







集合
概述
- 集合框架的接口和类在java.util包中
- 数组元素的个数是固定的,要实现动态数组比较麻烦
- 三大接口:Collection、Map、Iterator

Collection
public interface Collection<E>
extends iterable<E>
List
- 有序的collection(序列),此接口的用户可以对列表中每个元素的插入位置进行精确的控制,用户可以根据元素的整数索引(在列表中的位置)访问元素,并搜索列表中的元素。允许多个null元素,元素可重复
public interface List<E> extends Collection<E>
- 具体实现类 ArrayList、Vector、LinkedList
- 开发中选择
- 安全性问题 【ArrayList(结合工具类)、Vector】
- 是否频繁插入、删除操作 【LinkedList】
- 是否是存储后遍历 【ArrayList】
ArrayList
public class ArrayList<E> extends AbstractList<E>
implements List<E>,RandomAccess,Cloneable,Serializable
- 基本方法使用
private static void arrayList() {
/*
* 使用集合来存储多个不同类型的元素(对象),那么在处理时会比较麻烦,在实际开发中,
* 不建议这样使用,应该在一个集合中存储相同类型的对象 -> 加泛型
*/
// List list = new ArrayList(); //父类引用指向子类对象
// list.add("李四");
// list.add("王五");
// list.add(10); //自动装箱
List<String> list = new ArrayList<>();
list.add("李四");
list.add("王五");
//遍历集合
int size = list.size(); //局部变量,进栈,访问栈变量比调用方法快
for(int i=0; i<size; i++) {
System.out.println(list.get(i));
}
String[] array = list.toArray(new String[]{});
for(String s:array) {
System.out.println(s);
}
}
- 基本原理
- 采用动态对象数组实现,默认构造方法创建了一个空数组
- 第一次添加元素,扩充容量为10,之后的扩充算法:原来数组大小+原来数组的一半
- 不适合进行删除或插入操作
- 为了防止数组动态扩充次数过多,建议创建ArrayList时,给定初始容量
- 线程不安全,适合单线程访问时使用
Vector
public class Vector<E> extends AbstractList<E>
implements List<E>,RandomAccess,Cloneable,Serializable
- 基本方法使用
private static void vector() {
Vector<String> v = new Vector<>();
v.add("李四");
v.add("王五");
for(int i=0; i<v.size(); i++) {
System.out.println(v.get(i));
}
}
- 实现原理
- 采用动态对象数组实现,默认构造方法创建了一个大小为10的对象数组
- 扩充算法:当增量为0时,扩充为原来大小的两倍,当增量大于0时,扩充为原来大小+增量
- 不适合进行删除或插入操作
- 为了防止数组动态扩充次数过多,建议创建Vector时,给定初始容量
- 线程安全,适合在多线程访问时使用,在单线程下使用效率较低
LinkedList
public class LinkedList<E> extends AbstractSequentialList<E>
implements List<E>,Deque<E>,Cloneable,Serializable
除了实现List的接口外,LinkedList类还为在列表的开头及结尾get、remove、insert元素提供了统一的命名方法
- 基本方法使用
private static void linkedList() {
LinkedList<String> list = new LinkedList<String>();
list.add("李四");
list.add("王五");
for(int i=0; i<list.size(); i++) {
System.out.println(list.get(i));
}
}
- 实现原理
- 采用双向链表结构实现
- 适合插入、删除操作,性能高
set
public interface Set<E> extends Collection<E>
- 不包含重复元素e1.equals(e2)
- 最多包含一个null元素
- 无序
- 如果要排序,选择TreeSet
- 如果不要排序,也不要保证顺序选择HashSet
- 不要排序,要保证顺序选择LinkedHashSet
HashSet
public class HashSet<E> extends AbstractSet<E>
implements Set<E>,Cloneable,Serializable
- 实现原理:基于哈希表(HashMap)实现
- 不允许重复,可以有一个NULL元素 【equals不相等】
- 不保证顺序恒久不变,不保证迭代顺序
- 添加元素时,把元素作为HashMap的key存储,HashMap的value使用一个固定的object对象
- 判断两个对象是否相同,先判断两个对象的HashCode是否相同(如果两个对象的HashCode相同,不一定是同一个对象;如果不同,那一定不是同一个对象),如果不同,则两个对象不是同一个对象;如果相同,还要进行equals判断,equals相同则是同一个对象,不是则不是同一个对象
- 自定义对象要认为属性值都相同时为同一个对象时,要重写对象所在类的hashCode和equals方法
- 哈希表的存储结构:数组+链表(数组里的每个元素以链表的形式存储)
- 如何把对象存储到哈希表中:先计算对象的hashCode值,再对数组的长度求余数,来决定对象要存储在数组中的哪个位置
public class Cat {
private String name;
private int age;
private int id;
public String getName() {
return name;
}
public void setName(String name) {
this.name = name;
}
public int getAge() {
return age;
}
public void setAge(int age) {
this.age = age;
}
public int getId() {
return id;
}
public void setId(int id) {
this.id = id;
}
public Cat(String name, int age, int id) {
super();
this.name = name;
this.age = age;
this.id = id;
}
public Cat() {
super();
}
@Override
public String toString() {
