







【Java网络编程03】网络原理进阶(一)
1. UDP协议
1.1 基本介绍
我们首先再来回顾UDP协议的基本特点:
- 无连接的
- 不可靠传输的
- 面向数据报的
- 全双工的
既然谈到数据报,我们就来看一下UDP数据报的格式:
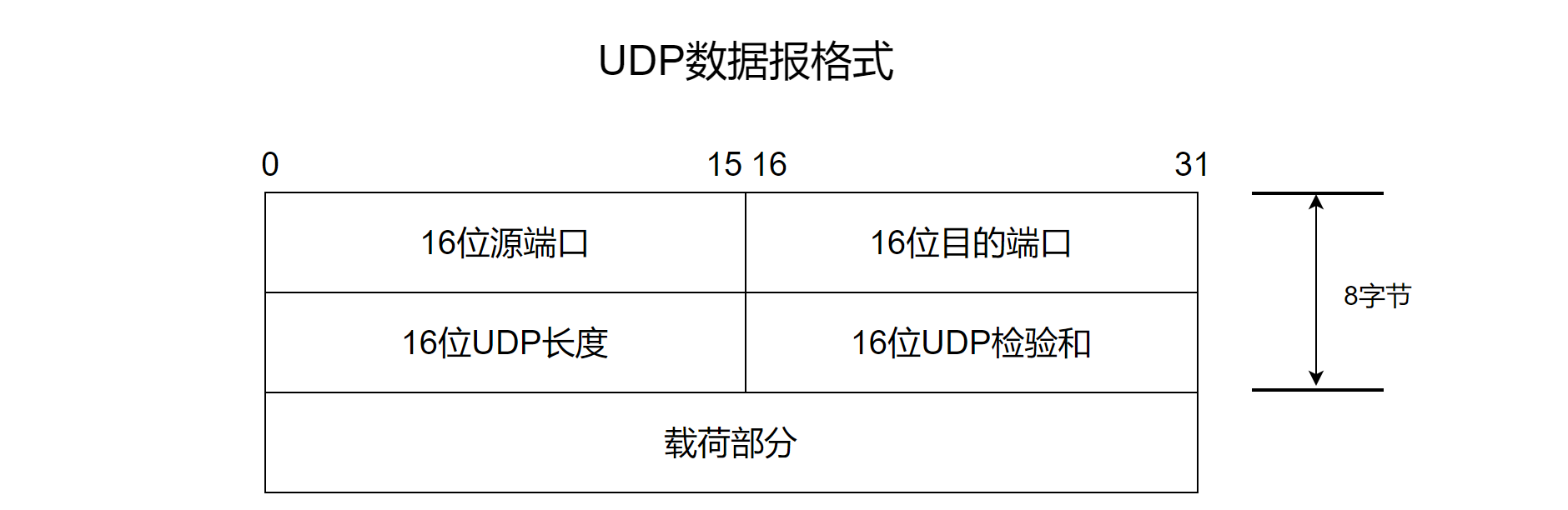
UDP数据报分为报头和载荷部分,其中载荷部分就是应用层报文,报头固定8字节,分为以下四个部分:
- 源端口:标识发送方位于源主机的哪个应用程序
- 目的端口:标识接收方位于目的主机的哪个应用程序
- 数据报长度:报头+载荷部分的总长度,最大为64KB
- 检验和(checksum):用于检验传送过程中是否出现差错
1.2 相关机制
1.2.1 UDP检验和
校验和(checksum):由于网络传输过程中,数据以光/电/电磁波信号进行传输,因此难免遇到外界环境干扰导致数据出现差错,造成比特0-1翻转。因此引入检验和(checksum)可以在一定程度上进行差错检验,
