







这里分享一下学习YOLOPOSE自定义关键点以及自己写修改label文件的脚本的过程,记录了一些踩过的坑。最后我分享了自己做的数据集label修改脚本,欢迎有需要的同学使用。
本文参考这位博主的方法,并修复了一些问题
https://zhuanlan.zhihu.com/p/603799078
一、代码修改
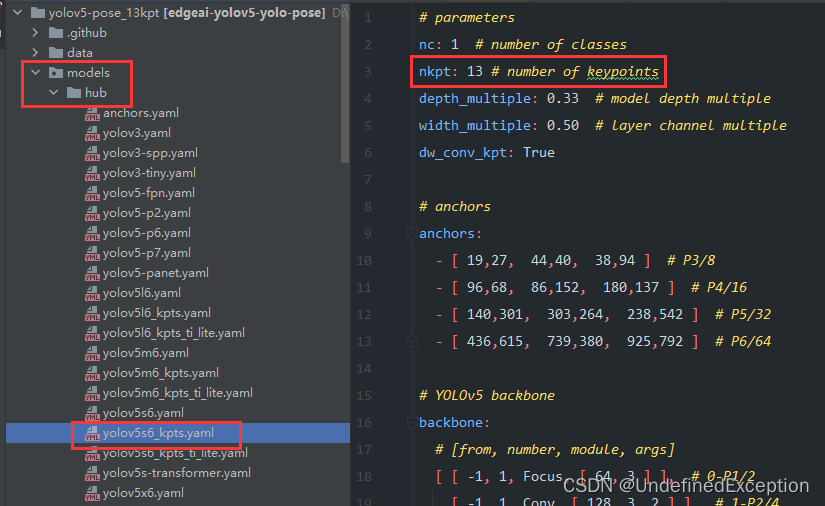
1.1 修改模型(yaml文件)
我想只用13个关键点,除去了腿部的四个关键点:
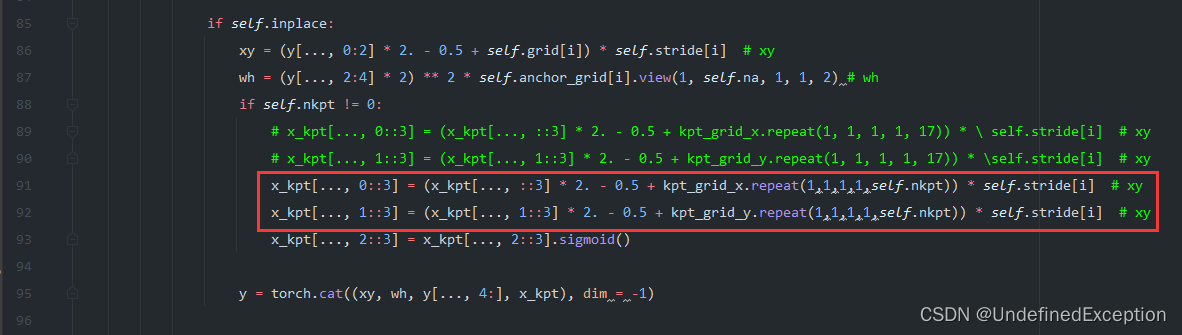
1.2 修改models/yolo.py
修改Detect类的forward函数中的这一部分。self.nkpt 即模型的yaml中定义的关键点数量
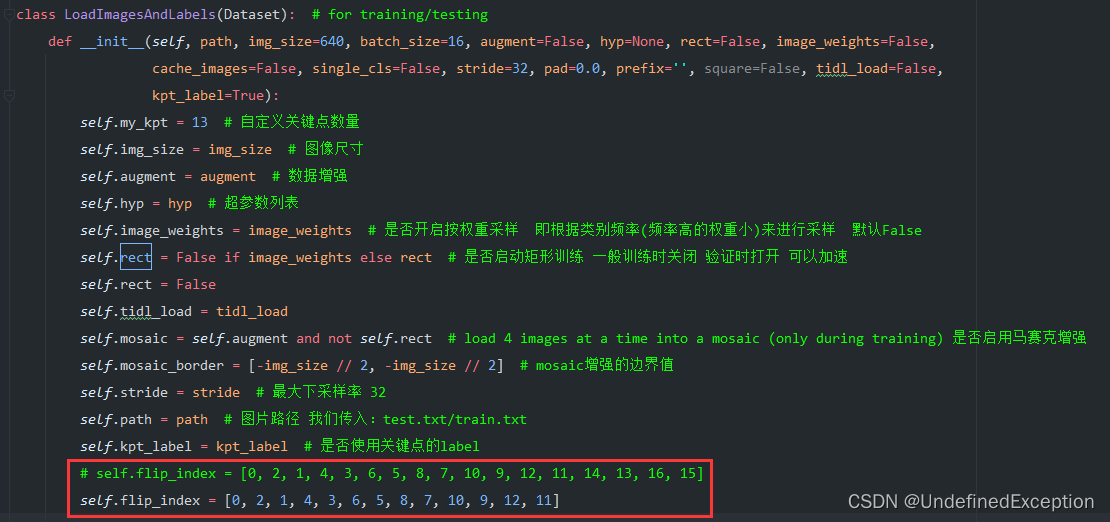
