







Grid-world网格世界的例子
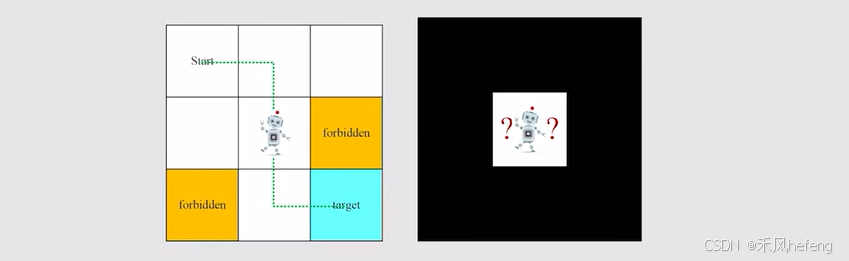
这个例子的任务就是找到比较好的路径从起点到终点。那么,如何定义“好”呢?在寻求更短路径的条件下,我们需要避免forbidden area,避免超越boundary。
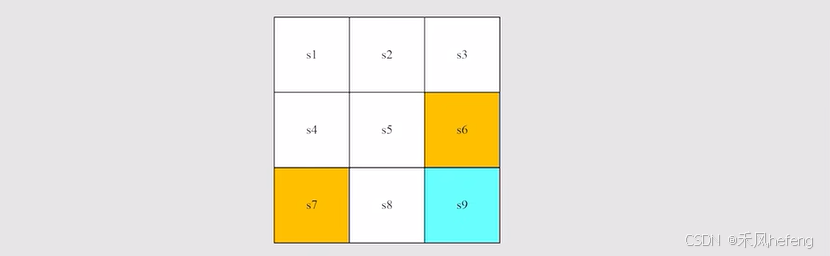
State:描述的就是agent相对于环境中的状态,在grid-world例子中,agent的位置就是状态,。
State space:所有状态的集合 。
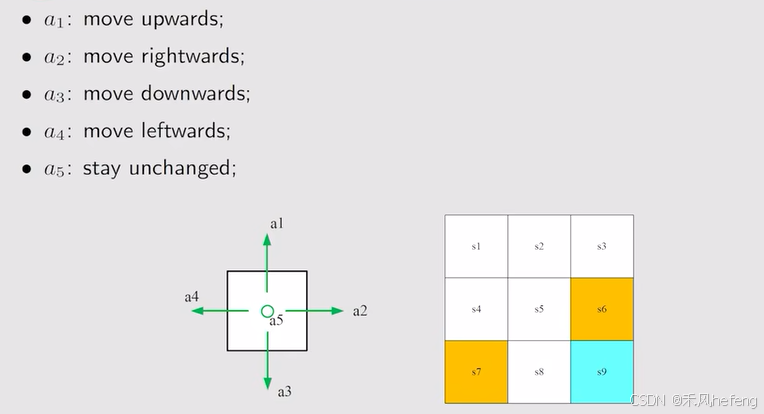
Action:对于每个状态会有一系列的可采取的行动。
Action space of a state:一个状态上所有可能行动的集合。
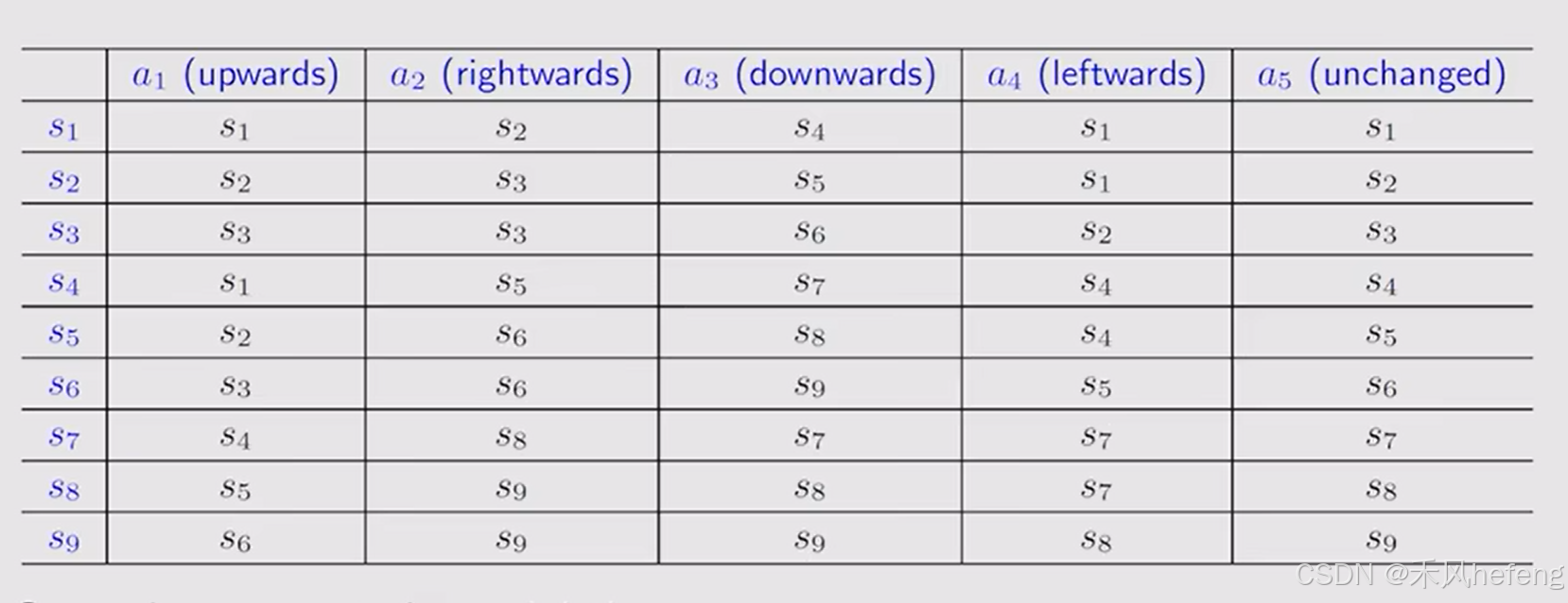
Sate transition:当采取一个行动时,agent从一个状态到达另一个状态。例如,从跳到了
:
。
- Forbidden area:当forbidden area可以进入但是会被惩罚时,
;当forbidden area不能进入时,
。
- Tabular representation:
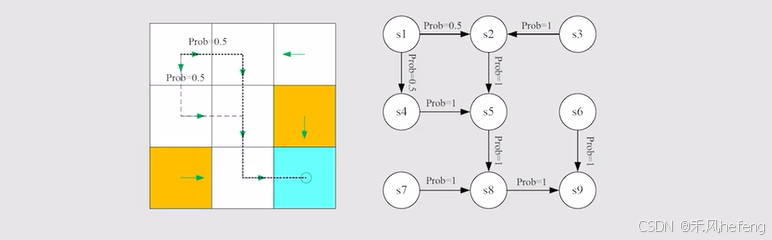
- State transition probability:在状态
采取行动
,下一个状态就是
。
,
。
Policy:告诉agent在一个状态上应该采取什么样的行动。

