







6.5 图的遍历
在前面我们知道,树是一种非线性结构,为了方便它在计算机中的存储,对树进行遍历使它线性化。
而图同样也是一种非线性结构,但是图又是一种不同于树的多对多结构,所以在前面我们将其转换为了多个一对多的结构来描述它的存储结构。
图的遍历同树类似,也是从某一个顶点出发,按照某种方法对图中所有顶点访问且仅访问一次。图的遍历算法是求解图的连通性问题、拓扑排序和关键路径等算法的基础。
因为图的任一顶点都可能和其余的顶点相邻接,为了避免同一顶点被访问多次,在遍历图的过程中,必须记下每个已访问过的顶点。
通常有两条遍历的图的路径:深度优先搜索和广度优先搜索。
6.5.1 深度优先搜索
1. 深度优先搜索遍历的过程
深度优先搜索(Depth First Search,DFS)遍历类似于树的先序遍历。我们也可以理解一下深度的概念,也就是树中深度的概念,但这需要图要有跟树相似的形状。何谓深度优先?就是从某个顶点一直往下,先不管与它处于同一层次的其它顶点。
对于一个连通图,深度优先搜索遍历的过程如下:
- 从图中某个顶点 v v v出发,访问顶点 v v v
- 找到刚访问过的顶点的第一个未被访问的邻接点,接着访问该邻接点;然后以该邻接点为新的顶点,重复上述步骤,直到刚访问过的顶点没有未被访问的邻接点。
- 经过了第二步后,由 v v v的第一个未被访问的邻接点延伸的后面的顶点都被访问了(但不确定这条延伸链上每个顶点的其它邻接点是否被访问),此时还停留在“最下面”的那个顶点,这时我们需要返回到前一个访问过的且仍有未被访问的邻接点的顶点。若停留顶点的前面一个顶点的邻接点都被访问过,则继续“向上”回溯。
- 重复步骤(2)和(3),直至图中所有顶点都被访问过,搜索结束。
下面举一个例子,来说明该搜索方法,如下图: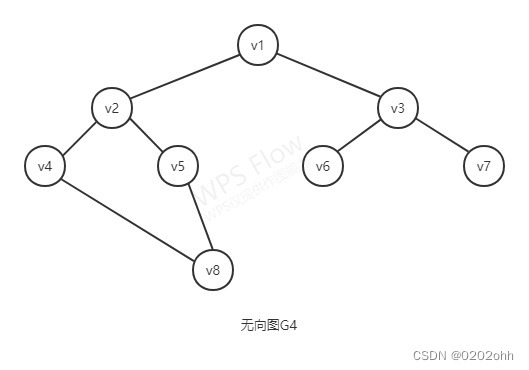
如果我们要遍历该图,按照上述的步骤进行,那么即:
- 从顶点 v 1 v_{1} v1出发,访问 v 1 v_{1} v1(也可从其它任一顶点出发)
- 选择 v 1 v_{1} v1未被访问的第一个邻接点 v 2 v_{2} v2(也可以是 v 3 v_{3} v3),访问 v 2 v_{2} v2。又以 v 2 v_{2} v2为新顶点,那么这条延伸链则为: v 1 → v 2 → v 4 → v 8 → v 5 v_{1}\rightarrow v_{2}\rightarrow v_{4}\rightarrow v_{8}\rightarrow v_{5} v1→v2→v4→v8→v5,因为 v 5 v_{5} v5的邻接点都已被访问过,最后停留在 v 5 v_{5} v5。
- 此时我们需要回溯,找到前面顶点的未被访问过的邻接点。 v 5 → v 8 v_5\rightarrow v_{8} v5→v8, v 8 → v 4 v_{8}\rightarrow v_{4} v8→v4, v 4 → v 2 v_{4}\rightarrow v_{2} v4→v2,都没有找到未被访问的邻接点,最后 v 2 → v 1 v_{2}\rightarrow v_{1} v2→v1, v 1 v_{1} v1有未被访问的邻接点,搜索又从 v 1 → v 3 v_{1}\rightarrow v_{3} v1→v3,继续进行下去。
- 最后,我们得到的访问序列为: v 1 → v 2 → v 4 → v 8 → v 5 → v 3 → v 6 → v 7 v_{1}\rightarrow v_{2}\rightarrow v_{4}\rightarrow v_{8}\rightarrow v_{5}\rightarrow v_{3}\rightarrow v_{6}\rightarrow v_{7} v1→v2→v4→v8→v5→v3→v6→v7。
因为我们遍历是求解图的连通性问题,若访问结束没有未被访问的结点,则是连通图;若有,则是非连通图。
对于上述深度优先搜索的结果,我们可以构造一棵以
v
1
v_{1}
v1为根的树,称为深度优先生成树,如下图:
2. 深度优先搜索遍历的算法实现
由于遍历的过程需要判断搜索的顶点是否已被访问,所以我们应该想办法在搜索的时候判断每个是否已被访问。已知,每个顶点只有两种状态:已被访问和未被访问。所以如果该顶点未被访问,只需将其状态改为已被访问就行。而该判断方法比较简单,所以我们可以考虑用一维数组visited来存储每个顶点的状态。若未被访问,则其值为false;若已访问,则其值为true。在这里可以使用布尔类型来实现。 → \rightarrow →布尔数据类型
