






前景:在应用开发的过程中,由于前期数据量少,开发人员编写的SQL语句或者数据库整体解决方案都更重视在 功能上的实现, 但是当应用系统正式上线后,随着生成数据量的急剧增长,很多SQL语句和数据库整体开始逐渐显露出了性能问题,此时Mysql数据库的性能问题成为系统应 用的瓶颈,因此需要进行Mysq数据库的性能优化。
性能下降的原因
- 查询语句写的不好,各种连接,各种子查询导致用不上索引或者没有建立索引
- 建立的索引失效,建立了索引,在真正执行时,没有用上建立的索引
- 关联查询太多join
- 服务器调优及配置参数导致,如果设置的不合理,比例不恰当,也会导致性能下降,sql变慢
- 系统架构的问题
常用方案

- 索引优化: 添加适当索引(index)(重点)
- Sql优化: 写出高质量的sql,避免索引失效 (重点)
- 设计优化: 表的设计合理化(符合3NF,有时候要进行反三范式操作)
- 配置优化: 对mysql配置优化 [配置最大并发数my.ini, 调整缓存大小 ]
- 架构优化:读写分离、分库分表
- 硬件优化: 服务器的硬件优化
一般来说我们都采用索引来解决SQL性能问题。索引就是一种数据结构,可大大提高mysql查询效率。
1.索引原理
对于索引,首先我们要知道内存和磁盘的概念。
每次从磁盘中查找数据称为磁盘I/O, 而磁盘IO 至少要经历磁盘寻道、磁盘旋转、数据读取等等操作,非常影响性能,所以对于读取数据,最大的优化就是减少磁盘I/O.
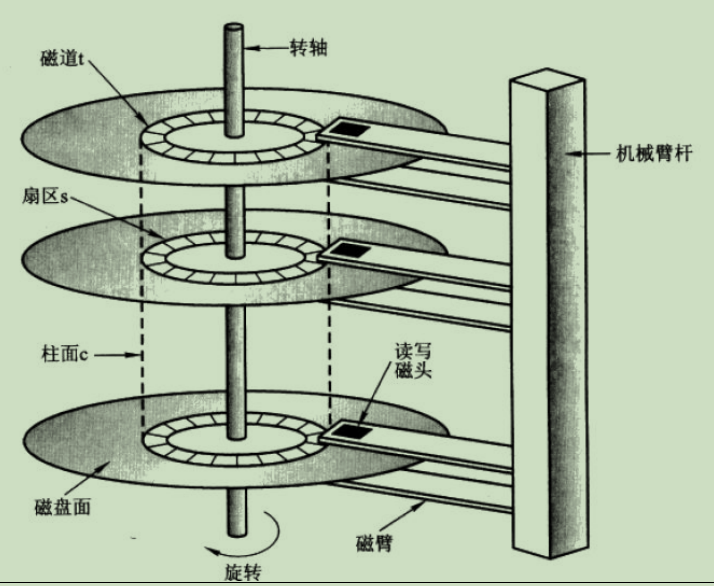
mysql底层的数据结构主要是基于Hash和B+Tree
底层数据结构分析:
二叉树:虽然可加加快数据的查找,当数据量到达一定量时,树的高度过高,磁盘IO的次数就会加大。
所以B+Tree树又称自平衡多叉查找树度
- (Degree) 节点的数据存储个数
- 叶节点具有相同的深度
- 节点中数据key从左到右递增排列
- 叶节点的指针为空
- 在节点中直接存储了数据 data
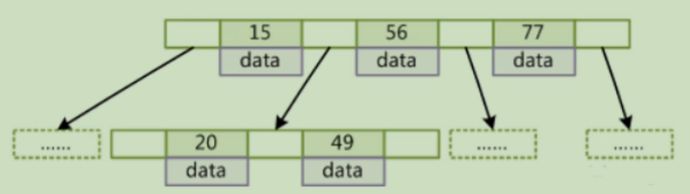
疑问:
二叉树的节点只存了一个数据? 而BTree的节点因为有度的概念存了多个数据?
那么二叉树的节点数据量小是不是在读取的时候效率更高呢?
而且读到内存中的遍历速度是不是更快些呢?
预读:磁盘一般会顺序向后读取一定长度的数据(页的整数倍)放入内存
局部性原理:当一个数据被用到时,其附近的数据也通常会马上被使用
存储器读取数据按 磁盘块读取
每个磁盘块的大小为 扇区(页)的2的N次方
每个扇区的最小单位 512B 或 4096B 不同的生产厂家不同
为了提升度的长度,还需要对这种数据结构进行优化,所以它的升华版B+Tree诞生了
2.B+Tree
B+树是B树的变体,基本与BTree相同
特点
- 非叶子节点不存储data,只存储key,可以增大度
- 叶子节点不存储指针
- 顺序访问指针,提高区间访问能力
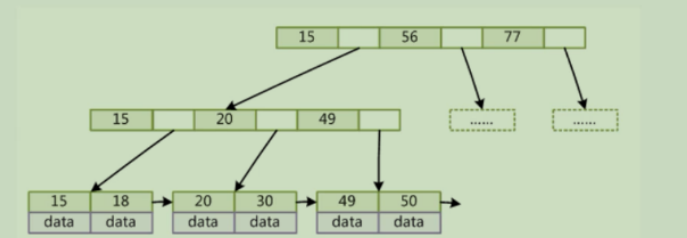
B+Tree索引的性能分析
一般使用磁盘IO次数来评价索引结构的优劣
B+Tree的度一般会超过100,因此h非常小 (一般为3到5之间),性能就会非常稳定
B+Tree叶子节点有顺序指针,更容易做范围查询
对比Hash
使用hash结构存储索引,查找单行数据很快,但缺点也很明显

