






刚开始使用selenium进行的人机交换,通过搜索框获取各帖子的内容,但这样可获取的信息太少,所以我又去抓包,在包中发现了更多详细的信息,所以又改为抓包获取信息。
一、观察微博关键词搜索的特点
我们先打开开发者工具中的network,在进行微博关键词搜索的过程中,观察是否存在包,直接包含所有数据。我们可以发现微博有一个“getIndex?containerid=100103type%3D1%26q%3D%E6%97%A0%E8%8A%B1%E6%9E%9C&page_type=searchall”的包,点击“preview”,我们可以看到其包含我们搜索的关键词,并且存在data。
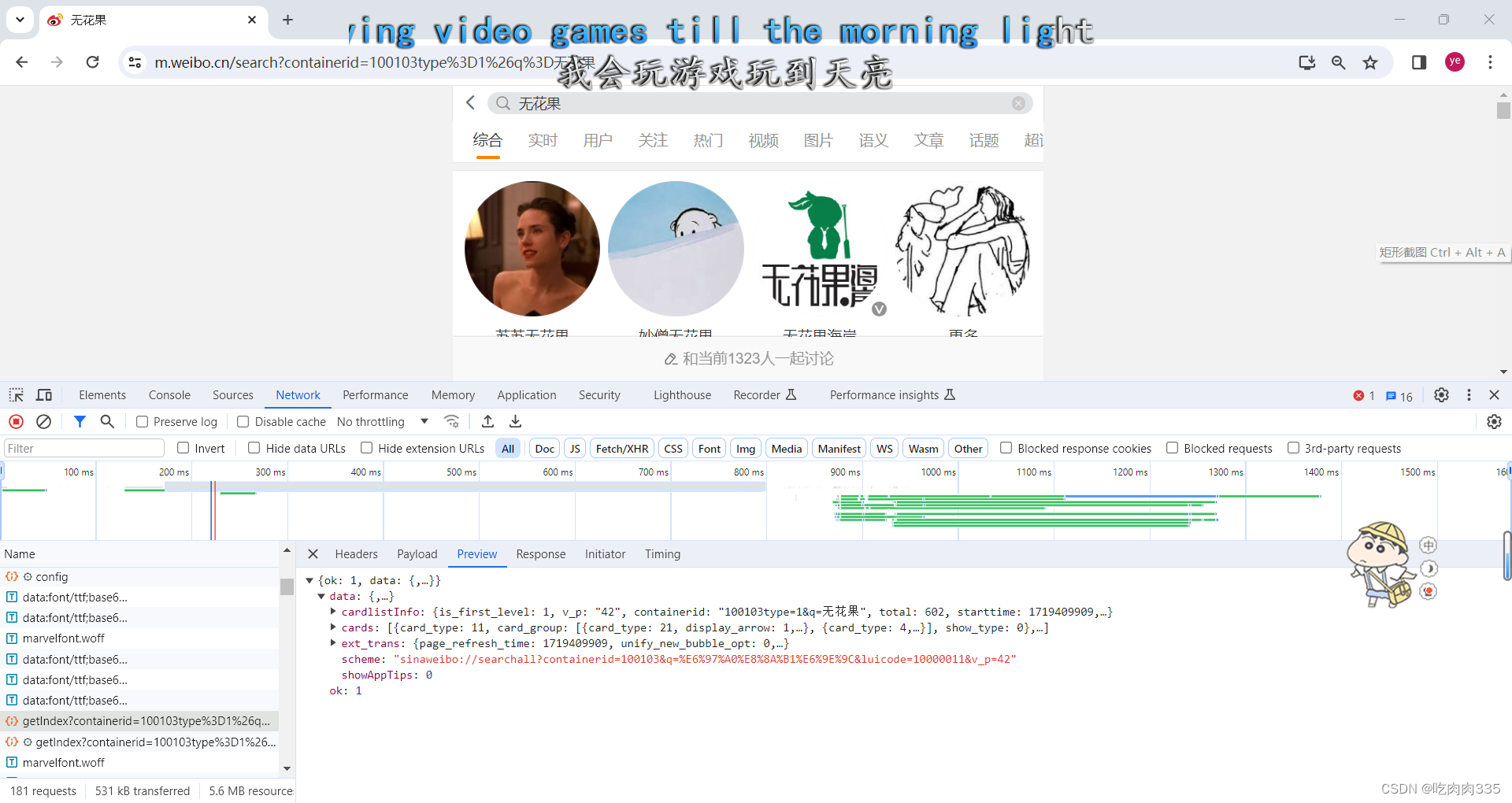
继续观察data,我们很明显的可以看到 cards下有多条数据,并且个数与显示的帖子的数量一致,说明我们找对了包。
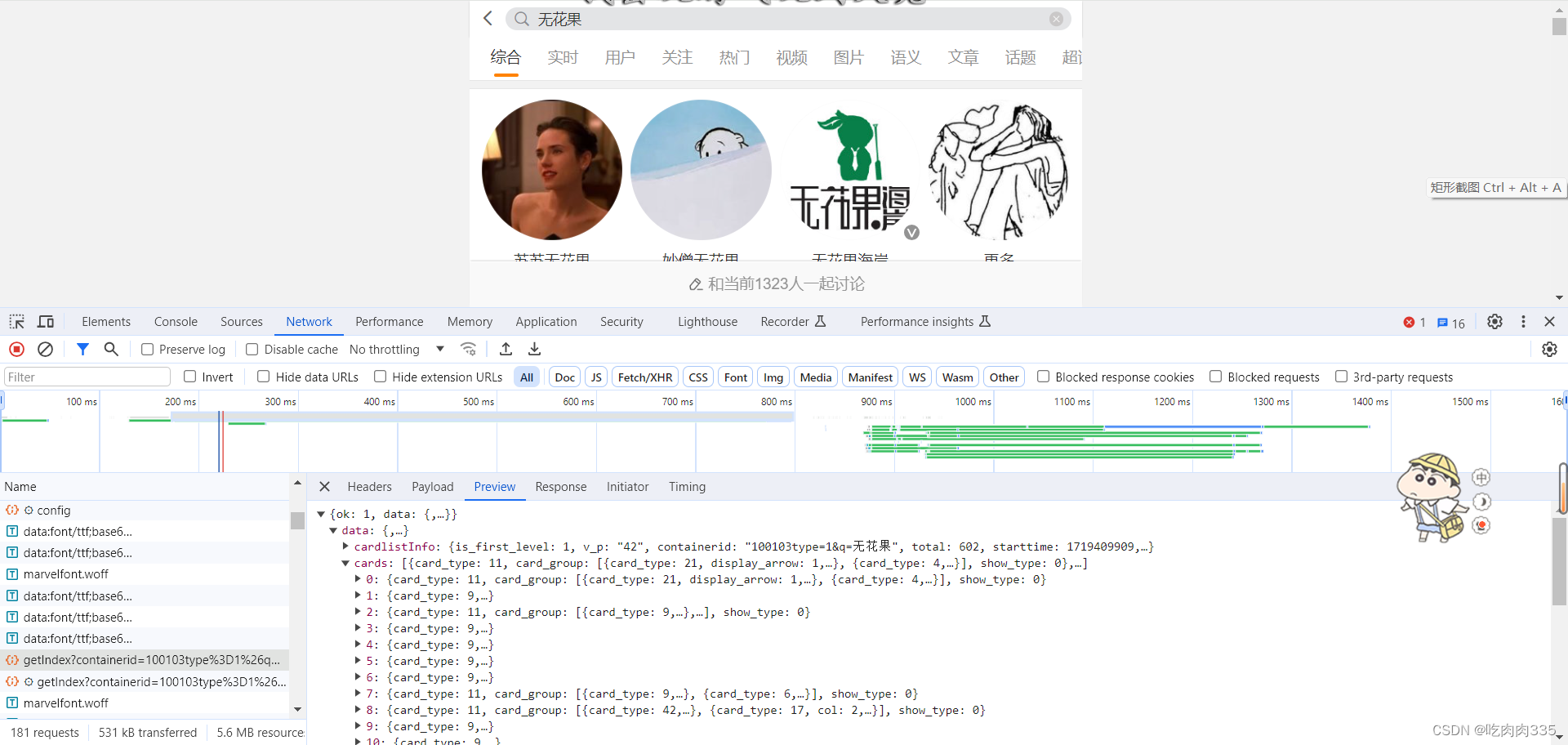
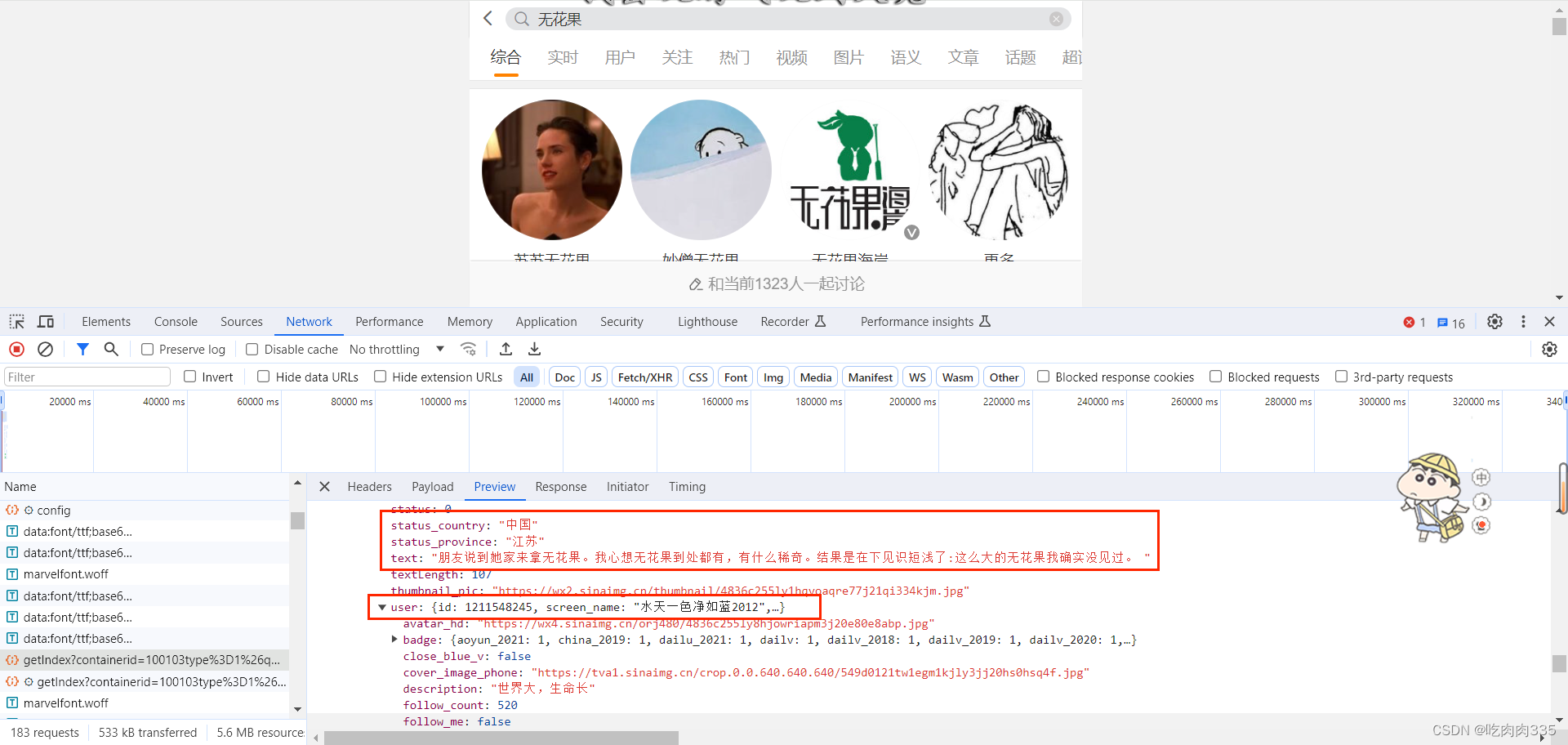
继续寻找我们想要爬取的参数,我们可以发现在mblog下就存在我们需要的参数,那么现在就确定该包就是我们需要的,开始编写代码。
二 、编写代码
def get_detail_by_all(url):
headers = {
# 这里的参数填自己的
'user-agent': '',
'cookie': '_',
'referer': 'https://m.weibo.cn/search?containerid=100103type%3D1%26q%3D' + quote(keyword)
}
response = requests.get(url, headers=headers)
cards = response.json()['data']['cards']
# print(cards[0])
for card in cards:
info = []
