






Redis 持久化
文章目录
一、RDB
1. 什么是RDB?
RDB(Redis DataBase)是一种定期的备份策略。RDB 持久化是把当前内存数据⽣成快照保存到硬盘的过程,触发 RDB 持久化过程分为手动触发和⾃动触发。
2. RDB 的触发机制
RDB 的触发机制分为自动触发和手动触发.
1)手动触发
手动触发 分别对应于 save 和 bgsave 命令:
-
save 命令
save 手动触发会阻塞当前的 Redis 服务器,直到 RDB 过程完成为止,对于内存比较大的实例造成长时间阻塞,基本不采用。 -
bgsave 命令
Redis 进程执行执行 fork 操作创建子进程,RDB 持久化过程由子进程负责执行,完成后自动结束。阻塞只发生在 fork 阶段。
Redis 内部的所有涉及到 RDB 的操作都采用类似于 bgsave 的方式执行。
2)自动触发
对于程序员来说,手动触发的方式虽然可以保证 Redis 的持久化,但是既然是手动的,那么就存在数据写入之后忘记执行 save 命令的风险或者执行过程中,Redis 服务器宕机的问题,因此 Redis 服务器还提供了自动触发机制,这个触发机制才是实战中最有价值的。
自动触发的时机:
-
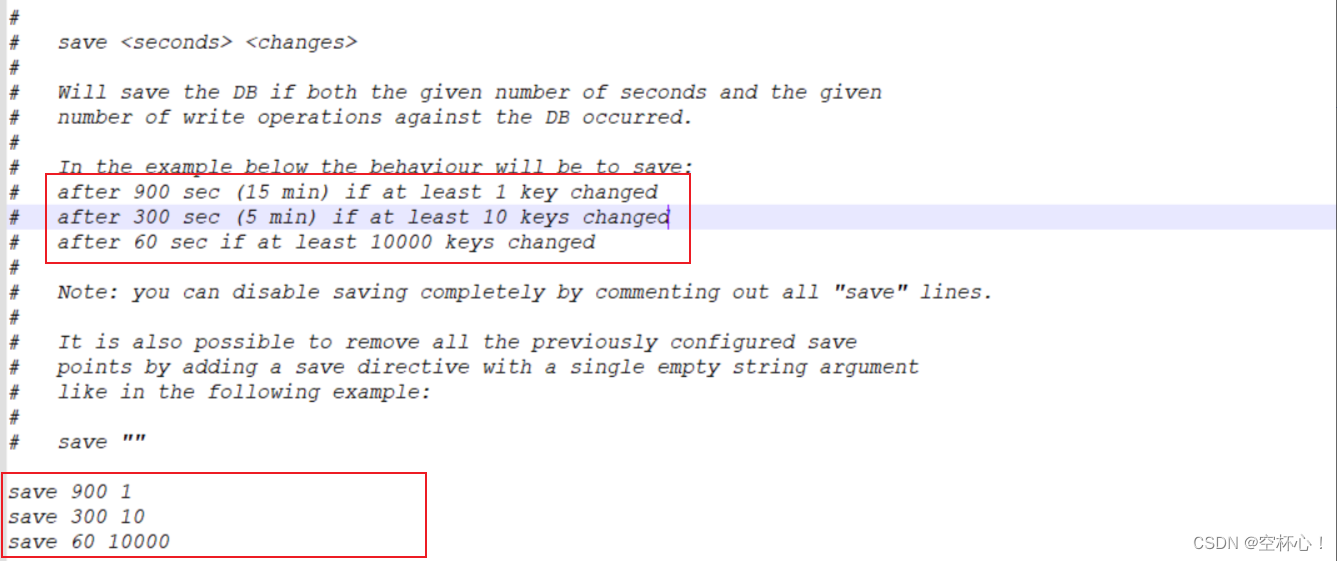
使用 save 配置
如使用 “save m n” 配置,表示 m 秒内数据发生了 n 次修改,会触发 RDB 持久化。
-
从节点进行全量复制操作时,主节点自动进行 RDB 持久化,随后将 RDB 文件的内容发送给从节点。
3. 执行 shutdown 命令关闭 Redis时,触发 RDB 持久化。
通过 shutdown 命令(Redis 中的一个命令) 关闭服务器,会触发 RDB 持久化,service redis-server restart 正常重启 Redis 服务器也会触发 RDB 持久化。通过正常的流程关闭或者重启 Redis 服务器,Redis 会在退出时,自动生成 RDB 的操作,但是如果是异常重启 Redis 服务器,此时 Redis 服务器就来不及生成 RDB 文件,内存中尚未保存到快照中的数据,就会随着 Redis 服务器的重启而丢失,因为 Redis 是基于内存的存储系统,比如执行 kill -9 redis进程或者 Redis断电重启。
