






 本文介绍了如何在软件开发中实现控制台输出的敏感信息脱敏,包括操作流程、自定义日志输出类的转换规则,以及对手机号、中文名称和邮箱地址等特定类型数据的脱敏方法,以提升系统的安全性和保密性。
本文介绍了如何在软件开发中实现控制台输出的敏感信息脱敏,包括操作流程、自定义日志输出类的转换规则,以及对手机号、中文名称和邮箱地址等特定类型数据的脱敏方法,以提升系统的安全性和保密性。
目录
判断从字符串msg获取的key值是否为单词 , index为key在msg中的索引值
控制台脱敏是指在软件开发或运维过程中,对控制台(Console)输出的敏感信息进行隐藏或部分隐藏的处理方式。这样做的主要目的是保护敏感信息不被泄露,提高系统的安全性和保密性。以下是一些做控制台脱敏的主要原因:
-
保护敏感信息: 控制台输出可能包含用户密码、API 密钥、数据库连接字符串等敏感信息。如果这些信息被泄露,可能会导致安全漏洞或数据泄露,因此需要对其进行脱敏处理。
-
遵守法律法规: 根据一些法律法规(如 GDPR、HIPAA 等),个人隐私和敏感数据的保护是法律要求的。对控制台输出的敏感信息进行脱敏是遵守法律法规的重要手段之一。
-
降低风险: 在开发和调试过程中,开发人员可能会在控制台输出中包含调试信息或敏感数据,但这并不适合在生产环境中展示。对控制台输出进行脱敏可以降低意外泄露敏感信息的风险。
-
提高安全性: 控制台输出通常是系统运行状态的一部分,如果敏感信息直接显示在控制台上,可能会被未授权的人员或恶意用户看到。通过脱敏处理,可以提高系统的安全性,防止信息泄露。
-
符合最佳实践: 在软件开发和运维领域,保护用户隐私和敏感数据是一项基本的最佳实践。对控制台输出进行脱敏是这一最佳实践的一部分。
-
操作流程
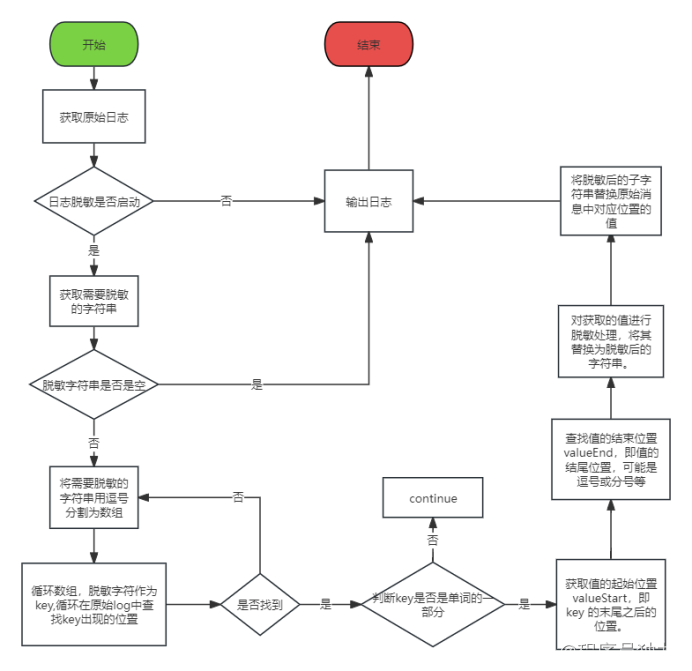
-
自定义日志输出类conversionRule
获取原始日志
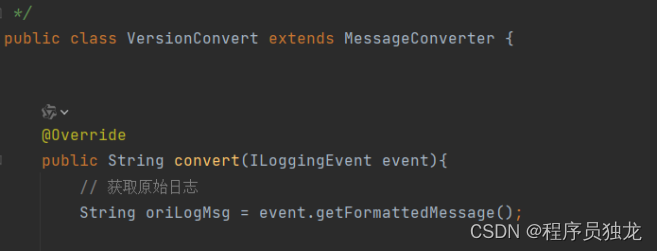
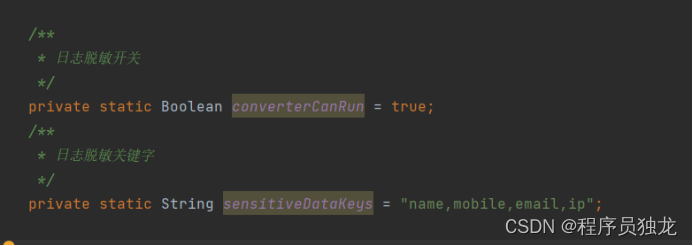
定义日志脱敏开关和脱敏关键字
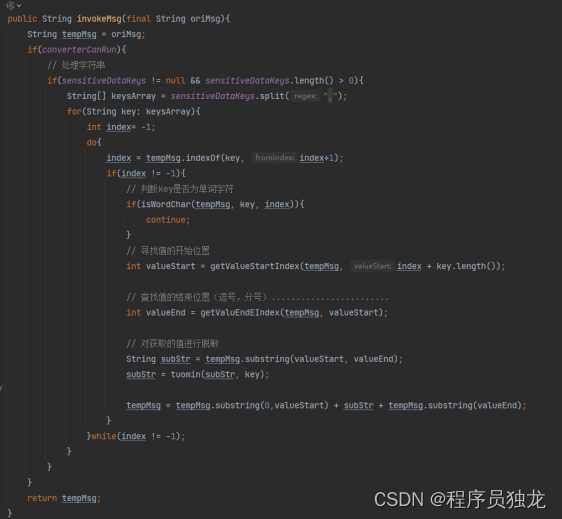
处理日志字符串,返回脱敏后的字符串