return "Cat [name=" + name + ", age=" + age + ", id=" + id + "]";
}
//重写 不重复
@Override
public int hashCode() {
return Objects.hash(age, id, name);
}
@Override
public boolean equals(Object obj) {
if (this == obj)
return true;
if (obj == null)
return false;
if (getClass() != obj.getClass())
return false;
Cat other = (Cat) obj;
return age == other.age && id == other.id && Objects.equals(name, other.name);
}
}
private static void hashSet() {
Set<String> set = new HashSet<String>();
set.add("张三");
set.add("李四");
set.add("王五");
String[] names = set.toArray(new String[]{});
for(String s:names) {
System.out.println(s);
}
Cat c1 = new Cat("miaomiao",3,1);
Cat c2 = new Cat("tom",3,2);
Cat c3 = new Cat("huahua",2,3);
// Cat c4 = new Cat("miaomiao",3,1);
Set<Cat> cats = new HashSet<>();
cats.add(c1);
cats.add(c2);
cats.add(c3);
// cats.add(c4);
for(Cat c:cats) {
System.out.println(c);
}
System.out.println(cats.size());
System.out.println("c1="+c1.hashCode()%16);
System.out.println("c2="+c2.hashCode()%16);
System.out.println("c3="+c3.hashCode()%16);
// System.out.println("c4="+c4.hashCode()%16);
}
TreeSet
public class TreeSet<E> extends AbstractSet<E>
implements NavigableSet<E>,Cloneable,Serializable
- 基于TreeMap的NavigableSet实现。使用元素的自然顺序对元素进行排序,或者根据创建set时提供的Comparator进行排序,具体取决于使用的构造方法
public class CatComparator implements Comparator<Cat>{
@Override
public int compare(Cat o1, Cat o2) {
return o1.getAge()-o2.getAge();
}
}
/**
* 有序的,基于TreeMap(二叉树数据结构),对象需要比较大小,通过对象比较器来实现,
* 对象比较器还可以去除重复元素,如果自定义的数据类没有实现比较器接口,无法添加到TreeSet集合中
*/
private static void treeSet() {
TreeSet<Cat> tree = new TreeSet<>(new CatComparator());
Cat c1 = new Cat("miaomiao", 3, 1);
Cat c2 = new Cat("tom", 3, 2);
Cat c3 = new Cat("huahua", 2, 3);
Cat c4 = new Cat("miaomiao", 3, 1);
tree.add(c1);
tree.add(c2);
tree.add(c3);
tree.add(c4);
System.out.println(tree.size());
for(Cat c:tree) {
System.out.println(c);
}
}
LinkedHashSet
public class LinkedHashSet<E> extends HashSet<E>
implements Set<E>,Cloneable,Serializable
- 定义了迭代顺序
- 具有可预知迭代顺序的Set接口的哈希表和链接列表实现
private static void linkedHashSet() {
LinkedHashSet<Cat> set = new LinkedHashSet<>();
Cat c1 = new Cat("miaomiao", 3, 1);
Cat c2 = new Cat("tom", 3, 2);
Cat c3 = new Cat("huahua", 2, 3);
Cat c4 = new Cat("miaomiao", 3, 1);
set.add(c1);
set.add(c2);
set.add(c3);
set.add(c4);
for(Cat c:set) {
System.out.println(c);
}
}
Iterator接口(集合输出)
- 集合输出 Iterator、ListIterator、Enumeration、foreach
- Iterator
public interface Iterator<E>
boolean hasNext(); //如果仍有元素可以迭代,则返回true
E next(); //返回迭代的下一个元素
void remove(); //从迭代器指向的collection中移除迭代器返回的最后一个元素
- ListIterator
- 系列表迭代器,允许程序员按任一方向遍历列表,迭代期间修改列表,并获得迭代器在列表中的当前位置
public interface ListIterator<E> extends Iterator<E>
void add(E e); //增加元素
boolean hasPrevious(); //判断是否有前一个元素
E previous(); //取出前一个元素
void set(E e); //修改元素的内容
int previousIndex(); //前一个索引位置
int nextIndex(); //下一个索引位置
- Enumeration
- 优先考虑Iterator;Iterator添加了一个可选的移除操作,并使用较短的方法名
public interface Enumeration<E>
//1.5之后
private static void foreach(Collection<Cat> c) {
for(Cat cat:c) {
System.out.println(cat);
}
}
//1.5之前
private static void iterator(Collection<Cat> c) {
Iterator<Cat> iter = c.iterator();
while(iter.hasNext()) {
System.out.println(iter.next());
}
}
private static void enumration() {
Vector<String> vs = new Vector<>();
vs.add("tom");
vs.add("jack");
