






一、卷积的基本属性
1.卷积核(Kernel):卷积操作的感受野,直观理解就是一个滤波矩阵,普遍使用的卷积核大小为3×3、5×5等;
2.步长(Stride):卷积核遍历特征图时每步移动的像素,如步长为1则每次移动1个像素,步长为2则每次移动2个像素(即跳过1个像素),以此类推;
3.填充(Padding):处理特征图边界的方式,一般有两种,一种是对边界外完全不填充,只对输入像素执行卷积操作,这样会使输出特征图的尺寸小于输入特征图尺寸;另一种是对边界外进行填充(一般填充为0),再执行卷积操作,这样可使输出特征图的尺寸与输入特征图的尺寸一致;
4.通道(Channel):卷积层的通道数(层数)。
如下图是一个卷积核(kernel)为3×3、步长stride)为1、填充(padding)为1的二维卷积:
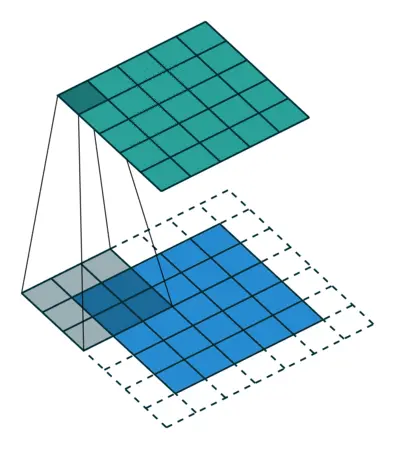
二、卷积的计算过程
卷积的计算过程非常简单,当卷积核在输入图像上扫描时,将卷积核与输入图像中对应位置的数值逐个相乘,最后汇总求和,就得到该位置的卷积结果。不断移动卷积核,就可算出各个位置的卷积结果。如下图:

三、卷积的各种类型
卷积现在已衍生出了各种类型,包括标准卷积、反卷积、可分离卷积、分组卷积等等,下面逐一进行介绍。
1、标准卷积
(1)二维卷积(单通道卷积版本)(2D Convolution: the single channel version)
只有一个通道的卷积。
卷积核(kernel)为3×3、步长(stride)为1、填充(padding)为0的卷积
(2)二维卷积(多通道版本)(2D Convolution: the multi-channel version)
拥有多个通道的卷积,例如处理彩色图像时,分别对R, G, B这3个层处理的3通道卷积,如下图:

再将三个通道的卷积结果进行合并(一般采用元素相加),得到卷积后的结果,如下图:

(3)三维卷积(3D Convolution)
卷积有三个维度(高度、宽度、通道),沿着输入图像的3个方向进行滑动,最后输出三维的结果,如下图