1.无法用于排序
2.只支持等值查找
3.存在Hash冲突
Hash索引只适用于某些特定场景,我们使用不多
3.mysql的索引实现
存储引擎的概念:
mysql索引对于不同的存储引擎,索引实现各不相同。
mysql中的数据用各种不同的技术存储在文件(或者)内存中。
这些技术使用不同的存储机制,索引技巧,锁定技巧,锁定水平,并且最终提供广泛的不同的功能和能力
这些不同的技术以及配套的相关功能在MySQL中被称为存储引擎
通过show engines 可以查看当前数据库支持的引起,默认的引擎
查看当前数据库的默认引擎 show VARIABLES like 'default_storage_engine'
如果你在研究大量的临时数据,你也许需要使用内存存储引擎。内存存储引擎能够在内存中存储所有的
表格数据。
也许需要一个支持事务处理的数据库(以确保事务处理不成功时数据的回退能力)选择支持事务的存储引擎
5.7 默认的引擎是innodb 可通过 SET default_storage_engine=< 存储引擎名 >更改.
MyISAM 和 innoDB引擎 这两种引擎都是采用B+Tree和hash 数据结构实现的索引。
MyISAM 和 innoDB的对比

总的来说:需要事务:用innoDB
不需要事务:myisam的查询效率高,内存要求低,但是其采用表锁,不适合并发写操作,读多写少选它
innoDB采用行锁,适合处理并发写操作,写多读少选它
3.1myisam索引实现:
myisam索引特点 : 非聚簇索引
采用B+Tree和Hash作为数据结构
myisam索引文件和数据文件是分离的(非聚簇)
叶子结点存储的是数据的磁盘地址,非主键索引和主键索引类似