1.3 修改utils/dataset.py
修改LoadImagesAndLabels类的init函数。这个参数涉及到左右反转训练,根据自己需要添加或删除关键点。
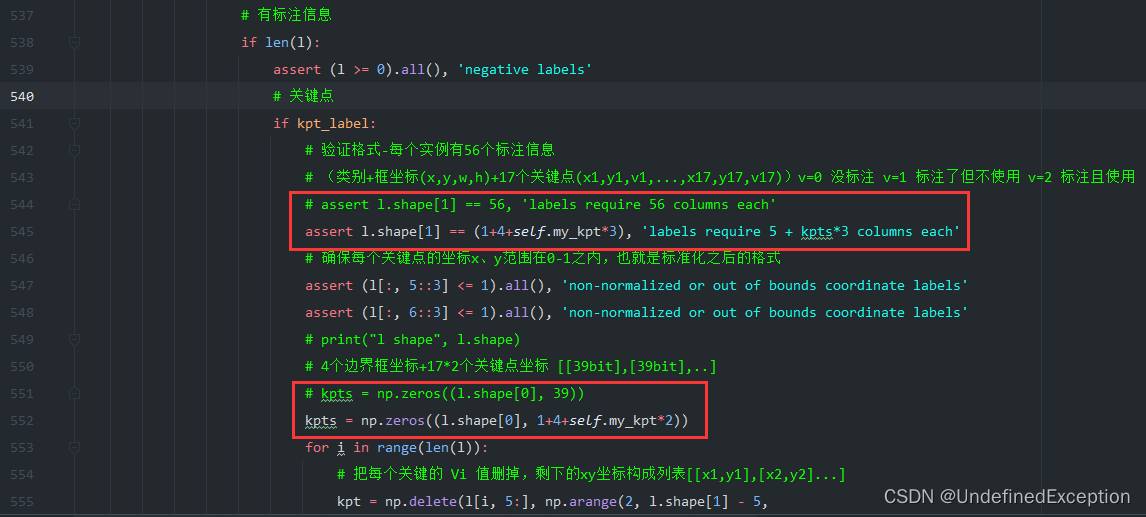
修改cache_labels函数。my_kpt参数我自定义的关键点数量
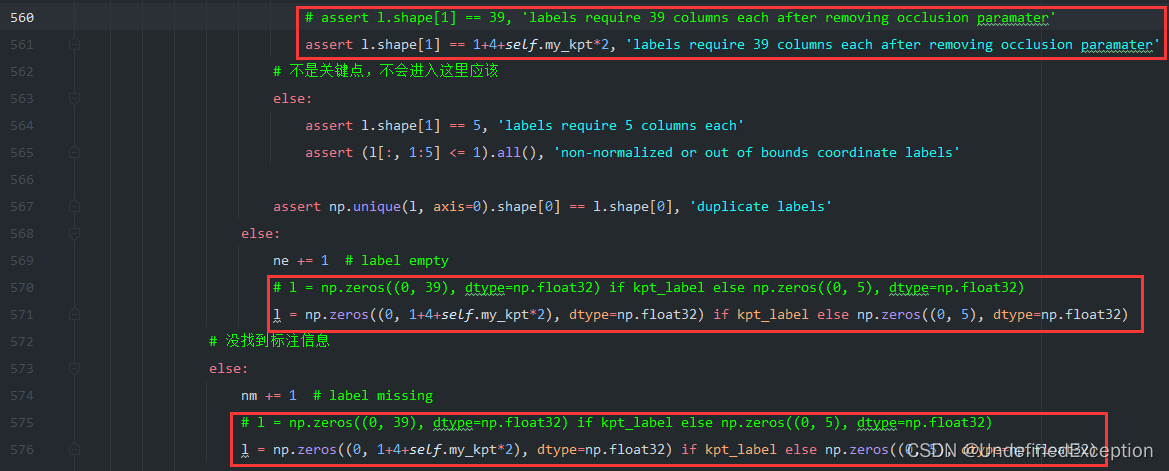
修改random_perspective函数。
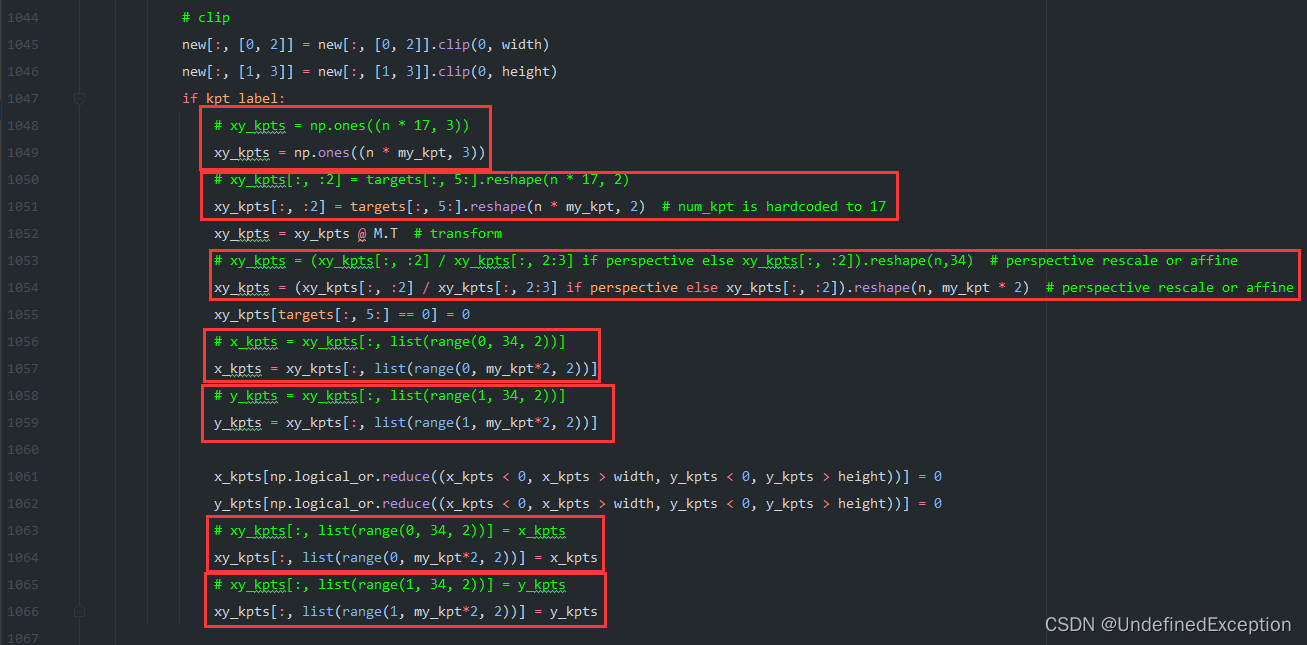
1.4 修改utils/loss.py
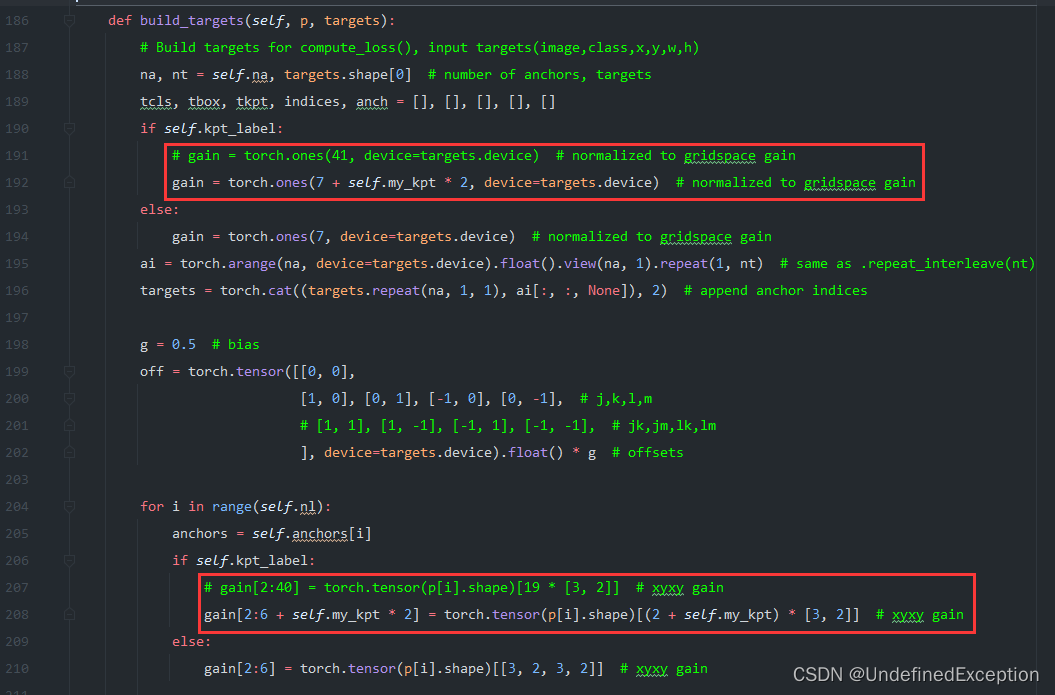
找到ComputeLoss类的build_targets函数。my_kpt 参数还是我定义的
