






目录
一、数据容器
Python中的数据容器:
一种可以容纳多份数据的数据类型,容纳的每一份数据称之为1个元素
每一个元素,可以是任意类型的数据,如字符串、数字、布尔等。
数据容器根据特点的不同,
如:
是否支持重复元素
是否可以修改
是否有序,等
分为5类,分别是:
列表(list)、元组(tuple)、字符串(str)、集合(set)、字典(dict)

1.list(列表)
1.1列表的定义
基本语法:

列表内的每一个数据,称之为元素
以 [] 作为标识
列表内每一个元素之间用, 逗号隔开
列表可以嵌套列表
1.2列表的下标(索引)
1.2.1使用:下标索引

列表中的每一个元素,都有其位置下标索引,从前向后的方向,从0开始,依次递增
我们只需要按照下标索引,即可取得对应位置的元素。
#语法:列表[下标索引]
name_list=['斯蒂芬库里','保罗乔治','勒布朗詹姆斯']
print(name_list[0]) #结果:史蒂芬库里
print(name_list[1]) #结果:保罗乔治
print(name_list[2]) #结果:勒布朗詹姆斯1.2.2下标索引 - 反向
可以反向索引,也就是从后向前:从-1开始,依次递减(-1、-2、-3......)

#语法:列表[下标索引]
name_list=['斯蒂芬库里','保罗乔治','勒布朗詹姆斯']
print(name_list[-1]) #结果:勒布朗詹姆斯
print(name_list[-2]) #结果:保罗乔治
print(name_list[-3]) #结果:斯蒂芬库里
1.2.3嵌套列表的下标(索引)
如果列表是嵌套的列表,同样支持下标索引

如图,下标就有2个层级了。
#2层嵌套list
my_list=[[1,2,3],[4,5,6]]
#获取内层第一个list
print(my_list[0])#结果:[1,2,3]
#获取内层第一个list的第一个元素
print(my_list[0][0])#结果:1
下标索引的注意事项:
要注意下标索引的取值范围,超出范围无法取出元素,并且会报错
1.3列表的常用操作(方法)
列表除了可以:
定义
使用下标索引获取值
以外,列表也提供了一系列功能:
插入元素
删除元素
清空列表
修改元素
统计元素个数
等等功能,这些功能我们都称之为:列表的方法
1.3.1列表的查询功能(方法)
1.查找某元素的下标
功能:查找指定元素在列表的下标,如果找不到,报错ValueError
语法:列表.index(元素)
index就是列表对象(变量)内置的方法(函数)
name_list=['斯蒂芬库里','保罗乔治','勒布朗詹姆斯']
print(name_list.index("保罗乔治"))#结果:1
2.修改特定位置(索引)的元素值:
语法:列表[下标] = 值
可以使用如上语法,直接对指定下标(正向、反向下标均可)的值进行:重新赋值(修改)
#正向下标
my_list=[1,2,3]
my_list[0]=5
print(my_list)#结果:[5,2,3]
#反向下标
my_list=[1,2,3]
my_list[-3]=5
print(my_list)#结果:[5,2,3]
3.插入元素:
语法:列表.insert(下标, 元素),在指定的下标位置,插入指定的元素
name_list=['斯蒂芬库里','保罗乔治','勒布朗詹姆斯']
name_list.insert(1,"凯文杜兰特")
print(name_list) #结果:['斯蒂芬库里','凯文杜兰特','保罗乔治','勒布朗詹姆斯']
4.追加元素:
语法:列表.append(元素),将指定元素,追加到列表的尾部
my_list=[1,2,3]
my_list.append(4)
print(my_list) #结果:[1,2,3,4]
my_list=[1,2,3]
my_list.append([4,5,6])
print(my_list) #结果:[1,2,3,[4,5,6]
追加元素方式2:
语法:列表.extend(其它数据容器),将其它数据容器的内容取出,依次追加到列表尾部
my_list=[1,2,3]
my_list.extend([4,5,6])
print(my_list)#结果:[1,2,3,4,5,6]
列表方法总结
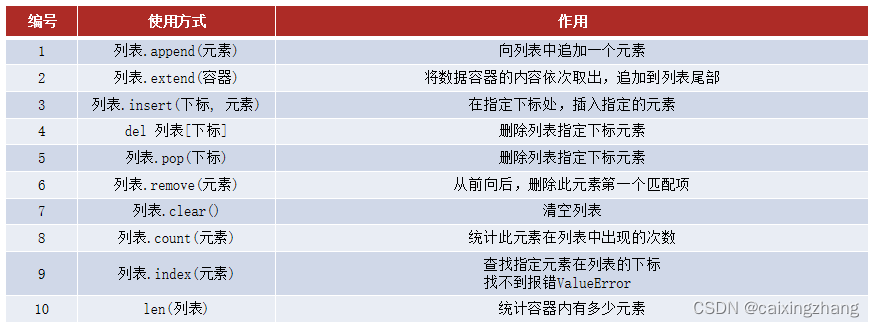
列表的特点:
可以容纳多个元素(上限为2**63-1、9223372036854775807个)
可以容纳不同类型的元素(混装)
数据是有序存储的(有下标序号)
允许重复数据存在
可以修改(增加或删除元素等)
2.list(列表)的遍历
2.1列表的遍历 - while循环
既然数据容器可以存储多个元素,那么,就会有需求从容器内依次取出元素进行操作。
将容器内的元素依次取出进行处理的行为,称之为:遍历、迭代。
语法:

deflist_while_func():
"""
使用while循环遍历列表的演示函数
:return:None
"""
my_list=["斯蒂芬库里","保罗乔治","勒布朗詹姆斯"]
#循环控制变量通过下标索引来控制,默认0
#每一次循环将下标索引变量+1
#循环条件:下标索引变量<列表的元素数量
#定义一个变量用来标记列表的下标
index=0#初始值为0
whileindex<len(my_list):
#通过index变量取出对应下标的元素
element=my_list[index]
print(f"列表的元素:{element}")
#循环变量(index)每一次循环都+1
index+=1
#函数调用
list_while_func()
2.2列表的遍历 - for循环
除了while循环外,Python中还有另外一种循环形式:for循环。
对比while,for循环更加适合对列表等数据容器进行遍历。
语法:

每一次循环将列表中的元素取出,赋值到变量i,供操作
表示,从容器内,依次取出元素并赋值到临时变量上。
在每一次的循环中,我们可以对临时变量(元素)进行处理。
deflist_for_func():
"""
使用for循环遍历列表的演示函数
:return:None
"""
my_list=[1,2,3,4,5]
#for临时变量in数据容器:
forelementinmy_list:
print(f"列表的元素有:{element}")
#函数调用
list_for_func()
2.3while循环和for循环的对比
while循环和for循环,都是循环语句,但细节不同:
在循环控制上:
while循环可以自定循环条件,并自行控制
for循环不可以自定循环条件,只可以一个个从容器内取出数据
在无限循环上:
while循环可以通过条件控制做到无限循环
for循环理论上不可以,因为被遍历的容器容量不是无限的
在使用场景上:
while循环适用于任何想要循环的场景
for循环适用于,遍历数据容器的场景或简单的固定次数循环场景
3.tuple(元组)
3.1元组定义:定义元组使用小括号,且使用逗号隔开各个数据,数据可以是不同的数据类型。

元组一旦定义完成,就不可修改
元组也支持嵌套:

注意事项:

注意:元组只有一个数据,这个数据后面要添加逗号
3.2元组的相关操作
| 编号 | 方法 | 作用 |
| 1 | index() | 查找某个数据,如果数据存在返回对应的下标,否则报错 |
| 2 | count() | 统计某个数据在当前元组出现的次数 |
| 3 | len(元组) | 统计元组内的元素个数 |
#根据下标(索引)取出数据
t1=(1,2,'hello')
print(t1[2])#结果:'hello'
#根据index(),查找特定元素的第一个匹配项
t1=(1,2,'hello',3,4,'hello')
print(t1.count('hello'))#结果:2
#统计元组内的元素个数
t1=(1,2,3)
print(len(t1))#结果:3元组的相关操作 - 注意事项
不可以修改元组的内容,否则会直接报错