3.2InnoDB索引实现
索引特点:
采用B+Tree 和 Hash作为数据结构
数据文件本身就是索引文件 (聚簇索引)
表数据文件本身就是按照B+Tree组织的一个索引结构文件
聚集索引-叶节点包含了完整的数据记录
非主键索引 的叶子节点指向主键
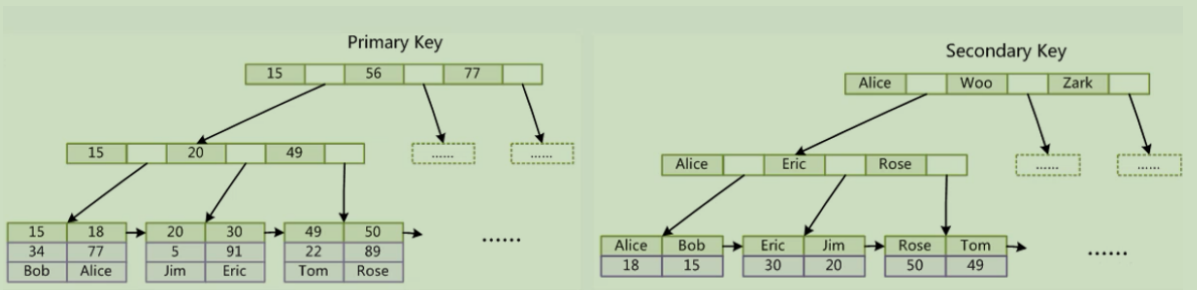
4.索引的分类
4种常用的索引,各有所长。
1.普通索引index :加速查找
create index idx_ on 表(字段)
2.唯一索引:
主键索引:primary key :加速查找+约束(不为空且唯一)
唯一索引:unique:加速查找+约束 (唯一)
3.联合索引(组合索引)
最左匹配原则
where A=? and B=? and C=?
create index A on 表(A,B,C)
-primary key(id,name):联合主键索引
-unique(id,name):联合唯一索引
-index(id,name):联合普通索引
4.全文索引fulltext :用于搜索很长一篇文章的时候,效果最好。 ELASTICSEARCH
4.1索引的操作:
创建索引
create (索引类型) index 索引名称 on 表名(字段(长度))
例如 : create index emp_name_index on employee(name)
查看索引
show index from 表名
删除索引
drop index[索引名称] on 表名
如:drop index emp_name_index on employee;
更改索引
alter table tab_name add primary key(column_list)
--添加一个主键,索引必须是唯一索引,不能为null
alter table tab_name add unque index_name(column_list)
---创建的索引是唯一索引,可以为null
alter table tab_name ad index index_name(column_list)
--普通索引,索引值可出现多次
alter table tab_name add fulltext index_name(column_list)
--全文索引
这里联合索引要特别说一下:
联合索引(最左匹配原则)
联合索引就是 当我们的where条件中经常存在多个条件查询的时候,我们可以为这个列创建联合也就是组合索引。
如:一张员工表,我们经常会用工号,名称,入职日期作为条件查询
select * from 员工表 where 工号=10002 and 名称=jack and 入职日期='2001-11-21'
此时我们可以考虑将(工号,名称,入职日期)创建为一个组合索引
这时我们有问题为什么不把这三个字段分别单独列一个索引?
主要是效率问题。分别创建索引,MySQL只会选择辨识度高的一列作为索引,假如有100w的数据,一个索引筛选出10%的数据,那么可以筛选出10w的数据
而对于组合索引来说,如果将这三个字段创建为一个组合索引,那么三个字段的筛选都会作用,先按巩固好排查,工号匹配完再按名称筛选,然后再按日期筛选,那么筛选的数据就是100w*10%*10%*10%筛选出1000条数据。
最左原则:
(工号,名称,入职日期)作为一个组合索引,就是b+树按照左边来顺序判断,对于我们的索引:
条件为: (工号) (工号,名称) (工号,名称,入职日期) 这几种情况都是生效的
条件为: (名称)不生效 (名称,入职日期)不生效 (工号,入职日期)部分生效
索引的优劣
优势:
- 1.可以通过建立唯一索引或者主键索引,保证数据库表中每一行数据的唯一性.
- 2.建立索引可以大大提高检索的数据,以及减少表的检索行数
- 3.在表连接的连接条件 可以加速表与表直接的相连
- 4.在分组和排序字句进行数据检索,可以减少查询时间中 分组 和 排序时所消耗的时间(数据库的记录会重新排序)
- 5.建立索引,在查询中使用索引 可以提高性能
劣势
- 1.索引文件会占用物理空间,除了数据表需要占用物理空间之外,每一个索引还会占用一定的物理空间
- 2.在创建索引和维护索引 会耗费时间,随着数据量的增加而增加
- 3.当对表的数据进行INSERT,UPDATE,DELETE 的时候,索引也要动态的维护,这样就会降低数据的维护速度
4.2索引的选择
适合建立索引
1.主键自动建立唯一索引:primary
2.频繁作为查询条件的字段应该创建索引
where name =
3.查询中与其它表关联的字段,外键关系建立索引
dept id employ dep_id
4.查询中排序的字段,排序的字段若通过索引去访问将大大提升排序速度
order by age
5.查询中统计或分组的字段
group by age
不适合建立索引
1.记录比较少
2.where条件里用不到的字段不建立索引
3.经常增删改的表
索引提高了查询的速度,同时却会降低更新表的速度,因为建立索引后, 如果对表进行
INSERT,UPDATE 和 DELETE, MYSQL不仅要保存数据,还要保存一下索引文件
4.数据重复的表字段
如果某个数据列包含了许多重复的内容,为它建立索引 就没有太大在的实际效果,比如表中
的某一个字段为国籍,性别,数据的差异率不高,这种建立索引就没有太多意义。
思考
- 什么是索引?
- 索引为什么能够提升查询效率?
- mysql的索引是基于什么数据结构实现的?
- 为什么选择这种数据结构?
- 聚簇索引和非聚簇索引有什么区别
- 索引的分类
- 索引的优劣
- 索引的选择
- 组合索引的最左原则















 10万+
10万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









