







目录
一、mode获取类型
stu_name <- "Richard"
yield <- 100
mode(stu_name)
mode(yield)

列表相关操作
v <- c(1,2,3)
v
v <- c(v,4,5)
v
w <- c(6,7,8,9)
v <- c(v,w)
v[15] <- 0
v
append操作
append可以追加元素,在指定after之后可以指定追加的位置
x <- 1:10
x
y <- append(x,100,after=5)
y
z <- append(x,100,after=0)
z

这里我们可以看到我们可以指定将表中的某两列相加,求平均,其生成的数据会生成新的一列数据。
mydata <- data.frame( x1 = c(1,2,3,4), x2 = c(5,6,7,8))
mydata
mydata$sumx <- mydata$x1+mydata$x2
mydata
mydata$meanx <- (mydata$x1+mydata$x2)/2
mydata
attach与detach
attach与detach是成对使用的。attach可以与表相连,detach可以取消与表相连
attach(mydata)
mydata$sumx <- x1+x2
mydata$meanx <- (x1+x2)/2
detach(mydata)
mydata <- transform(mydata, sumx=x1+x2, meanx=(x1+x2)/2)
transform
使用transform来改变数据框
mydata <- transform(mydata, sumx=x1+x2, meanx=(x1+x2)/2)
mydata

二、特殊值
从下面的测试中,我们可以看到如果是NULL的话,R语言缺失为我们生成了一个对象,但是没有存储空间。如果是NA的话,R缺失给对象分配了一块空间,但是这块空间中的内容时空的。
NA表示无法获取的值
NULL表示因不存在而无法获取的值
Inf无穷,,1/0得到的就是Inf
NAN无法表示,不是一个数,使用Inf-Inf所得到的就是NAN
x <- NULL
y <- NA
length(x)
length(y)
查看是否有NA
y <- c(1,2,3,NA)
is.na(y)
如果在数据里面包含NA时无法进行运算的,但我们可以使用na.rm=T来将我们的NA给忽略掉
x <- y[1]+y[2]+y[3]+y[4]
x
z <- sum(y)
z
l <- sum(y, na.rm=T)
l
na.omit
我们也可以使用na.omit()来将我们移除全部包含NA的观测。
mydata <- read.table("/Users/yangkailiang/Documents/R/data/leadership.csv",
header=T, sep=",")
mydata
newdata <- na.omit(mydata)
newdata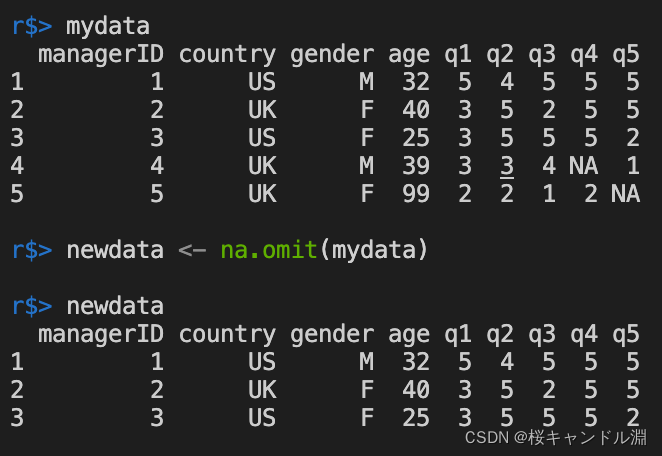
三、类型转换
| 判断是否是该类型 | 类型转换 |
| is.character() | as.character() |
| is.vector() | as.vector() |
| is.matrix() | as.matrix() |
| is.data.frame() | as.data.frame() |
| is.factor() | as.factor() |
| is.logical() | as.logical() |
| is.numeric() | as.numeric() |
a <- c(1,2,3)
a
is.numeric(a)
is.vector(a)
a <- as.character(a)
is.numeric(a)
is.vector(a)
is.character(a) 
四、数据排序
sort()/order()
从下面的测试代码中我们可以看出,如果直接使用sort本身的话,本身的数据的顺序是不会发生改变的,燃石如果我们将排序好的数据传给我们别的变量来接收的话,接收到的数据就是排好序的。默认的顺序是升序。
x <- c(12,4,7,11,2)
sort(x)
x
y <- sort(x)
y
z <- order(x)
x[z]
此外,我们也可以使用order来使我们的数据有序。但order生成的是该数组中的每一个元素的大小排序的索引值。所以我们需要用x[z]来使我们的数据呈现出有序的状态。从下面的图中我们可以看到x中的第一个元素应该排在第五个位置,第二个元素应该排在第二个位置,以此类推。

