







此文章仅用于学习交流,请勿攻击他人服务器或用于商用贩卖数据,如有违反,自己负责。
环境准备:
python3.7
Pycharm
urillb--->python自带了的
BeautifulSoup ---->需要自己下载(pip install bs4 他是集成在bs4里面的)
注: 1.源码后面都会给出。
2.这里默认大家会用pip指令下载东西,如果不会搜索“pip的安装与使用”,网上有很多详细教程。
爬取思路:
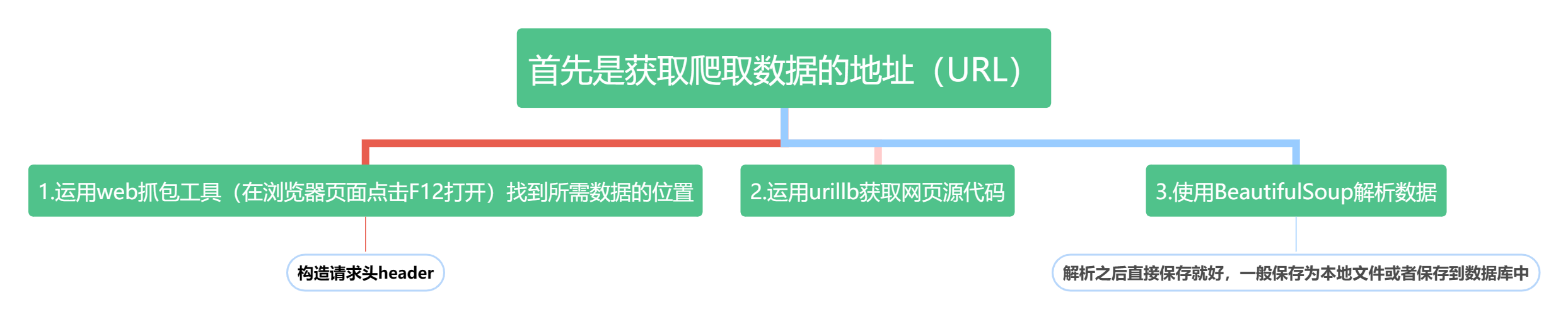
目标地址:
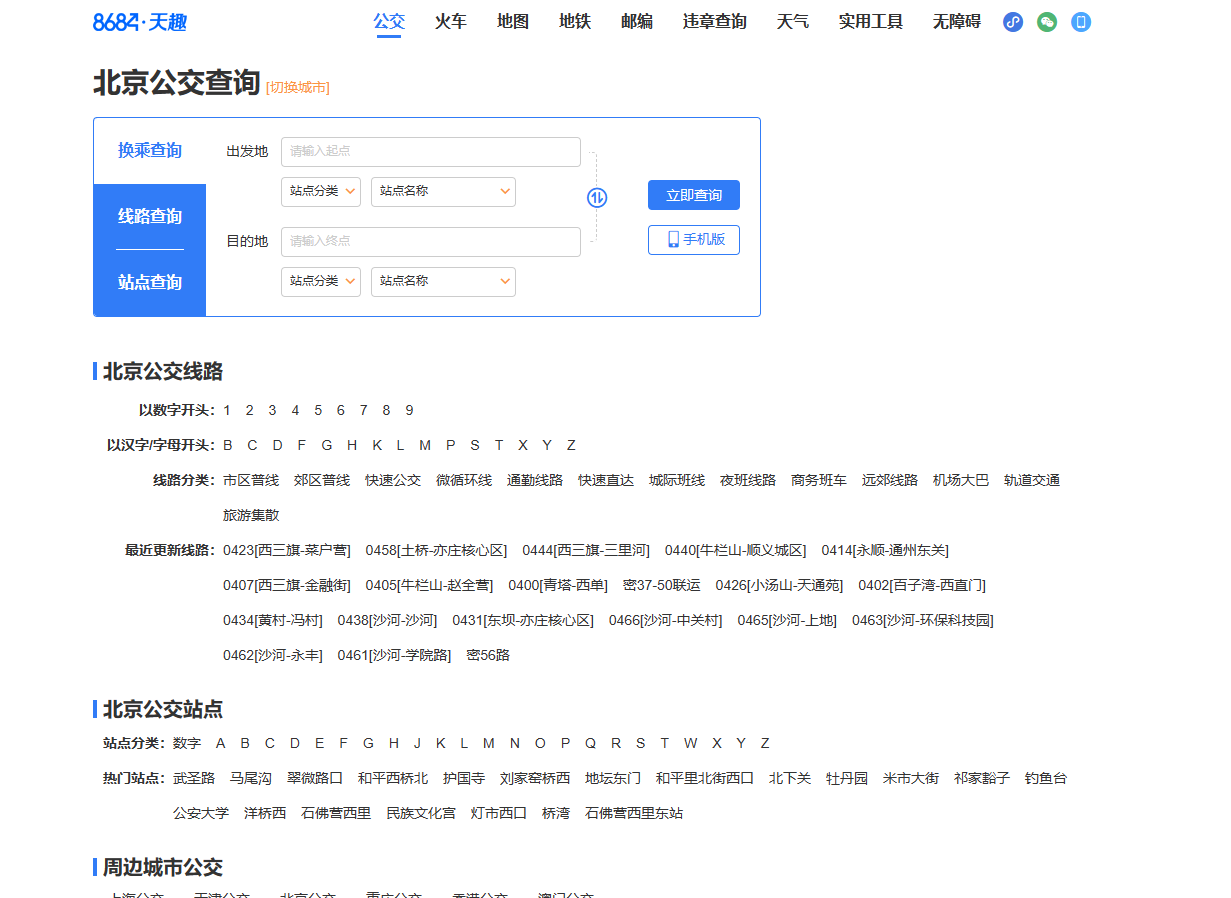
目标网址: https://beijing.8684.cn/
一、打开网址如下:
二、我们点开公交路线(以数字开头)---->多点几个,观察网址的变化
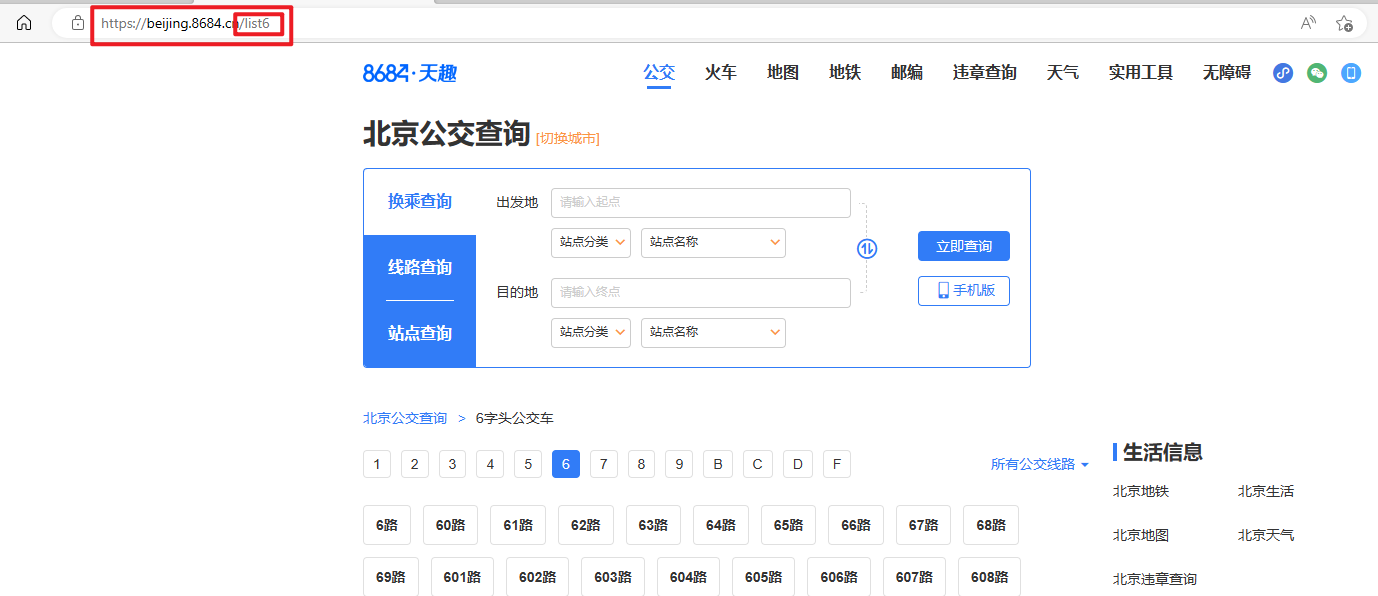
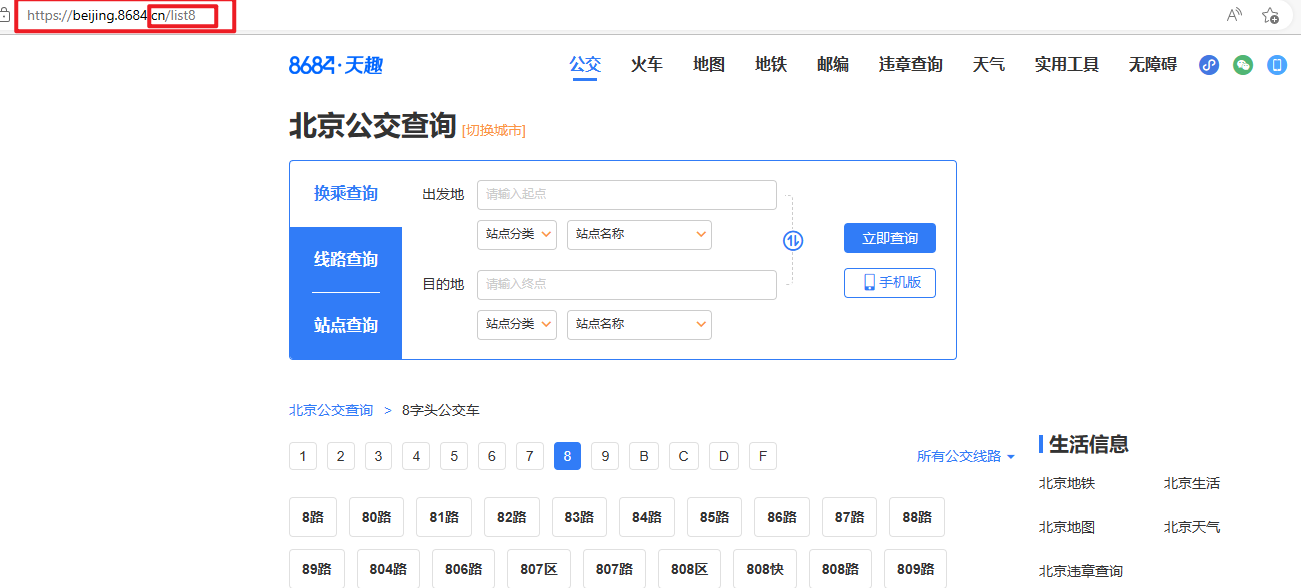
我们不难发现网址的变化为: https://beijing.8684.cn/list8 每次改变list后面的数值
三、之后查看当前页的数据数据展示(点击F12):
按住Ctrl + shift + C之后选中自己想要的数据即可在抓包工具中看到对应的源码
这里我们选中8路点击一下就可以看到源码
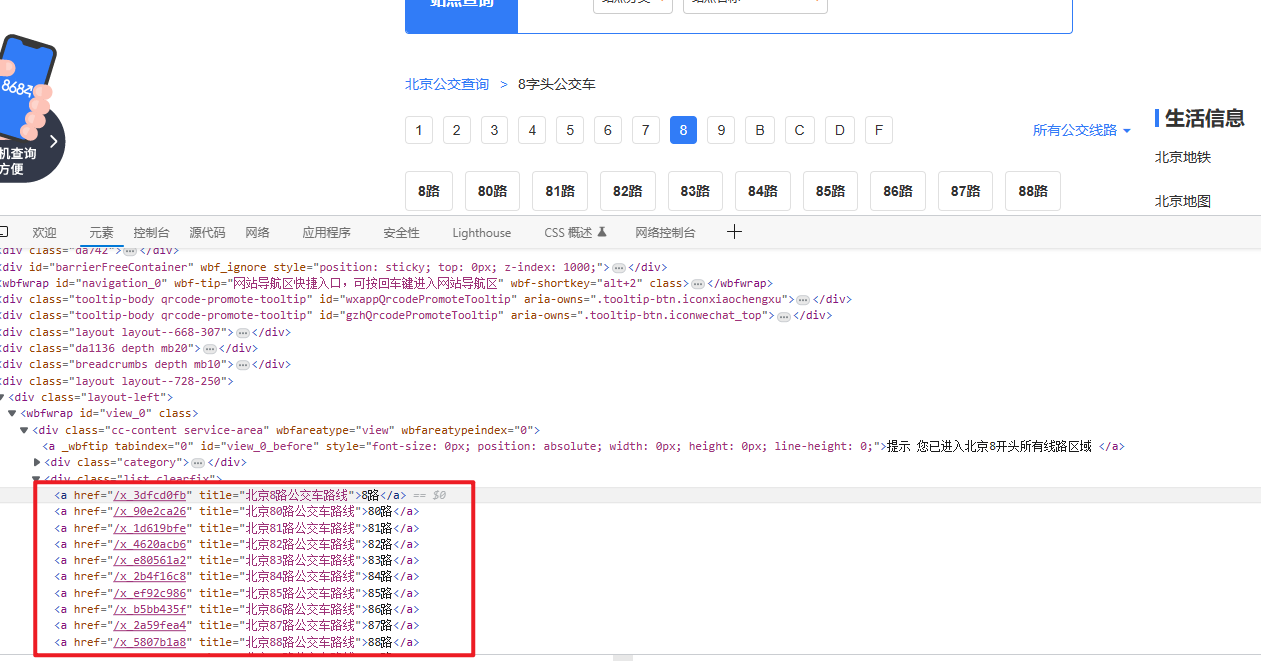
点击8路之后,发现网址和刚源码中的一样,因此我们需要爬取到上一页的公交路线信息,之后在获取每一页的公交信息
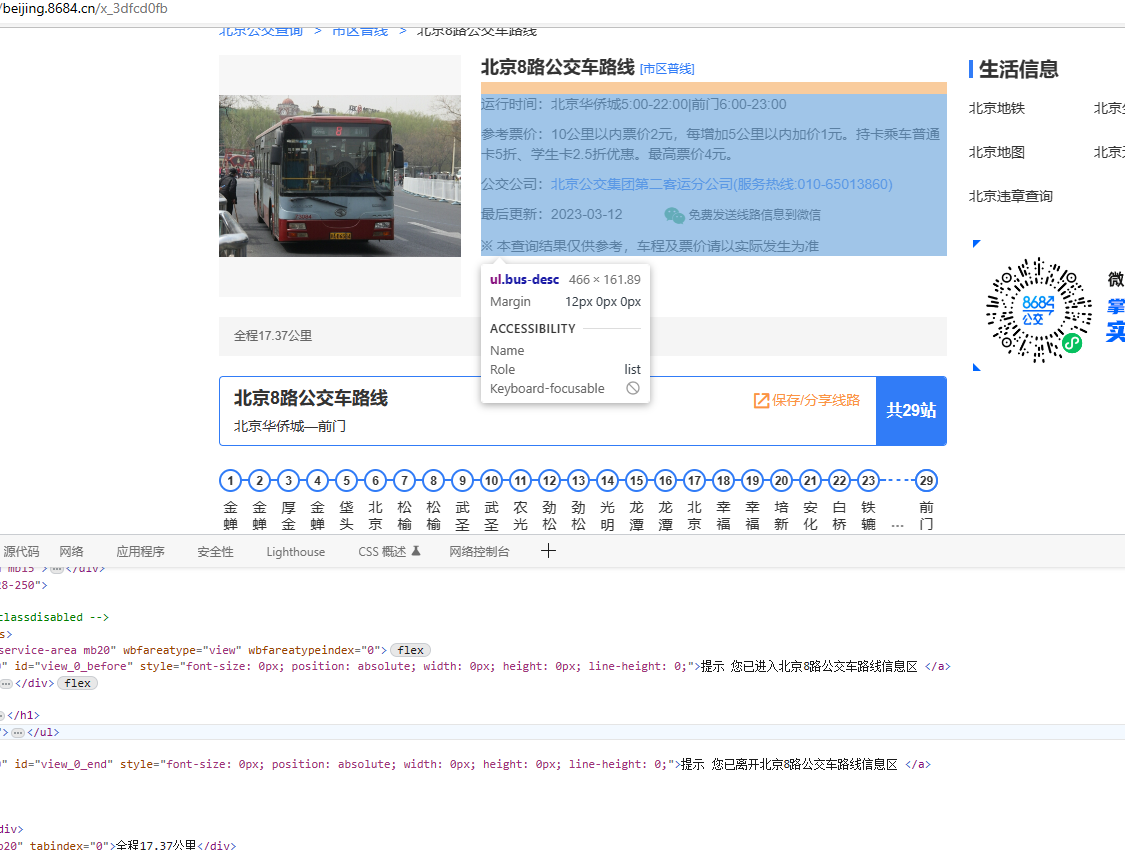
获取并解析第一个目标地址:
这一步主要是为了得到当前数字开头的所有公交信息地址(URL),以便通过改地址解析各自公交的信息
一、定制请求头,写好基础URL地址以便后面复用
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/110.0.0.0 Safari/537.36'
}
url = 'https://beijing.8684.cn/'
url_list = url + '/list%d'二、这里我们并不需要获取单独写方法来构造第一个目标地址,因为list后面的数字就是页数,因此我们只需要将其放到for循环中去就好了,爬取的页数自己定义就好,可以改成控制台输入的方式