vs.add("job");
vs.add("lily");
Enumeration<String> es = vs.elements();
while(es.hasMoreElements()) {
System.out.println(es.nextElement());
}
}
JDK1.8新的迭代方法
迭代接口
- foreach
//JDK1.8新的迭代方法
private static void foreach() {
List<String> list = new ArrayList<>();
list.add("tom");
list.add("jack");
list.add("job");
list.add("lily");
//list.forEach((String s) -> {System.out.println(s);});
//list.forEach(s -> System.out.println(s));
//Consumer<T> 消费者接口
list.forEach(System.out::println); // ::调用方法
}
//::
/**
* 方法引用
* 引用静态方法 Integer::valueOf
* 引用对象的方法 list::add
* 引用构造方法 ArrayList::new
*/
- Function<T,R>接口
- 表示接受一个参数并产生结果的函数
public static void main(String[] args) {
functionTest();
}
private static void functionTest() {
String s = strToUpp("qf_vince",str->str.toUpperCase());
System.out.println(s);
}
//Function<输入,输出>
public static String strToUpp(String str, Function<String,String> f) {
return f.apply(str);
}
- Supplier
//Supplier 代表结果供应商
private static void supplierTest() {
List<Integer> list = getNums(10,()->(int)(Math.random()*100));
list.forEach(System.out::println);
}
private static List<Integer> getNums(int num,Supplier<Integer> sup){
List<Integer> list = new ArrayList<>();
for(int i=0; i<num; i++) {
list.add(sup.get());
}
return list;
}
- Predicate接口
//断言接口
private static void predicate() {
//固定大小集合
List<String> list = Arrays.asList("Larry","Moe","Curly","Tom");
List<String> result = filter(list,(s)->s.contains("o")); //含o的字符串
result.forEach(System.out::println);
}
private static List<String> filter(List<String> list,Predicate<String> p){
List<String> results = new ArrayList<>();
for(String s:list) {
if(p.test(s)) {
results.add(s);
}
}
return results;
}
Stream

public static void main(String[] args) {
Stream<String> stream = Stream.of("good","good","study","day","day","up");
//foreach方法
//stream.forEach((str)->System.out.println(str));
//stream.forEach(System.out::println);
//filter
//stream.filter((s)->s.length()>3).forEach(System.out::println);
//distinct去重
//stream.distinct().forEach(System.out::println);
//map 映射
//stream.map(s->s.toUpperCase()).forEach(s->System.out.println(s));
//flatMap摊平
//Stream<List<Integer>> ss = Stream.of(Arrays.asList(1,2,3),Arrays.asList(4,5));
//ss.flatMap(list->list.stream()).forEach(System.out::println);
//reduce
//Optional<String> opt = stream.reduce((s1,s2) -> s1.length()>=s2.length() ? s1 : s2);
//System.out.println(opt.get()); //找出最长的字符串
//collect
List<String> list = stream.collect(Collectors.toList());
list.forEach(s->System.out.println(s));
}
Map接口
- 将键映射到值的对象,一个映射不能包含重复的键;每个键最多只能映射到一个值
//K key的类型 V value的类型
public interface Map<K,V>
//方法
void clear(); //清空Map集合中的内容
boolean containsKey(Object key); //判断集合中是否存在指定的key
boolean containsValue(Object value); //判断集合中是否存在指定的value
Set<Map.Entry<K,V>> entrySet(); //将Map接口变为Set集合
V get(Object key) //根据key找到其对应的value
- 如何选择选用哪个(存一个对象用Collection,两个用Map)
- HashMap 不要求顺序,单线程
- Hashtable 多线程(少用)
- LinkedHashMap 保证存储顺序
- TreeMap 排序 二叉树
HashMap
public class HashMap<K,V> extends AbstractMap<K,V>
implements Map<K,V>,Cloneable,Serializable
- 基于哈希表的Map接口的实现,允许使用null值和null键,不保证映射的顺序,不保证该顺序恒久不变
/**
* Map接口
* 键值对存储一组对象
* Key不能重复(唯一),Value可以重复
* 具体的实现类:HashMap、TreeMap、Hashtable、LinkedHashMap
*/
private static void hashMap() {
Map<Integer, String> map = new HashMap<>();
