







文章目录
MySQL部分
一条 SQL 语句在 MySQL 中如何执行的❓
🙋♂答:
-
连接器:与客户端进行TCP三次握手,建立连接。并且进行用户密码校验、权限校验。
连接器的工作完成后,客户端就可以向 MySQL 服务发送 SQL 语句了,MySQL 服务收到 SQL 语句后,就会解析出 SQL 语句的第一个字段,看看是什么类型的语句。如果是SELECT语句,会先查询缓存。(一般的查询缓存的命中率很低,在MySQL8.0版本中删掉了) -
解析器:进行词法分析、语法分析。构建语法树,并且判断SQL语句是否符合SQL标准。
之后就进入执行SQL的流程了。主要有三个阶段。 -
预处理器:检查 SQL 查询语句中的表或者字段是否存在;将
select *中的*符号,扩展为表上的所有列;(SELECT * 意为查询所有列) -
优化器:负责将 SQL 查询语句的执行方案确定下来,选择查询成本最小的执行计划,比如在表里面有多个索引的时候,优化器会基于查询成本的考虑,来决定选择使用哪个索引。
-
执行器:根据执行计划执行 SQL 查询语句,从存储引擎读取记录,返回给客户端;在执行的过程中,执行器就会和存储引擎交互了,交互是以记录为单位的。
explain命令了解吗❓
🙋♂答:
EXPLAIN 命令可以对 SELECT 语句进行分析, 并输出 SELECT 执行的详细信息, 以供开发人员针对性优化。
比如如果想要知道优化器选择了哪个索引,我们可以在查询语句最前面加个 explain 命令,这样就会输出这条 SQL 语句的执行计划。
我们一般关注如下几个字段:
-
type字段:表的访问方法,即如何查找表中的行。
ALL:走全表扫描,这种情况就需要使用索引来优化了。
ref:使用普通索引作为查询条件,查询结果可能找到多个符合条件的行。
const:表中最多只有一行匹配的记录,一次查询就可以找到,常用于使用主键或唯一索引的所有字段作为查询条件。 -
key字段:表示实际采用了哪个索引。
-
extra字段:表示一些附加信息。
using index :用到了覆盖索引,并且不需要回表。
using where:表示使用了where子句进行了条件过滤。
using index condition:表示索引下推优化**(index condition pushdown,ICP), 是针对联合索引的一种优化。可以在联合索引遍历过程中,对联合索引中包含的字段先做判断**,直接过滤掉不满足条件的记录,从而减少回表次数。
大表优化的思路、SQL调优的思路❓
🙋♂答:
MySQL调优可以从几个方面来考虑。
- 数据库、表方面进行优化
- 索引并不是越多越好,要根据查询有针对性的创建,考虑在
WHERE和ORDER BY命令上涉及的列建立索引,可根据EXPLAIN来查看是否用了索引还是全表扫描。 VARCHAR的长度只分配真正需要的空间。- 单表不要有太多字段,建议在20以内。
- 对数据库、表进行分库分表。
- 索引并不是越多越好,要根据查询有针对性的创建,考虑在
- 对SQL进行优化【效果最好】
- 正确使用索引,避免索引失效的情况,避免全表扫描。
- 应尽量避免在
WHERE子句中对字段进行NULL值判断,否则将导致引擎放弃使用索引而进行全表扫描 - 减少无效数据的查询
- 避免使用
select *,主要有以下原因:- 不需要的列会增加数据传输时间和网络开销
- 失去MySQL优化器“覆盖索引”策略优化的可能性
- 列表数据不要拿全表,要使用
LIMIT来分页,每页数量也不要太大。
- 避免使用