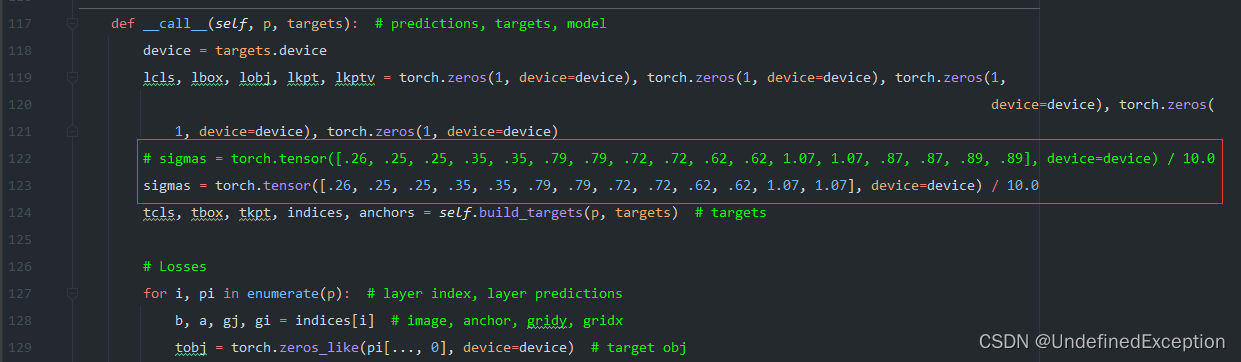
然后修改call函数的sigmas,让sigmas元素个数等于关键点的数量,是惩罚项。
1.5 修改models/common.py
不理解为啥要加这个,加就是了
class SPPF(nn.Module):
# Spatial Pyramid Pooling - Fast (SPPF) layer for YOLOv5 by Glenn Jocher
def __init__(self, c1, c2, k=5): # equivalent to SPP(k=(5, 9, 13))
super().__init__()
c_ = c1 // 2 # hidden channels
self.cv1 = Conv(c1, c_, 1, 1)
self.cv2 = Conv(c_ * 4, c2, 1, 1)
self.m = nn.MaxPool2d(kernel_size=k, stride=1, padding=k // 2)
def forward(self, x):
x = self.cv1(x)
with warnings.catch_warnings():
warnings.simplefilter('ignore') # suppress torch 1.9.0 max_pool2d() warning
y1 = self.m(x)
y2 = self.m(y1)
return self.cv2(torch.cat([x, y1, y2, self.m(y2)], 1))1.6(重要)修改utils.plot函数
在这里卡了好长时间,训练一直报错。原文中没有具体说修改哪些,debug好长时间终于好了!!!