map.put(1, "Tom");
map.put(2, "Bin");
map.put(3, "April");
map.put(4, "Lily");
System.out.println("size="+map.size());
//通过key取值
System.out.println(map.get(1));
//map遍历
//①
Set<Entry<Integer,String>> entrySet = map.entrySet();
for(Entry e:entrySet) {
System.out.println(e.getKey()+"->"+e.getValue());
}
//②
Set<Integer> keys = map.keySet();
for(Integer i:keys) {
String value = map.get(i);
System.out.println(i+"->"+value);
}
//③
Collection<String> values = map.values();
for(String value:values) {
System.out.println(value);
}
//④
map.forEach((key,value)->System.out.println(key+"->"+value));
System.out.println(map.containsKey(1));
}
- 实现原理
- 基于哈希表(数组+链表+二叉树(红黑树))1.8
- 默认加载因子(0.75),默认数组大小是16
- 把对象存储到哈希表中
- 把对象存储到哈希表中:把key对象通过hash() 方法计算hash值,然后用这个hash值对数组长度取余数(默认16),来决定该对key对象在数组中的位置,当这个位置有多个对象时,以链表结构存储,JDK1.8后,当链表长度大于8时,链表将转换为红黑树结构存储。这样取值会更快
- 数组扩充原理:当数组的容量超过了75%,表示该数组需要进行扩充。扩充算法:小于最大值的情况:当前数组容量<<1(*2)。扩充次数过多会影响性能,每次扩充表示哈希表重新散列(重新计算每个对象的存储位置),尽量减少扩充次数。
- 线程不安全。适合单线程
Hashtable
public class Hashtable<K,V> extends Dictionary<K,V>
implements Map<K,V>, Cloneable,Serializable
- 实现一个哈希表,该哈希表将键映射到相应的值。任何非null对象都可以用作键或值。用作键的对象必须实现hashCode方法和equals方法
private static void hashtable() {
Map<String,String> table = new Hashtable<>();
table.put("one", "Lily");
table.put("two", "April");
table.put("three", "Bin");
table.forEach((key,value)->System.out.println(key+"->"+value));
}
LinkedHashMap
public class LinkedHashMap<K,V>
extends HashMap<K,V> implements Map<K,V>
- Map接口的哈希表和链接列表的实现,具有可预知的迭代顺序。此实现维护着一个运行于所有条目的双重链接列表
- 是HashMap的子类,由于HashMap不能保证顺序恒久不变,此类使用一个双重链表来维护元素添加的顺序
private static void linkedHashMap() {
Map<String,String> table = new LinkedHashMap<>();
table.put("one", "Lily");
table.put("two", "April");
table.put("three", "Bin");
table.forEach((key,value)->System.out.println(key+"->"+value));
}
TreeMap
public class treeMap<K,V> extends AbstractMap<K,V>
implements NavigableMap<K,V>,Cloneable,Serializable
- 基于红黑树(Red-Black tree)的NavigableMap实现。该映射根据其键的自然顺序进行排序,或者根据创建映射时提供的Comparator进行排序,具体取决于使用的构造方法
private static void treeMap() {
Map<String,String> map = new TreeMap<>();
map.put("one", "Lily");
map.put("two", "April");
map.put("three", "Bin");
map.forEach((key,value)->System.out.println(key+"->"+value));
Map<Dog,String> dogs = new TreeMap<>();
dogs.put(new Dog(1,"2h",3), "dog1");
dogs.put(new Dog(2,"3h",3), "dog2");
dogs.put(new Dog(3,"4h",3), "dog3");
dogs.forEach((key,value)->System.out.println(key+"->"+value));
}
public class Dog implements Comparable<Dog>{
private int id;
private String name;
private int age;
public int getId() {
return id;
}
public void setId(int id) {
this.id = id;
}
public String getName() {
return name;
}
public void setName(String name) {
this.name = name;
}
public int getAge() {
return age;
}
public void setAge(int age) {
this.age = age;
}
@Override
public String toString() {
return "Dog [id=" + id + ", name=" + name + ", age=" + age + "]";
}
public Dog(int id, String name, int age) {
super();
this.id = id;
this.name = name;
this.age = age;
}
public Dog() {
super();
}
@Override
public int compareTo(Dog o) {
return this.id-o.id;
}
}
Map接口1.8新方法
public static void main(String[] args) {
Map<Integer,String> map = new HashMap<>();
map.put(1, "Jack");
map.put(2, "tom");
map.put(3, "lily");
String value = map.getOrDefault(4, "null");