可以修改元组内的list的内容(修改元素、增加、删除、反转等)
#尝试修改元组内容
t1=(1,2,['斯蒂芬库里','保罗乔治'])
t1[2][1]='凯文杜兰特'
print(t1)#结果:(1,2,['斯蒂芬库里','凯文杜兰特'])
不可以替换list为其它list或其它类型

3.元组的遍历
同列表一样,元组也可以被遍历。
可以使用while循环和for循环遍历它
#while循环遍历元组
my_tuple=(1,2,3,4,5)
index=0
while index<len(my_tuple):
print(my_tuple[index])
index+=1
#for循环遍历元组
my_tuple=(1,2,3,4,5)
foriinmy_tuple:
print(i)
元组的特点
可以容纳多个数据
可以容纳不同类型的数据(混装)
数据是有序存储的(下标索引)
允许重复数据存在
不可以修改(增加或删除元素等)
支持for循环
多数特性和list一致,不同点在于不可修改的特性。
4.str(字符串)
4.1字符串是字符的容器,一个字符串可以存放任意数量的字符。
如,字符串:"itheima"

4.2字符串的下标(索引)
和其它容器如:列表、元组一样,字符串也可以通过下标进行访问
从前向后,下标从0开始
从后向前,下标从-1开始
#通过下标获取特定位置字符
name="abcdef"
print(name[0])#结果:a
print(name[-1])#结果:f
同元组一样,字符串是一个:无法修改的数据容器。
所以:
修改指定下标的字符 (如:字符串[0] = “a”)
移除特定下标的字符 (如:del 字符串[0]、字符串.remove()、字符串.pop()等)
追加字符等 (如:字符串.append())
均无法完成。如果必须要做,只能得到一个新的字符串,旧的字符串是无法修改
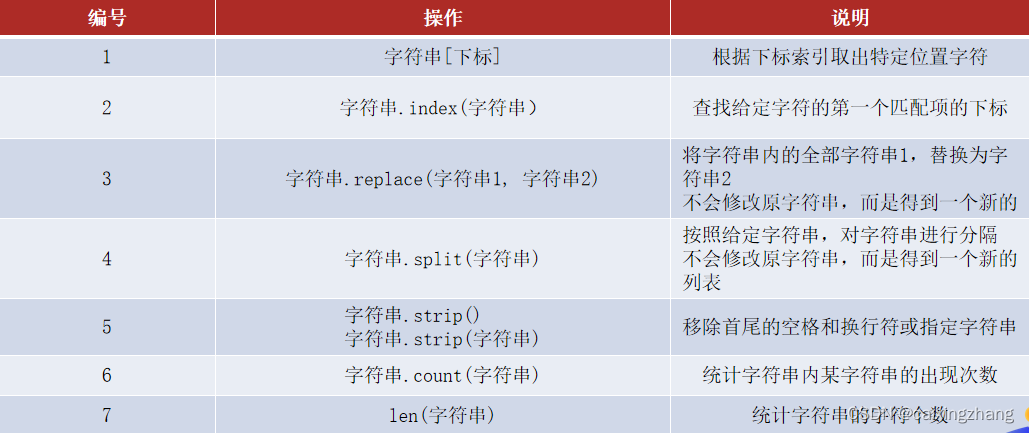
4.3字符串的常用操作
查找特定字符串的下标索引值
语法:字符串.index(字符串)
my_str="Decemberneedsamiracle"
print(my_str.index("needs"))#结果9
字符串的替换
语法:字符串.replace(字符串1,字符串2)
功能:将字符串内的全部:字符串1,替换为字符串2
注意:不是修改字符串本身,而是得到了一个新字符串哦
name="Decemberneedsamiracle"
new_name=name.replace("December","November")
print(new_name) #结果:Novemberneedsamiracle
print(name) #结果:Decemberneedsamiracle字符串name本身并没有发生变化,而是得到了一个新字符串对象
字符串的分割
语法:字符串.split(分隔符字符串)
功能:按照指定的分隔符字符串,将字符串划分为多个字符串,并存入列表对象中
注意:字符串本身不变,而是得到了一个列表对象
name="斯蒂芬库里保罗乔治勒布朗詹姆斯凯文杜兰特"
name_list=name.split("")
print(name_list)#结果:['斯蒂芬库里','保罗乔治','勒布朗詹姆斯','凯文杜兰特']
print(type(name_list))#结果:<class'list'>
字符串按照给定的 <空格>进行了分割,变成多个子字符串,并存入一个列表对象中。
字符串的规整操作(去前后空格)
语法:字符串.strip()
my_str="Decemberneedsamiracle"
print(my_str.strip())#结果:Decemberneedsamiracle
字符串的规整操作(去前后指定字符串)
语法:字符串.strip(字符串)
my_str="12Decemberneedsamiracle21"
print(my_str.strip("12"))#结果:Decemberneedsamiracle
注意,传入的是“12” 其实就是:”1”和”2”都会移除,是按照单个字符。
统计字符串中某字符串的出现次数
语法:字符串.count(字符串)
my_str="Decemberneedsamiracle"
print(my_str.count("e"))#结果:6