3)bgsave 的执行流程
bgsave 是主流的持久化方式,它的执行流程如下:
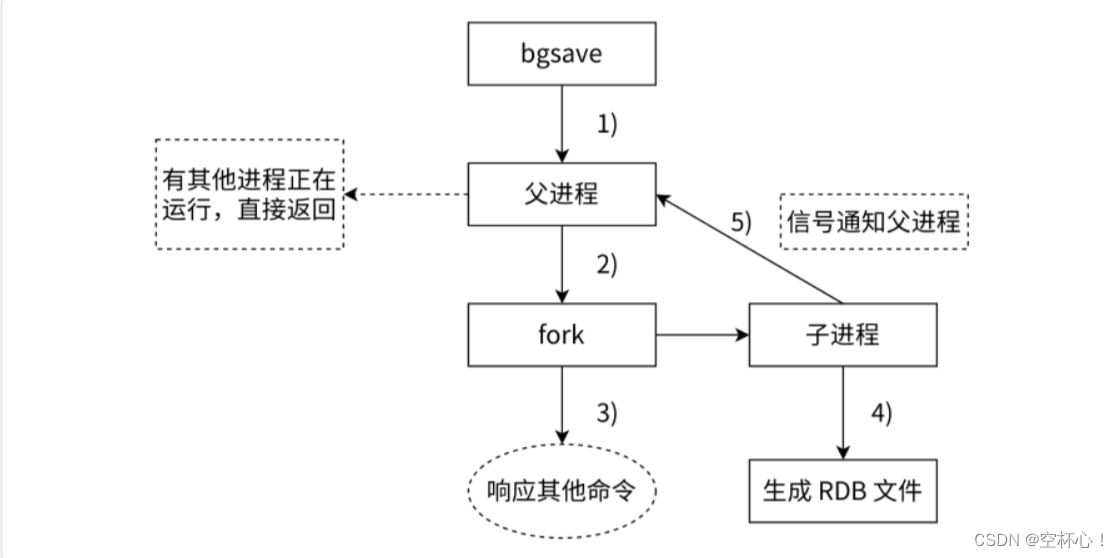
- 执行 bgsave 命令,Redis 父进程判断当前进程是否存在其他正在执行的子进程,如 RDB/AOF 子进程,如果存在 bgsave 命令直接返回。
- 如果当前没有其他工作的子进程,那么父进程执行 fork 操作,创建子进程,fork 过程中,父进程会阻塞,通过 info stats 命令查看 latest_fork_usec 选项,可以获取最近一次 fork 操作的耗时,单位为微秒。
- 父进程 fork 完成之后,bgsave 命令会返回 “background saving started” 信息,并不再阻塞父进程,可以继续响应其他命令。
- 子进程创建 RDB 文件,根据父进程在内存中生成的数据生成临时快照,完成后会对原有的 RDB 文件进行原子替换。执行 lastsave 命令后可以获取最后一次生成 RDB 文件的时间,对应 info 统计的 rdb_last_save_time 选项。
- 子进程发送信号给父进程,告诉父进程 RDB 持久化完成,父进程更新统计信息。
补充:
fork 是 linux 系统提供的一个创建子进程的 API(系统调用),如果是其他的系统,比如 Windows,创建子进程就不是 fork 了。fork 创建子进程的方式简单粗暴,直接把当前的进程(父进程)复制一份给子进程(包括 pcb、虚拟地址空间(内存中的数据)、文件描述符表等);一旦复制完成,父子进程就是两个独立的进程,就各自执行各自的了。本来 Redis server 中,有若干变量,保存了一些键值对数据,随着这样的 fork 的进行,子进程的这个内存里也会存在和刚才父进程中一模一样的变量;因此,复制出来的这个"克隆体"(子进程)的内存中的数据就是和"本体"(父进程)是一样的,接下来安排子进程去执行"持久化"操作,也就是相当于把父进程本体这里的数据给持久化了。如果父进程打开了一个文件,fork 了之后,子进程也是可以同样使用这个文件的,也就导致了子进程持久化写入的那个文件和父进程本来要写的文件是同一个了。
- 如果当前 Redis 服务器中存储的数据特别多,内存消耗特别大(比如说 100GB),此时,进行上述的赋值操作,是否会有很大的性能开销???