UDP校验和:UDP所采取的检验和的方式就是将报文中的所有16比特的和进行反码运算,期间遇到的任何溢出都要回卷,计算方式这里省略。。。
校验过程:首先在发送方会进行一次检验和算法过程然后将结果value1存放到UDP数据报的检验和字段,接收方会使用相同的算法处理接收到的数据再次得到一个结果记做value2,此时比对value1与value2是否一致,如果不一致那就证明一定出现了比特翻转,直接丢弃该数据包即可,但是检验和存在一个缺点就是如果有多于一位比特的比特差错,此时有可能得到的校验和结果是一致的!因此不一定能证明数据100%正确。
补充知识:业界还有更高精度的校验和算法例如md5和sha1算法,这里简单介绍md5的特点
- 定长:无论原始数据如何,生成的md5值一定是固定长度的,常见的有16位、32位、64位版本
- 分散:只要原始数据变化一丁点,生成的md5值就会大相径庭,这样的特性也决定了它可以被用作字符串hash算法。
- 不可逆:对于A(原始数据)=>B(md5值)的过程是不可逆的,原理上无法做到根据md5值反推原始数据,这个特性也决定它可以用作加密算法。很多网站所谓md5解密本质是采取暴力"打表"的方式计算各种原始值的md4值并存放到数据库的过程。
2. TCP协议
2.1 报文格式
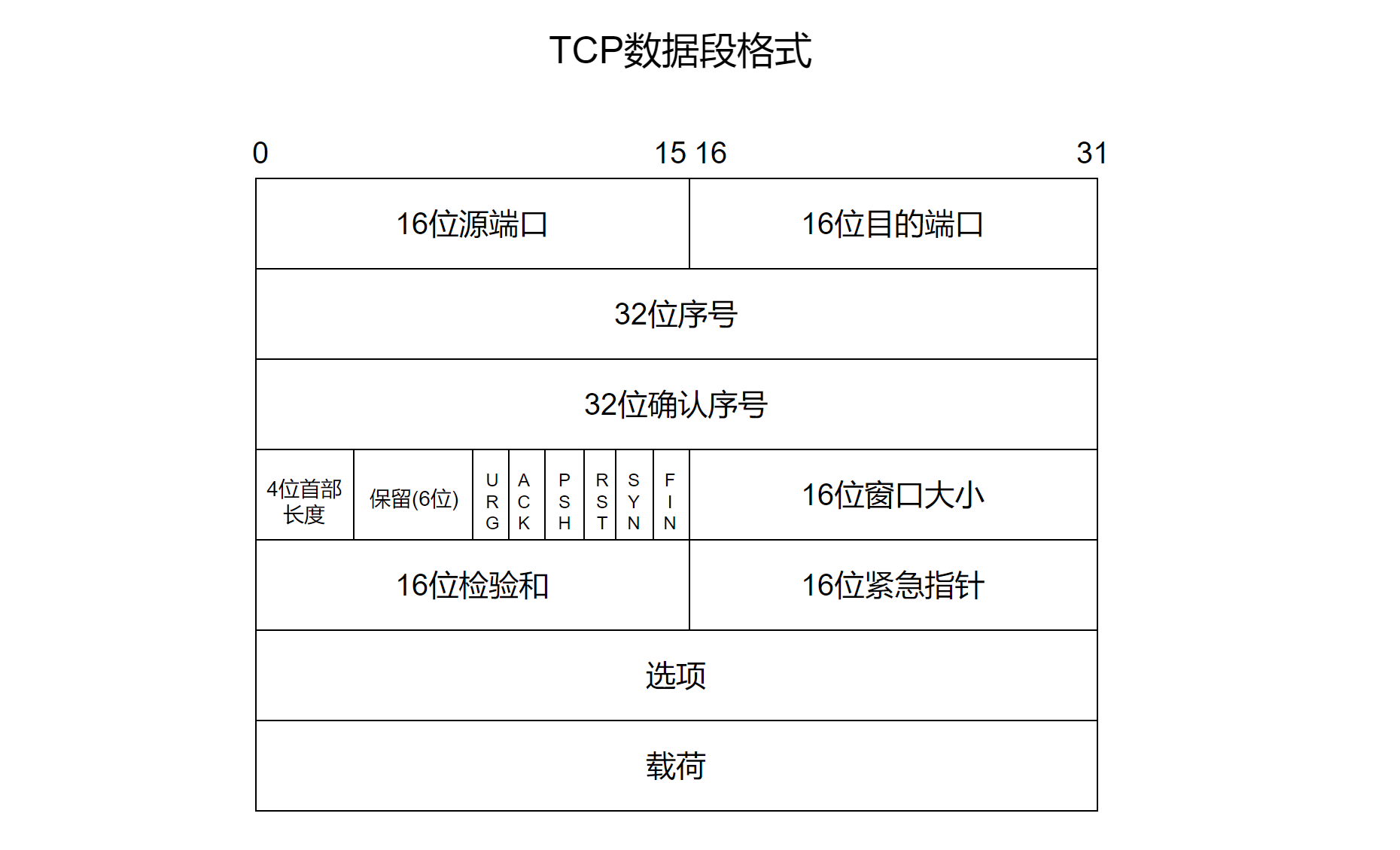
TCP协议段的格式如下:
2.2 可靠传输机制
再来回顾TCP协议的特点:
- 有连接
- 可靠传输的
- 面向字节流的
- 全双工
其中有连接、面向字节流、全双工这几个特性我们都在TCP套接字编程中可以体会到,但是体现不出可靠传输机制,因此我们就来探究TCP实现可靠传输的网络原理
可靠传输:再来强调一下可靠传输的含义,并不是说使用TCP协议那么发送方发送的数据包能够百分百到达接收方,此处的可靠性只是"退而求其次",利用相关机制可以让发送方知道发送的数据包是否成功到达接收方,就认为是"可靠传输"了
2.2.1 确认应答机制(核心)