统计字符串的长度
语法:len(字符串)
my_str="123abcd!@#$我是张艺兴"
print(len(my_str))#结果:19
数字(1、2、3...)
字母(abcd、ABCD等)
符号(空格、!、@、#、$等)
中文
均算作1个字符
所以上述代码,结果20
4.4字符串的遍历
同列表、元组一样,字符串也支持while循环和for循环进行遍历
4.5字符串的特点
作为数据容器,字符串有如下特点:
只可以存储字符串
长度任意(取决于内存大小)
支持下标索引
允许重复字符串存在
不可以修改(增加或删除元素等)
支持for循环
基本和列表、元组相同
不同与列表和元组的在于:字符串容器可以容纳的类型是单一的,只能是字符串类型。
不同于列表,相同于元组的在于:字符串不可修改
练习:
my_str="Decemberneedsamiracle"
#统计字符串内有多少个"e"字符
num=my_str.count("e")
print(f"字符串{my_str}中有{num}个字符")
#将字符串内的空格,全部替换为字符:"/"
new_my_str=my_str.replace("","|")
print(f"字符串{my_str}被替换空格后,结果是:{new_my_str}")
#并按照"|"进行字符串分割,得到列表
my_str_list=new_my_str.split("|")
print(f"字符串{new_my_str}按照|分割后结果是:{my_str_list}")
5.(序列)的切片
5.1序列
序列是指:内容连续、有序,可使用下标索引的一类数据容器
列表、元组、字符串,均可以可以视为序列。
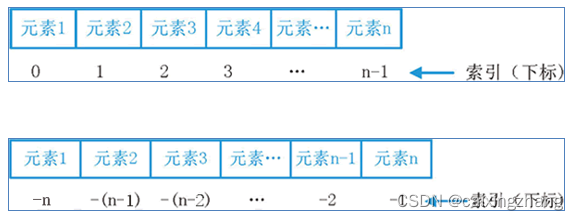
序列的典型特征就是:有序并可用下标索引,字符串、元组、列表均满足这个要求
5.2序列的常用操作 - 切片
序列支持切片,即:列表、元组、字符串,均支持进行切片操作
切片:从一个序列中,取出一个子序列
语法:序列[起始下标:结束下标:步长]
表示从序列中,从指定位置开始,依次取出元素,到指定位置结束,得到一个新序列:
起始下标表示从何处开始,可以留空,留空视作从头开始
结束下标(不含)表示何处结束,可以留空,留空视作截取到结尾
步长表示,依次取元素的间隔
步长1表示,一个个取元素
步长2表示,每次跳过1个元素取
步长N表示,每次跳过N-1个元素取
步长为负数表示,反向取(注意,起始下标和结束下标也要反向标记)
注意,此操作不会影响序列本身,而是会得到一个新的序列(列表、元组、字符串)
切片演示:
my_list=[1,2,3,4,5]
new_list=my_list[1:4]#下标1开始,下标4(不含)结束,步长1
print(new_list)#结果:[2,3,4]
my_tuple=(1,2,3,4,5)
new_tuple=my_tuple[:]#从头开始,到最后结束,步长1
print(new_tuple)#结果:(1,2,3,4,5)
my_list=[1,2,3,4,5]
new_list=my_list[::2]#从头开始,到最后结束,步长2
print(new_list)#结果:[1,3,5]
my_str="12345"
new_str=my_str[:4:2]#从头开始,到下标4(不含)结束,步长2
print(new_str)#结果:"13"
my_str="12345"
new_str=my_str[::-1]#从头(最后)开始,到尾结束,步长-1(倒序)
print(new_str)#结果:"54321"
my_list=[1,2,3,4,5]
new_list=my_list[3:1:-1]#从下标3开始,到下标1(不含)结束,步长-1(倒序)
print(new_list)#结果:[4,3]
my_tuple=(1,2,3,4,5)
new_tuple=my_tuple[:1:-2]#从头(最后)开始,到下标1(不含)结束,步长-2(倒序)
print(new_tuple)#结果:(5,3)
可以看到,这个操作对列表、元组、字符串是通用的
同时非常灵活,根据需求,起始位置,结束位置,步长(正反序)都是可以自行控制的
6.set(集合)
集合,最主要的特点就是:不支持元素的重复(自带去重功能)、并且内容无序
6.1基本语法:

names={"斯蒂芬库里","克莱汤普森","追梦格林","保罗乔治","斯蒂芬库里","凯文杜兰特"}
print(names) #结果:{'追梦格林','保罗乔治','克莱汤普森','斯蒂芬库里','凯文杜兰特'}
结果中可见:去重且无序,因为要对元素做去重处理,所以无法保证顺序和创建的时候一致
6.2集合的常用操作 - 修改
首先,因为集合是无序的,所以集合不支持:下标索引访问
但是集合和列表一样,是允许修改的,所以我们来看看集合的修改方法。
添加新元素
语法:集合.add(元素)。将指定元素,添加到集合内
结果:集合本身被修改,添加了新元素
my_set={"斯蒂芬库里","保罗乔治"}
my_set.add("凯文杜兰特")
print(my_set)#结果{'斯蒂芬库里','凯文杜兰特','保罗乔治'}
移除元素
语法:集合.remove(元素),将指定元素,从集合内移除
结果:集合本身被修改,移除了元素
my_set={'斯蒂芬库里','凯文杜兰特','保罗乔治'}
my_set.remove("凯文杜兰特")
print(my_set)#结果{'保罗乔治','斯蒂芬库里'}
从集合中随机取出元素
语法:集合.pop(),功能,从集合中随机取出一个元素
结果:会得到一个元素的结果。同时集合本身被修改,元素被移除
#pop(),从集合中随机取走一个元素,同时集合本身的这个元素会去掉
my_set={'斯蒂芬库里','凯文杜兰特','保罗乔治'}
element=my_set.pop()
print(my_set)#结果{'保罗乔治','斯蒂芬库里'}
print(element)#结果凯文杜兰特
清空集合
语法:集合.clear(),功能,清空集合
结果:集合本身被清空
my_set={'斯蒂芬库里','凯文杜兰特','保罗乔治'}
my_set.clear()
print(my_set)#结果set()空集合
取出2个集合的差集
语法:集合1.difference(集合2),功能:取出集合1和集合2的差集(集合1有而集合2没有的)
结果:得到一个新集合,集合1和集合2不变
set1={1,2,3}
set2={1,5,6}
set3=set1.difference(set2)
print(set3)#结果:{2.3}得到新的集合
print(set1)#结果:{1,2,3}不变
print(set2)#结果:{1,5,6}不变
消除2个集合的差集
语法:集合1.difference_update(集合2)
功能:对比集合1和集合2,在集合1内,删除和集合2相同的元素。
结果:集合1被修改,集合2不变
set1={1,2,3}
set2={1,5,6}
set1.difference_update(set2)
print(set1)#结果:{2,3}
print(set2)#结果:{1,5,6}不变
2个集合合并
语法:集合1.union(集合2)
功能:将集合1和集合2组合成新集合
结果:得到新集合,集合1和集合2不变
set1={1,2,3}
set2={1,5,6}
set3=set1.union(set2)
print(set3)#结果:{1,2,3,5,6},新集合
print(set1)#结果:{1,2,3},set1不变
print(set2)#结果:{1,5,6}set2不变
查看集合的元素数量
语法:len(集合)
功能:统计集合内有多少元素
结果:得到一个整数结果
set1={1,2,3}
print(len(set1)) # 结果3
6.3集合的常用操作 - for循环遍历
集合同样支持使用for循环遍历
set1={1,2,3}
foriinset1:
print(i)
#结果
1
2
3
要注意:集合不支持下标索引,所以也就不支持使用while循环。
6.4集合常用功能总结