此处的性能开销,其实挺小的,fork 在进行内存拷贝的时候不是简单无脑的直接把所有数据都拷贝一遍,而是"写时拷贝"的机制来完成的;如果子进程里的内存数据,和父进程的内存数据完全一样,此时就不会触发真正的拷贝动作(而是爷俩使用同一份内存数据),但是,实际上这俩进程的内存空间应该是各自独立的,一旦某一方对这个内存数据进行了修改,就会立即触发真正的物理内存上的数据拷贝。在 bgsave 这个场景中,绝大部分的内存数据,是不需要改变的(整体来说这个过程执行的还挺快的,这个短时间内,父进程中不会有大批的内存数据的变化),因此子进程的"写时拷贝"并不会触发很多次,也就保证了整体的"拷贝时间"是可控的、高效的。
3. RDB 文件处理
1)保存
RDB ⽂件保存在 dir 配置指定的⽬录(默认 /var/lib/redis/)下,⽂件名通过 dbfilename 配置指定(默认文件名是 dump.rdb)。可以通过执⾏ config set dir {newDir} 和 config set dbfilename{newFilename} 运⾏期间动态执⾏,当下次运⾏时 RDB ⽂件会保存到新⽬录。

2)压缩
Redis 默认采⽤ LZF 算法对⽣成的 RDB ⽂件做压缩处理,压缩后的⽂件远远小于内存⼤小,默认开启,可以通过参数 config set rdbcompression {yes|no} 动态修改。

虽然压缩 RDB 文件会消耗 CPU,但可以⼤幅降低⽂件的体积,方便保存到硬盘或通过网络发送到从节点,因此建议开启。
3)校验
如果 Redis 启动时加载到损坏的 RDB ⽂件会拒绝启动。这时可以使⽤ Redis 提供的 redis-check-dump ⼯具检测 RDB ⽂件并获取对应的错误报告。
4. RDB 的缺点
优点:
- RDB 是⼀个紧凑压缩的⼆进制⽂件,代表 Redis 在某个时间点上的数据快照。非常适用于备份,全量复制等场景。比如每 6 小时执⾏ bgsave 备份,并把 RDB ⽂件复制到远程机器或者⽂件系统中(如 hdfs)用于灾备。
- Redis 加载 RDB 文件恢复数据远远快于 AOF 的⽅式。
缺点:
- RDB ⽅式数据没办法做到实时持久化 / 秒级持久化。因为 bgsave 每次运⾏都要执行 fork 创建⼦进程,属于重量级操作,频繁执⾏成本过⾼。
- RDB ⽂件使⽤特定⼆进制格式保存,Redis 版本演进过程中有多个 RDB 版本,多个版本间的 Redis 的 RDB 文件的兼容性可能有风险。
二、AOF
1. 什么是 AOF ?
