










一、题目描述
给定一个二叉搜索树, 找到该树中两个指定节点的最近公共祖先。
百度百科中最近公共祖先的定义为:“对于有根树 T 的两个结点 p、q,最近公共祖先表示为一个结点 x,满足 x 是 p、q 的祖先且 x 的深度尽可能大(一个节点也可以是它自己的祖先)。”
例如,给定如下二叉搜索树: root = [6,2,8,0,4,7,9,null,null,3,5]
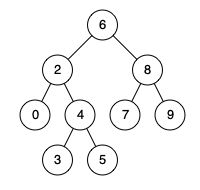
示例 1:
输入: root = [6,2,8,0,4,7,9,null,null,3,5], p = 2, q = 8 输出: 6 解释: 节点2和节点8的最近公共祖先是6。
示例 2:
输入: root = [6,2,8,0,4,7,9,null,null,3,5], p = 2, q = 4 输出: 2 解释: 节点2和节点4的最近公共祖先是2, 因为根据定义最近公共祖先节点可以为节点本身。
说明:
- 所有节点的值都是唯一的。
- p、q 为不同节点且均存在于给定的二叉搜索树中。
二、解题思路
- 利用二叉搜索树的性质:左子树节点的值小于根节点的值,右子树节点的值大于根节点的值。
- 从根节点开始遍历树:
- 如果当前节点的值大于 p 和 q 的值,说明 p 和 q 都在当前节点的左子树中,因此将当前节点移动到其左子节点。
- 如果当前节点的值小于 p 和 q 的值,说明 p 和 q 都在当前节点的右子树中,因此将当前节点移动到其右子节点。
- 如果当前节点的值在 p 和 q 的值之间(包括等于 p 或 q 的情况),那么当前节点就是 p 和 q 的最近公共祖先。
三、具体代码
class Solution {
public TreeNode lowestCommonAncestor(TreeNode root, TreeNode p, TreeNode q) {
// 确保 p 的值小于等于 q 的值,方便后续处理
if (p.val > q.val) {
return lowestCommonAncestor(root, q, p);
}
// 遍历二叉搜索树
while (root != null) {
// 如果当前节点的值大于 p 和 q 的值,向左子树移动
if (root.val > p.val && root.val > q.val) {
root = root.left;
}
// 如果当前节点的值小于 p 和 q 的值,向右子树移动
else if (root.val < p.val && root.val < q.val) {
root = root.right;
}
// 如果当前节点的值在 p 和 q 的值之间,则找到了最近公共祖先
else {
return root;
}
}
return null; // 如果 p 和 q 不存在,返回 null,但根据题目描述这种情况不会发生
}
}
以上代码实现中,我们假设 TreeNode 类已经定义,并且 root, p, q 都是 TreeNode 类型的实例。在代码中,我们首先确保 p 的值小于等于 q 的值,这样我们可以简化逻辑处理。然后我们遍历树,根据二叉搜索树的性质找到最近公共祖先。
四、时间复杂度和空间复杂度
1. 时间复杂度
-
代码中首先有一个判断
if (p.val > q.val),这是一个常数时间操作,时间复杂度为 O(1)。 -
然后是一个
while循环,该循环会在二叉搜索树中进行遍历。在每次循环中,我们都会将当前节点移动到其左子节点或右子节点。由于二叉搜索树的特性,每次移动都会使得当前节点的值更接近 p 和 q 的值,因此我们最多只会遍历树的高度次。 -
在最坏的情况下,树是完全不平衡的(即退化成一条链表),树的高度为 n(n 是树中节点的数量)。在这种情况下,我们需要遍历 n 次,时间复杂度为 O(n)。
-
在平均情况下,二叉搜索树是平衡的,树的高度大约是 log(n)。因此,平均时间复杂度是 O(log(n))。
综上所述,该算法的时间复杂度是 O(h),其中 h 是树的高度。在平均情况下,它接近于 O(log(n))。
2. 空间复杂度
-
代码中没有使用额外的数据结构来存储信息,除了几个变量来存储当前节点、p 和 q 的值。
-
递归调用栈的深度最多为树的高度 h。在最坏的情况下(树不平衡),空间复杂度为 O(n),在平均情况下(树平衡),空间复杂度为 O(log(n))。
-
由于我们没有使用递归,而是使用了迭代的方法,因此空间复杂度只取决于我们使用的变量数量,而不是递归调用栈的深度。
综上所述,该算法的空间复杂度是 O(1),因为我们只使用了常数额外空间。
五、总结知识点
-
二叉搜索树(Binary Search Tree, BST)的性质:
- 二叉搜索树是一种特殊的二叉树,其中每个节点的值都大于其左子树中的所有节点的值,并且小于其右子树中的所有节点的值。
-
递归(Recursion):
- 在代码中,虽然主体逻辑使用的是迭代而非递归,但在
if (p.val > q.val)的判断中,使用了递归调用来确保p的值小于等于q的值。递归是一种常见的算法技巧,它允许函数调用自身。
- 在代码中,虽然主体逻辑使用的是迭代而非递归,但在
-
迭代(Iteration):
- 代码主要使用了一个
while循环来实现迭代遍历二叉搜索树,而不是使用递归方法。
- 代码主要使用了一个
-
条件语句(Conditional Statements):
- 代码中使用了
if-else语句来判断当前节点的值与p和q的值的关系,并根据条件进行不同的操作。
- 代码中使用了
-
指针或引用操作(Pointer/Reference Manipulation):
- 在
while循环中,代码通过改变root的引用来移动到树的左子节点或右子节点,这是对指针或引用的直接操作。
- 在
-
函数返回值(Function Return Values):
- 代码中的
return语句用于结束函数执行并返回一个值。这里,函数返回TreeNode类型,表示最近公共祖先节点。
- 代码中的
-
二叉树节点定义(Binary Tree Node Definition):
- 代码假设存在一个
TreeNode类,它定义了二叉树节点的结构,包括节点值val、左子节点left和右子节点right。
- 代码假设存在一个
-
边界条件处理(Edge Case Handling):
- 在
while循环结束后,返回null是对边界条件的处理,尽管根据题目描述,p和q总是存在于树中,因此实际上不会执行到这一行代码。
- 在
以上就是解决这个问题的详细步骤,希望能够为各位提供启发和帮助。

















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