(4)1x1卷积(1 x 1 Convolution)
当卷积核尺寸为1x1时的卷积,也即卷积核变成只有一个数字。如下图:

从上图可以看出,1x1卷积的作用在于能有效地减少维度,降低计算的复杂度。1x1卷积在GoogLeNet网络结构中广泛使用。
2、反卷积(转置卷积)(Deconvolution / Transposed Convolution)
卷积是对输入图像提取出特征(可能尺寸会变小),而所谓的“反卷积”便是进行相反的操作。但这里说是“反卷积”并不严谨,因为并不会完全还原到跟输入图像一样,一般是还原后的尺寸与输入图像一致,主要用于向上采样。从数学计算上看,“反卷积”相当于是将卷积核转换为稀疏矩阵后进行转置计算,因此,也被称为“转置卷积”
如下图,在2x2的输入图像上应用步长为1、边界全0填充的3x3卷积核,进行转置卷积(反卷积)计算,向上采样后输出的图像大小为4x4。
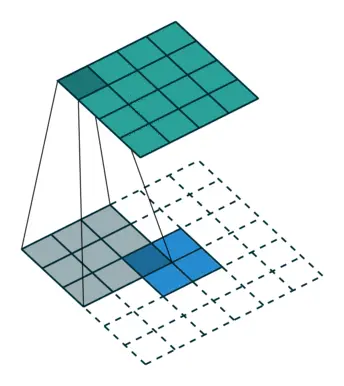
3、空洞卷积(膨胀卷积)(Dilated Convolution / Atrous Convolution)
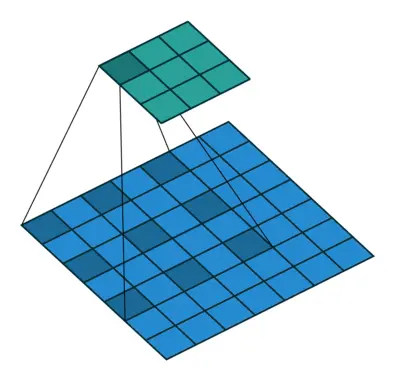
为扩大感受野,在卷积核里面的元素之间插入空格来“膨胀”内核,形成“空洞卷积”(或称膨胀卷积),并用膨胀率参数L表示要扩大内核的范围,即在内核元素之间插入L-1个空格。当L=1时,则内核元素之间没有插入空格,变为标准卷积。如下图为膨胀率L=2的空洞卷积:
4、可分离卷积(Separable Convolutions)
(1)空间可分离卷积(Spatially Separable Convolutions)
空间可分离卷积是将卷积核分解为两项独立的核分别进行操作。一个3x3的卷积核分解如下图:
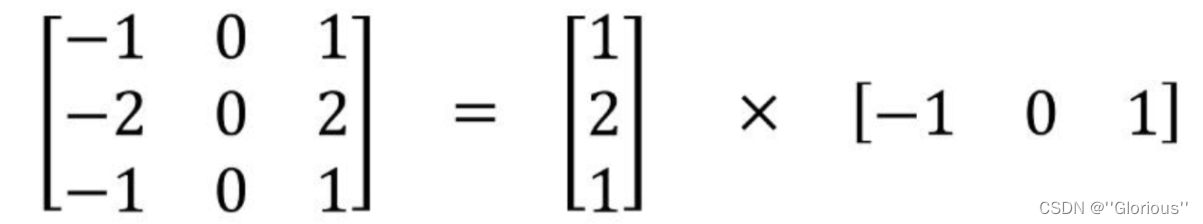
分解后的卷积计算过程如下图,先用3x1的卷积核作横向扫描计算,再用1x3的卷积核作纵向扫描计算,最后得到结果。采用可分离卷积的计算量比标准卷积要少。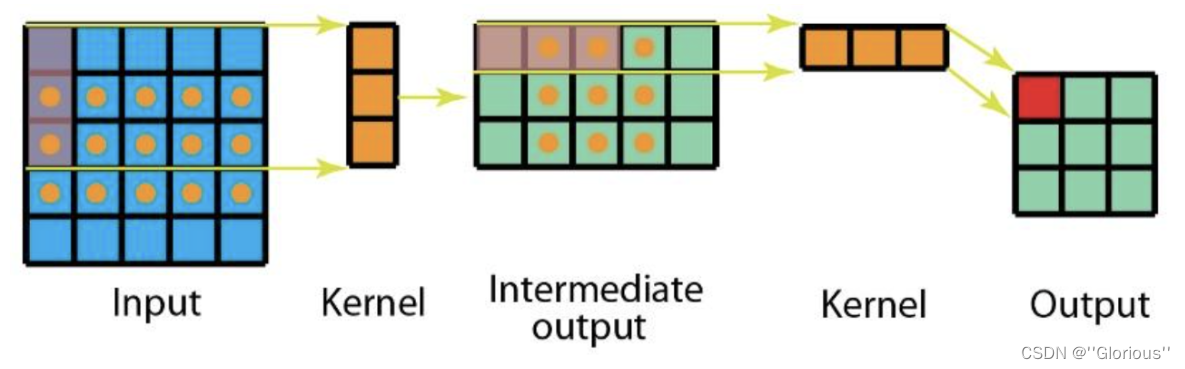