AOF(append Only File)是一种实时备份策略。AOF(Append Only File)持久化:以独立日志的方式记录每次写入数据的命令,每次进行写入操作时,将写入命令追加到 AOF 文件的末尾,重启时再重新执行 AOF 文件中的命令,达到恢复数据的⽬的。
AOF 持久化方式的出现,主要是为了解决解决 RDB 持久化方式无法保证数据持久化的实时性问题,⽬前 AOF 持久化方式已经是 Redis 持久化的主流⽅式。理解掌握好 AOF 持久化机制对我们兼顾数据安全性和性能非常有帮助。
2. AOF 的工作流程
Redis 虽然是基于单线程的服务器,但是执行的速度却很快,很快的原因重要原因,就是因为 Redis 只是操作内存,那么引入 AOF 持久化机制之后,不仅要修改内存中的数据,又要将数据持久化到硬盘中,还能保证和为未持久化之前一样的执行速度吗?
实际上是没有影响的,AOF 持久化并没有直接影响到 Redis 处理请求的速度,主要是因为:
- AOF 机制并非是直接让工作线程把数据写入硬盘,而是将数据先写入到一个内存的缓冲区,积累一定的量之后,再统一写入到硬盘。这样就可以大大降低写入磁盘的次数。比如说,假设有 100 个请求,100 个请求的数据一次写入硬盘的速度比 100 个请求的数据写入 100 次硬盘的速度要快很多。写入硬盘的时候,写入硬盘数据的多少,对于性能的影响没有很大,但是写入硬盘的次数对于速度的影响就会很大。
- 硬盘上读写数据,顺序读写的速度是比较快的,随机访问的速度则是比较慢的,AOF 持久化每次把新的操作写入到原文件的末尾,属于是顺序写入,所以读取的时候也是顺序读写,速度会比较快。
工作流程:
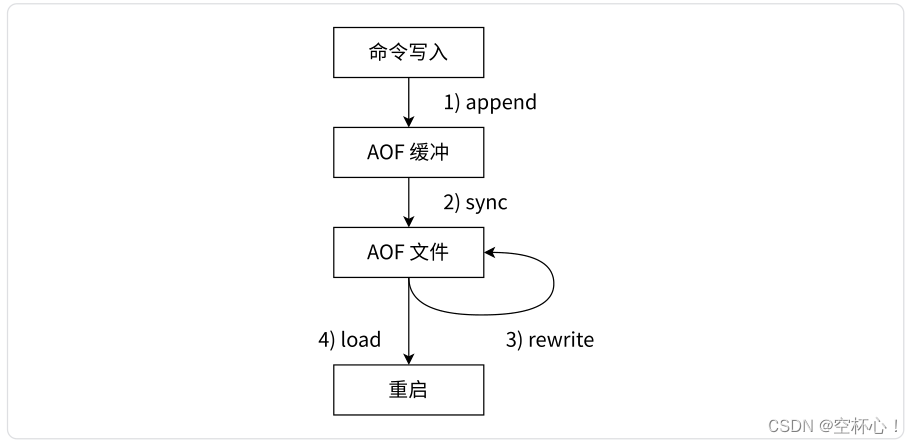
- 所有写入命令会追加到 aof_buf (缓冲区) 中。
- AOF 缓冲区根据对应的重写策略向硬盘做同步操作。
- 随着 AOF 文件越来越大,需要定期对 AOF文件进行重写,达到压缩文件大小的目的。
- 当 Redis 服务器启动时,可以加载 AOF 文件进行数据恢复。
3. AOF 缓冲区刷新策略
虽然可以把数据先写入到缓冲区,再把缓冲区的数据写入到硬盘以提高数据写入硬盘的速度。但是缓冲区的本质还是内存的一部分,万一这个时候,突然进程挂了,或者主机掉电了,意味着缓冲区中的数据也就丢了,因为缓冲区的数据还没来得及写入硬盘的数据是会丢失的。因此 Redis 给出了一些选项,让程序员根据实际情况俩决定怎么取舍缓冲区的刷新策略;当然刷新频率和快慢是会直接影响到性能的。
