






学习资料2025最新LangChain实战入门教程,从零到开始快速入门及底层原理,结合RAG构建一个完整的问答系统!赶快收藏吧!全网都没有这么全的教程!_哔哩哔哩_bilibili
记忆
帮助LLM记住你过去和他聊过的信息,在聊天机器人模型中应用广泛。
[Beta] Memory | 🦜️🔗 LangChain这里可以在官网查看更多信息,看看哪一种记忆类型适合需要
在langchain中,它提供了langchain.memory的一个库,可以直接调用ChatMessageHistory来使用这个模块,实现一个简单的memory应用
from langchain.memory import ChatMessageHistory
history = ChatMessageHistory() #初始化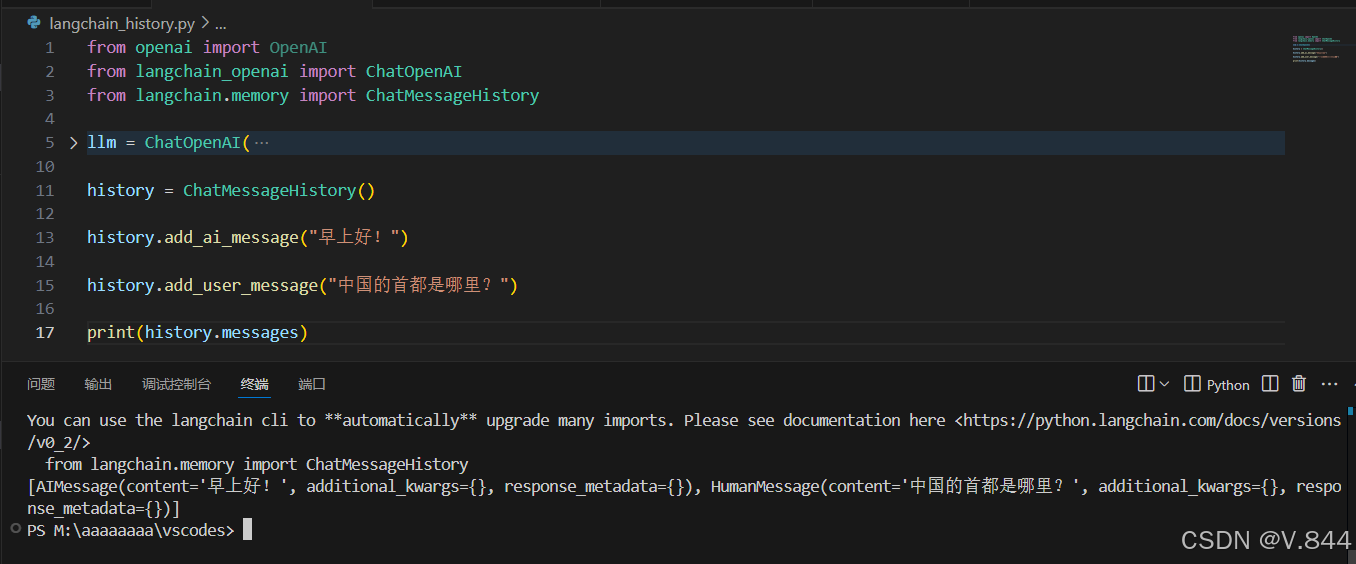
可以以这样的方式去叠加history message,信息像这样数组的形式去叠加。
有了ChatMessageHistory后,可以直接把它丢进大模型里面,让大模型直接给出答案,这样就不需要以其他方式去让他得出答案
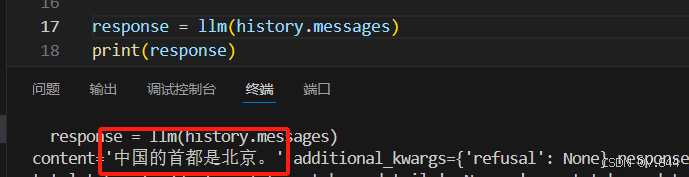
然后可以再通过
history.add_ai_message(response.content)来添加刚刚AI回答过的信息
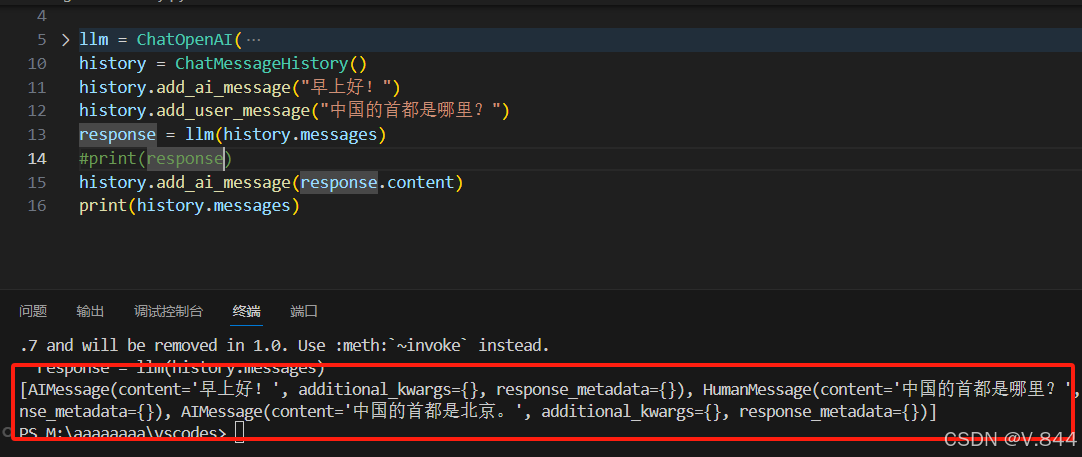
以此类推可以不断的新添加信息。以上这个只是最简单的一个memory类型,可以去官网查看到更多的类型,有这个会话缓存记忆
还有很多memory在其他方面的应用,后面要学习到
链
链(chain)是langchain的灵魂,也可以看出来chain在’langchain‘这个因为单词中组成部分,它可以自动组合不同的LLM的调用和操作,像在上次的学习中已经用到了chain中的RetrievalQA检索链
qa = RetrievalQA.from_chain_type(
llm=chat_model,
chain_type="stuff",
retriever=retriever
)
总结链中几个常用的总结方法

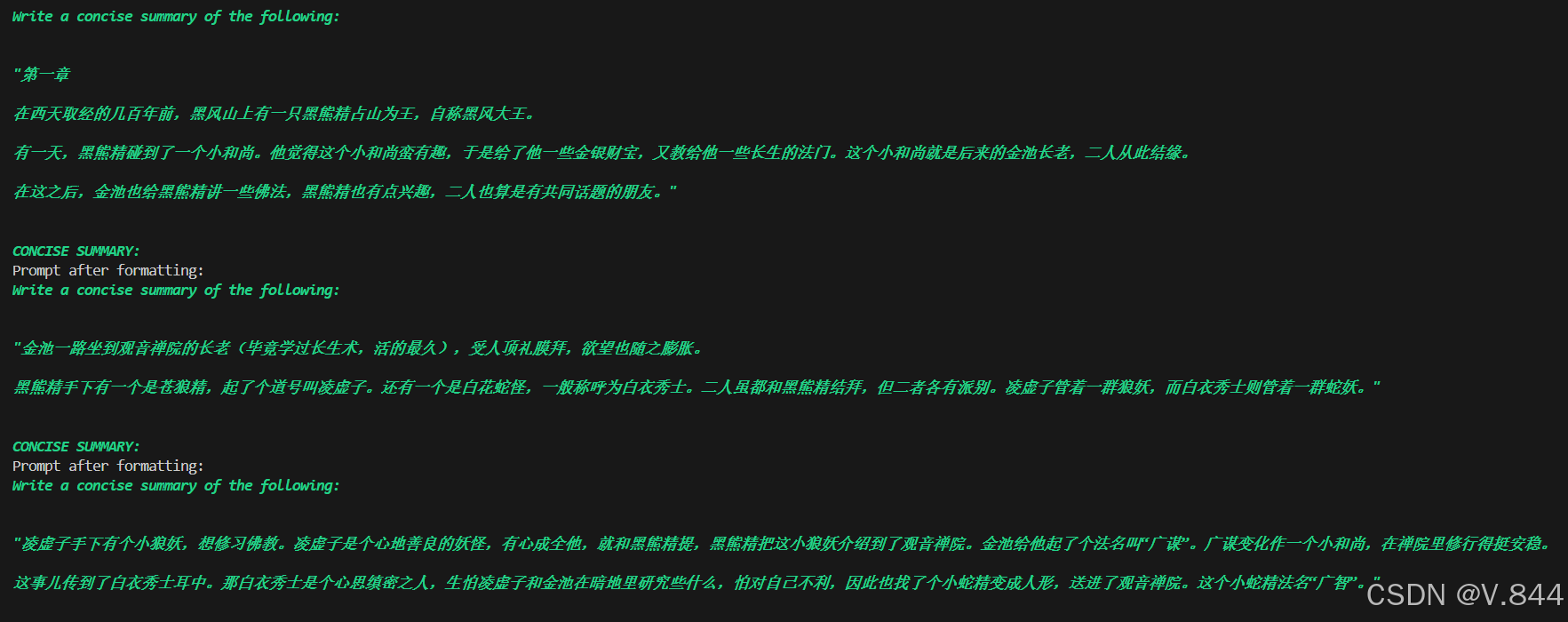