if __name__ == '__main__':
for k in range(1, 2):
urls = url_list % k
time.sleep(3)
get_page_url(urls)
print(f'完成{k}个......')三、写一个方法解析第一个目标地址的数据,获取对应公交信息
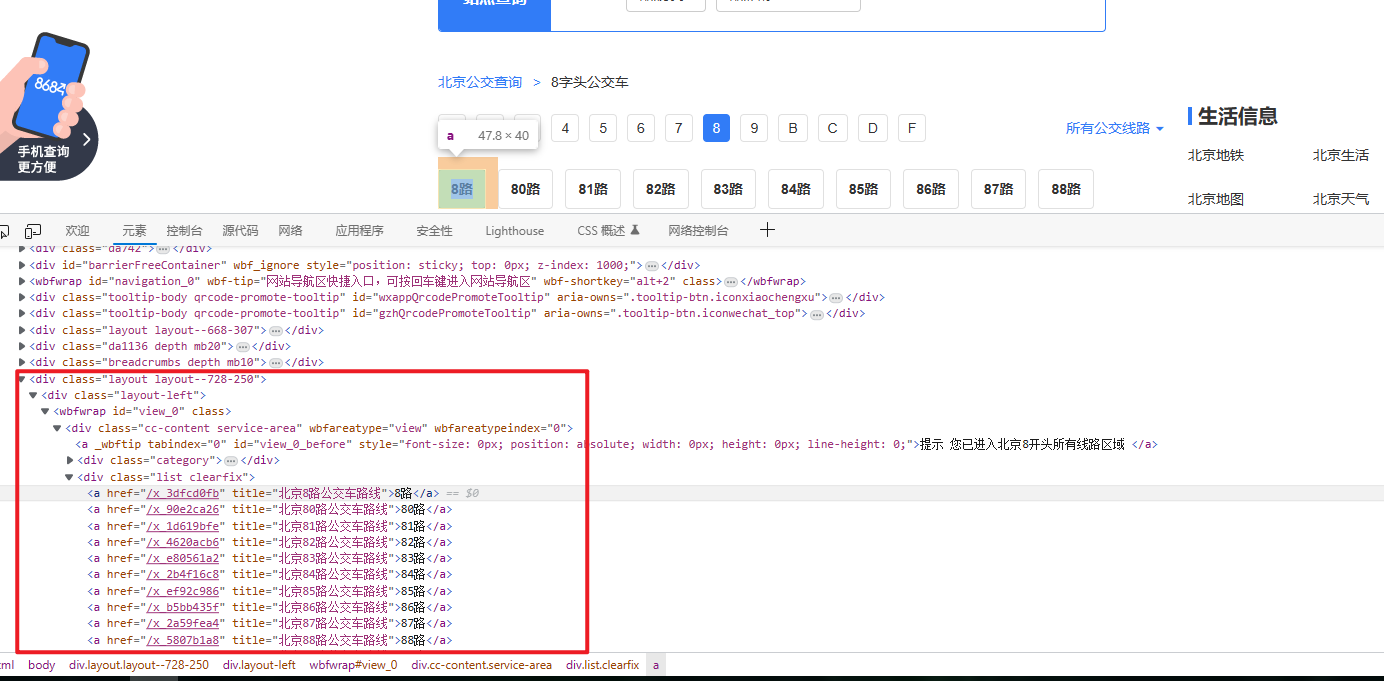
从上面我们不难发现,只需要找到class ='list clearfix'的div标签就可以找到对应的网址(如果感觉这样跳跃不保险也可以用select 类选择器逐步递进筛选)
def get_page_url(urls):
rep = urllib.request.Request(urls, headers=headers)
html = urllib.request.urlopen(rep)
btsoup = bs(html.read(), 'html.parser')
lu = btsoup.find('div', class_='list clearfix')
hrefs = lu.find_all('a')
for i in hrefs:
print(i)
print(i['href'])
urls = urljoin(url, i['href']) # 拼接网址
get_page_info(urls) # 下面会写这一个方法进入第二目标地址,拿到对应的数据:
一、通过第一个目标得知获取的对应公交信息网址进入并解析数据
二、这里我们解析好数据之后将其存储在一个结果列表中,以便后面保存数据
三、构造方法,实现删除两步
def get_page_info(urls):
rep = urllib.request.Request(url=urls, headers=headers)
html = urllib.request.urlopen(rep)
soup = bs(html.read(), 'html.parser')
bus_name = soup.select('div.info > h1.title > span')[0].string