算法——深度优先搜索遍历连通图
算法分析:
- 首先我们将数组visited初始化,将每个顶点的状态值都赋为false
- 再从该顶点延伸往下,都是访问的该延伸链中每个顶点的第一个邻接点,最后再从该延伸链最后一个顶点回溯。从这里我们可以看到,要访问一个顶点的全部邻接点,是从最下面的那个顶点开始,逐层向上。而这,不就是一个递归的过程吗。而每个顶点要访问所有邻接点,肯定也是一个循环结构。
- 然后我们需要注意的是循环和递归结束的条件。循环结束的条件不用说,肯定是邻接点访问完后。而递归结束的条件就是循环结束,循环结束后向上回溯,直至第一个顶点 v v v的循环结束
- 至此,该连通图的所有顶点全部都被访问过
代码实现:
bool visited[MVNum];
void DFS(Graph G,int v)
{
printf("%d",&v); //打印出每个顶点,方便最后检查是否全部顶点已被访问
visited[v]=ture;
for(int w=FirstAdjVex(G,v);w>=0;w=NextAdjVex(G,v,w))
if(!visited[w]) //如果该邻接点未被访问
DFS(G,w);
}
其中FirstAdjVex和NextAdjVex函数要根据具体的图的存储结构来设计。
算法——深度优先搜索遍历非连通图
算法分析:
- 非连通图我们可以理解为是由两个及两个以上的图构成的
- 由此,该算法不能向遍历连通图那样,从任一一个顶点出发就可遍历所有顶点。在此算法中,若采用上述算法,则只能遍历“一个图”,其它图就不能遍历
- 于是,我们只有对所有顶点做一个循环,只要有未被访问的顶点,就从该顶点出发调用上述算法
代码实现:
void DFSTraverse(Graph G)
{
for(int v=0;v<G.vexnum;v++)
visited[v]=false;
for(int v=0;v<G.vexnum;v++)
if(!visited[v])
DFS(G,v);
下面分别采用两种不同的图结构来实现深度优先搜索。有了上述过程的理解,我们直接给出代码实现。
算法——采用邻接矩阵表示图的深度优先搜索遍历
void DFS_AM(AMGraph G,int v)
{
for(int i=0;i<vexnum;i++)
visited[i]=false;
printf("%d ",&v);
visited[v]=true;
for(w=0;w<G.vexnum;w++)
if((G.arcs[v][w]!=0)&&!visited[w])
DFS_AM(G,w);
}
算法——采用邻接表表示图的深度优先搜索遍历
void DFS_AL(ALGraph G,int v)
{
ArcNode *p;
for(int i=0;i<G.vexnum;i++)
visited[i]=false;
printf("%d ",&v);
visited[v]=true;
p=G.vertices[v].firstarc;
while(p!=NUll)
{
w=p->adjvex;
if(!visited[w])
DFS_AL(G,w);
p=p->nextarc;
}
}
3. 对深度优先搜索算法的分析
在遍历图时,对图中每个顶点至多调用依次DFS函数,因为一旦某个顶点被标志成已被访问,就不再从它出发进行搜索。因此,遍历图的过程实质上是对每个顶点查找其邻接点的过程,其耗费时间取决于所采用的存储结构。
- 若用邻接矩阵:时间复杂度为 O ( n 2 ) O(n^2) O(n2),n为顶点数
- 若用邻接表:时间复杂度为 O ( e ) O(e) O(e),e为边数
6.5.2 广度优先搜索
广度优先搜索和深度优先搜索正好相反,如果说深度优先搜索是“竖”着来,那么广度优先搜索就是“横”着来。
1. 广度优先搜索遍历的过程
该过程类似于树的按层次遍历
- 依旧是从图中的某个顶点 v v v出发,并访问 v v v
- 依次访问 v v v的所有未被访问过的邻接点
- 再从邻接点出发,依次访问它们的邻接点,并使先被访问的顶点的邻接点先于后被访问的顶点的邻接点。重复该步骤,直至图中所有已被访问的顶点的邻接点都被访问到
下图为对无向图G4广度优先搜索遍历的一个示例过程:
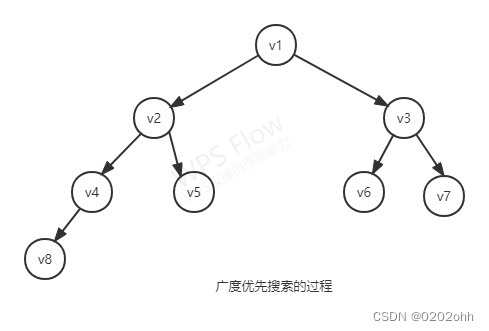
由此我们得到的访问序列为:
v
1
→
v
2
→
v
3
→
v
4
→
v
5
→
v
6
→
v
7
→
v
8