判断从字符串msg获取的key值是否为单词 , index为key在msg中的索引值
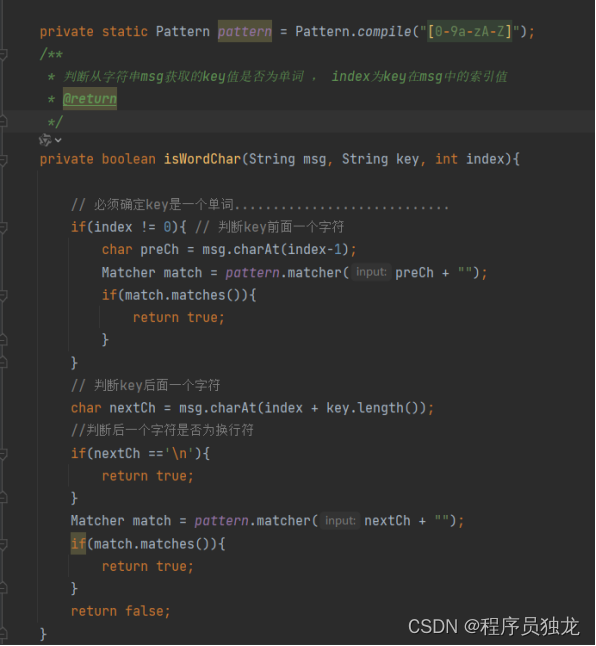
isWordChar 方法用于判断从字符串 msg 中获取的 key 值是否为单词的一部分。该方法主要用于辅助敏感数据处理方法中的逻辑判断。
方法参数:
- msg:待处理的字符串,即原始消息。
- key:要判断的关键字。
- index:key 在 msg 中的索引位置。
-
方法实现
首先,定义了一个静态的正则表达式模式 pattern,用于匹配数字和字母字符 [0-9a-zA-Z]。
然后,根据索引位置 index,判断 key 是否为单词的一部分,具体步骤如下:若 index 不为 0,则判断 key 前一个字符是否为单词字符:获取 key 前一个字符 preCh。
使用正则表达式匹配判断 preCh 是否为字母或数字,如果是,则返回 true,表示 key 前面有单词字符。
判断 key 后一个字符是否为单词字符:获取 key 后一个字符 nextCh。若 nextCh 为换行符 \n,则返回 true,表示 key 后面有单词字符。否则,使用正则表达式匹配判断 nextCh 是否为字母或数字,如果是,则返回 true,表示 key 后面有单词字符。
若以上条件均不满足,则返回 false,表示 key 前后均没有单词字符。
获取value值的开始位置
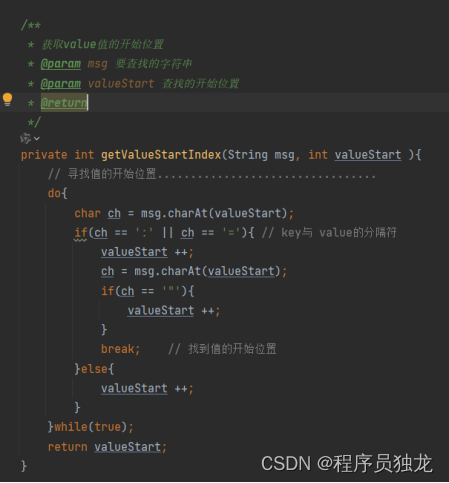
getValueStartIndex 方法用于获取字符串 msg 中值的起始位置,即键值对中值的开始位置。该方法通常用于解析消息中的键值对。
方法参数
- msg:要查找的字符串,即原始消息。
- valueStart:查找的起始位置,即从该位置开始向后搜索值的起始位置。
-
方法实现
方法通过一个 do-while 循环来寻找值的开始位置。
在循环中,逐字符检查消息字符串 msg:若当前字符 ch 是键值对的分隔符 ':' 或 '=',表示可能是值的开始位置。
如果下一个字符是 '"',则表示值的起始位置在双引号内,此时将 valueStart 向后移动一位。循环结束,表示找到值的开始位置。
如果当前字符不是分隔符,则继续向后移动 valueStart。
返回找到的值的起始位置 valueStart。