bus_type = soup.select('div.info > h1.title > a.category')[0].string
time_select = soup.select('div.info > ul.bus-desc > li')
bus_time = time_select[0].string
bus_ticket = time_select[1].string
gongsi = time_select[2].find('a').string
gengxin = time_select[3].find('span').string
try:
licheng = soup.find('div', class_="change-info mb20").string
except:
licheng = None
# 往的信息 ---> 0
wang_info1 = bus_name
wang_info2 = soup.select('div > div > div.trip')[0].string
wang_total = soup.select('div > div > div.total')[0].string
wang_road_ol = soup.find_all('div', class_='bus-lzlist mb15')[0].find_all('ol')
wang_road = get_page_wangFan(wang_road_ol)
# 返的信息 ---> 1
try:
fan_info1 = bus_name
fan_info2 = soup.select('div > div > div.trip')[1].string
fan_total = soup.select('div > div > div.total')[1].string
fan_road_ol = soup.find_all('div', class_='bus-lzlist mb15')[1].find_all('ol')
fan_road = get_page_wangFan(fan_road_ol)
except IndexError:
fan_info1 = None
fan_info2 = None
fan_total = None
fan_road = None
result_lst = [bus_name, bus_type, bus_time, bus_ticket, gongsi, gengxin, licheng, wang_info1, wang_info2,
wang_total, wang_road, fan_info1, fan_info2, fan_total, fan_road]
cs = open('BeiJing_Bus_Info.txt', 'a', newline="", encoding='utf-8')
writer = csv.writer(cs)
# 这里可以进行空值处理(不想做,没做)
# 写入数据
writer.writerow(result_lst)
print("又下载完一个^_^")
time.sleep(5)
注:这里面获取往返数据单独写了一个方法,因为这里有隐藏数据,需要长个心眼
def get_page_wangFan(wangFan_road_ol):
wangFan_road_tmp = wangFan_road_ol[0].find_all('li')
wangFan_road_lst = []
for road in wangFan_road_tmp:
temp = road.find('a')
if temp is None:
continue
else:
wangFan_road_lst.append(temp)
# 删除最后一个值
wangFan_road_lst.pop()
try:
# 找隐藏的数据
wangFan_road_tmp = wangFan_road_ol[1].find_all('li')
except:
wangFan_road_tmp = None
if wangFan_road_tmp is not None:
for road in wangFan_road_tmp:
temp = road.find('a')
if temp is None:
continue
else:
wangFan_road_lst.append(temp)
# 格式化字段
wangFan_road = ""
for r in wangFan_road_lst:
wangFan_road += r.string + ', '
return wangFan_road源码
import csv
import time
import urllib.request
