






一、应用场景
该网络爬虫系统基于租房场景。大数据时代,人们如果有租房需求,往往会通过在线租房平台来寻找房源。但同一地区的房源可能会散布在不同的租房平台上,这增加了用户寻找理想住房的时间成本。为了解决这个问题,设计并实现了一个基于微信小程序的网络爬虫系统,名为租房助手系统。该系统旨在通过网络爬虫技术获取各大租房平台的房屋信息,并利用微信生态系统提供的用户界面,将整合后的房屋信息以清晰透明的形式展示给用户,使用户能够轻松地进行数据查看与分析。同时系统管理员也可以利用清晰简洁的后台界面,进行系统管理。本系统不仅整合了微信小程序的优势,还结合了基于Python的网络爬虫技术,实现了高效的数据采集与数据处理,以及清晰简单的数据展示。
二、相关技术
python语言、flask框架,微信小程序开发者工具、网络爬虫技术(Selenium、Requests)、网络反爬虫技术、OCR技术。
三、主流的基于Python的网络爬虫技术
网络爬虫,通常也被称为网络蜘蛛或网络机器人,是一种按照一定方法,获取网络各种信息的自动化脚本程序,也可以将其理解为一个在互联网上自动提取网页信息并进行解析抓取的程序。网络爬虫的功能不仅局限于复制网页内容、下载音视频文件,更包括自动化执行行为链以及模拟用户登录等复杂操作。在当前大数据背景下,无论是人工智能应用还是数据分析工作,均依赖于海量的数据支持。如果仅依赖人工采集这一种方式,不仅效率低下且成本高昂。在这一需求下,自动化、高效且可并发执行的网络爬虫便担起了获取数据的重任。
目前国内外基于Python的主流爬虫技术有Requests技术、Scrapy技术和Selenium技术。要想设置一个网络爬虫,首先需要直接通过Request技术、Selenium自动化测试框架或Scrapy框架等方式请求URL,进行网页访问,获取响应数据,然后对数据进行解析,解析方法包括Regular Expression正则解析、Xpath解析、JSON解析以及Beautiful Soup 4解析等。最后,根据研究的数据格式要求,对数据进行持久化存储。
分别研究这三种网络爬虫技术,并对其进行对比,选定本系统采用的爬虫策略。详细:略。
四、反爬虫技术
由于网络爬虫的数据获取速率远远超过人类常规操作的速率,所以网络爬虫会过度消耗目标服务器的带宽资源。若众多用户都使用网络爬虫技术来抓取同一目标网站的信息,那么大量的、高频率的非人类用户请求将极大地加重目标网站服务器的运行负担。这种负荷的急剧增加不仅会影响服务器的响应效率,还会严重妨碍其他用户访问目标网站的速度,从而可能造成网络拥堵现象。为了减少网络爬虫对网站的潜在威胁,减轻网站服务器的压力,防止数据的大量流失,网站一般会采用以下几种反爬虫的技术限制网络爬虫:请求头校验机制、访问量限制、数据异步加载、验证码限制机制、CSS偏移量反爬虫等。详情:略。
五、功能模块
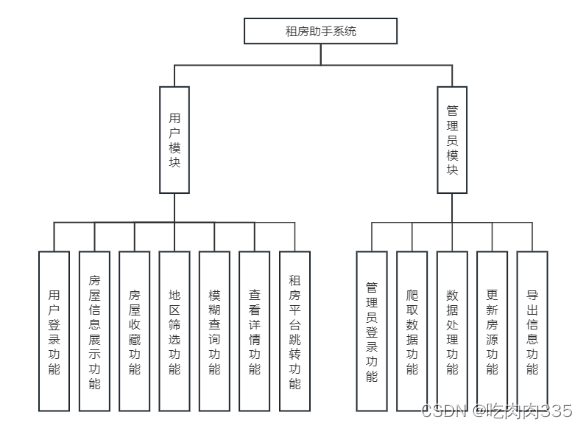
本系统分为用户模块与管理员模块两个模块。用户模块应具备以下功能:用户登录功能、房屋信息展示功能、房屋收藏功能、查看详情功能、租房平台跳转功能、地区筛选功能和模糊查询功能。管理员模块应具备以下功能:管理员登录功能、爬取数据功能、数据处理功能、更新房源功能、导出信息功能。
六、界面展示

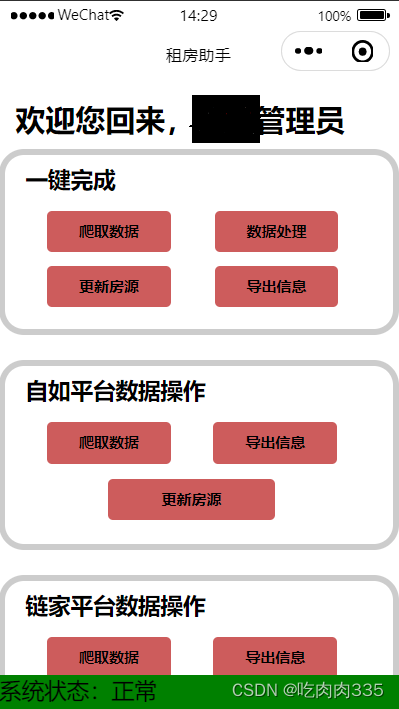

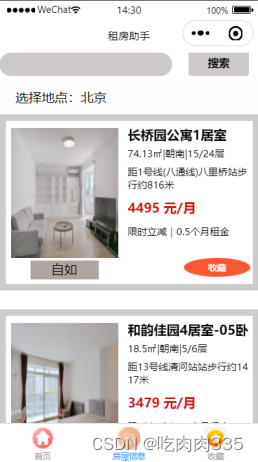















 1万+
1万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