v_{1}\rightarrow v_{2}\rightarrow v_{3}\rightarrow v_{4}\rightarrow v_{5}\rightarrow v_{6}\rightarrow v_{7}\rightarrow v_{8}
v1→v2→v3→v4→v5→v6→v7→v8
而上述图也可作为广度优先搜索的一棵广度优先生成树。
2. 广度优先搜索遍历的算法实现
算法分析:
- 在前面我们说到,在广度优先搜索中要使先被访问的顶点的邻接点先于后被访问的顶点的邻接点被访问,但前提是先访问了这两个顶点,再去按照一定次序分别访问它们的邻接点
- 如果我们把它想象成树的结构那么就好理解了,上一条的意思就是在每一层一定要以从左到右的次序访问顶点
- 在这里是一层一层从上到下访问的,所以递归是行不通的,而对访问的次序又有一定的要求。我们再来捋一捋思路:假如从 v 1 v_{1} v1出发,再访问它的邻接点 v 2 , v 3 v_{2},v_{3} v2,v3(先访问的是 v 2 v_{2} v2),然后再访问 v 2 , v 3 v_{2},v_{3} v2,v3的邻接点(先访问的是 v 2 v_{2} v2的邻接点,也就是 v 4 , v 5 v_{4},v_{5} v4,v5,再访问 v 3 v_{3} v3的邻接点也就是, v 6 , v 7 v_{6},v_{7} v6,v7)。由于它们访问有一定的次序,因此按照前面深度优先搜索的算法中某些步骤是很麻烦的
- 我们再将它的规则总结以下,也就是先“到”先访问,看到这里是否觉得很熟悉?没错,这就是队列的特点,根据这个规则,我们就可以引入队列,那么就十分方便了,如果队列有点忘了,那么可以复习一下: ~~~~~~~~ → \rightarrow →队列
- 于是,我们可以利用出队和进队的方式来进行有先后次序的访问
代码实现:
typedef struct
{
QElemType *base;
int front;
int rear;
}SqQueue;
void InitQueue(SqQueue &q)
{
base=(QElemType*)malloc(MVNum*sizeof(QElemType));
q.front=q.rear=0;
}
void EnQueue(SqQueue &q,QElemType e)
{
if(q.rear+1)%MVNum=q.front;
return;
q.base[q.rear]=e;
q.rear=(q.rear+1)%MVNum;
}
void DeQueue(SqQueue &q,QElemType &e)
{
if(q.front==q.rear)
return;
e=q.base[q.front];
q.front=(q.front+1)%MVNum;
}
bool visited[MVNum];
void BFS(Graph G,int v)
{
for(int i=0;i<G.vexnum;i++)
visited[i]=false;
printf("%d ",&v);
visited[v]=true;
Initiate(Q);
Enqueue(Q,v);
while(!QueueEmpty(Q)) //队列非空
{
Dequeue(Q,u); //队头元素置为u
for(w=FirstAdjVex(G,u);w>=0;w=NextAdjVex)
if(!visited[w])
{
printf("%d ",&w);
visited[w]=true;
Enqueue(Q,w);
}
}
}
根据上述算法,每个顶点至多进一次队列。遍历图的过程实质上是通过边找邻接点的过程,因此广度优先搜索遍历图的时间复杂度和深度优先搜索遍历相同。
总结
图的遍历其实并不难,关键是我们知道为什么要去遍历图:是求解图的连通性问题、拓扑排序和关键路径等算法的基础。
遍历图可以从两个方向去遍历,即深度和广度。顾名思义,深度就是从上到下,广度就是从左到右。但深度又不是单纯的从上到下,它是从某个顶点出发,延该顶点的第一个邻接点及该邻接点的第一个邻接点等等继续往下延伸,形成了一条延伸链,直到该延伸链最下面的那个顶点没有未被访问的邻接点,最后再由该延伸链向上回溯。而广度,是要把图看成树状的,一层一层从左到右地去遍历。
对于不同的图的结构,遍历的算法又不同,因此因根据实际情况来操作。
这两个遍历方法并没有好坏之分,只是对于顶点访问的顺序不同。














 1362
1362











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