获取value值的结束位置
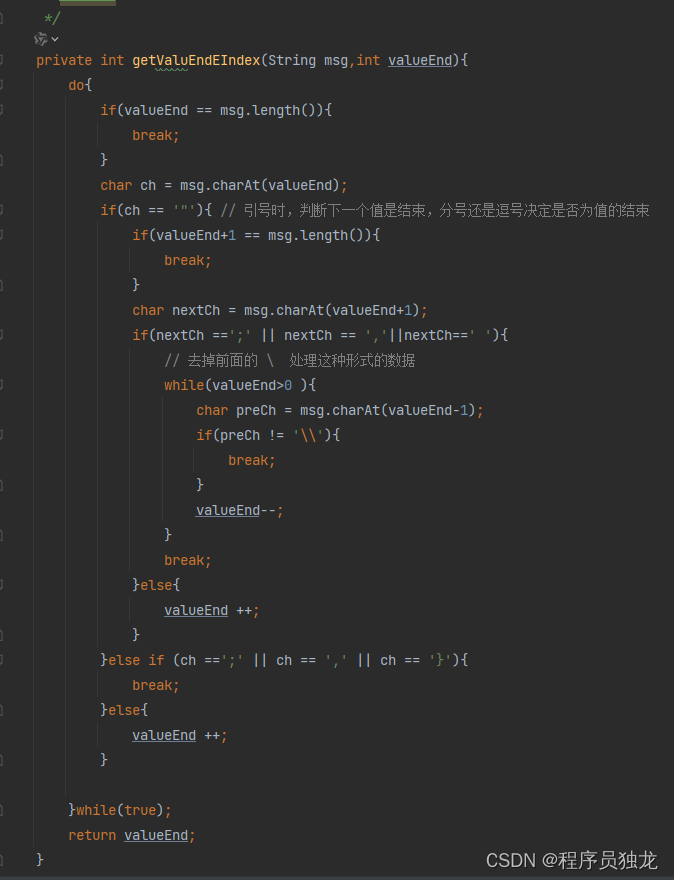
getValuEndEIndex 方法用于获取字符串 msg 中值的结束位置,即键值对中值的末尾位置。该方法通常用于解析消息中的键值对。
方法参数
- msg:要查找的字符串,即原始消息。
- valueEnd:值的结束位置的初始值,即从该位置开始向后搜索值的结束位置。
-
返回找到的值的结束位置 valueEnd。
方法实现
方法通过一个 do-while 循环来寻找值的结束位置。
在循环中,逐字符检查消息字符串 msg:
若当前字符 ch 是双引号 '"',表示值可能在双引号内,需要进一步判断下一个字符。
如果下一个字符是分号 ';'、逗号 ',' 或空格 ' ',则表示双引号内的值结束。
同时,检查双引号前是否有转义字符 '\',如果有,则需要将值的结束位置向前调整,直到找到非转义的双引号。
循环结束,表示找到值的结束位置。
否则,继续向后移动 valueEnd。
如果当前字符是分号 ';'、逗号 ',' 或大括号 '}',表示值的结束位置在当前位置。循环结束,表示找到值的结束位置。如果当前字符不是以上情况,则继续向后移动 valueEnd。
数据脱敏
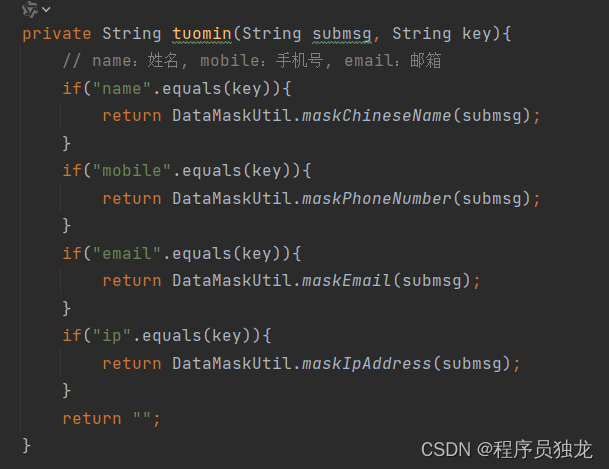
自定义脱敏工具类
手机号脱敏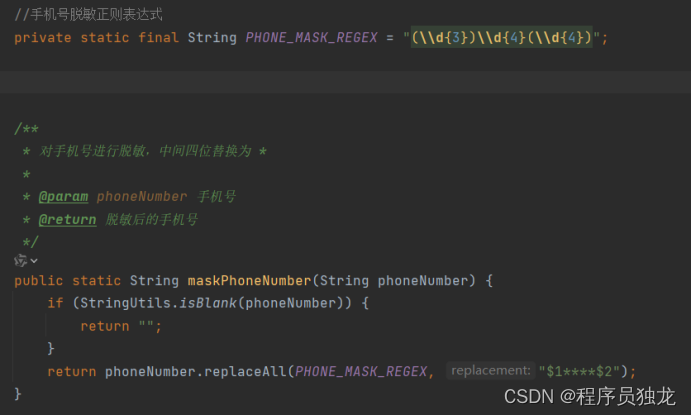
对中文名称脱敏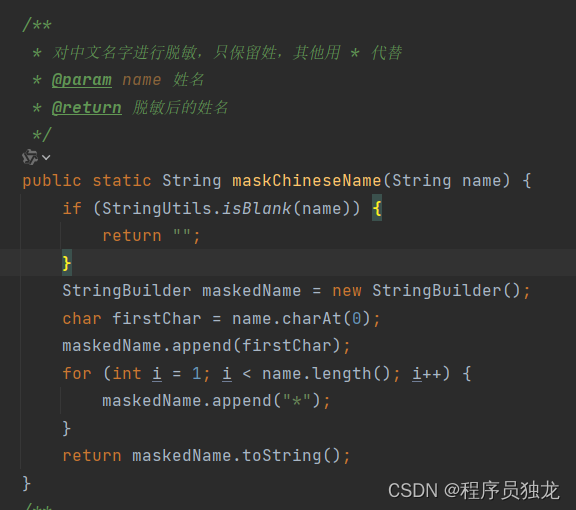
对邮箱脱敏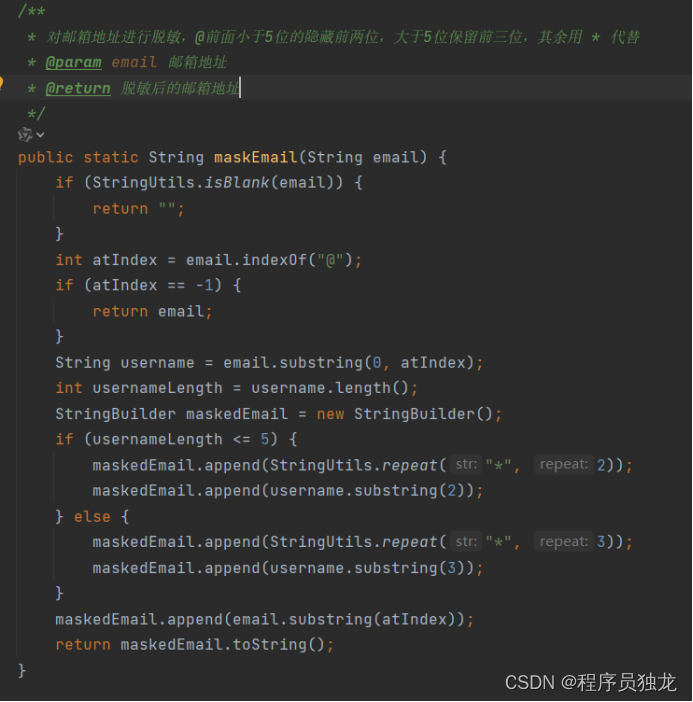
完整代码
package com.wenbo.common.utils;
import ch.qos.logback.classic.pattern.MessageConverter;
import ch.qos.logback.classic.spi.ILoggingEvent;
import java.util.regex.Matcher;
import java.util.regex.Pattern;
/**
* @author chensheng
* @date 2023/2/10 14:27
*/
