






在数据库的建模过程中,数据冗余经常会导致数据库发生一下问题
- 冗余存储:信息被重复存储,导致大量浪费了存储空间
- 更新异常:当重复信息的一个副本被修改,所有副本都必须进行同样的修改。因此当更新数据时,系统要付出很大的代价来维护数据库的完整性,否则会面临数据不一致带来的风险
- 插入异常:只有当一些信息事先已经存放在数据库中时,另外一些数据才能存入数据库中。(如当一个班级要创建,但是班级的学生没有确定,班级的信息就无法导入表中)
- 删除异常:删除某些信息时可能丢失其他数据。(当整个班的学生全部删除掉,班级信息也同时被删除掉)
一般在解决上述问题,是将其中的属性依赖关系确定好,将属性依赖关系,分别分解到每个单独的关系模式中,这样通过分解一个较大的关系模式来消除其中不适合的数据依赖,以解决数据冗余及其带来的各种问题。但是模式分解同样会带来问题
模式分解导致的问题
- 什么样的关系模型需要进一步的分解为较小的关系模型集
- 是否所有模式分解都是有益的
- 分解之后会不会导致数据丢失
- 分解之后原来存在的属性依赖还存不存在
所以一个好的关系模型,应该是数据冗余应尽可能的少,且不会发生插入异常,删除异常和更新异常等问题,而且,当减少冗余进行模式分解时,应该考虑分解后的模式是否具有无损连接,保持依赖等特性的。
那么在说范式之前,我先大概讲一下依赖(函数依赖)的定义
函数依赖的定义
函数依赖是一种完整性约束,是现实世界事物属性之间的一种制约关系。
1.函数依赖
设r(R)为关系模式,α属于R,β属于R。对任意合法关系中r及其他任两个元组ti和tj,i不等于j,若ti【α】 = tj【α】,则ti【β】 = tj【β】,那么称α函数确定β,或β函数依赖于α,记作α ->β
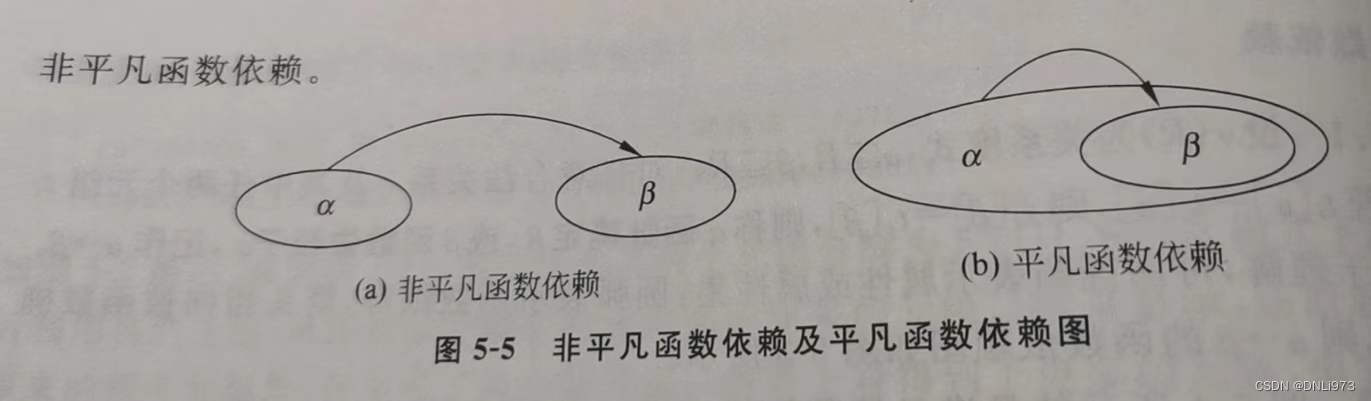
2.平凡与非平凡函数
在关系模式中了r(R)中,α属于R,β属于R。若α ->β,当β不属于α ,则称α ->β是非平凡函数依赖。否则,若β属于α ,则称α ->β为平凡函数依赖
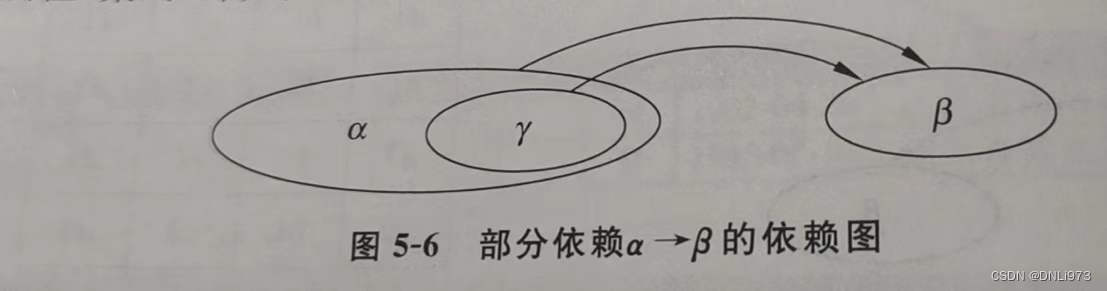
3.完全函数依赖和非完全函数依赖
在关系模式中了r(R)中,α属于R,β属于R。α ->β,是非平凡函数依赖。若对任意的α包含 γ,γ->β都不成立,则称α ->β是完全函数依赖,否则,若存在非空的α包含 γ,使γ ->β则称为α ->β是部分函数依赖。
4.传递函数依赖
在关系模式中了r(R)中,α属于R,β属于R,γ属于R。若α ->β,β->γ,则必存在α ->γ,若α ->β,β->γ和α->γ都是非平凡函数依赖,且β ->α不成立,则称为α ->γ是传递函数依赖。
传递函数依赖和部分依赖可能会导致数据冗余及产生各种异常,在模型分解过程中要避免这种依赖出现

范式
范式一共分为三种:第一范式(1NF),第二范式(2NF),第三范式(3NF),他们之间的所属关系是: 1NF包含2NF包含3NF包含
第一范式(1NF)——码:
如果一关系模式r(R)的每一个属性对应的值域都是不可分的,则称R属于第一范式
第一范式的目标是:将基本数据划分成称为实体集或表的逻辑单元,当设计好每一个实体否,需要指定主码,关系模型至少是第一范式
在我的理解中,第一范式要保证,实体集中的属性都是简单属性不可再次分割。

第二范式(2NF)——全部是码:
设有一个关系模式r(R),α属于R。若α包含在R的某个候选码中,则称α为主属性,否则α为非主属性
如果一个关系模式r(R),R属于第一范式,且所有非主属性都完全函数依赖于R的候选码,则称R属于第二范式。
也就是说对于满足第一范式的关系模型,如果有复合候选码,那么非主属性不允许依赖于部分候选码,必须依赖于全部候选码属性。
第二范式的目标是:将只是部分依赖于候选码的非主属性通过关系模式分解移到其他表中
第三范式(3NF)——仅仅是码:
如果一个关系模式 r(R属于第二范式,且所有非主属性都直接函数依赖于R的候选码(即不存在非主属性传递依赖于候选码),则称为R为第三范式
也就是说,对于满足第二范式的关系模型,非主属性不能依赖于另一个(组)非主属性(这样就形成了对候选码的传递依赖),即非主属性只能直接依赖于候选码
第三范式的目标是:将不直接依赖于候选码的非主属性通过关系模型分解转移到其他表中















 810
810











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