- 刷新频率越快,性能影响就很大,同时数据的可靠性就越高;
- 刷新频率越慢,性能影响就小,数据的可靠性就越低;
Redis 提供了多种 AOF 缓冲区同步文件策略,由参数 appendfsync 控制,不同值表示不同的含义:
| 可配置项 | 说明 | 性能 |
|---|---|---|
| always | 命令写入 aof_buf 后调用 fsync 同步,完成后返回 | 频率最高,数据可靠性最高,性能最低 |
| everysec | 命令写入 aof_buf 后只执行 write 操作,不进行 fsync,每秒由同步线程进行 fsync | 频率低一些,数据可靠性也会降低,性能会提高 |
| no | 命令写入 aof_buf 后只执行 write 操作,由操作系统控制 fsync 频率 | 频率最低,数据可靠性也是最低的,性能是最高的。 |
4. AOF 的重写机制
AOF 持久化方式是采用在 .aof 文件的末尾追加写入操作命令的方式进行数据记录,那么随着写操作的不断进行,.aof 文件的体积就会越来越大,对于 Redis 服务器来说,Redis 在启动的时候需要读取 .aof 文件,那么就意味着 .aof 文件越大,Redis 服务器在启动的时候花的时间就会越长。并且 .aof 文件中记录的所有的写入操作的命令,那么就以为者文件有一部分的内容是冗余的,例如:
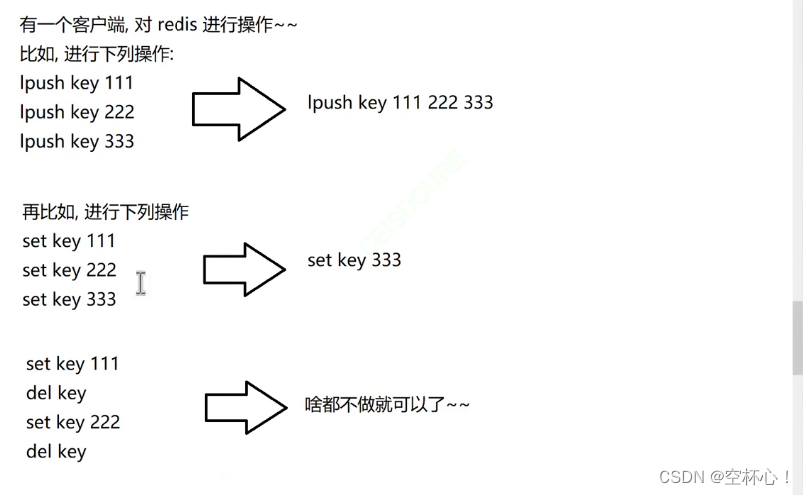
虽然 .aof 文件中记录所有写入操作的命令,但是我们在启动 Redis 服务器的时候并不关注中间写入操作的过程,我们只关心 .aof 文件中记录的最终结果,也就是上述的过程,把相同的操作整理为一条或者多条的指令。因此 Redis 就存在一个机制,能够针对 .aof 文件继续宁整理操作,这个整理能够剔除文件中的冗余操作,并且合并一些操作,达到给 .aof 文件 "瘦身"的效果。这样的机制我们就称为 AOF 的重写机制。
5. AOF 文件重写的触发机制
1)手动触发
执行 bgrewriteaof 命令。
2)自动触发
根据 auto-min-size 和 auto-rewrite-percentage 参数确定自动触发时机:
- auto-aof-rewrite-min-size:表示触发重新写时 AOF 文件的最小文件大小,默认是 64 M.