(2)深度可分离卷积(Depthwise Separable Convolutions)
深度可分离卷积由两步组成:深度卷积和1x1卷积。
首先,在输入层上应用深度卷积。如下图,使用3个卷积核分别对输入层的3个通道作卷积计算,再堆叠在一起。
再使用1x1的卷积(3个通道)进行计算,得到只有1个通道的结果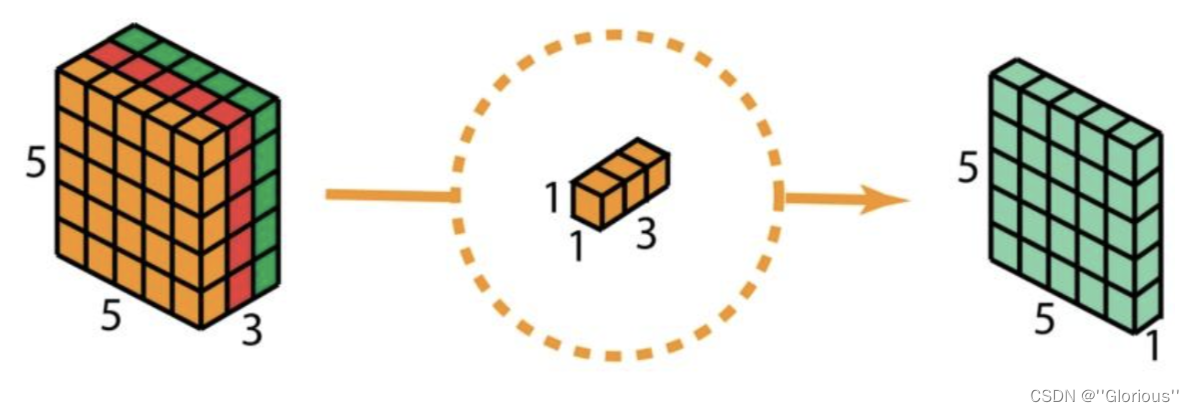
重复多次1x1的卷积操作(如下图为128次),则最后便会得到一个深度的卷积结果。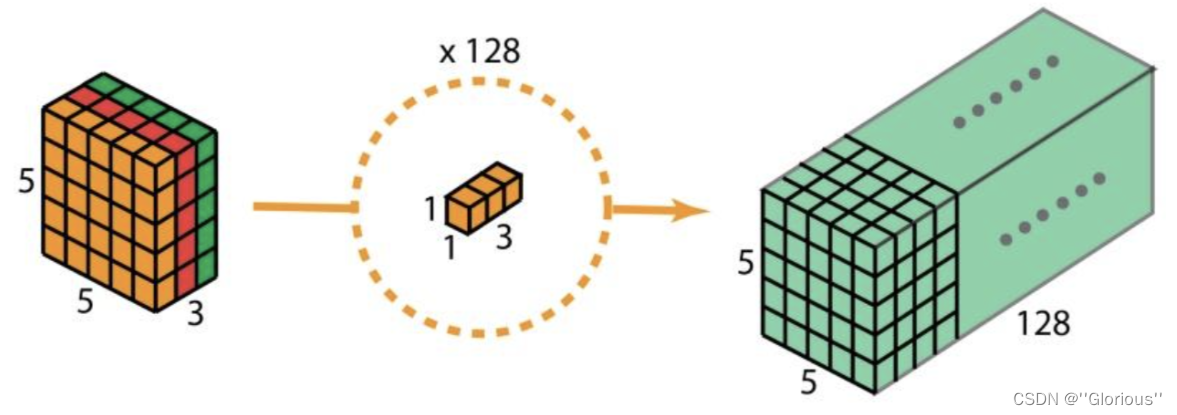
完整的过程如下:

5、扁平卷积(Flattened convolutions)
扁平卷积是将标准卷积核拆分为3个1x1的卷积核,然后再分别对输入层进行卷积计算。这种方式,跟前面的“空间可分离卷积”类似,如下图:
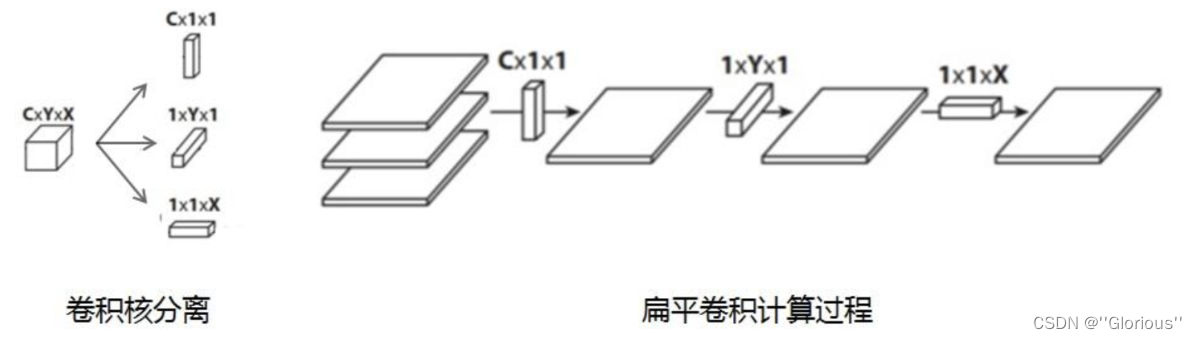
6、分组卷积(Grouped Convolution)
2012年,AlexNet论文中最先提出来的概念,当时主要为了解决GPU显存不足问题,将卷积分组后放到两个GPU并行执行。
在分组卷积中,卷积核被分成不同的组,每组负责对相应的输入层进行卷积计算,最后再进行合并。如下图,卷积核被分成前后两个组,前半部分的卷积组负责处理前半部分的输入层,后半部分的卷积组负责处理后半部分的输入层,最后将结果合并组合。

7、混洗分组卷积(Shuffled Grouped Convolution)
在分组卷积中,卷积核被分成多个组后,输入层卷积计算的结果仍按照原先的顺序进行合并组合,这就阻碍了模型在训练期间特征信息在通道组之间流动,同时还削弱了特征表示。而混洗分组卷积,便是将分组卷积后的计算结果混合交叉在一起输出。
如下图,在第一层分组卷积(GConv1)计算后,得到的特征图先进行拆组,再混合交叉,形成新的结果输入到第二层分组卷积(GConv2)中:

四、卷积、池化、空洞卷积的输入输出大小计算公式
(1)卷积对于卷积经过某层后的特征图大小计算方式:
h2 = (h1-k+2p)/s + 1 w2 = (w1-k+2p)/s + 1
总结:卷积输出大小=[(输入大小-卷积核大小+2*Padding)/步长]+1
所以当stride为1时,当卷积核的大小比padding的两倍大1时,可以不改变特征图的尺寸,只改变通道数。
(2)池化对于池化:
H=(H-K)/S+1 W=(W-K)/S+1
总结:池化输出大小=[(输入大小-卷积核大小)/步长]+1
(3)空洞卷积空洞卷积的等效卷积核大小:
ke = k + (k − 1)(r − 1)
k为原始卷积核大小,r为diarate参数。输出计算同卷积运算。
注意:卷积(除不尽)向下取整,池化(除不尽)向上取整。
五、常规卷积和深度可分离卷积的参数量
普通卷积:3x3x3x4=108
3x3是卷积核尺寸,3是输入图片通道数目,4是输出卷积核的个数。
深度可分离卷积:
DW:3x3x3x1=27
这里卷积核个数其实只设置为1。会形成3张feature map
PW:1x1x3x4=12
1x1为卷积核的尺寸,3为上一层feature map的数量,4为最终需要的维度。其实这里我们也得到了4维的feature map。
total: 27+12=39
明显可以看到,深度可分离卷积计算量比普通卷积小很多,只有其近三分之一的计算量。
六、反池化原理
反池化是池化的逆操作,是无法通过池化的结果还原出全部的原始数据。因为池化的过程就只保留了主要信息,舍去部分信息。如果想从池化后的这些主要信息恢复出全部信息,则存在信息缺失,这时只能通过补位来实现最大程度的信息完整。
池化有两种:最大池化和平均池化,其反池化也需要与其对应。
1、 平均池化和反平均池化
首先还原成原来的大小,然后将池化结果中的每个值都填入其对应原始数据区域中相应位置即可。
平均池化和反平均池化的过程如下:
2、 最大池化和反最大池化
要求在池化过程中记录最大激活值的坐标位置,然后在反池化时,只把池化过程中最大激活值所在位置坐标值激活,其他的值设置为0.当然,这个过程只是一种近似。因为在池化过程中,除了最大值的位置,其他的值也是不为0的。
最大池化和反最大池化的过程如下:
七、CNN有什么特点和优势?
