









HDFS简述
HDFS是Hadoop的两大核心之一,用来分布式存储海量数据
文件系统结构:

HDFS结构类似于文件系统:

HDFS实现目标:
1.兼容廉价的硬件设施
2.实现流数据读写
3.支持大数据集
4.支持简单的文件模型
5.强大的跨平台兼容
HDFS局限性:
1.不合适低延迟的数据访问
2.无法高效存储大量小文件
3.不支持多用户写入及任意修改文件
HFDS相关概念
1.块
块设计的好处:支持大规模文件存储简化系统设计,适合数据备份
2.HDFS两大主件:
名称节点(NameNode):整个HDFS集群的管家,存储数据地址

FsImage:存储文件的复制等级,修改和访问时间,访问权限,块大小以及组成文件的块的相关元数据
名称节点对两大主件的调用过程:

但随着数据的增大EditLog会不断增大,使用第二名称节点可以解决这个问题
第二名称节点:1.名称节点的冷备份 2.对EditLog的处理
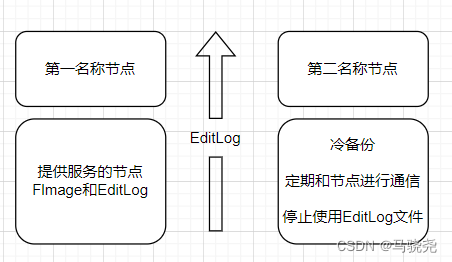
第二名称节点会定期的和名称节点通信,让它停止对EditLog的创建,名称节点会马上停止,然后生一个edits.new,又生成一个EditLog,把对数据的全部更新都写到edits.new中,让第二名称节点将它取走,第二名称节点会通过get方法从名称节点将Fslmage和EditLog下载到本地,然后拷到第二名称节点对Fslmage和EditLog合并得到一个新的名称节点,合并之后再发送给名称节点,然后名称节点会把edit.new更改为Edit,实现了数据的合并和冷备份。
数据节点(DataNode):存储数据

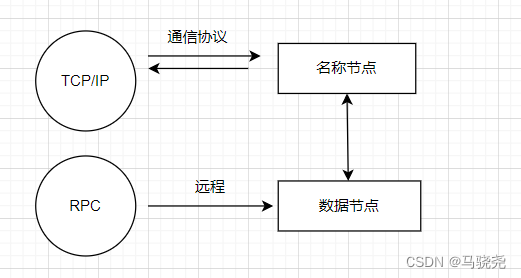
HDFS体系结构
体系:

HDFS命名空间:包含目录文件,块
通信:
HDFS存储原理
数据冗余保存:HDFS的底层大多数是廉价的机器,存在不断发生故障的缺陷,使用就要对数据进行冗余保存,一般将同一份数据保存三份或多份。
冗余存储的好处:
1.加快数据传输速度:一个数据有多个备份,方便了客户端并行访问数据
2.很容易检查数据错误:多个数据备份相互对照
3.保证数据可靠性
数据存放策略:块复制三份副本,第一个副本放在上传文件的节点,如果提交请求的不是来自集群内部则存放在随机磁盘不太满,CPU不太忙的节点,第二个副本放在和第一个副本不同的机架上,第三个副本放在第一个副本的相同机架上的不同位置,如果还有多个就随机放
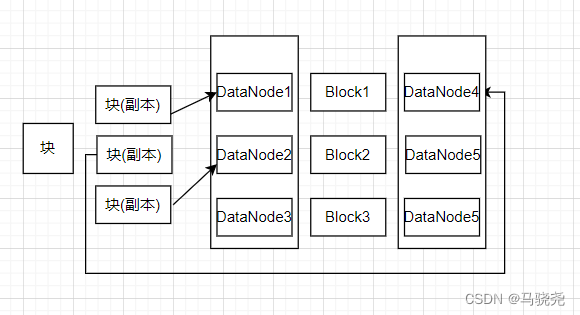
数据读取:
·HDFS提供了一个API可以确定一个数据节点所属的机架ID,客户端可以通过API得到自己所属的机架ID
·客户端读取数据时,从名称节点得到数据块的不同副本的存放位置,选择距离最近的副本读取,如果没有最近的就随机读取
数据的错误和恢复:
·名称节点出错
·数据节点出错
·数据本身出错
名称节点出错恢复:名称节点出错,HDFS系统会停止一段时间,从第二数据节点中冷备份数据然后恢复名称节点数据
数据节点出错恢复:DataNode会隔一定时间向NameNode发放信息,传递心跳,若NameNode没有在规定时间内所到DataNode的信息,NameNodehui会将其视为宕机,在将宕机DataNode的数据的备份数据复制到其他DataNode节点上
数据本身出错恢复:客户端读取数据时会产生校验码,可以用来校验数据信息,数据块在创建时会产生校验码,二者保存在同一目录下,在读数据的时候会产生新的校验码,让新的校验码和原有的校验码对比,如果不一致,则说明数据在存储时发生了错误,要进行数据的冗余恢复
HDFS读数据过程
在Hadoop中有一个叫FileSystem的通用的文件基类,它可以被分布式文件系统进程实现一个DistributedFileSystem的类,还可以通过HTTP访问相关文件或通过FTP方式读写文件

具体过程:

1.打开文件: HDFS客户端打开文件
2.获取数据块信息:DFSInputStream会与名称节点沟通,通过ClientProtocal.getBlockLocations()获得数据块的位置
3.读取请求:HDFS客户端得到数据的位置就可以通过read函数读取数据
4.读取数据:数据从数据节点读到客户端,读取后FSDataInputStream要关闭和数据节点的连接
5.获取数据块信息:再让输入流通过ClientProtocal.getBlockLocations()查找下一个数据块
6.读取数据:获得数据位置后再次和其他数据节点交互读取数据,读取后关闭连接
7.关闭文件:当数据读取结束,调用close函数关闭文件,读取数据结束
HFDS写数据过程
过程:

1.创建文件请求: HDFS创建服务请求,创建FSDataOutputStream输出流,FSDataInputStream封装了DFSOutStream,通过DFSOutStream和名称节点打交道
2.创建文件元数据:远程调用询问名称节点在文件命名空间中创建一个空间,名称节点会检查文件是否存在,是否有创建权限,如果检查通过,就创建文件
3.写入数据:HDFS会把数据分包,然后保存到FSDataInputStream流的内部队列中,FSDataInputStream再从名称节点申请保存这些数据的节点
4.写入数据:数据分包先放到第一个节点,然后放到第二个节点,依次往下
5.接收确定包:从最后一个数据节点往第一数据节点传输写入数据完成的信息,再从第一个节点将信息传输给客户端,确定写操作完成
6.关闭文件
7.写操作完成

















 287
287











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