分库分表了解么、为什么要分库分表❓
🙋♂答:
单库太大:数据库里面的表太多,所在服务器磁盘空间装不下。I/O次数多。
单表太大:一张表的字段太多,数据太多。SQL查询慢。
所以需要分库分表。不管是分库还是分表,都有两种切分方式:水平切分和垂直切分。
垂直切分:
-
分表:表中的字段多,一般将不常用的、 数据较大、长度较长的拆分到“扩展表“。一般情况加表的字段可能有几百列,此时是按照字段进行数竖直切。注意垂直分是列多的情况。
-
分库:一个数据库的表太多。此时就会按照一定业务逻辑进行垂直切,比如用户相关的表放在一个数据库里,订单相关的表放在一个数据库里。注意此时不同的数据库应该存放在不同的服务器上,此时磁盘空间、内存、TPS等等都会得到解决。
水平切分:
-
分表:单表的数据量太大。按照某种规则(RANGE,HASH取模等),将单张表的数据切分到多张表里面去。 但是这些表还是在同一个库中,所以库级别的数据库操作还是有IO瓶颈。(表的数据量少了,单次执行SQL语句的执行效率就会变高。)
-
分库:水平分库理论上切分起来是比较麻烦的,它是指将单张表的数据切分到多个服务器上去,每个服务器具有相应的库与表,只是表中数据集合不同。 库多了,I/O性能自然就会提升。
Redis
说一下 Redis 和 Memcached 的区别和共同点❓
🙋♂答:
相同点
- 都是基于内存的数据库,一般都用来当做缓存使用。
- 都有过期淘汰策略。
- 两者的性能都非常高。
区别
- Redis的数据结构更加丰富,Memcached只支持key-value数据类型;
- Redis 支持数据的持久化,可以将内存中的数据保持在磁盘中,重启的时候可以再次加载进行使用,而 Memcached 没有持久化功能,数据全部存在内存之中,Memcached 重启或者挂掉后,数据就没了;
- Redis 支持发布订阅模型、Lua 脚本、事务等功能,而 Memcached 不支持;
- Redis 可以通过 MULTI,EXEC,DISCARD 和 WATCH 等命令来实现事务功能,Memcached不支持事务。
- Redis 原生支持集群模式,Memcached 没有原生的集群模式,需要依靠客户端来实现往集群中分片写入数据;
总之,Memcached是解决简单缓存问题的可靠选择。然而,一般来说,「Redis通过提供更丰富的功能和各种各样的特性而优于Memcached,这些特性对于解决复杂的场景更有优势」。
有缓存情况下查询数据和修改数据的流程(数据库和缓存时如何保证一致性的?常见的缓存更新策略?)❓
🙋♂答:
常见的缓存更新策略共有3种
Cache Aside(旁路缓存)策略
最常用,应用程序直接与「数据库、缓存」交互,并负责对缓存的维护,该策略又可以细分为「读策略」和「写策略」。
- 写策略:先更新数据库中的数据,再删除缓存中的数据。
- 读策略:如果读取的数据命中了缓存,则直接返回数据;否则从数据库中读取数据,然后将数据写入到缓存,并且返回给用户。
- Cache Aside 策略适合读多写少的场景,不适合写多的场景,因为当写入比较频繁时,缓存中的数据会被频繁地清理,这样会对缓存的命中率有一些影响。如果业务对缓存命中率有严格的要求,那么可以考虑两种解决方案:
- 一种做法是在更新数据时也更新缓存,只是在更新缓存前先加一个分布式锁,同一时间只允许一个线程更新缓存,就不会产生并发问题。当然这么做对于写入的性能会有一些影响;
- 另一种做法同样也是在更新数据时更新缓存,只是**给缓存加一个较短的过期时间,**这样即使出现缓存不一致的情况,缓存的数据也会很快过期,对业务的影响也是可以接受。