1.修改plot_images函数。我定义的关键点数量是13,减去了4个,因此40改成40-4*2=32
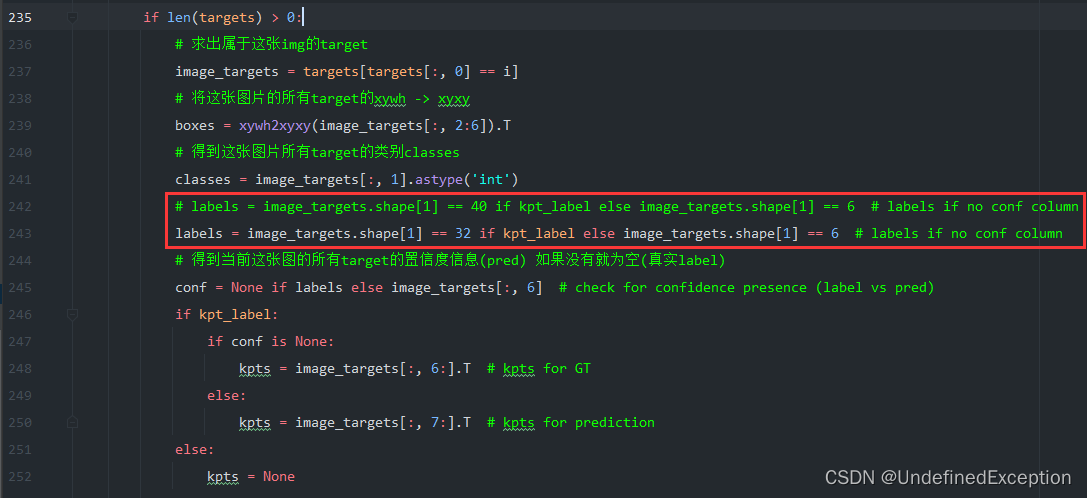
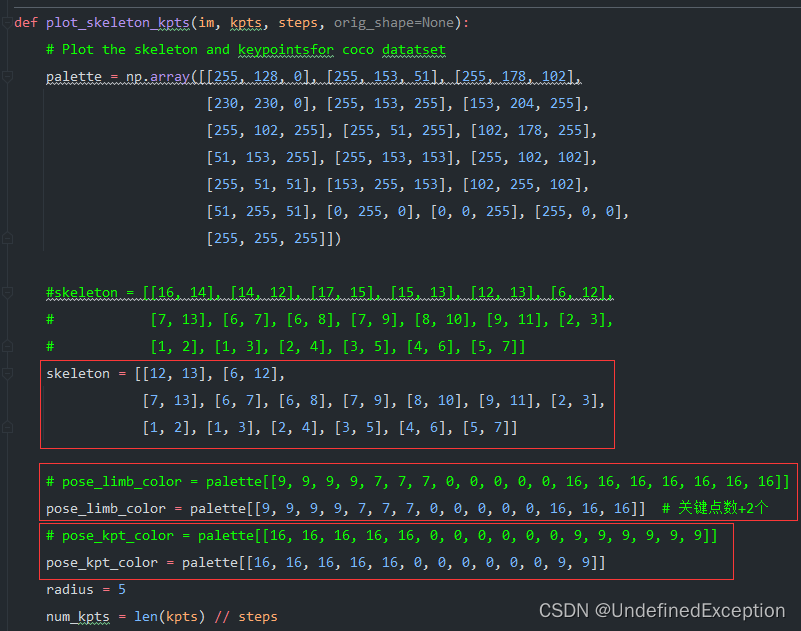
2.修改plot_skeleton_kpts函数。
skeleton存储了关键点间的联系,需要删除不需要的关键点,比如我使用1-13关键点,其他的都删掉。
下面两个列表的元素数量分别为kpt数量+2以及kpt数量
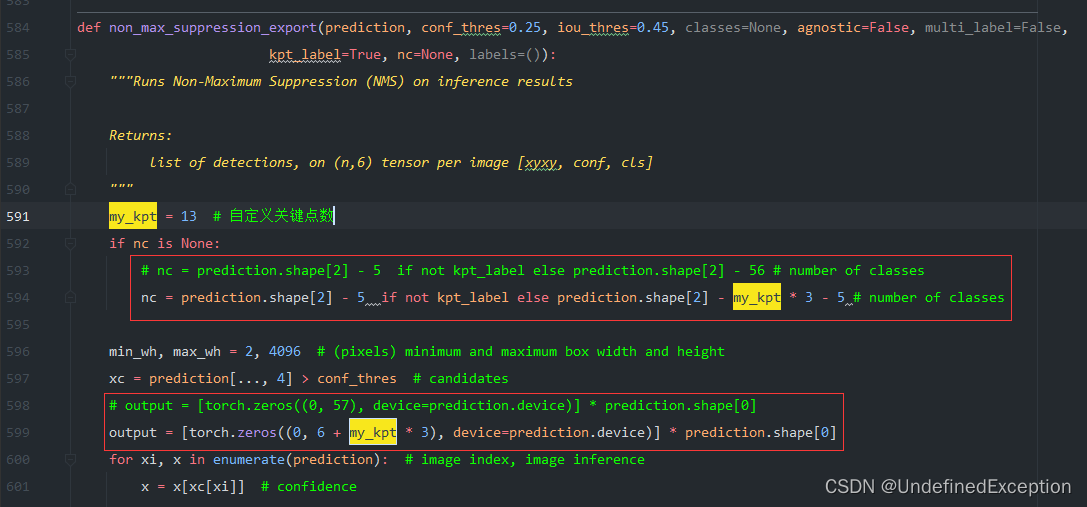
1.7 修改utils/general.py
修改non_max_suppression函数
onnx相关的暂时不需要,先不管他。
二、数据集修改
YOLOPose提供了yolo格式的数据格式,我希望把所有图片的关键点label由17个改为13个。先看一下label文件的结构:
0 0.535530 0.308733 0.206900 0.317147 0.000000 0.000000 0.000000 0.000000 0.000000 0.000000 0.000000 0.000000 0.000000 0.514000 0.194667 2.000000 0.534000 0.213333 2.000000 0.482000 0.224000 2.000000 0.526000 0.229333 2.000000 0.462000 0.186667 2.000000 0.568000 0.210667 2.000000 0.446000 0.165333 2.000000 0.610000 0.184000 2.000000 0.462000 0.336000 2.000000 0.498000 0.341333 2.000000 0.462000 0.368000 2.000000 0.536000 0.290667 2.000000 0.460000 0.453333 2.000000 0.508000 0.376000 2.000000
0 0.736090 0.272987 0.189260 0.259413 0.000000 0.000000 0.000000 0.000000 0.000000 0.000000 0.762000 0.184000 2.000000 0.000000 0.000000 0.000000 0.754000 0.178667 2.000000 0.710000 0.176000 2.000000 0.730000 0.178667 2.000000 0.674000 0.189333 2.000000 0.780000 0.202667 2.000000 0.652000 0.218667 2.000000 0.806000 0.205333 2.000000 0.660000 0.245333 2.000000 0.680000 0.250667 2.000000 0.708000 0.304000 2.000000 0.736000 0.293333 2.000000 0.722000 0.365333 2.000000 0.714000 0.373333 2.000000
