f是假设函数H
fig, ax = plt.subplots(figsize=(12,8))#以其他关键字参数**fig_kw来创建图
#figsize=(a,b):figsize 设置图形的大小,b为图形的宽,b为图形的高,单位为英寸
ax.plot(x, f, 'r', label='Prediction') #设置点的横坐标,纵坐标,用红色线,并且设置Prediction为关键字参数
ax.scatter(df.人口, df.利润, label='Traning Data') #以人口为横坐标,利润为纵坐标并且设置Traning Data为关键字参数
ax.legend(loc=2) #legend为显示图例函数,loc为设置图例显示的位置,loc=2即在左上方
ax.set_xlabel('Population') #设置x轴变量
ax.set_ylabel('Profit') #设置x轴变量
ax.set_title('Predicted Profit vs. Population Size') #设置表头
plt.show()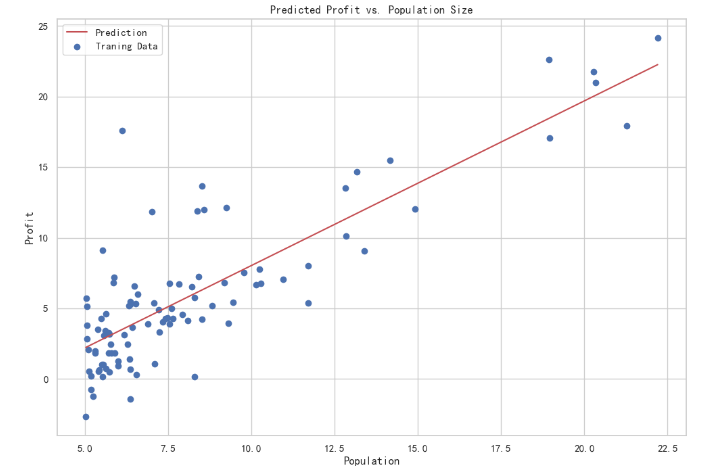














 6137
6137











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









