






 本文探讨了LRU算法在计算机内存管理中的应用,如MySQL的BufferPool和Redis的内存淘汰策略。重点讲解了如何解决MySQL中的预读失效和BufferPool污染问题,以及Redis对传统LRU的优化,包括近似LRU实现和LFU淘汰策略的引入。最后介绍了LRU缓存实战,以LeetCode题目为例,展示了LinkedHashMap在LRU缓存中的关键作用。
本文探讨了LRU算法在计算机内存管理中的应用,如MySQL的BufferPool和Redis的内存淘汰策略。重点讲解了如何解决MySQL中的预读失效和BufferPool污染问题,以及Redis对传统LRU的优化,包括近似LRU实现和LFU淘汰策略的引入。最后介绍了LRU缓存实战,以LeetCode题目为例,展示了LinkedHashMap在LRU缓存中的关键作用。
计算机中的LRU算法
LRU(Least Recently Used,最近最少使用算法)
- 传统的LRU算法
- 用链表管理数据;当访问的数据在链表中,把链表中的数据移动到表头/尾;当访问的数据不在链表中,从磁盘中读取数据,把数据放到链表头/尾,同时还要淘汰LRU链表末尾的节点。
- 后面会给出Java实现的方法,使用LinkedHashMap可以很好地实现我们的需求;
- MySQL中的LRU:InnoDB存储引擎中的Buffer Pool,使用LRU算法管理缓存页。
- buffer pool是InnoDB设计的一个缓冲池,以页为单位缓存磁盘数据。从而提高读写效率。
- Redis中的LRU:Redis中的内存淘汰策略中,有LRU算法,将最近最少使用的key淘汰出内存。
- 需要注意的是,Redis实现的是近似LRU算法,并不是我们想的链表方式;
- 操作系统中的LRU:页面置换算法中可以使用LRU页面置换算法,将最近最少使用的页面置换出内存。
- 当我们试图在通过虚拟内存地址访问一个页表时,该页表不在内存中,就会发生缺页异常,需要将页从磁盘换入到内存中,但是如果内存满,需要将内存中的页面置换出来,此时就需要页面置换算法。
MySQL对LRU的修改
如果使用传统的LRU算法,MySQL中可能出现预读失效和Buffer Pool污染的问题。
- 预读失效:MySQL 在加载数据页时,会提前把它相邻的数据页一并加载进来,目的是为了减少磁盘 IO。但是可能这些被提前加载进来的数据页,并没有被访问,相当于这个预读是白做了,这个就是预读失效。
- 解决预读失效(提前淘汰预读页),可以将LRU划分为young区域和old区域。用户直接读取的页面,直接移动到young区域的头部;预读到的页放到old区域的头部中,当真正被访问到时,才放入young区域的头部。这样才不会让我们的预读白做,即使预读页没被访问,也会很快被删除。·
- Buffer Pool污染:当某一个 SQL 语句扫描了大量的数据时,在 Buffer Pool 空间比较有限的情况下,可能会将 Buffer Pool 里的所有页都替换出去,导致大量热数据被淘汰了,等这些热数据又被再次访问的时候,由于缓存未命中,就会产生大量的磁盘 IO,MySQL 性能就会急剧下降,这个过程被称为 Buffer Pool 污染。
- 解决Buffer Pool污染。
- 设置LRU链表的插入点,也就是设置old区域所占的百分比。新扫描到的数据插入到old区域,防止替换掉young区域的热数据。innodb_old_blocks_pct参数控制该百分比,默认值为 37,即young / old = 63/37。
- 并且提高进入到 young 区域的门槛,增加一个old区域停留的时间判断,只有满足被访问 + 大于该停留时间,才会将数据页放在young区域头部。这个间隔时间是由 innodb_old_blocks_time 控制的,默认是 1000 ms。
- 解决Buffer Pool污染。
- 另外,MySQL 针对 young 区域其实做了一个优化,为了防止 young 区域节点频繁移动到头部。young 区域前面 1/4 被访问不会移动到链表头部,只有后面的 3/4被访问了才会。
Redis对LRU的修改
如果使用传统的LRU算法,Redis不想维护一个较大的链表,占用内存空间。
Redis实现的是近似LRU算法,它的实现方式是在 Redis 的对象结构体中添加一个额外的字段,用于记录此数据的最后一次访问时间。
当 Redis 进行内存淘汰时,会使用随机采样的方式来淘汰数据,它是随机取 5 个值(此值可配置),然后淘汰最久没有使用的那个。
Redis的LRU算法存在缓存污染的问题,比如应用一次读取了大量的数据,而这些数据只会被读取这一次,那么这些数据会留存在 Redis 缓存中很长一段时间,造成缓存污染。
所以Redis4.0之后新增了lfu淘汰策略。
LRU缓存实战
LeetCode : 146.LRU 缓存
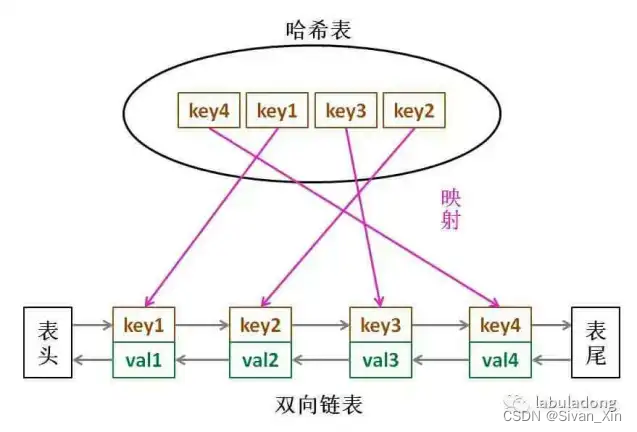
LRU缓存算法的核心数据结构:LinkedHashMap。
LinkedHashMap本质还是一个HashMap,但是维护了一个双向链表。不同于HashMap,LinkedHashMap可以维护map的插入顺序,得到插入的第一个元素:
// 删除第一个元素
LinkedHashMap map = new LinkedHashMap();
int key = map.keySet().iterator().next();
// 获取某个元素
LinkedHashMap map = new LinkedHashMap();
int value = map.get(key);
注意,在这个LRU链表中,最常访问的元素我们放在了链表末尾,当元素满时,每次移除链表头的元素。
class LRUCache {
LinkedHashMap<Integer,Integer> cache = new LinkedHashMap<>();
int capacity;
public LRUCache(int capacity) {
this.capacity = capacity;
}
public int get(int key) {
// 如果缓存中本来没有该元素
if(!cache.containsKey(key)){
return -1;
}
// 返回的答案
int val = cache.get(key);
// 因为访问了该元素,移出缓存
cache.remove(key);
//放进缓存,此时就在链表末尾,代表最近最多使用
cache.put(key,val);
return val;
}
public void put(int key, int value) {
if(cache.containsKey(key)){
cache.remove(key);
}
cache.put(key,value);
if(cache.size() > capacity){
// 移出队头元素 使用 cache.keySet().iterator().next();
int delKey = cache.keySet().iterator().next();
cache.remove(delKey);
}
}
}
重点
文章原创不易,点个赞支持下~
















 764
764











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