接下来对上次的学习中的heishenghuawukong.txt用map-reduce的方法进行总结
from langchain.chains.summarize import load_summarize_chain
from langchain.document_loaders import TextLoader
from langchain.text_splitter import RecursiveCharacterTextSplitter
from langchain_openai import ChatOpenAI
llm = ChatOpenAI(
openai_api_key='xxxxxxxxxxxxxxx',
base_url="https://api.siliconflow.cn/v1/",
model='Qwen/Qwen2-7B-Instruct'
)
#加载文档
loader = TextLoader(file_path="heishenghuawukong.txt", encoding='utf-8')
docs = loader.load()
#分割器
text_splitter = RecursiveCharacterTextSplitter(chunk_size=200, chunk_overlap=20)
#将文档拆分为文本
chunk = text_splitter.split_documents(docs)
chain = load_summarize_chain(llm,chain_type="map_reduce",verbose=True)
chain.run(chunk)
map-reduce总结方法的部分的展示:
每一段总结
然后给出一个最后的总结,这就是map-reduce的方法
一个简单的顺序链
直接演示代码
from langchain.chains import LLMChain #LLMChain类似于chain中的链结
from langchain.prompts import PromptTemplate
from langchain.chains import SimpleSequentialChain #简单顺序链
from langchain_openai import ChatOpenAI
