






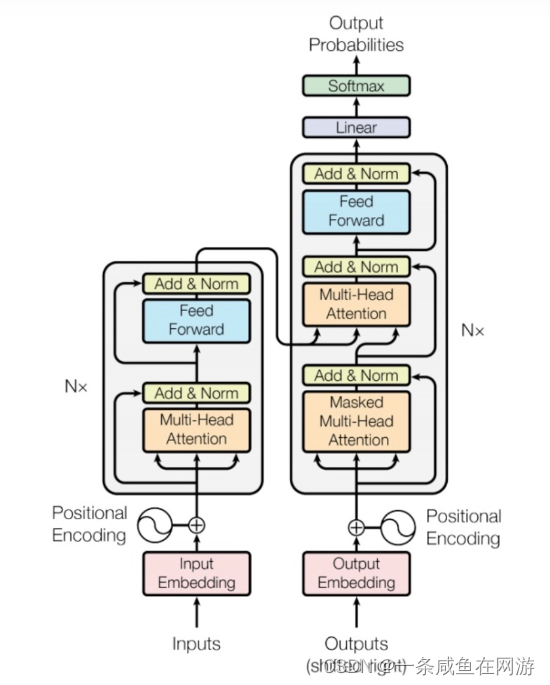
原理学习:
(3条消息) The Illustrated Transformer【译】_于建民的博客-CSDN博客
代码学习:
https://github.com/jadore801120/attention-is-all-you-need-pytorch/tree/master/transformer
mask学习:
(3条消息) NLP 中的Mask全解_mask在自然语言处理代表什么_郝伟博士的博客-CSDN博客
多头注意力机制学习:
【1】代码:
class MultiHeadAttention(nn.Module):
''' Multi-Head Attention module '''
def __init__(self, n_head, d_model, d_k, d_v, dropout=0.1):
super().__init__()
self.n_head = n_head
self.d_k = d_k
self.d_v = d_v
self.w_qs = nn.Linear(d_model, n_head * d_k, bias=False)
self.w_ks = nn.Linear(d_model, n_head * d_k, bias=False)
self.w_vs = nn.Linear(d_model, n_head * d_v, bias=False)
self.fc = nn.Linear(n_head * d_v, d_model, bias=False)
self.attention = ScaledDotProductAttention(temperature=d_k ** 0.5)
self.dropout = nn.Dropout(dropout)
self.layer_norm = nn.LayerNorm(d_model, eps=1e-6)
def forward(self, q, k, v, mask=None):
d_k, d_v, n_head = self.d_k, self.d_v, self.n_head
sz_b, len_q, len_k, len_v = q.size(0), q.size(1), k.size(1), v.size(1)
residual = q
# Pass through the pre-attention projection: b x lq x (n*dv)
# Separate different heads: b x lq x n x dv
q = self.w_qs(q).view(sz_b, len_q, n_head, d_k)
k = self.w_ks(k).view(sz_b, len_k, n_head, d_k)
v = self.w_vs(v).view(sz_b, len_v, n_head, d_v)
# Transpose for attention dot product: b x n x lq x dv
q, k, v = q.transpose(1, 2), k.transpose(1, 2), v.transpose(1, 2)
if mask is not None:
mask = mask.unsqueeze(1) # For head axis broadcasting.
q, attn = self.attention(q, k, v, mask=mask)
# Transpose to move the head dimension back: b x lq x n x dv
# Combine the last two dimensions to concatenate all the heads together: b x lq x (n*dv)
q = q.transpose(1, 2).contiguous().view(sz_b, len_q, -1)
q = self.dropout(self.fc(q))
q += residual
q = self.layer_norm(q)
return q, attn【2】解读代码:
定义了一个名为
MultiHeadAttention的类,继承自nn.Module。该类实现了多头注意力模块。在初始化方法
__init__中,接受了一些参数:n_head(注意力头数)、d_model(模型维度)、d_k(查询和键的维度)、d_v(值的维度)和dropout(dropout 比率)。首先,这些参数被存储在对应的类属性中。
然后,定义了四个线性变换层
w_qs、w_ks、w_vs和fc。这些变换层将输入数据投影到不同的维度上,以用于多头注意力的计算。接下来,创建了一个
ScaledDotProductAttention类的实例self.attention。这个类尚未提供代码,但根据命名可以猜测是实现了缩放点积注意力机制。然后,创建了一个
nn.Dropout类的实例self.dropout,用于进行 dropout 操作。最后,创建了一个
nn.LayerNorm类的实例self.layer_norm,用于进行层归一化操作。在前向传播方法
forward中,首先从类属性中获取各个维度的大小,并保存在局部变量中。然后,将输入
q复制给residual,以便后面进行残差连接操作。接下来,将输入
q、k和v分别通过线性变换层w_qs、w_ks和w_vs进行线性变换,并调整维度以适应多头注意力的计算。通过调用线性变换层的方法,将输入数据分别投影到多个注意力头的维度上,得到的结果维度为
(sz_b, len_q, n_head, d_k)、(sz_b, len_k, n_head, d_k)和(sz_b, len_v, n_head, d_v)。对于进行注意力计算的维度调整,需要将
q、k和v的维度进行转置,以便后续进行点积操作。如果提供了掩码
mask,则将其增加一个维度使其与注意力张量的维度相匹配。调用
self.attention的前向传播函数,对输入的q、k和v进行多头注意力计算。得到计算后的注意力张量