0 0.146660 0.667293 0.194000 0.441093 0.000000 0.000000 0.000000 0.000000 0.000000 0.000000 0.000000 0.000000 0.000000 0.000000 0.000000 0.000000 0.180000 0.498667 2.000000 0.144000 0.549333 2.000000 0.198000 0.541333 2.000000 0.124000 0.648000 2.000000 0.000000 0.000000 0.000000 0.092000 0.720000 2.000000 0.000000 0.000000 0.000000 0.172000 0.704000 2.000000 0.222000 0.701333 2.000000 0.102000 0.746667 2.000000 0.162000 0.754667 2.000000 0.130000 0.856000 2.000000 0.170000 0.829333 2.000000
这个图片中标注了3组标签,也就是3个人。所有坐标数据都压缩了。每组标签首位是0,代表人类类别。往后数4位是边界框坐标,再往后面的17*3位是关键点信息。每个关键点由x,y,v组成,v代表该点是否可见。一组标注信息共1+4+17*3=56个数字。
我的思路是把每个label文件中每组标签的后12位(4*3=12)去掉,只保留13个关键点。下面是修改后的label文件。每组标签包括56-12=44 个数字组成。
0 0.535530 0.308733 0.206900 0.317147 0.000000 0.000000 0.000000 0.000000 0.000000 0.000000 0.000000 0.000000 0.000000 0.514000 0.194667 2.000000 0.534000 0.213333 2.000000 0.482000 0.224000 2.000000 0.526000 0.229333 2.000000 0.462000 0.186667 2.000000 0.568000 0.210667 2.000000 0.446000 0.165333 2.000000 0.610000 0.184000 2.000000 0.462000 0.336000 2.000000 0.498000 0.341333 2.000000
0 0.736090 0.272987 0.189260 0.259413 0.000000 0.000000 0.000000 0.000000 0.000000 0.000000 0.762000 0.184000 2.000000 0.000000 0.000000 0.000000 0.754000 0.178667 2.000000 0.710000 0.176000 2.000000 0.730000 0.178667 2.000000 0.674000 0.189333 2.000000 0.780000 0.202667 2.000000 0.652000 0.218667 2.000000 0.806000 0.205333 2.000000 0.660000 0.245333 2.000000 0.680000 0.250667 2.000000