llm = ChatOpenAI(
openai_api_key='xxxxxxxx',
base_url="https://api.siliconflow.cn/v1/",
model='Qwen/Qwen2-7B-Instruct'
)
#提示词模板
template = """你的工作是想出一个用户所在地区的一个经典的地标建筑。
%用户地区
{user_location}
你的回答:
"""
#初始化
prompt_template = PromptTemplate(input_variables=["user_location"],template=template)
#地区的chain
location_chain = LLMChain(llm=llm,prompt=prompt_template)
#第二个提示词模板
template = """介绍一个地标建筑,并简要的介绍他的历史故事。
%地标建筑
{user_building}
你的回答:
"""
#初始化
prompt_template = PromptTemplate(input_variables=["user_building"],template=template)
#建筑的chain
building_chain = LLMChain(llm=llm,prompt=prompt_template)
#将两个链结在一起
sum_chain = SimpleSequentialChain(chains=[location_chain,building_chain],verbose=True)#后续还可以增加更多的chain
review = sum_chain("上海")
输出:

可以看出SimpleSequentialChain的输出方式是 Entering new SimpleSequentialChain chain...
先是说“上海的地标性建筑是东方明珠电视塔”,然后不需要用户继续操作将“东方明珠电视塔”丢给llm,自动以链条的概念去把上一个链条的输入转化为下一链条的输出,这样非常的方便。
最后完成
![]()


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