在保证TCP协议的可靠传输机制中,最为核心的就是 确认-应答机制了
- Step1:接收方需要根据接收到的数据包发回响应
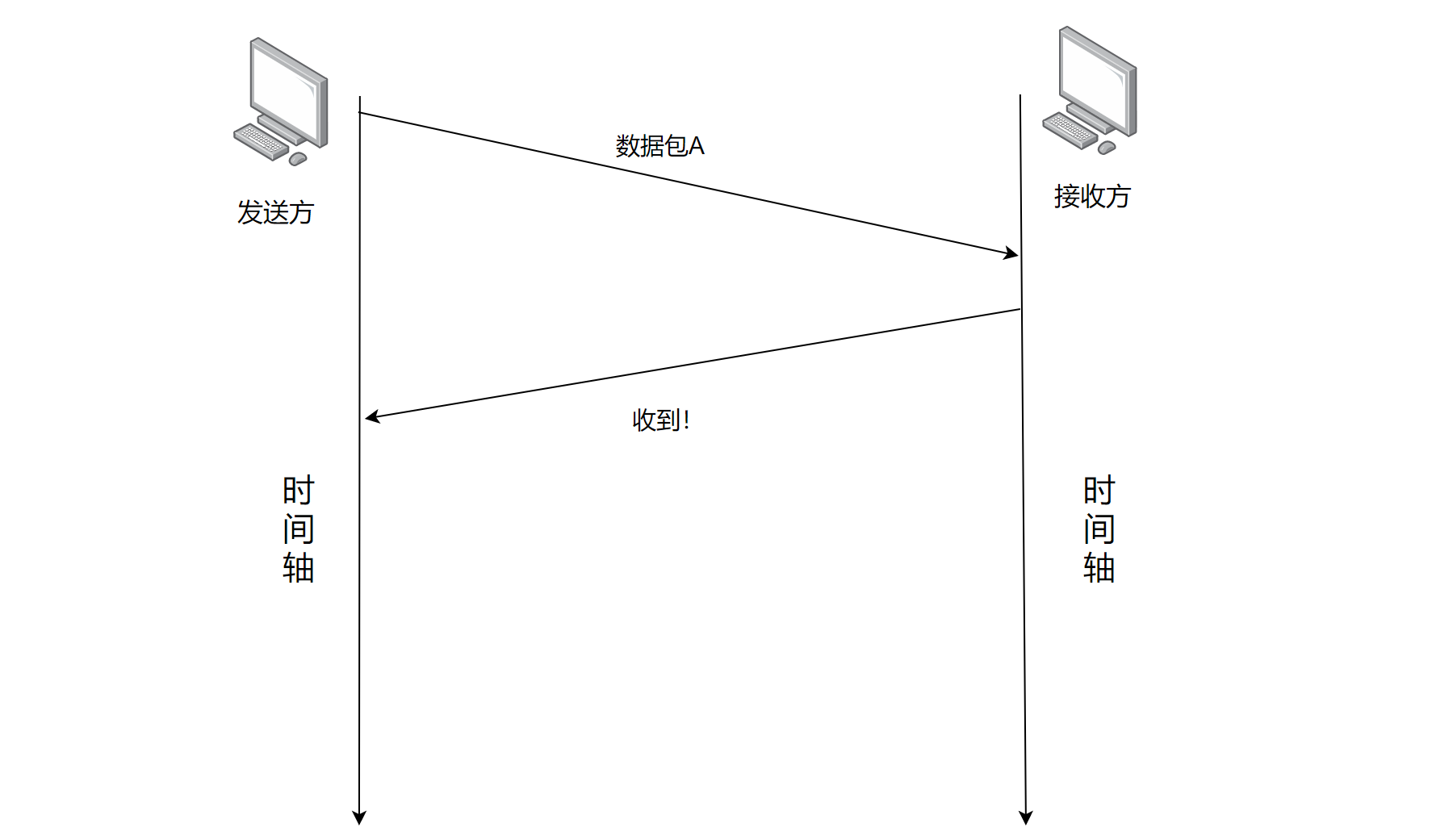
此时我们引入应答报文就可以让发送方知道发送报文是否到达接收方了,但是往往发送方发送的不止一个TCP段,接下来让我们发送多个报文段看看
- Step2:发送方发送多个TCP报文段
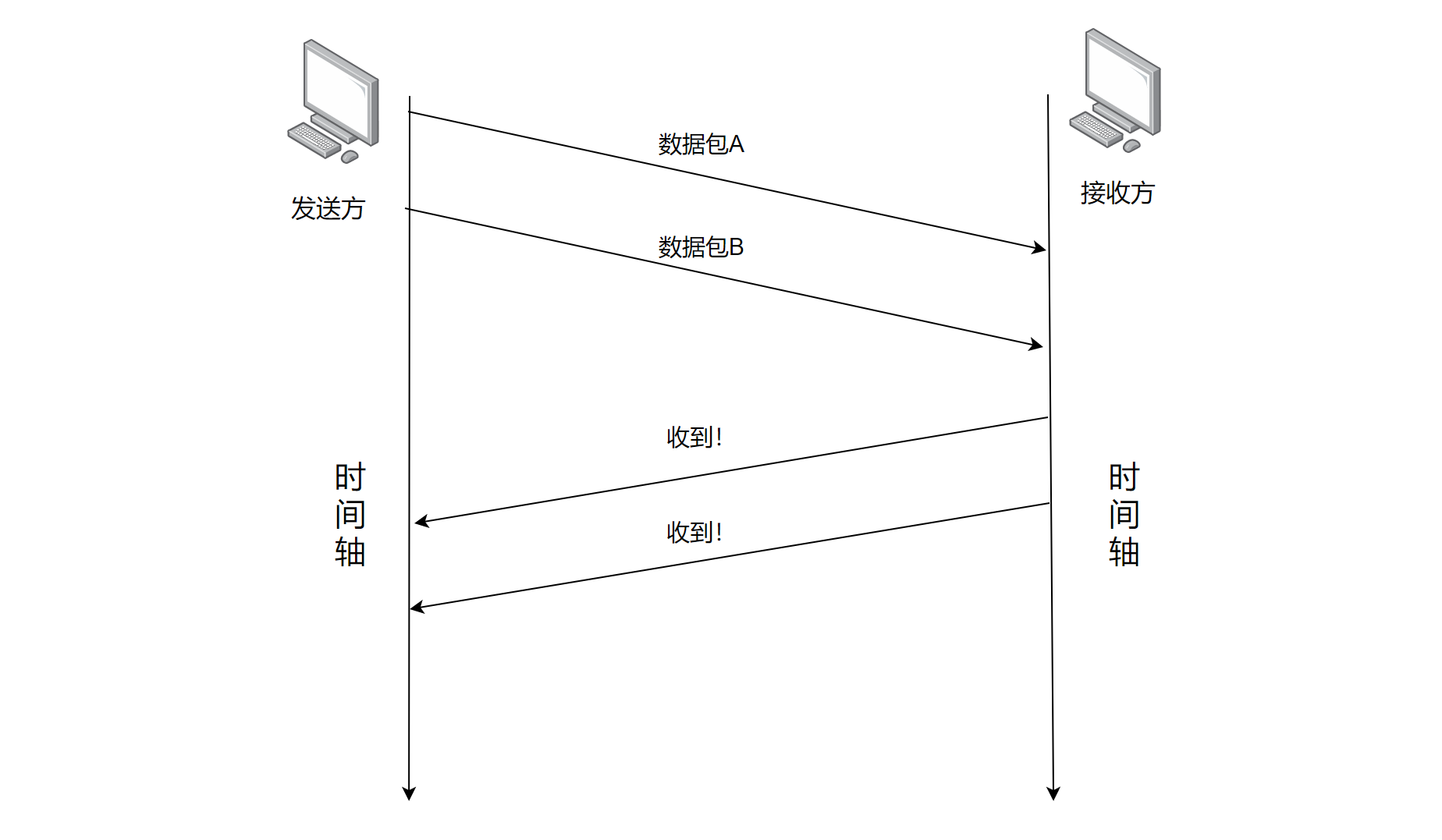
好像似乎也没什么问题呀,事实上如果数据包都是按序到达的,是没有什么问题的,但是现实中的网络情况十分错综复杂,因此很有可能导致"后发先至"的情况。因此事实上很有可能出现的是下面的时序情况
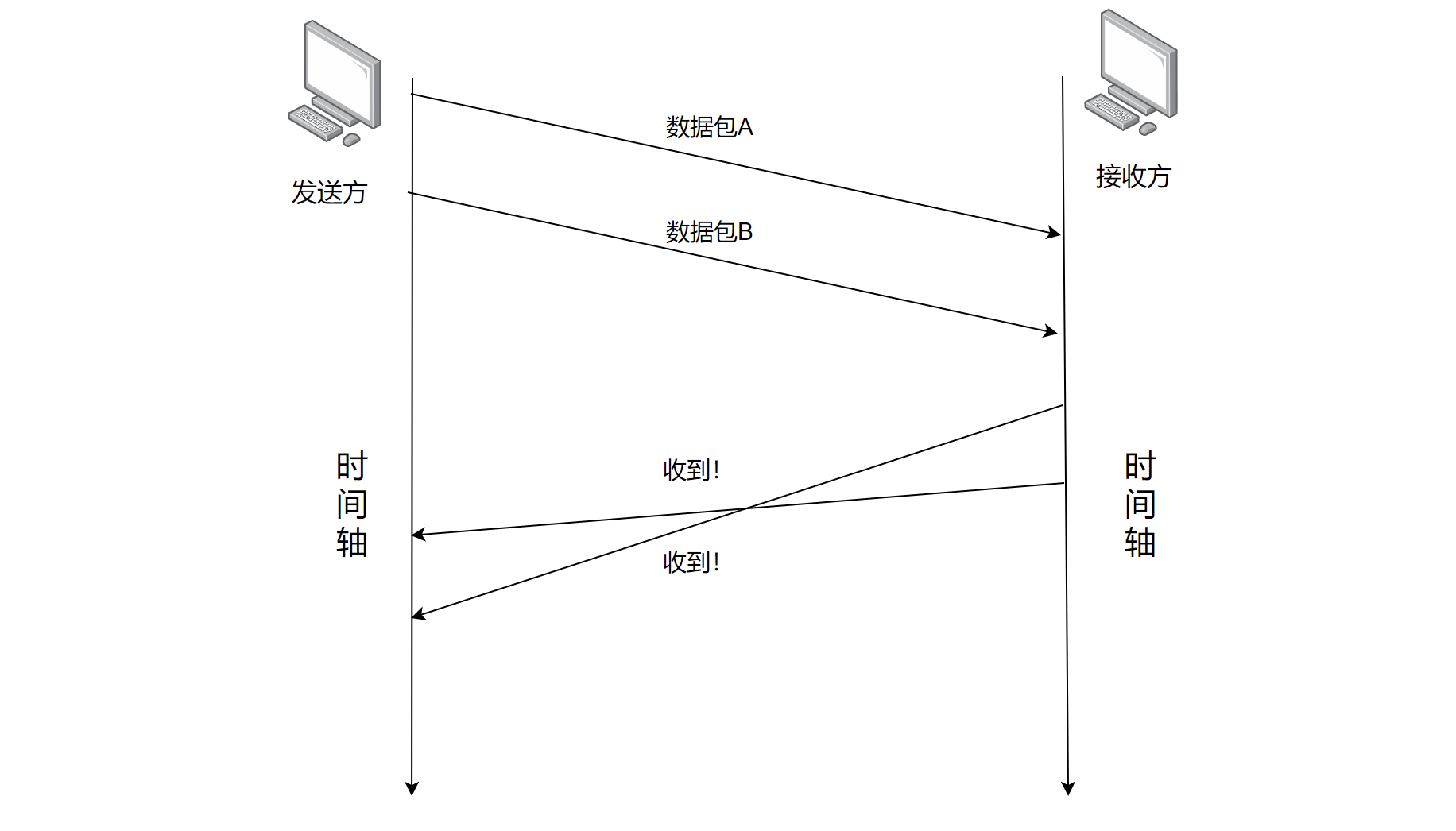
此时难以区分第一个"收到!"和第二个"收到!"到底针对的是哪个数据包所回复的了。因此TCP又引入了 序号与确认号 的机制来匹配响应报文和发送报文之间的对应关系