q和注意力权重attn。根据多头注意力计算的结果,对
q进行维度转置和重塑,然后通过线性变换层fc进行线性变换,并进行 dropout 操作。接下来,将残差连接操作的结果与处理后的
q相加,得到多头注意力模块的输出。最后,对输出进行层归一化操作,并返回输出结果和注意力权重。
希望以上解释能够帮助到您理解这段代码的工作原理。如果还有其他问题,请随时提问。
【3】代码:
class Transformer(nn.Module):
def __init__(self, feature_dim, num_heads, num_layers,drop_p):
super(Transformer, self).__init__()
self.num_layers = num_layers
self.self_attention_layers = nn.ModuleList([
SelfAttention(feature_dim, num_heads)
for _ in range(num_layers)
])
self.feed_forward_layers = nn.ModuleList([
nn.Sequential(
nn.Dropout(p=drop_p),
nn.Linear(feature_dim, feature_dim))
for _ in range(num_layers)
])
self.norm=nn.LayerNorm(feature_dim)
def forward(self, x):
for layer_idx in range(self.num_layers):
attention_output = self.self_attention_layers[layer_idx](x)
x = self.norm(x + attention_output)
feed_forward_output = self.feed_forward_layers[layer_idx](x)
x = self.norm(x + feed_forward_output)
return x
class SelfAttention(nn.Module):
def __init__(self, feature_dim, num_heads):
super(SelfAttention, self).__init__()
self.num_heads = num_heads
self.feature_dim=feature_dim
self.query = nn.Linear(feature_dim, feature_dim)
self.key = nn.Linear(feature_dim, feature_dim)
self.value = nn.Linear(feature_dim, feature_dim)
self.concat_projection = nn.Linear(feature_dim, feature_dim)
def forward(self, x):
q = self.query(x)
k = self.key(x)
v = self.value(x)
query = self.split_heads(q)
key = self.split_heads(k)
value = self.split_heads(v)
scores = torch.matmul(query, key.transpose(-1, -2))
scaled_scores = scores / torch.sqrt(torch.tensor(self.feature_dim / self.num_heads))
attention_weights = torch.softmax(scaled_scores, dim=-1)
attention_output = torch.matmul(attention_weights, value)
attention_output = self.concat_heads(attention_output)
return attention_output
def split_heads(self, x):
batch_size, seq_len, _ = x.size()
x_ = x.view(batch_size, seq_len, self.num_heads, self.feature_dim // self.num_heads)
x_ = x_.permute(0, 2, 1, 3)
return x_
def concat_heads(self, x):
batch_size, _, seq_len, _ = x.size()
x = x.permute(0, 2, 1, 3).contiguous()
x = x.view(batch_size, seq_len, self.feature_dim)
x = self.concat_projection(x)
return x【4】与【1】代码的区别:
这两种方法都是为了在模型中使用多头注意力机制,处理输入数据并计算注意力权重。它们的目标都是将输入数据分割为多个部分,每个部分对应一个注意力头,然后对每个部分进行投影转换。
不同之处在于具体的实现方式:
第一种方法中,每个注意力头有独立的权重参数,也就是说,每个注意力头都有自己的“专属”线性变换层。这样做的好处是可以对每个注意力头进行单独的处理,使其更具灵活性,以适应不同的任务需求。
第二种方法中,所有的注意力头共享相同的权重参数,使用统一的线性变换层来处理输入数据。这样做的好处是减少了模型的参数量,提高了计算效率,但也可能限制了每个注意力头的个性化表达能力。
更通俗来讲区别就是:
第一种 多头,每一头的数据不一样,第二这种 多头 每一头的数据都一样
第一种: 数据x 分为多头就是 heads1--->x heads2--->x
第二种:数据x 分为多头就是 heads1---->x/num_heads















 228
228

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