# print("********")
item = card['card_group'][0]
# 获取该帖子的id
mid = item['mblog']['mid']
info.append(mid)
# print(mid)
# 获取该帖子的内容,不包含超链接以及部分表情
text = item['mblog']['text']
content = re.sub(r'<[^>]+>', '', text)
info.append(content)
# print(content)
# 获取该帖子发表人的信息;id、昵称、所处地方
country = item['mblog']['status_country']
province = item['mblog']['status_province']
try:
city = item['mblog']['status_city']
except:
city = ''
info.append(country + province + city)
userId = item['mblog']['user']['id']
userName = item['mblog']['user']['screen_name']
# print((country, province, city, userId, userName))
info.append(userId)
info.append(userName)
# 获取帖子的创建时间,转发数reposts,评论数comments、点赞数attitudes
creatTime = item['mblog']['created_at']
reposts_count = item['mblog']['reposts_count']
comments_count = item['mblog']['comments_count']
attitudes_count = item['mblog']['attitudes_count']
# print(creatTime, reposts_count, comments_count, attitudes_count)
info.append(creatTime)
info.append(reposts_count)
info.append(comments_count)
info.append(attitudes_count)
print(info)三、多页爬取
上方代码抓取的是“综合”下的帖子信息,并且只抓取了一个包。当页面触底时,微博会再次发起一个包,流程如上,观察第二页的包的url:“https://m.weibo.cn/api/container/getIndex?containerid=100103type%3D1%26q%3D%E6%97%A0%E8%8A%B1%E6%9E%9C&page_type=searchall&page=2”,我们发现其实实际上就是加了“&page=2”这部分,那么多页面爬取的代码就容易编写了。
for i in range(2, page):
print(f'****正在爬取第{i}页')
time.sleep(random.randint(1, 3))
url = f'https://m.weibo.cn/api/container/getIndex?containerid=100103type%3D1%26q%3D{keyword}%3D&page_type=searchall&page={i}'
get_detail_by_time(url)四、可完善之处
1.如果需要大量数据进行研究,那么应该抓取“实时”的帖子信息,不定期的更新数据。
2.由于帖子内容过长,它只会显示部分内容,仍需继续抓取完善的信息。
3.还未将爬取的数据进行保存。















 3516
3516











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