- Step3:引入序号与确认序号机制
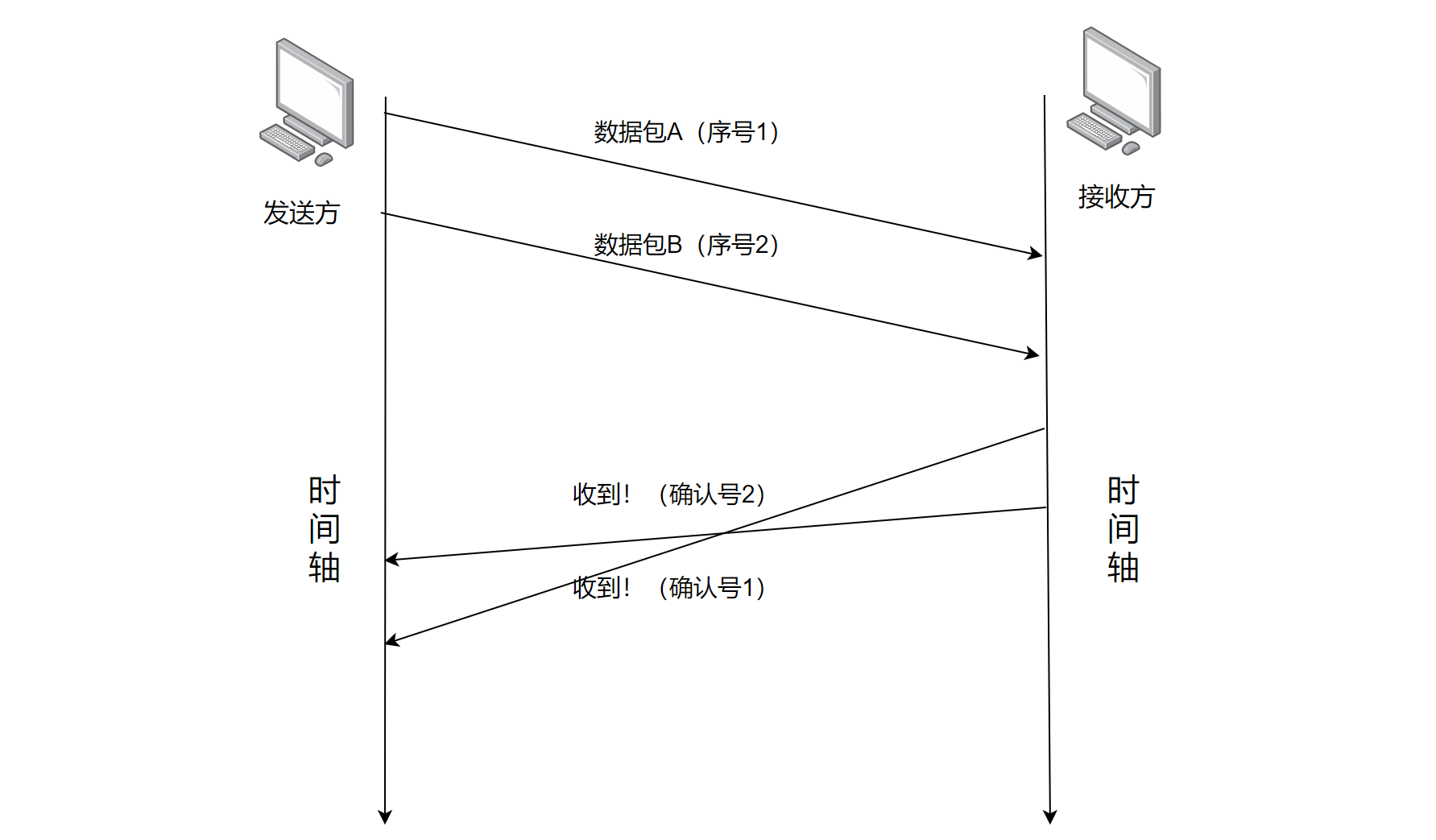
此时就算是出现"后发先至"的情况,发送方也能够清楚的知晓响应报文是匹配哪个发送报文的了
注意:
以上实际上是简化版本的模型,真实的TCP的情况要更加复杂一些,实际上TCP是面向字节流的,而不是以上所展示的对一个一个数据包进行编号,事实上TCP针对每一个字节进行编号
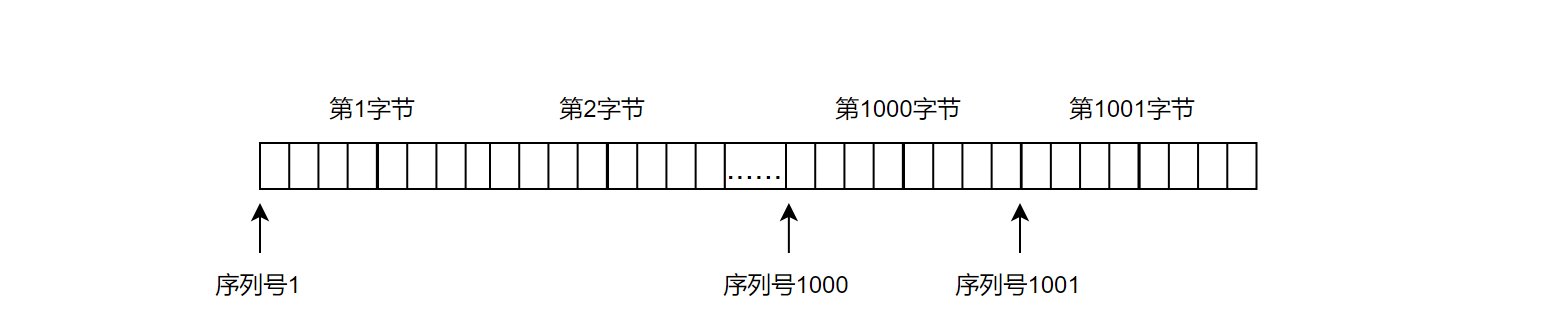
- 假设发送报文中载荷部分中一共有1000个字节,编号为1001-2000,由于序号是连续的,因此只需要在TCP报头序号填上第一个字节的编号1001即可,也可以通过计算得出最后一个字节的编号。
- 应答报文中的确认序号值,是按照接收到的最后一个字节的序号+1进行设定的,因此如果应答报文中的确认序号为1001,具有两种含义:1、1001号以前的数据都已经接收完毕,2、发送方接下来可以发送1001开始往后的数据了。