public class VersionConvert extends MessageConverter {
@Override
public String convert(ILoggingEvent event){
// 获取原始日志
String oriLogMsg = event.getFormattedMessage();
// 获取脱敏后的日志
String afterLogMsg = invokeMsg(oriLogMsg);
return afterLogMsg;
}
/**
* 日志脱敏开关
*/
private static Boolean converterCanRun = true;
/**
* 日志脱敏关键字
*/
private static String sensitiveDataKeys = "name,mobile,email,ip";
/**
* 处理日志字符串,返回脱敏后的字符串
* @param oriMsg
* @return
*/
public String invokeMsg(final String oriMsg){
String tempMsg = oriMsg;
if(converterCanRun){
// 处理字符串
if(sensitiveDataKeys != null && sensitiveDataKeys.length() > 0){
String[] keysArray = sensitiveDataKeys.split(",");
for(String key: keysArray){
int index= -1;
do{
index = tempMsg.indexOf(key, index+1);
if(index != -1){
// 判断key是否为单词字符
if(isWordChar(tempMsg, key, index)){
continue;
}
// 寻找值的开始位置
int valueStart = getValueStartIndex(tempMsg, index + key.length());
// 查找值的结束位置(逗号,分号)........................
int valueEnd = getValuEndEIndex(tempMsg, valueStart);
// 对获取的值进行脱敏
String subStr = tempMsg.substring(valueStart, valueEnd);
subStr = tuomin(subStr, key);
///
tempMsg = tempMsg.substring(0,valueStart) + subStr + tempMsg.substring(valueEnd);
}
}while(index != -1);
}
}
}
return tempMsg;
}
private static Pattern pattern = Pattern.compile("[0-9a-zA-Z]");
/**
* 判断从字符串msg获取的key值是否为单词 , index为key在msg中的索引值
* @return
*/
private boolean isWordChar(String msg, String key, int index){
// 必须确定key是一个单词............................
if(index != 0){ // 判断key前面一个字符
char preCh = msg.charAt(index-1);
Matcher match = pattern.matcher(preCh + "");
if(match.matches()){
return true;
}
}
// 判断key后面一个字符
char nextCh = msg.charAt(index + key.length());
//判断后一个字符是否为换行符
if(nextCh =='\n'){
return true;
}
Matcher match = pattern.matcher(nextCh + "");
if(match.matches()){
return true;
}
return false;
}
/**
* 获取value值的开始位置
* @param msg 要查找的字符串
* @param valueStart 查找的开始位置
* @return
*/
private int getValueStartIndex(String msg, int valueStart ){
// 寻找值的开始位置.................................