Read/Write Through(读穿 / 写穿)策略
该策略原则是应用程序只和缓存交互,不再和数据库交互,而是由缓存和数据库交互,相当于更新数据库的操作由缓存自己代理了。
我们经常使用的分布式缓存组件,无论是 Memcached 还是 Redis 都不提供写入数据库和自动加载数据库中的数据的功能,所以不常用。
Write Back(写回)策略
在更新数据的时候,只更新缓存,同时将缓存数据设置为脏的,然后立马返回,并不会更新数据库。对于数据库的更新,会通过批量异步更新的方式进行。
Write Back(写回)策略也不能应用到我们常用的数据库和缓存的场景中,因为 Redis 并没有异步更新数据库的功能。
为什么写策略先更新数据库,再删除缓存❓
🙋♂答:
因为只有这种情况可以保证缓存的一致性。
-
情况一:先删除缓存,再更新数据库。删除缓存后,操作二进行读操作,将缓存修改。此时操作一更新数据库,就会发生缓存和数据库不一致的问题。
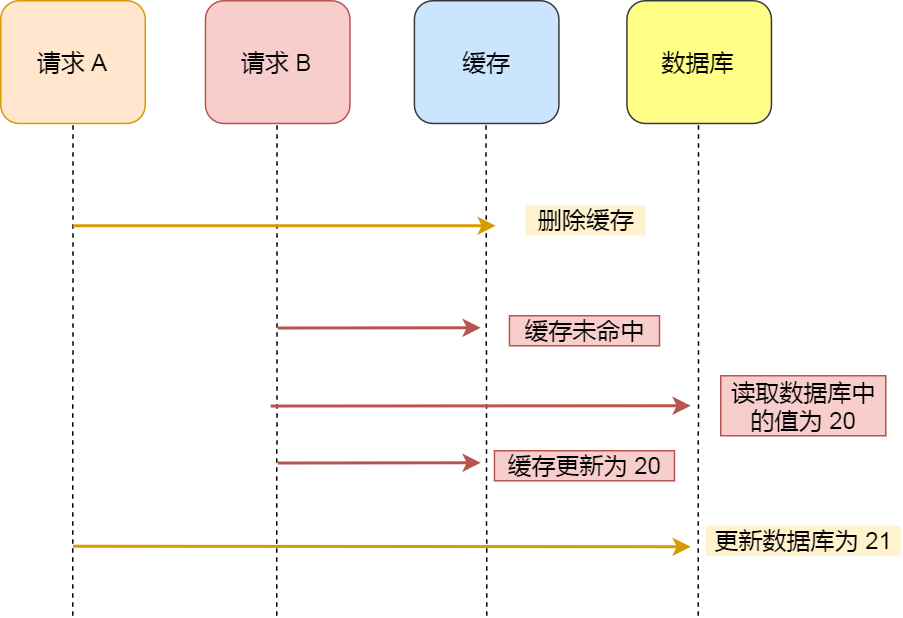
-
情况二:先更新数据库,再更新缓存,会出现数据库和缓存不一致的现象。
如果产生两次写操作,两次写操作交叉执行,那么最后更新的缓存可能时第一次写时的值。先更新缓存再更新数据库也同样。
-
情况三:写操作执行之后,读操作才将写回缓存。缓存的写入通常要远远快于数据库的写入,所以在实际中很难出现 写策略A已经更新了数据库并且删除了缓存,读策略B才更新完缓存的情况。
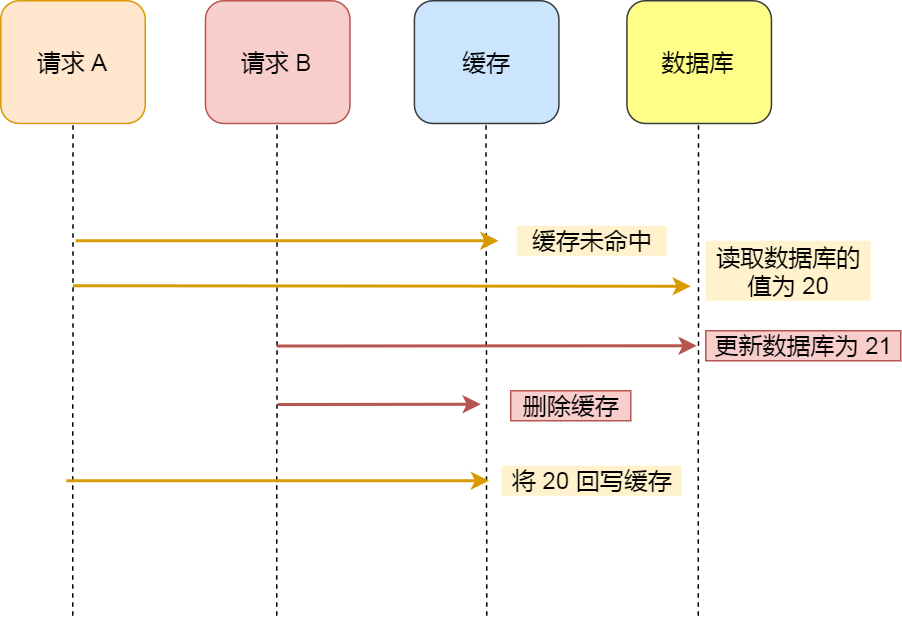
Redis 有哪些数据类型?SDS 了解么❓
🙋♂答:
String、List、Hash、Set、Zet都是比较常用的数据类型。
Redis 的 String 数据类型的底层数据结构是 SDS(simple dynamic string,SDS)
SDS这个数据结构中存在几个字段:
-
len,记录了字符串长度。这样获取字符串长度的时候,只需要返回这个成员变量值就行,时间复杂度只需要 O(1)。
-
alloc,分配给字符数组的空间长度。这样在修改字符串的时候,可以通过
alloc - len计算出剩余的空间大小,可以用来判断空间是否满足修改需求,如果不满足的话,就会自动将 SDS 的空间扩展至执行修改所需的大小,然后才执行实际的修改操作,所以使用 SDS 既不需要手动修改 SDS 的空间大小,也不会出现前面所说的缓冲区溢出的问题。 -
buf[],字符数组,用来保存实际数据。不仅可以保存字符串,也可以保存二进制数据。
-
flags,用来表示不同类型的 SDS。
对比C语言,主要有以下优势:
-
O(1)复杂度获取字符串长度
-
C 语言的字符串长度获取 strlen 函数,需要通过遍历的方式来统计字符串长度,时间复杂度是 O(N)。
-
而 Redis 的 SDS 结构因为加入了 len 成员变量,那么获取字符串长度的时候,直接返回这个成员变量的值就行,所以复杂度只有 O(1)。
-
-
二进制安全
-
因此, SDS 的 API 都是以处理二进制的方式来处理 SDS 存放在 buf[] 里的数据,程序不会对其中的数据做任何限制,数据写入的时候时什么样的,它被读取时就是什么样的。
通过使用二进制安全的 SDS,而不是 C 字符串,使得 Redis 不仅可以保存文本数据,也可以保存任意格式的二进制数据。
-
-
不会发生缓冲区溢出
-
Redis 的 SDS 结构里引入了 alloc 和 len 成员变量,这样 SDS API 通过