2.2.2 超时重传机制
超时重传机制:这是对于确认应答机制的补充。如果一切顺利的情况下,通过应答报文(ACK报文)就可以让发送方知晓当前数据是否成功被接收方接收。但是网络实际情况是错综复杂的,很有可能出现"丢包"现象,如果数据包没有发送到接收到,也就不存在什么应答报文了,这个情况下就需要"超时重传机制"了。本质上是设置一个等待时间阈值,如果超过等待时间仍未收到应答报文,就会触发重传数据包行为。
丢包现象:由于网络中主机A与主机B并不是直连的,中间会经过多个路由器、交换机等网络设备转发,如果一个交换机/路由器在某个时刻负载量激增,短时间内有多个数据包需要经过该设备进行转发,超过了这个设备所能承受的最大转发量,此时该网络设备就会有选择性的丢弃一部分数据包维持网络传输速率。
超时重传两种场景:
超时重传可能出现以下两种情况:
- 情况一:发送数据包丢包
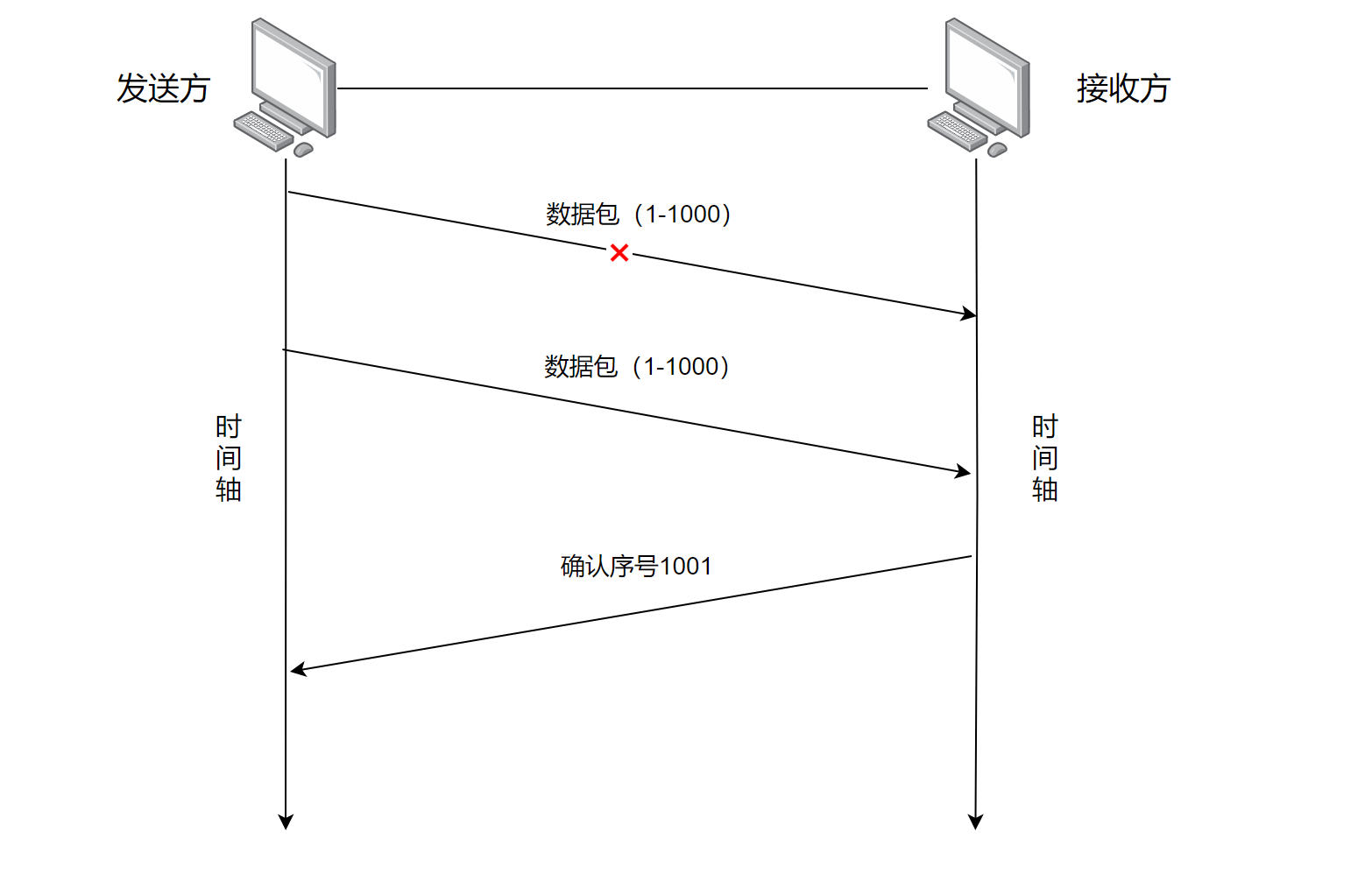
这种情况接收方本身就没有接收到数据,因此进行超时重传理所应当,是没有任何问题的