6.5集合的特点
经过上述对集合的学习,可以总结出集合有如下特点:
可以容纳多个数据
可以容纳不同类型的数据(混装)
数据是无序存储的(不支持下标索引)
不允许重复数据存在
可以修改(增加或删除元素等)
支持for循环
7.dict(字典、映射)
7.1字典的定义
字典的定义,同样使用{},不过存储的元素是一个个的:键值对,如下语法:

使用{}存储原始,每一个元素是一个键值对
每一个键值对包含Key和Value(用冒号分隔)
键值对之间使用逗号分隔
Key和Value可以是任意类型的数据(key不可为字典)
Key不可重复,重复会对原有数据覆盖
字典同集合一样,不可以使用下标索引
但是字典可以通过Key值来取得对应的Value
#语法,字典[Key]可以渠道对应的Value
stu_score={"斯蒂芬库里":34,"保罗乔治":32,"勒布朗詹姆斯":38}
print(stu_score["斯蒂芬库里"])#结果:34
print(stu_score["保罗乔治"])#结果:32
print(stu_score["勒布朗詹姆斯"])#结果:38
字典的Key和Value可以是任意数据类型(Key不可为字典)
那么,就表明,字典是可以嵌套的
需求如下:记录学生各科的考试信息
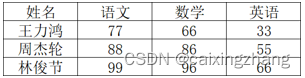
代码:
stu_score={"王力鸿":{"语文":77,"数学":66,"英语":33},"周杰轮":{"语文":88,"数学":86,"英语":55},"林俊节":{"语文":99,"数学":96,"英语":66}}
优化一下可读性,可以写成:
stu_score={
"王力鸿":{"语文":77,"数学":66,"英语":33},
"周杰轮":{"语文":88,"数学":86,"英语":55},
"林俊节":{"语文":99,"数学":96,"英语":66}
}
嵌套字典的内容获取,如下所示:
stu_score={
"王力鸿":{"语文":77,"数学":66,"英语":33},
"周杰轮":{"语文":88,"数学":86,"英语":55},
"林俊节":{"语文":99,"数学":96,"英语":66}
}
print(stu_score["王力鸿"])#结果:{'语文':77,'数学':66,'英语':33}
print(stu_score["王力鸿"]["语文"])#结果:77
print(stu_score["周杰轮"]["数学"])#结果:86
7.2字典的常用操作
新增元素
语法:字典[Key] = Value,结果:字典被修改,新增了元素
stu_score={
"王力鸿":77,
"周杰轮":88,
"林俊节":99
}
#新增:张学油的考试成绩
stu_score['张学油']=66
print(stu_score)#结果:{'王力鸿':77,'周杰轮':88,'林俊节':99,'张学油':66}
更新元素
语法:字典[Key] = Value,结果:字典被修改,元素被更新
注意:字典Key不可以重复,所以对已存在的Key执行上述操作,就是更新Value值
stu_score={
"王力鸿":77,
"周杰轮":88,
"林俊节":99
}
#更新:王力鸿的考试成绩
stu_score['王力鸿']=100
print(stu_score)#{'王力鸿':100,'周杰轮':88,'林俊节':99}
删除元素
语法:字典.pop(Key),结果:获得指定Key的Value,同时字典被修改,指定Key的数据被删除
stu_score={
"王力鸿":77,
"周杰轮":88,
"林俊节":99
}
value=stu_score.pop("王力鸿")
print(value)#结果:77
print(stu_score)#{'周杰轮':88,'林俊节':99}
清空字典
语法:字典.clear(),结果:字典被修改,元素被清空
stu_score={
"王力鸿":77,
"周杰轮":88,
"林俊节":99
}
stu_score.clear()
print(stu_score)#{}
获取全部的key
语法:字典.keys(),结果:得到字典中的全部Key
stu_score={
"王力鸿":77,
"周杰轮":88,
"林俊节":99
}
keys=stu_score.keys()
print(keys)#结果:dict_keys(['王力鸿','周杰轮','林俊节'])
遍历字典
语法:for key in 字典.keys()
stu_score={
"王力鸿":77,
"周杰轮":88,
"林俊节":99
}
keys=stu_score.keys()
forkeyinkeys:
print(f"学生:{key},分数:{stu_score[key]}")
#结果:学生:王力鸿,分数:77
#学生:周杰轮,分数:88
#学生:林俊节,分数:99
注意:字典不支持下标索引,所以同样不可以用while循环遍历
计算字典内的全部元素(键值对)数量
语法:len(字典)
结果:得到一个整数,表示字典内元素(键值对)的数量
stu_score={
"王力鸿":77,
"周杰轮":88,
"林俊节":99
}
print(len(stu_score))#结果:3
7.3字典的常用操作总结:

字典的特点
经过上述对字典的学习,可以总结出字典有如下特点:
可以容纳多个数据
可以容纳不同类型的数据
每一份数据是KeyValue键值对
可以通过Key获取到Value,Key不可重复(重复会覆盖)
不支持下标索引
可以修改(增加或删除更新元素等)
支持for循环,不支持while循环
二、数据容器对比总结
1.数据容器分类
数据容器可以从以下视角进行简单的分类:
是否支持下标索引
支持:列表、元组、字符串 - 序列类型
不支持:集合、字典 - 非序列类型
是否支持重复元素:
支持:列表、元组、字符串 - 序列类型
不支持:集合、字典 - 非序列类型
是否可以修改
支持:列表、集合、字典
不支持:元组、字符串
2.数据容器特点对比
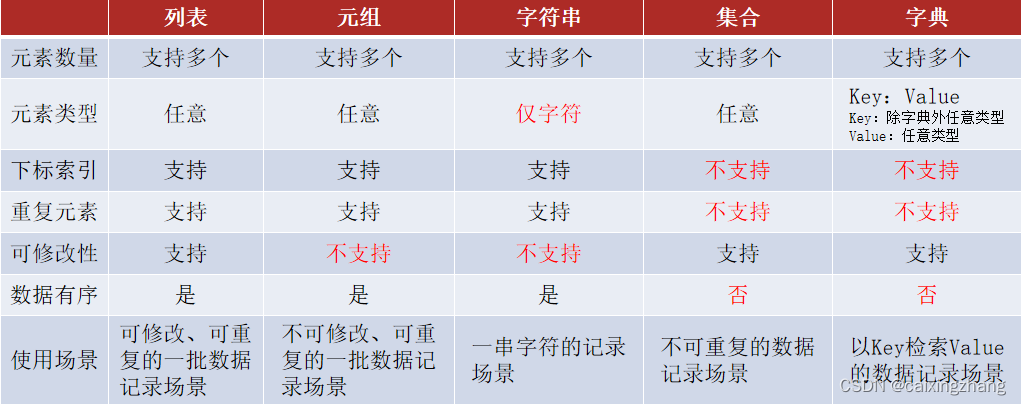
基于各类数据容器的特点,它们的应用场景如下:
列表:一批数据,可修改、可重复的存储场景
元组:一批数据,不可修改、可重复的存储场景
字符串:一串字符串的存储场景
集合:一批数据,去重存储场景
字典:一批数据,可用Key检索Value的存储场景
三、数据容器的通用操作
1.数据容器的通用操作 - 遍历
数据容器尽管各自有各自的特点,但是它们也有通用的一些操作。
首先,在遍历上:
5类数据容器都支持for循环遍历
列表、元组、字符串支持while循环,集合、字典不支持(无法下标索引)
尽管遍历的形式各有不同,但是,它们都支持遍历操作。
2.容器通用功能总览

四、字符串大小比较
在程序中,字符串所用的所有字符如:
大小写英文单词
数字
特殊符号(!、\、|、@、#、空格等)
都有其对应的ASCII码表值
每一个字符都能对应上一个:数字的码值
字符串进行比较就是基于数字的码值大小进行比较的。

字符串比较
字符串是按位比较,也就是一位位进行对比,只要有一位大,那么整体就大。
1. 字符串如何比较
从头到尾,一位位进行比较,其中一位大,后面就无需比较了。
2. 单个字符之间如何确定大小?
通过ASCII码表,确定字符对应的码值数字来确定大小















 603
603











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