例子:
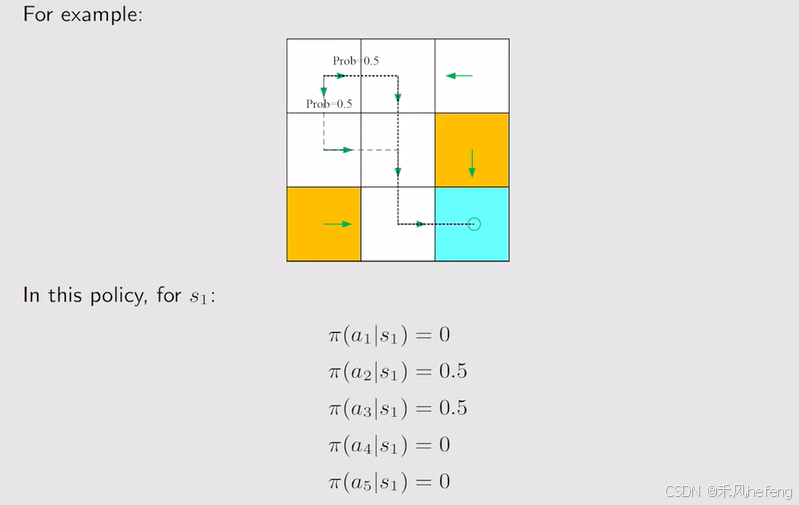
Reward:是一个实数、标量,如果数为正数,则鼓励这种行为,如果数为负数,则惩罚这种行为。当数值为0的时候,表示没有乘法。从某种意义上讲,正数也可以代表惩罚,负数也可以表示鼓励,这时候agent就希望要更小的reward。
- 如果agent尝试去走出边界,则
。
- 如果agent尝试进入forbidden area,则
。
- 如果agent到达target area,则
。
- 其他情况下,agent得到reward为
。
- Tabular representation:
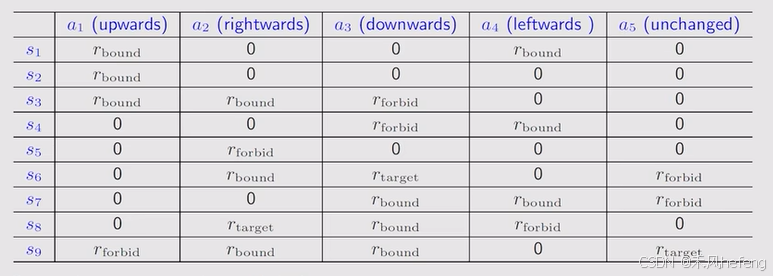
- Mathematical description:在状态
,可以得到reward
,数学上表示为
。
Trajectory:是一种state-action-reward 链,。
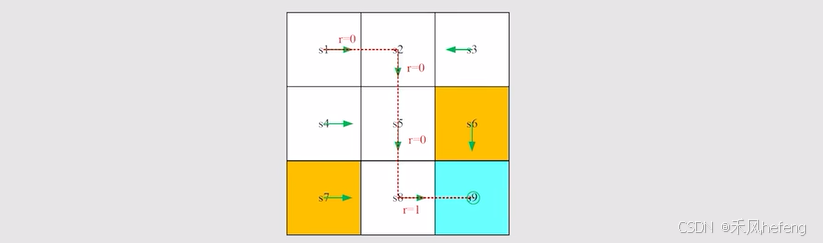
Return:trajectory上reward的总和
Discounted return:trajectory可能是无穷的,return是
。如何解决这个问题呢?我们可以引入discounted rate
,
discounted return则为
。
Episode:会伴随概念terminal state,当agent遵循一个policy与环境进行交互时,agent可能停止在某些terminal state上,而最终导致的trajectory称作episode,。
Markov decision process(MDP)有很多要素:
- 集合:
- State:状态S的集合。
- Action:行为
的集合。
- Reward:奖励
的集合。
- 概率分布:
- Sate transition probability 状态转移概率:
- Reward probability奖励概率:
- Policy:
- Markov property(无记忆):
,
参考资料:


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