- 情况二:应答报文丢包
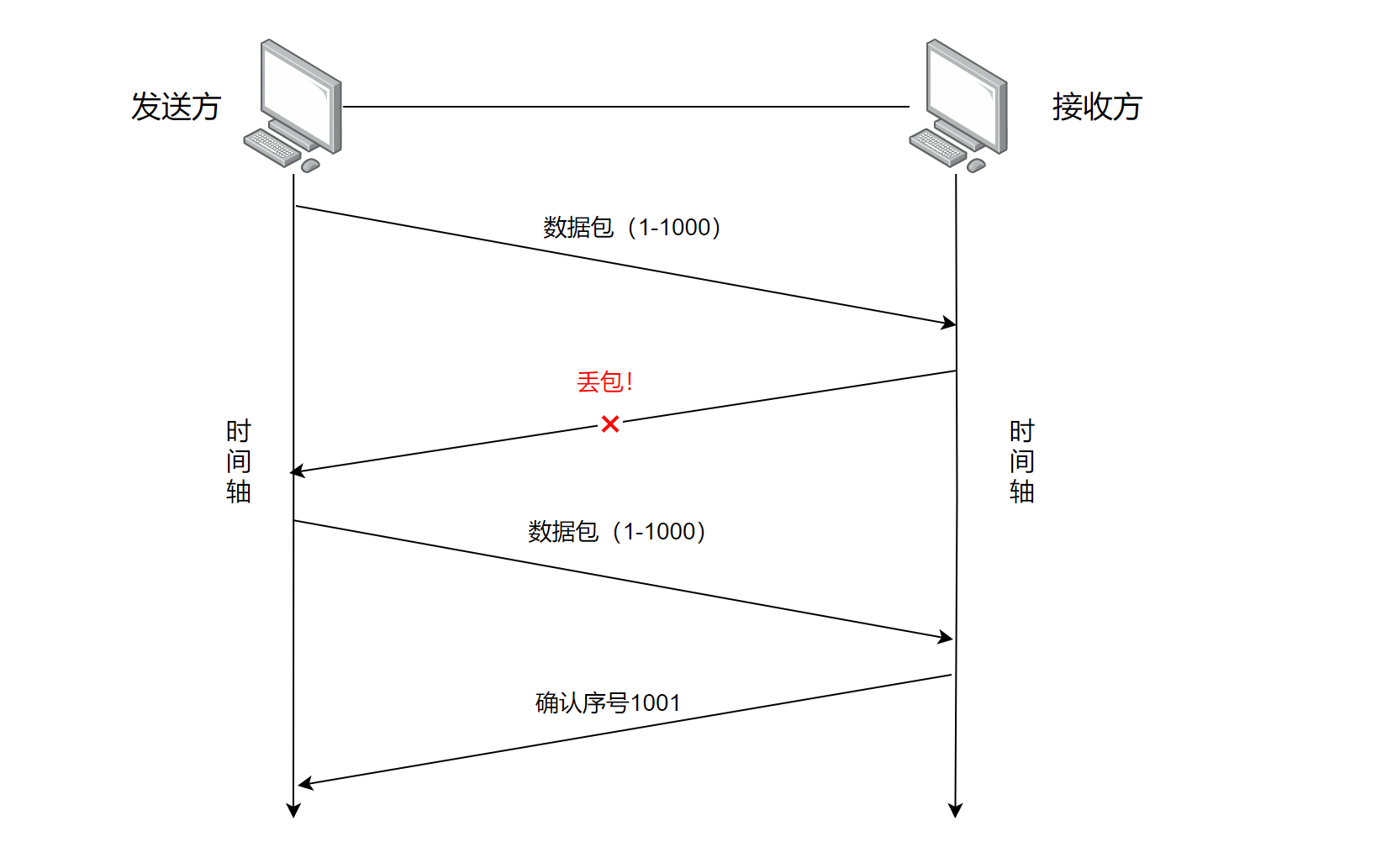
这种情况属于接收方已经接收到数据,但是由于应答报文丢包了!导致发送方超时重传,这种情况仔细想想其实是有问题的,如果是转账业务呢?那么接收方接收两次不就需要扣款两次吗?事实上设计TCP的大佬们已经帮我们处理好了,就是通过TCP的 接收缓冲区 解决的
TCP接收缓冲区:
TCP的socket在内核中存在接收缓冲区(一段内存空间),发送方发来的数据需要先保存在接收缓冲区当中,然后应用程序调用read方法读取缓冲区的数据,这里的读操作实际上针对的是缓冲区中的数据。其中接收缓冲区最重要的核心功能就是会进行**“去重”**操作,那么如何判断重复数据呢?核心判断依据就是数据的序号。
- 当数据还在接收缓冲区时,还没有被应用程序read读走,那么就会拿着新到达的数据序号与接收缓冲区中的数据序号依次进行比对,如果有一样的那就是有重复了,直接丢弃。
- 如果数据已经被应用程序从缓冲区读走了,但是应用程序读取缓冲区的数据是按照序号的先后顺序读取(即先读取序号小的,再读取序号大的)的,因此如果新到达的数据序号为3000,并且此时应用程序读取到的最后的数据序号为4000,就可以证明4000以前的数据都被读走了,因此可以判断出3000序号数据重复,直接丢弃。
总结而言就是TCP的接收缓冲区实现了"去重"数据包的功能,并且该去重机制还额外完成了排序数据包的工作。
超时重传策略:
超时确实会导致发送方重传数据包,但是重传不是无限制次数的重传,重传也是有一定策略的
- 重传次数是有上限的,重传到一定程度,还没有收到ACK应答报文,此时就会重置连接,如果重置也失败,就直接放弃连接
- 重传的超时时间间隔并不是固定不变的,随着重传次数的增多,超时时间阈值也会增大(重传频率变得更低)














 1万+
1万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