alloc - len计算,可以算出剩余可用的空间大小,这样在对字符串做修改操作的时候,就可以由程序内部判断缓冲区大小是否足够用。 -
而且,当判断出缓冲区大小不够用时,Redis 会自动将扩大 SDS 的空间大小,以满足修改所需的大小。
-
-
节省内存空间
flags成员变量表示SDS类型,SDS 设计了不同类型的结构体,是为了能灵活保存不同大小的字符串,从而有效节省内存空间。比如,在保存小字符串时,结构头占用空间也比较少。
除了设计不同类型的结构体,Redis 在编程上还使用了专门的编译优化来节省内存空间,即在 struct 声明了
__attribute__ ((packed)),它的作用是:告诉编译器取消结构体在编译过程中的优化对齐,按照实际占用字节数进行对齐。
Redis 内存满了怎么办❓
🙋♂答:
在Redis的配置文件redis.conf文件中,配置maxmemory可以设置Redis的内存大小。Redis 的运行内存超过了这个阀值,就会触发内存淘汰机制。
Redis 内存淘汰策略共有八种,这八种策略大体分为「不进行数据淘汰」和「进行数据淘汰」两类策略。
- 不进行数据淘汰的策略
- noeviction(不进行驱逐)(Redis3.0之后,默认的内存淘汰策略) :它表示当运行内存超过最大设置内存时,不淘汰任何数据,而是不再提供服务,直接返回错误。
- 进行数据淘汰的策略
- 在设置了过期时间的数据中进行淘汰:
- volatile-random:随机淘汰设置了过期时间的任意键值;
- volatile-ttl(Time-To-Live):优先淘汰更早过期的键值。
- volatile-lru(Least recently used,最近最少使用)(Redis3.0 之前,默认的内存淘汰策略):淘汰所有设置了过期时间的键值中,优先淘汰最久未用的键值;
- volatile-lfu(Least Frequently Used,最近最不常用)(Redis 4.0 后新增的内存淘汰策略):淘汰所有设置了过期时间的键值中,优先淘汰最近最不常用(使用次数最少)的键值;
- 在所有数据范围内进行淘汰:
- allkeys-random:随机淘汰任意键值;
- allkeys-lru:淘汰整个键值中最久未用的键值;
- allkeys-lfu(Redis 4.0 后新增的内存淘汰策略):淘汰整个键值中最不常用的键值。
- 在设置了过期时间的数据中进行淘汰:
Redis 内存淘汰算法除了 LRU 还有哪些❓
🙋♂答:
LFU 内存淘汰算法是 Redis 4.0 之后新增内存淘汰策略,为了解决 LRU 算法的问题。
-
LRU(最近最少使用)算法根据时间淘汰,LFU(最近最不常用)算法根据使用次数淘汰。
-
在 LRU 算法中,Redis 对象头的 24 bits 的 lru 字段是用来记录 key 的访问时间戳,因此在 LRU 模式下,Redis可以根据对象头中的 lru 字段记录的值,来比较最后一次 key 的访问时间长,从而淘汰最久未被使用的 key。
-
在 LFU 算法中,Redis对象头的 24 bits 的 lru 字段被分成两段来存储,高 16bit 存储 ldt(Last Decrement Time),低 8bit 存储 logc(Logistic Counter)。
- ldt 是用来记录 key 的访问时间戳;
- logc 是用来记录 key 的访问频次,它的值越小表示使用频率越低,越容易淘汰,每个新加入的 key 的logc 初始值为 5。logc 并不是单纯的访问次数,而是访问频次(访问频率),因为 logc 会随时间推移而衰减的。
