









摘要:
说明背景:大数据分析和预测的重要地位
存在问题:负荷预测模型需要消耗大量的关键词:足够种类的数据才能达到高精度,同时这些数据是敏感的;带宽消耗
提出使用联邦学习(FL)作为一种去中心化的机器学习差分隐私隐私保护(FL 方法不提供可证明的隐私保证)
(1)带宽高效
(2)引入了 POWER-SELECTION 协议来选择参与 FL 轮的建筑物
整体架构:
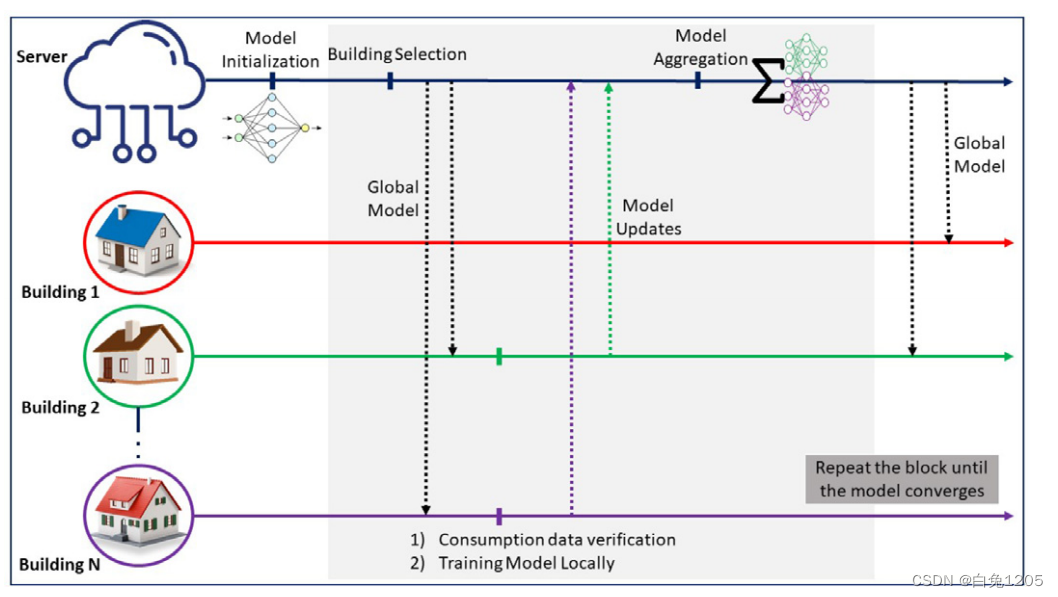
具体过程:
服务器的贡献系统操作员(DSO)通过训练公共数据集来初始化模型。然后,模型被发送到一组随机的活动建筑物。这些建筑物可以有不同的天气条件,并且位于不同的位置,这丰富了训练数据。每个建筑物都使用其本地数据集训练模型,然后将更新发送到 DSO。DSO 最终聚合发送的更新并生成新模型。这个过程将重复,直到全局模型稳定(经典联邦学习训练流程)
仍存在挑战:
(1)存在一些攻击,例如属性推断和成员资格
(2)捕获的梯度可用于重建整个训练样本
(3)巨大的带宽
因此,提出:
提出了一种带宽高效、隐私保护的 FL 框架,从理论上保证了隐私。
在提议的框架中,保留了差异隐私以克服隐私问题。这是一项具有挑战性的任务,随着不平衡数据的增加,差分隐私所需的注入噪声也会增加。因此,模型质量大大恶化。(那怎么缓解呢)
还依靠梯度的极端量化来降低通信成本。我们还使用小批量的下采样来减少差异隐私所需的噪声(缓解策略吗)。
此外,框架使用功率选择协议在参与的建筑物中选择一组建筑物来参加训练期。该过程的工作原理是选择局部损失值较高的建筑物参与下一轮。
结果:
证明了居住者级别的隐私,并且预测准确性几乎没有损失
在signSGD(Bernstein et al., 2018a)中,服务器接收基于所有参与边缘设备的单个小批量计算的随机梯度的符号向量。然后,服务器通过计算中值来聚合接收到的符号向量,并将聚合后的符号发送回边缘设备。(猜测受这篇文章启发)
与signSGD方案的区别:
• 目标是训练一个通用模型,该模型在每次迭代时分布在所有参与边缘设备的随机子集上。但是,signSGD 中的所有参与边缘设备均以相同的初始化共享模型开始,并且服务器在每次迭代时向所有参与边缘设备发送聚合模型。仅选择随机子集的事实有几个好处,包括针对临时节点故障的鲁棒性、上游通信成本降低和隐私增强。选择随机数据子集可以通过减少暴露的敏感信息量来帮助增强隐私性。当数据被随机采样或子集化时,攻击者重新识别个人数据点或推断有关个人的敏感信息变得更加困难。通过选择随机的数据子集,可以减少发布的敏感信息量,这有助于保护个人隐私。此外,随机二次采样可以帮助防止某些类型的攻击,例如成员推理攻击,其中攻击者试图推断特定个体是否包含在数据集中。然而,值得注意的是,随机二次采样提供的隐私保护水平取决于样本的大小和数据的分布。在某些情况下,随机二次采样可能不足以保护个人隐私,可能需要额外的隐私增强技术。
• 在signSGD 中,每个边缘设备使用单个小批量执行单个本地SGD 迭代。相比之下,我们的框架允许边缘设备在计算模型更新之前使用多个小批量在本地执行多个 SGD 迭代。 • 在signSGD 中,服务器在每一轮将聚合符号的符号发送到所有边缘设备。因此,每个参数仅向下游的所有边缘设备发送一位。在我们的框架中,整个模型被传输,但仅传输到边缘设备的随机子集。















 1454
1454











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