对表格中的某一列进行排序
#按照我们的age列进行排序
newdata <- mydata[order(mydata$age),]
#按照我们的age列进行降序排序
newdata2 <- mydata[order(mydata$age,decreasing=T),]
#先按照gender进行排序,再按照age进行升序排序
newdata3 <- mydata[order(mydata$gender,mydata$age),]
attach(mydata)
#先按照gender进行排序,再按照年龄进行降序排序
newdata4 <- mydata[order(gender,-age),]
newdata4
detach(mydata)
五、数据集的合并
1、直接横向合并
直接横向合并不需要指定公共索引
C = cbind(A,B)
2.如果需要指定索引
C = merge(A,B, by="公共索引")
C = merge(A,B, by="ID")
C = merge(A,B, by=c("ID","Country"))
3.纵向合并
如果需要纵向合并,A与B,A与B需要拥有完全相同的变量(顺序可以不一样)
4.示例
这里是我们四张表格的数据

#直接将我们的两张表格合并在一起(左右)
cdata <- cbind(data1,data3)
data5 <- cbind(data1,data4)
#使用merge函数的话,会自动合并对应值
data6 <- merge(data1,data2)
data7 <- merge(data1,data4)
#按照kids列进行合并排序
data8 <- merge(data1,data4,by="kids")
六、取数据集子集
1、选入变量(列)
#从我们的mydata中选取全部行,取第1,2,4列
newdata <- mydata[,c(1,2,4)]
#从我们的mydata中选取全部行,取managerID,country,age列
newdata2 <- mydata[,c("managerID","country","age")]
2、剔除变量(列)
mydata
#方法一
#剔除mydata种地第一列,第二列,第四列
newdata <- mydata[,c(-1,-2,-4)]
newdata
#方法二
#剔除"managerID","country","age"这三列,会返回一个布尔类型的向量
#%in%为一个运算符
delvar <- names(mydata) %in% c("managerID","country","age")
newdata2 <- mydata[!delvar] 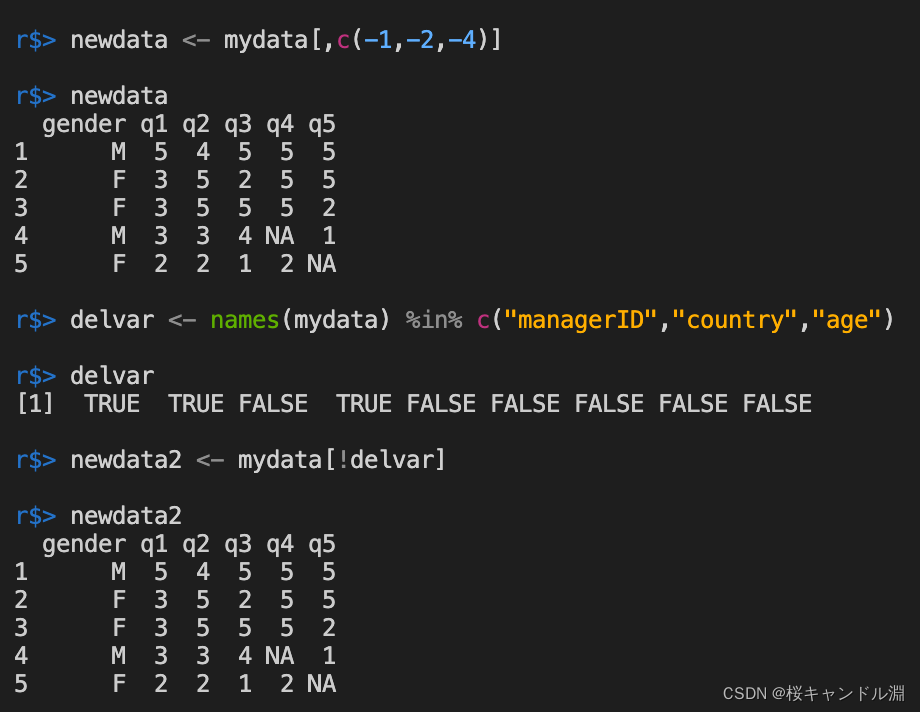
3.选入观测
#选取一到三行,全部的列
newdata <- mydata[1:3,]
newdata
#筛选出性别是M,并且年龄大于30的观测
newdata1 <- mydata[which(mydata$gender=="M" & mydata$age>30),]
newdata1
attach(mydata)
#筛选出性别是M,并且年龄大于30的观测
newdata2 <- mydata[which(gender=="M" & age>30),]
newdata2
detach(mydata)
七、使用函数subset()选择观测
#对我们mydata数据框中筛选年龄大于等于35或者年龄小于24的的观测,并且将其q1,q2,q3列的数据显示出来
newdata <- subset(mydata, age>=35 | age < 24,select=c("q1","q2","q3"))
newdata
#将mydata数据框中性别为M,并且年龄大于25,将其中gender列到q4列全部都显示出来
newdata2 <- subset(mydata, gender == "M" & age >25,select=gender:q4)
newdata2
八、处理数据对象实用函数