do{
char ch = msg.charAt(valueStart);
if(ch == ':' || ch == '='){ // key与 value的分隔符
valueStart ++;
ch = msg.charAt(valueStart);
if(ch == '"'){
valueStart ++;
}
break; // 找到值的开始位置
}else{
valueStart ++;
}
}while(true);
return valueStart;
}
/**
* 获取value值的结束位置
* @return
*/
private int getValuEndEIndex(String msg,int valueEnd){
do{
if(valueEnd == msg.length()){
break;
}
char ch = msg.charAt(valueEnd);
if(ch == '"'){ // 引号时,判断下一个值是结束,分号还是逗号决定是否为值的结束
if(valueEnd+1 == msg.length()){
break;
}
char nextCh = msg.charAt(valueEnd+1);
if(nextCh ==';' || nextCh == ','||nextCh==' '){
// 去掉前面的 \ 处理这种形式的数据
while(valueEnd>0 ){
char preCh = msg.charAt(valueEnd-1);
if(preCh != '\\'){
break;
}
valueEnd--;
}
break;
}else{
valueEnd ++;
}
}else if (ch ==';' || ch == ',' || ch == '}'){
break;
}else{
valueEnd ++;
}
}while(true);
return valueEnd;
}
private String tuomin(String submsg, String key){
// name:姓名, mobile:手机号, email:邮箱
if("name".equals(key)){
return DataMaskUtil.maskChineseName(submsg);
}
if("mobile".equals(key)){
return DataMaskUtil.maskPhoneNumber(submsg);
}
if("email".equals(key)){
return DataMaskUtil.maskEmail(submsg);
}
if("ip".equals(key)){
return DataMaskUtil.maskIpAddress(submsg);
}
return "";
}
}
package com.wenbo.common.utils;
/**
* @author ChenSheng
* @date 2023/10/19 9:16
*
*/
public class DataMaskUtil {
//手机号脱敏正则表达式
private static final String PHONE_MASK_REGEX = "(\\d{3})\\d{4}(\\d{4})";
/**
* 对手机号进行脱敏,中间四位替换为 *
*
* @param phoneNumber 手机号
* @return 脱敏后的手机号
*/
public static String maskPhoneNumber(String phoneNumber) {
if (StringUtils.isBlank(phoneNumber)) {
return "";
}
return phoneNumber.replaceAll(PHONE_MASK_REGEX, "$1****$2");
}
/**
* 对中文名字进行脱敏,只保留姓,其他用 * 代替
* @param name 姓名
* @return 脱敏后的姓名
*/
public static String maskChineseName(String name) {
if (StringUtils.isBlank(name)) {
return "";
}
StringBuilder maskedName = new StringBuilder();
char firstChar = name.charAt(0);
maskedName.append(firstChar);
for (int i = 1; i < name.length(); i++) {
maskedName.append("*");
}
return maskedName.toString();
}
/**
* 对邮箱地址进行脱敏,@前面小于5位的隐藏前两位,大于5位保留前三位,其余用 * 代替
* @param email 邮箱地址
* @return 脱敏后的邮箱地址
*/
public static String maskEmail(String email) {
if (StringUtils.isBlank(email)) {
return "";
}
int atIndex = email.indexOf("@");
if (atIndex == -1) {
return email;
}
String username = email.substring(0, atIndex);
int usernameLength = username.length();
StringBuilder maskedEmail = new StringBuilder();
if (usernameLength <= 5) {
maskedEmail.append(StringUtils.repeat("*", 2));
maskedEmail.append(username.substring(2));
} else {
maskedEmail.append(StringUtils.repeat("*", 3));
maskedEmail.append(username.substring(3));
}
maskedEmail.append(email.substring(atIndex));
return maskedEmail.toString();
}
/**
* 对ip进行脱敏
* @param ipAddress
* @return
*/
public static String maskIpAddress(String ipAddress) {
int lastDotIndex = ipAddress.lastIndexOf(".");
// 如果没有找到点号,则返回原始IP地址
if (lastDotIndex == -1) {
return ipAddress;
}
String maskedPart = ipAddress.substring(0, lastDotIndex + 1) + "*";
return maskedPart;
}
}


















 2109
2109

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