System.out.println(value); //null
String val = map.put(3, "Bom");
System.out.println(val);
map.forEach((k,v)->System.out.println(k+"->"+v)); //key不变,value覆盖
map.putIfAbsent(3, "April"); //只会添加不存在key的值,不会覆盖
map.remove(1, "Jack"); //键和值都匹配时才删除
map.replace(2, "April");
map.replace(2,"April","vince");
map.compute(3, (k,v1)->v1+"1");
map.computeIfAbsent(5, v->v+"test"); //key不存在是添加
map.merge(2, "888", (oldVal,newVal)->oldVal.concat(newVal)); //合并
map.merge(8, "888", (oldVal,newVal)->oldVal.concat(newVal)); //不存在是值是newVal
map.forEach((k,v)->System.out.println(k+"->"+v));
}
Collections工具类
-
Collection工具类提供了大量针对Collection/Map的操作,总体可分为四类,都为静态方法
-
Collection接口Collections类;带s的是工具类,不带s是集合接口
排序操作
reverse(List list); //反转指定List集合中元素的顺序
shuffle(List list); //对List中的元素进行随机排序
sort(List list); //对List中的元素根据自然升序排序
sort(List list,Comparator c); //自定义比较器进行排序
swap(List list,int i, int j); //将指定List集合中i处元素和j处元素进行交换
rotate(List list,int distance); //将所有元素向右移指定长度,如果distance等于size那么结果不变
public static void main(String[] args) {
List<String> list = new ArrayList<>();
list.add("jack");
list.add("tom");
list.add("lily");
System.out.println("-----反序-----");
Collections.reverse(list);
System.out.println(list);
System.out.println("-----随机排序-----");
Collections.shuffle(list);
System.out.println(list);
System.out.println("-----自然升序-----");
Collections.sort(list);
System.out.println(list);
System.out.println("-----交换-----");
Collections.swap(list,1,2);
System.out.println(list);
System.out.println("-----向右移位-----");
Collections.rotate(list,1);
System.out.println(list);
}
/*
-----反序-----
[lily, tom, jack]
-----随机排序-----
[tom, lily, jack]
-----自然升序-----
[jack, lily, tom]
-----交换-----
[jack, tom, lily]
-----向右移位-----
[lily, jack, tom]
*/
查找和替换
binarySearch(List list,Object key); //使用二分搜索法,以获得指定对象在List中的索引,前提是集合已经排序
max(Collection coll); //返回最大元素
max(Collection coll,Comparator comp); //根据自定义比较器,返回最大元素
min(Collection coll); //返回最小元素
min(Collection coll,Comparator comp); //根据自定义比较器,返回最小元素
fill(List list,Object obj); //使用指定对象填充
frequency(Collection coll, Object o); //返回指定集合中指定对象出现的次数
replaceAll(List list,Object old,Object new); //替换
public static void main(String[] args) {
List<String> list = new ArrayList<>();
list.add("jack");
list.add("tom");
list.add("lily");
System.out.println(Collections.binarySearch(list, "tom"));
System.out.println(Collections.max(list));
System.out.println(Collections.min(list));
}
同步控制
- Collections工具类中提供了多个synchronizedXxx方法,该方法返回指定集合对象对应的同步对象,从而解决多线程并发访问集合时线程的安全问题。HashSet、ArrayList、HashMap都是线程不安全的,如果需要考虑同步,则使用这些方法,这些方法主要有:synchronizedSet、synchronizedSortedSet、synchronizedList、synchronizedMap、synchronizedSortedMap
- 在使用迭代方法遍历集合时需要手工同步返回集合
List<String> syncList = Collections.synchronizedList(new ArrayList<String>());
设置不可变集合
emptyXxx() //返回一个空的不可变的集合对象
singletonXxx() //返回一个只包含指定对象的,不可变的集合对象
unmodifiableXxx() //返回指定集合对象的不可变视图
List<String> sList = Collections.emptyList(); //不能添加,用在返回集合,当集合为空时返回Collections.emptyList()
其他
disjoint(Collection<?>c1, Collection<?>c2) //如果两个指定collection中没有相同的元素,则返回true
addAll(Collection<? super T>c, T...a) //将所有指定元素添加到指定collection中
Comparator<T> reverseOrder(Comparator<T> cmp) //返回一个比较器,强行反转指定比较器的顺序。如果指定比较器为null,则此方法等同于reverseOrder() [返回一个比较器,该比较器强行反转实现Comparable接口那些对象collection上的自然顺序]
Optional容器类