CNN的使用范围是具有局部空间相关性的数据,比如图像、自然语言、语音。
局部连接(稀疏连接):可以提取局部特征
权值共享:减少参数数量,降低训练难度,避免过拟合,提升模型“平移不变性”
降维:通过池化或卷积stride实现
多层次结构:将低层次的局部特征组合成较高层次的特征,不同层级的特征可以对应不同任务
八、池化层的作用
池化层大大降低了网络模型参数和计算成本,也在一定程度上降低了网络过拟合的风险。概括来说,池化层主要有以下五点作用:
- 增大网络感受野
- 抑制噪声,降低信息冗余
- 降低模型计算量,降低网络优化难度,防止网络过拟合
- 使模型对输入图像中的特征位置变化更加鲁棒
九、常见的池化类型
1. Max Pooling(最大池化)
定义:
最大池化(Max Pooling)是将输入的图像划分为若干个矩形区域,对每个子区域输出最大值。
如下图所示,表示的就是对一个4x4的特征图邻域内的值,用一个2x2的filter,步长为2进行“扫描”,选择最大值输出到下一层,这叫做最大池化。
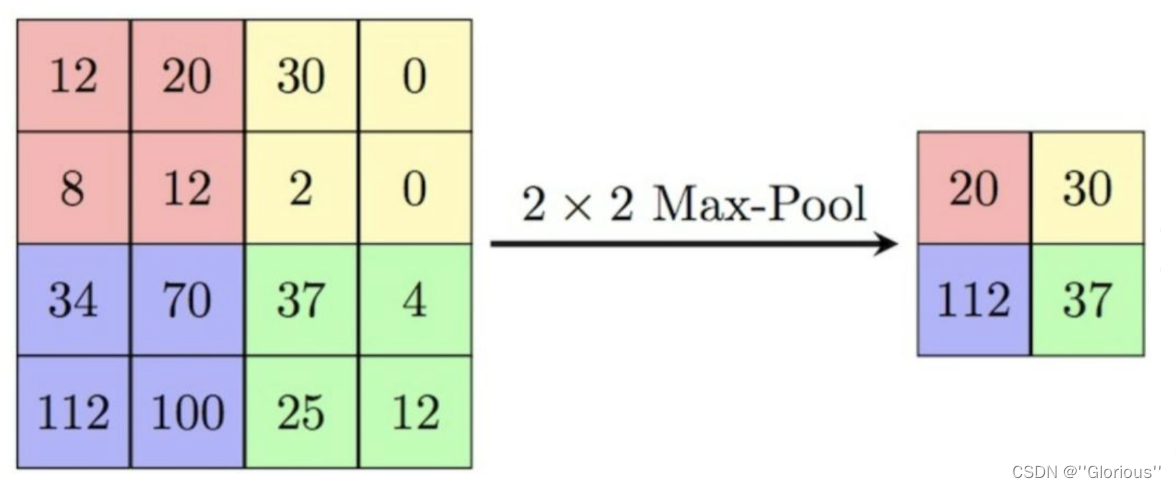
解说:
对于最大池化操作,只选择每个矩形区域中的最大值进入下一层,而其他元素将不会进入下一层。所以最大池化提取特征图中响应最强烈的部分进入下一层,这种方式摒弃了网络中大量的冗余信息,使得网络更容易被优化。同时这种操作方式也常常丢失了一些特征图中的细节信息,所以最大池化更多保留些图像的纹理信息。
2. Average Pooling(平均池化)
定义:
平均池化(Average Pooling)是将输入的图像划分为若干个矩形区域,对每个子区域输出所有元素的平均值。
如下图下所示,表示的就是对一个4x4的特征图邻域内的值,用一个2x2的filter,步长为2进行“扫描”,对区域内元素取平均,将平均值输出到下一层,这叫做平均池化。

解说:
平均池化取每个矩形区域中的平均值,可以提取特征图中所有特征的信息进入下一层,而不像最大池化只保留值最大的特征,所以平均池化可以更多保留些图像的背景信息。