length(newdata)
dim(newdata)
#str是struct的缩写
str(newdata)
class(newdata)
mode(newdata)
names(newdata)
head(newdata)
tail(newdata)
ls(newdata)
九、向量分组
split()返回值为一个列表,按照某一个因子变量对数据集进行分隔。
library(MASS)
groups<-split(Cars93$MPG.city,Cars93$Origin)
groups[[1]]
groups[[2]]十、将函数应用于每个列表元素
lapply返回结果为列表
sapply返回结果为向量
scores <- list(S1=numeric(0),S2=numeric(0),S3=numeric(0),S4=numeric(0))
scores$S1 <- c(89,85,85,62,93,77,85)
scores$S2 <- c(60,100,83,77,86)
scores$S3 <- c(95,86,91,82,63,67,97,64,55)
scores$S4 <- c(67,63,83,89)
lapply(scores,length)
sapply(scores,mean)


十一、将函数应用于行或列
apply()
results <- apply(matrix,1,function) #对矩阵的行进行处理
results <- apply(matrix,2,function) #对矩阵的列进行处理对于数据框而言,如果每一行的数据类型一致,则可以使用apply来处理
如果数据框的列数据类型不一致,则需要使用上述的lapply与sapply来进行处理
Mat_long <- matrix(c(-1.85,0.94,-0.54,-1.41,1.35,-1.71,-1.01,-0.16,-0.35,-3.72,1.63,-0.28,-0.28,2.45,-1.22),nrow=3,dimnames=list(c("Moe", "Larry","Curly"),c("trial1","trial2","trial3","trial4","trial")))
apply(Mat_long,1,mean)
apply(Mat_long,1,range)
apply(Mat_long,2,mean) 
十二、将函数应用于组数据
tapply(vector,factor,function)
vector为一个向量,factor为一个分组因子,function是一个函数,即需要对vector进行的方法
wagedata <- read.csv("/Users/Documents/R/data/wagedata.csv")
attach(wagedata)
#先将edu按照female进行分组,然后分别求平均值
tapply(educ,female,mean)
detach(wagedata)
educ

十三、将函数应用于行组
by(dataframe,factor,function)
dataframe是一个向量,factor是一个分组因子,function是一个函数
wagedata <- read.csv("/Users/Documents/R/data/wagedata.csv")
by(wagedata,female,mean)
十四、用户自编函数
myfunction <- function(arg1,arg2,...){
statements
return(object)
}
#以下为勾股定理的编写
#向量的平方指的是每一个分量的平方,然后我们将每一个分量的平方相加再开平方,我们就能够得到我们第三条边的长度。
lengththm <- function(x) {
thirdl <- sqrt(sum(x^2))
return(thirdl)
}
a <- c(3,4)
lengththm(a) 
十五、循环
for (var in seq) {
statements
}
while (condition) {
statements
}
x <- c(2,5,10)
for (n in x)
print(n^2) 















 1199
1199











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