- 这是一个可以为null的容器对象。如果值存在则isPresent()方法会返回true,调用get()方法会返回该对象
of //为非null的值创建一个Optional
ofNullable //为指定的值创建一个Optional,如果指定值为null,则返回一个空的Optional
isPresent //如果值存在返回true,不存在返回false
get //如果Optional有值则将其返回,否则抛出NoSuchElementException
ifPresent //如果Optional实例有值则为其调用consumer,否则不做处理
orElse //如果有值则将其返回,否则返回指定的其他值
orElseGet //接受Supplier接口的实现用来生成默认值
orElseThrow //如果有值则将其返回,否则抛出supplier接口创建的异常
map //如果有值,对其执行调用mapping函数得到返回值。返回值不为null则创建包含mapping返回值的Optional作为map方法返回 值,否则返回空Optional
flatmap //如果有值,为其执行mapping函数返回Optional类型返回值,否则返回空Optional。flatMap与map(Function)方法类 似,区别在于flatMap中的mapper返回值必须是Optional。调用结束时,flatMap不会对结果用Optional封装
filter //如果有值并且满足断言条件返回包含该值的Optional,否则返回空的Optional
public static void main(String[] args) {
//创建Optional对象
Optional<String> optional1 = Optional.of("bin");
//Optional<String> optional2 = Optional.ofNullable("bin"); //value为null是返回empty()
Optional<String> optional3 = Optional.empty();
System.out.println(optional1.isPresent());
System.out.println(optional1.get());
optional1.ifPresent((value)->System.out.println(value));
System.out.println(optional1.orElse("无值")); //有value打印value,无value打印“无值”
System.out.println(optional1.orElseGet(()->"default"));
// try {
// optional3.orElseThrow(Exception::new);
// } catch (Exception e) {
// e.printStackTrace();
// }
Optional<String> optional4 = optional1.map((value)->value.toUpperCase());
System.out.println(optional4.orElse("无值"));
optional4 = optional1.flatMap((value)->Optional.of(value.toUpperCase()+"-flatMap"));
System.out.println(optional4.orElse("无值"));
optional4 = optional1.filter((value)->value.length()>3);
System.out.println(optional4.orElse("无值"));
}
Queue
- 先进先出【FIFO】的线性数据结构
- 在表的前端(队头)删除,后端(队尾)插入
- LinkedList是Queue接口的实现类
boolean add(E e); //将指定元素插入队列;成功时返回true,当前没有可用空间时抛出illegalStateException
E element(); //获取,不移除此队列的头
boolean offer(E e); //将指定元素插入队列,优于add(E)
E peek(); //获取但不移除队列的头,队列为空返回null
E poll(); //获取并移除队列的头,队列为空返回null
E remove() //获取并移除此队列的头
private static void queue() {
Queue<String> queue = new LinkedList<>();
queue.add("小一");
queue.add("小二");
queue.add("小三");
queue.add("小四");
System.out.println(queue.size());
System.out.println(queue.peek()); //仅获取队列的头
System.out.println(queue.poll()); //获取移除队列的头
}
Deque
-
双端队列
-
一个线性collection,支持在两端插入和移除元素
private static void deque() {
Deque<String> deque = new LinkedList<>();
deque.add("小一");
deque.add("小二");
deque.add("小三");
deque.add("小四");
System.out.println(deque.getFirst());
System.out.println(deque.getLast());
}
Stack
- 堆栈
- 先进后出
//类
private static void stack() {
Stack<String> s = new Stack<>();
//压栈
s.push("Bin");
s.push("April");
s.push("Tom");
System.out.println(s.peek());
// pop()移除顶部对象
}
对象的一对多与多对多关系
- 对象的一对多
public class Teacher {
private String name;
private int age;
private String sex;
private HashSet<Student> students = new HashSet<>(); //一个老师多个学生
public HashSet<Student> getStudents() {
return students;
}
public void setStudents(HashSet<Student> students) {
this.students = students;
}
public String getName() {
return name;
}
public void setName(String name) {
this.name = name;
}
public int getAge() {
return age;
}
public void setAge(int age) {
this.age = age;
}
public String getSex() {
return sex;
}
public void setSex(String sex) {
this.sex = sex;
}
@Override
public String toString() {
return "Teacher [name=" + name + ", age=" + age + ", sex=" + sex + "]";