-
LRU全称是 Least Recently Used ,也就是淘汰最近最少使用的数据。
- 传统 LRU 算法使用链表实现,链表中的元素按照操作顺序从前往后排列,最新操作的键会被移动到表头,当需要内存淘汰时,删除的链表尾部元素就代表最久未被使用的元素。
- Redis 并没有使用这样的方式实现 LRU 算法,因为传统的 LRU 算法存在两个问题:
- 用链表管理Redis中的缓存数据,会有空间开销。
- 当有数据被访问时,需要在链表上把该数据移动到头端,如果有大量数据被访问,就会带来很多链表移动操作,会很耗时,进而会降低 Redis 缓存性能。
- Redis 实现的是一种近似 LRU 算法,目的是为了更好的节约内存,它的实现方式是在 Redis 的对象结构体中添加一个额外的字段,用于记录此数据的最后一次访问时间。
- 当 Redis 进行内存淘汰时,会使用随机采样的方式来淘汰数据,它是随机取 5 个值(此值可配置),然后淘汰最久没有使用的那个。
- Redis 实现的 LRU 算法的优点:
- 不用为所有的数据维护一个大链表,节省了空间占用;
- 不用在每次数据访问时都移动链表项,提升了缓存的性能;
- 但是 LRU 算法有一个问题,无法解决缓存污染问题,比如应用一次读取了大量的数据,而这些数据只会被读取这一次,那么这些数据会留存在 Redis 缓存中很长一段时间,造成缓存污染。引入LFU算法解决了这个问题。
- LFU 全称是 Least Frequently Used 翻译为最近最不常用,LFU 算法是根据数据访问次数来淘汰数据的。
- Redis 在访问 key 时,对于 logc 是这样变化的:
- 先按照上次访问距离当前的时长,来对 logc 进行衰减;
- 然后,再按照一定概率增加 logc 的值。
- Redis 在访问 key 时,对于 logc 是这样变化的:
Redis 给缓存数据设置过期时间有啥用? Redis 是如何判断数据是否过期的呢?过期删除策略❓
🙋♂答:
Redis 是可以对 key 设置过期时间的,防止无用的key占用内存空间。因此需要有相应的机制将已过期的键值对删除,而做这个工作的就是过期键值删除策略。
-
Redis的过期字典中,保存了数据库中所有key的过期时间。当我们查询一个key,Redis会首先检查key是否存在与过期字典中。
- 如果不再,正常获取键值。
- 如果存在,则会进行比较时间之后判断。
-
Redis 使用的过期删除策略是「惰性删除+定期删除」这两种策略配和使用。
- 惰性删除策略的做法是,不主动删除过期键,每次从数据库访问 key 时,都检测 key 是否过期,如果过期则删除该 key。
- 优点:此策略使用很少的系统资源,对CPU最友好。缺点:过期的key会一直占用系统资源,对内存不友好。
- 定期删除策略的做法是,每隔一段时间「随机」从数据库中取出一定数量的 key 进行检查,并删除其中的过期key。
- 优点:通过限制删除操作执行时长和频率,可以减少对CPU的影响,同时也能删除部分数据,避免对内存的影响。缺点:难以确定删除操作执行时长和频率。
- 惰性删除策略的做法是,不主动删除过期键,每次从数据库访问 key 时,都检测 key 是否过期,如果过期则删除该 key。
















 455
455











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