3.Global Average Pooling(全局平均池化)
背景:
在卷积神经网络训练初期,卷积层通过池化层后一般要接多个全连接层进行降维,最后再Softmax分类,这种做法使得全连接层参数很多,降低了网络训练速度,且容易出现过拟合的情况。在这种背景下,M Lin等人提出使用全局平均池化Global Average Pooling来取代最后的全连接层。用很小的计算代价实现了降维,更重要的是GAP极大减少了网络参数(CNN网络中全连接层占据了很大的参数)。
定义:
全局平均池化是一种特殊的平均池化,只不过它不划分若干矩形区域,而是将整个特征图中所有的元素取平均输出到下一层。
解说:
作为全连接层的替代操作,GAP对整个网络在结构上做正则化防止过拟合,直接剔除了全连接层中黑箱的特征,直接赋予了每个channel实际的类别意义。除此之外,使用GAP代替全连接层,可以实现任意图像大小的输入,而GAP对整个特征图求平均值,也可以用来提取全局上下文信息,全局信息作为指导进一步增强网络性能。
4. Mix Pooling(混合池化)
定义:
为了提高训练较大CNN模型的正则化性能,受Dropout(将一半激活函数随机设置为0)的启发,Dingjun Yu等人提出了一种随机池化Mix Pooling的方法,随机池化用随机过程代替了常规的确定性池化操作,在模型训练期间随机采用了最大池化和平均池化方法,并在一定程度上有助于防止网络过拟合现象。其定义如下:
其中,是0或1的随机值,表示选择使用最大池化或平均池化,换句话说,混合池化以随机方式改变了池调节的规则,这将在一定程度上解决最大池和平均池所遇到的问题。
解说:
混合池化优于传统的最大池化和平均池化方法,并可以解决过拟合问题来提高分类精度。此外该方法所需要的计算开销可忽略不计,而无需任何超参数进行调整,可被广泛运用于CNN。
5. Stochastic Pooling(随机池化)
定义:
随机池化**Stochastic Pooling[3]**是Zeiler等人于ICLR2013提出的一种池化操作。随机池化的计算过程如下:
先将方格中的元素同时除以它们的和sum,得到概率矩阵。
按照概率随机选中方格。
pooling得到的值就是方格位置的值。
假设特征图中Pooling区域元素值如下(参考Stochastic Pooling简单理解):
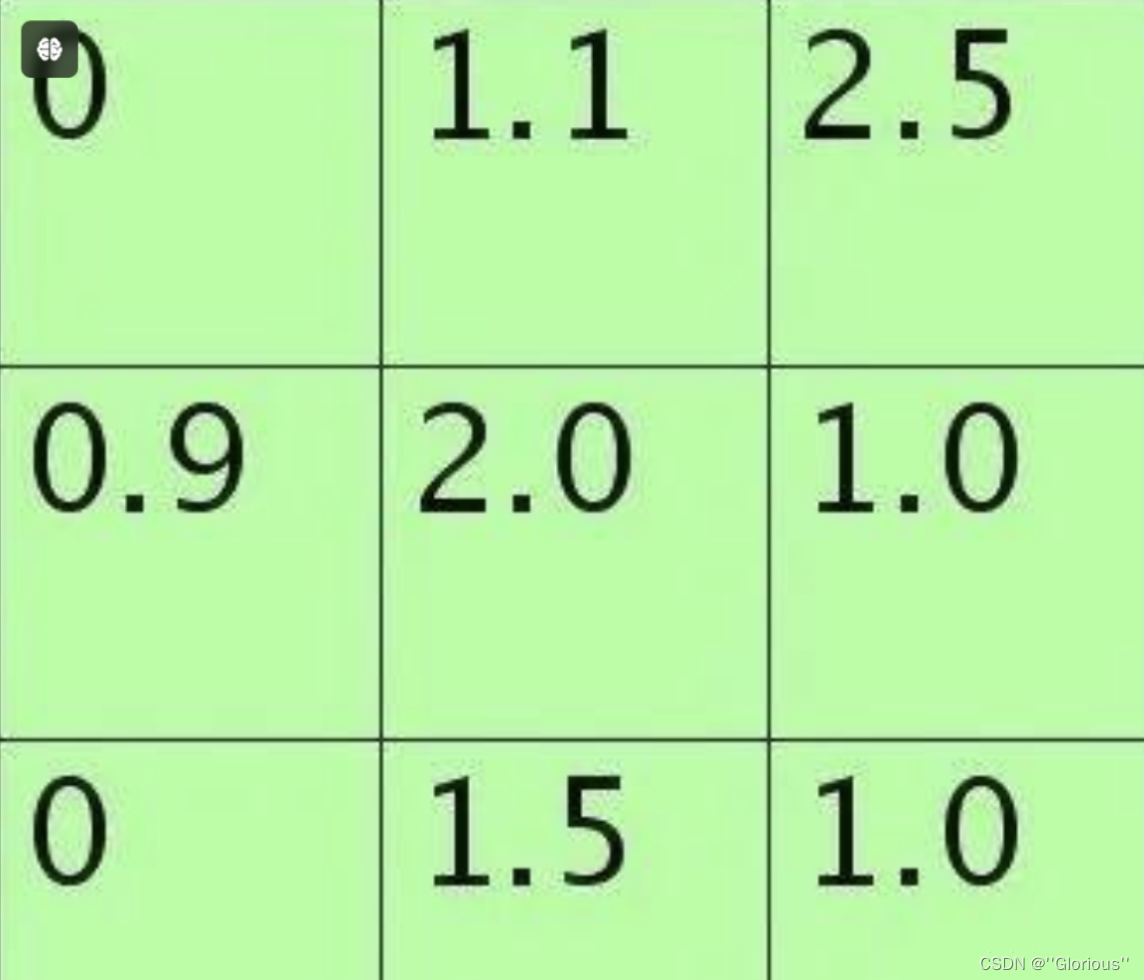
3×3大小的,元素值和sum=0+1.1+2.5+0.9+2.0+1.0+0+1.5+1.0=10。方格中的元素同时除以sum后得到的矩阵元素为:
每个元素值表示对应位置处值的概率,现在只需要按照该概率来随机选一个,方法是:将其看作是9个变量的多项式分布,然后对该多项式分布采样即可,theano中有直接的multinomial()来函数完成。当然也可以自己用0-1均匀分布来采样,将单位长度1按照那9个概率值分成9个区间(概率越大,覆盖的区域越长,每个区间对应一个位置),然随机生成一个数后看它落在哪个区间。比如如果随机采样后的矩阵为:
则这时候的poolng值为1.5。使用stochastic pooling时(即test过程),其推理过程也很简单,对矩阵区域求加权平均即可。比如对上面的例子求值过程为为:
说明此时对小矩形pooling后的结果为1.625。在反向传播求导时,只需保留前向传播已经记录被选中节点的位置的值,其它值都为0,这和max-pooling的反向传播非常类似。本小节参考**Stochastic Pooling简单理解[4]**。
解说:
随机池化只需对特征图中的元素按照其概率值大小随机选择,即元素值大的被选中的概率也大,而不像max-pooling那样,永远只取那个最大值元素,这使得随机池化具有更强的泛化能力。















 563
563











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