}
public Teacher(String name, int age, String sex) {
super();
this.name = name;
this.age = age;
this.sex = sex;
}
public Teacher() {
super();
}
}
public class Student {
private String name;
private int age;
private Teacher teacher;
public Teacher getTeacher() {
return teacher;
}
public void setTeacher(Teacher teacher) {
this.teacher = teacher;
}
public String getName() {
return name;
}
public void setName(String name) {
this.name = name;
}
public int getAge() {
return age;
}
public void setAge(int age) {
this.age = age;
}
@Override
public String toString() {
return "Student [name=" + name + ", age=" + age + "]";
}
public Student(String name, int age) {
super();
this.name = name;
this.age = age;
}
public Student() {
super();
}
}
public static void main(String[] args) {
Teacher t1 = new Teacher("lily",18,"女");
Student s1 = new Student("小小",10);
Student s2 = new Student("小贝",9);
Student s3 = new Student("贝贝",9);
t1.getStudents().add(s1);
t1.getStudents().add(s2);
t1.getStudents().add(s3);
s1.setTeacher(t1);
s2.setTeacher(t1);
s3.setTeacher(t1); //双向绑定
print(t1);
}
private static void print(Teacher t) {
System.out.println(t.getName());
for(Student student:t.getStudents()) {
System.out.println(student);
}
}
- 多对多
- 不建议直接使用多对多,拆分成两个一对多
迭代器设计模式
-
提供一个方法按顺序遍历一个集合内的元素,而不需要暴露该对象的内部表示
-
应用场景
- 访问一个集合的对象而不暴露对象的内部表示
- 支持对集合对象的多种遍历
- 对遍历不同的对象提供统一的接口
-
迭代器模式的角色构成
- 迭代器角色【Iterator】
- 定义遍历元素所需要的方法
- next() 取得下一个元素
- hasNext() 判断是否遍历结束
- remove() 移除当前对象
- 定义遍历元素所需要的方法
//迭代器接口 public interface Iterator { public boolean hasNext(); public Object next(); }- 具体迭代器角色【Concrete Iterator】
- 实现迭代器接口中定义的方法,完成集合的迭代
//迭代器接口的具体实现类 public class ConcreteIterator implements Iterator{ private MyList list = null; private int index; //迭代器的指针 public ConcreteIterator(MyList list) { this.list = list; } @Override public boolean hasNext() { if(index >= list.getSize()) { return false; } else return true; } @Override public Object next() { Object obj = list.get(index); index++; return obj; } }- 容器角色【Aggregate】
- 一般是一个接口,提供一个iterator()方法
//容器的接口 public interface MyList { void add(Object e); Object get(int index); Iterator iterator(); int getSize(); }- 具体容器角色【ConcreteAggregate】
- 抽象容器的具体实现类
- 迭代器角色【Iterator】
//容器接口的具体实现类
public class ConcreteAggregate implements MyList{
private Object[] elements; //对象数组
private int size; //数组大小
private int index;
public ConcreteAggregate() {
elements = new Object[100];
}
@Override
public void add(Object e) {
elements[index++] = e;
size++;
}
@Override
public Object get(int index) {
return elements[index];
}
@Override
public int getSize() {
return size;
}
@Override
public Iterator iterator() {
return new ConcreteIterator(this);
}
}
guava对集合的支持



eclipse使用Junit测试类
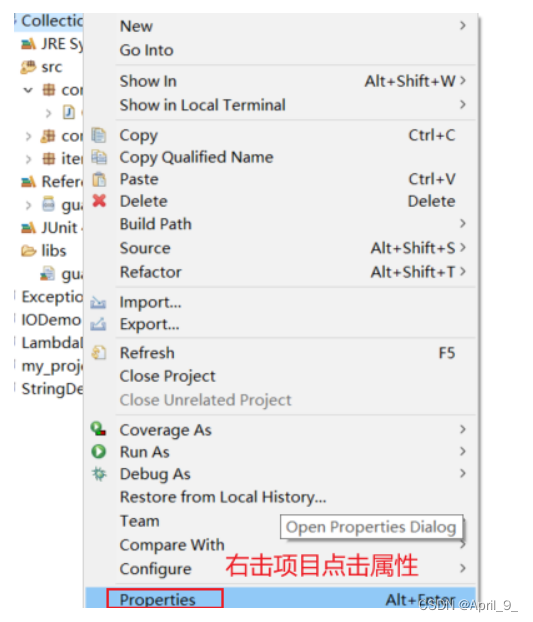




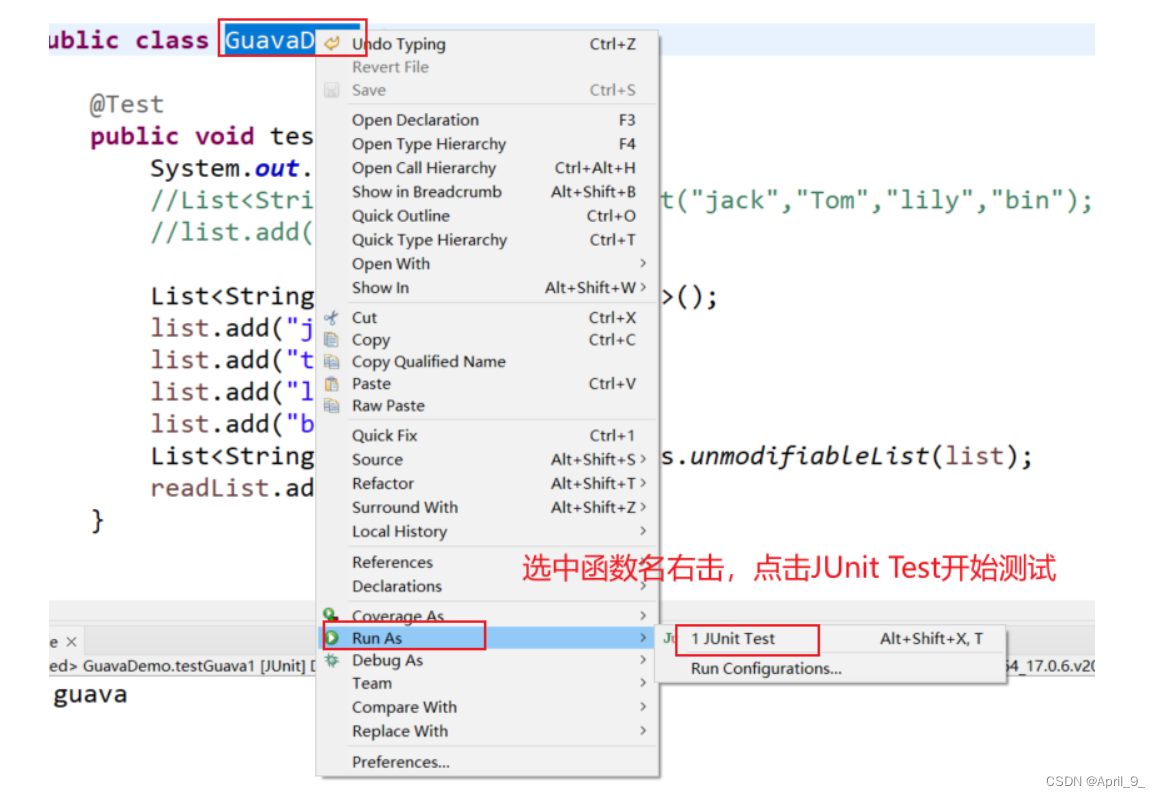

只读设置
public class GuavaDemo {
@Test
public void testGuava1() {
System.out.println("test guava");
//List<String> list = Arrays.asList("jack","Tom","lily","bin");
//list.add("vince");
List<String> list = new ArrayList<>();
list.add("jack");
list.add("tom");
list.add("lily");
list.add("bin");
//List<String> readList = Collections.unmodifiableList(list);
//readList.add("vince");
ImmutableList<String> iList = ImmutableList.of("jack","tom","lily","bin");
iList.add("vince");
}