from bs4 import BeautifulSoup as bs
from urllib.parse import urljoin
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/110.0.0.0 Safari/537.36'
}
url = 'https://beijing.8684.cn/'
url_list = url + '/list%d'
def get_page_wangFan(wangFan_road_ol):
wangFan_road_tmp = wangFan_road_ol[0].find_all('li')
wangFan_road_lst = []
for road in wangFan_road_tmp:
temp = road.find('a')
if temp is None:
continue
else:
wangFan_road_lst.append(temp)
# 删除最后一个值
wangFan_road_lst.pop()
try:
# 找隐藏的数据
wangFan_road_tmp = wangFan_road_ol[1].find_all('li')
except:
wangFan_road_tmp = None
if wangFan_road_tmp is not None:
for road in wangFan_road_tmp:
temp = road.find('a')
if temp is None:
continue
else:
wangFan_road_lst.append(temp)
# 格式化字段
wangFan_road = ""
for r in wangFan_road_lst:
wangFan_road += r.string + ', '
return wangFan_road
def get_page_info(urls):
rep = urllib.request.Request(url=urls, headers=headers)
html = urllib.request.urlopen(rep)
soup = bs(html.read(), 'html.parser')
bus_name = soup.select('div.info > h1.title > span')[0].string
bus_type = soup.select('div.info > h1.title > a.category')[0].string
time_select = soup.select('div.info > ul.bus-desc > li')
bus_time = time_select[0].string
bus_ticket = time_select[1].string
gongsi = time_select[2].find('a').string
gengxin = time_select[3].find('span').string
try:
licheng = soup.find('div', class_="change-info mb20").string
except:
licheng = None
# 往的信息 ---> 0
wang_info1 = bus_name
wang_info2 = soup.select('div > div > div.trip')[0].string
wang_total = soup.select('div > div > div.total')[0].string
wang_road_ol = soup.find_all('div', class_='bus-lzlist mb15')[0].find_all('ol')
wang_road = get_page_wangFan(wang_road_ol)
# 返的信息 ---> 1
try:
fan_info1 = bus_name
fan_info2 = soup.select('div > div > div.trip')[1].string
fan_total = soup.select('div > div > div.total')[1].string
fan_road_ol = soup.find_all('div', class_='bus-lzlist mb15')[1].find_all('ol')
fan_road = get_page_wangFan(fan_road_ol)
except IndexError:
fan_info1 = None
fan_info2 = None
fan_total = None
fan_road = None
result_lst = [bus_name, bus_type, bus_time, bus_ticket, gongsi, gengxin, licheng, wang_info1, wang_info2,
wang_total, wang_road, fan_info1, fan_info2, fan_total, fan_road]
cs = open('BeiJing_Bus_Info.txt', 'a', newline="", encoding='utf-8')
writer = csv.writer(cs)
# 这里可以进行空值处理(不想做,没做)
# 写入数据
writer.writerow(result_lst)
print("又下载完一个^_^")
time.sleep(5)
def get_page_url(urls):
rep = urllib.request.Request(urls, headers=headers)
html = urllib.request.urlopen(rep)
btsoup = bs(html.read(), 'html.parser')
lu = btsoup.find('div', class_='list clearfix')
hrefs = lu.find_all('a')
for i in hrefs:
# 这里因为是Tag对象所以可以直接用i['href']访问对应的href属性
print(i)
####################################################
print(i['href'])
urls = urljoin(url, i['href'])
get_page_info(urls)
if __name__ == '__main__':
for k in range(1, 2):
urls = url_list % k
time.sleep(3)
get_page_url(urls)
print(f'完成{k}个......')

















 1309
1309

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