0 0.146660 0.667293 0.194000 0.441093 0.000000 0.000000 0.000000 0.000000 0.000000 0.000000 0.000000 0.000000 0.000000 0.000000 0.000000 0.000000 0.180000 0.498667 2.000000 0.144000 0.549333 2.000000 0.198000 0.541333 2.000000 0.124000 0.648000 2.000000 0.000000 0.000000 0.000000 0.092000 0.720000 2.000000 0.000000 0.000000 0.000000 0.172000 0.704000 2.000000 0.222000 0.701333 2.000000
我的COCO数据集放在与项目同一级目录中,在COCO数据集配置文件中定义了label文件夹的地址。
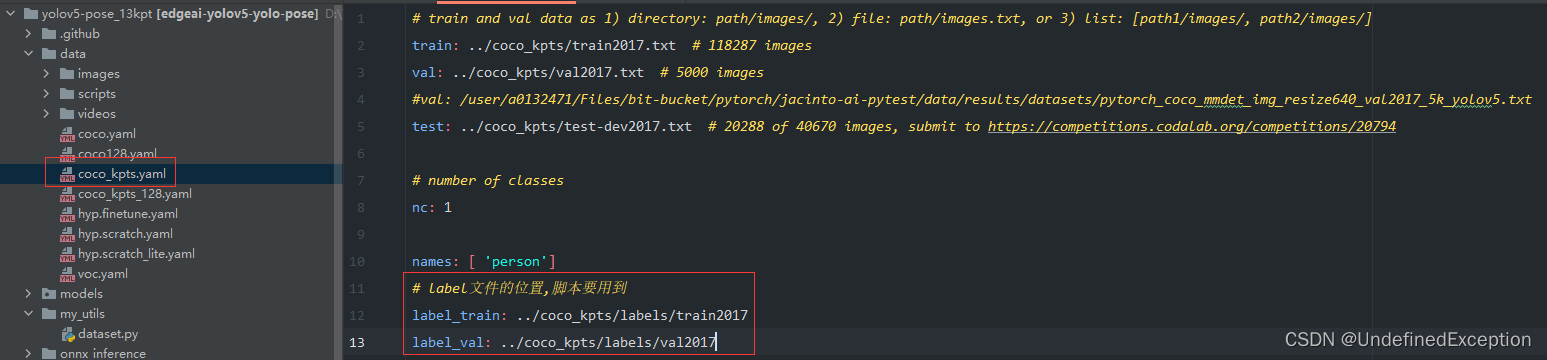
工具放在了这里。除非自己另外修改路径,否则文件夹的位置不要轻易变。
注意:使用脚本前最好把label文件夹备份, 防止数据丢失!下面是工具地址:
master-wz/myUtils: 学习过程中一些自己做的小工具 (github.com)
创作不易,希望能给个star!
三、训练数据可视化
很多时候我们需要查看训练过程中各个指标的变化。yolopose中有tensorboard,但yolopsoe的作者可能忽略了这部分代码的修改,导致很多指标数据是错乱的,因为loss输出的变量数量跟yolov5不一样了。我修改了这部分的标签,但val部分的数据仍然有问题,不过map、PR指标和train的数据是正确的,已经够我用了。
请修改train.py的tag标签如下:
# Log
tags = ['train/box_loss', 'train/obj_loss', 'train/cls_loss','train/ktp_loss','train/kptv_loss','train/loss', # train loss
'metrics/precision','metrics/recall','metrics/mAP_0.5','metrics/mAP_0.5:0.95',
'val/box_loss', 'val/obj_loss', 'val/cls_loss', 'val/ktp_loss', 'val/kptv_loss','val/loss'
'x/lr0', 'x/lr1', 'x/lr2'] # params















 2536
2536

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