}
过滤器
@Test
public void testGuava2() {
List<String> list = Lists.newArrayList("java","php","jack","javascript");
Collection<String> result = Collections2.filter(list,(e)->e.startsWith("j"));
result.forEach(System.out::println);
}
转换
@Test
public void testGuava3() {
Set<Long> timeSet = Sets.newHashSet(20121212L,20170520L,20160808L);
Collection<String> timeCollect = Collections2.transform(timeSet,(e)->new SimpleDateFormat("yyyy-MM-dd").format(e));
timeCollect.forEach(System.out::println);
}
组合式函数编程
@Test
public void testGuava4() {
List<String> list = Lists.newArrayList("java","php","jack","h5","javascript");
Function<String,String> f1 = new Function<String,String>(){
@Override
public String apply(String t) {
return t.length()>4 ? t.substring(0,4) : t;
}
};
Function<String,String> f2 = new Function<String,String>(){
@Override
public String apply(String t) {
return t.toUpperCase();
}
};
Function<String,String> f = Functions.compose(f1, f2);
Collection<String> coll = Collections2.transform(list, f);
coll.forEach(System.out::println);
}
集合操作:交集、差集、并集
@Test
public void testGuava5() {
Set<Integer> set1 = Sets.newHashSet(1,2,3);
Set<Integer> set2 = Sets.newHashSet(3,4,5);
//交集
SetView<Integer> v1 = Sets.intersection(set1, set2);
v1.forEach(System.out::println);
//差集
SetView<Integer> v2 = Sets.difference(set1, set2);
System.out.println("--------------------");
v2.forEach(System.out::println);
//并集
SetView<Integer> v3 = Sets.union(set1, set2);
System.out.println("--------------------");
v3.forEach(System.out::println);
}
Multiset 无序可重复
@Test
public void testGuava6() {
String s = "good good study day day up";
String[] ss = s.split(" ");
HashMultiset<String> set = HashMultiset.create();
for(String str : ss) {
set.add(str);
}
Set<String> set2 = set.elementSet();
for(String str : set2) {
System.out.println(str+":"+set.count(str));
}
}
Multimap key可以重复
@Test
public void testGuava7() {
Map<String,String> map = new HashMap<>();
map.put("Java从入门到精通", "bin");
map.put("Android从入门到精通", "bin");
map.put("PHP从入门到精通", "jack");
map.put("笑看人生", "vince");
Multimap<String,String> mmap = ArrayListMultimap.create();
Iterator<Map.Entry<String,String>> iter = map.entrySet().iterator();
while(iter.hasNext()) {
Map.Entry<String, String> entry = iter.next();
mmap.put(entry.getValue(), entry.getKey());
}
Set<String> keySet = mmap.keySet();
for(String key:keySet) {
Collection<String> values = mmap.get(key);
System.out.println(key+"->"+values);
}
}
/*
bin->[Java从入门到精通, Android从入门到精通]
vince->[笑看人生]
jack->[PHP从入门到精通]
*/
BiMap
- 双向Map,键与值不能重复
@Test
public void testGuava8() {
BiMap<String,String> map = HashBiMap.create();
map.put("finally_test", "11111111111111");
map.put("bin_test", "2222222222");
String name = map.inverse().get("11111111111111");
System.out.println(name);
}
双键的Map—>Table—>rowKey+columnKey+value
@Test
public void testGuava9() {
Table<String,String,Integer> table = HashBasedTable.create();
table.put("jack", "java", 80);
table.put("tom","php",70);
table.put("bin", "java", 60);
table.put("lily", "ui", 98);
Set<Cell<String,String,Integer>> cells = table.cellSet();
for(Cell c:cells) {
System.out.println(c.getRowKey()+"-"+c.getColumnKey()+"-"+c.getValue());
}
}
















 2366
2366











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