- auto-aof-rewrite-percentage:代表当前 AOF 占用大小相较于上次重写时增加的比例。
6. AOF 重写的执行流程
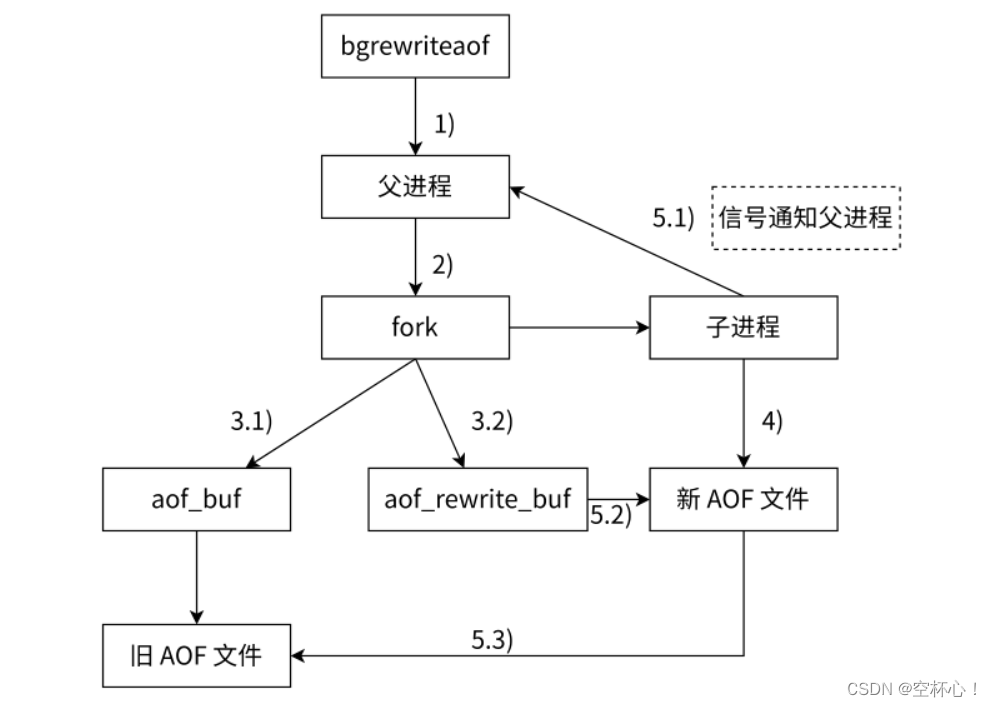
1. 执行 AOF 重写请求
如果当前进程正在执行 AOF 重写,请求不执行。如果当前进程正在执行 bgsave 操作,重写命令延迟到 bgsave 完成之后再执行。
-
父进程执行 fork 创建子进程。
-
重写
a. 主进程 fork 之后,继续响应其他命令。所有的修改操作写入 AOF 缓冲区,并根据 appendfsync 策略同步到硬盘,保证旧 AOF 文件机制正确。b. 子进程只有 fork 之前的所有内存信息,父进程只需要将 fork 之后这段时间的修改操作写入 AOF 重写缓冲区中。
-
子进程根据内存快照,将命令合并到新的 AOF 文件中。
-
子进程完成重写
a. 新文件写入后,子进程发送信号给父进程。
b. 父进程把 AOF 重写缓冲区内临时保存的命令追加到新的 AOF 文件中。
c. 用新的 AOF 文件替换旧的 AOF 文件
注意:
- 和 RDB 的 bgsave 的执行原理一样,AOF 重写机制的执行流程也是通过 fork 创建子进程的方式进行重写,父进程仍然负责接收请求,子进程负责针对 .aof 文件进行重写;**重写的时候,不关心 .aof 文件中原来都有什么命令,只是关心当前内存中最终的数据状态,此时内存中的数据就是 .aof 文件重写后的最终结果,子进程只需要把当前内存中的数据,获取出来,然后以 AOF 文件的格式将数据写入到一个新的 AOF 文件中。内存中的数据的状态,就相当于是把 AOF 文件重写后的结果。**此处子进程写数据的过程,非常类似于 RDB 生成一个镜像快照的过程,只不过 RDB 这里是按照二进制的方式来生成的,AOF 重写,则是按照 AOF 这里要求的文件格式来生成的。但是他们的目的都是一样的,都是为了把当前内存中的数据记录到文件中!!!
- 子进程写新 aof 文件的同时,父进程仍然在不断的接收新的请求。父进程还是会把这些写请求产生的 AOF 数据先写入到缓冲区,再刷新到原有的 AOF 文件里。
- 在创建子进程的一瞬间,子进程就继承了当前父进程的内存状态。因此,子进程里的内存数据是父进程 fork 之前的状态,fork 之后,新来的请求堆内存造成的修改,是子进程不知道的。此时父进程这里有准备一个 aof_rewrite_buf 缓冲区,专门放 fork 之后收到的数据。子进程这边,把 aof 数据写完之后,会通过 信号 通知一下父进程,父进程再把 aof_rewrite_buf 缓冲区中的内容也写入到新的 AOF 文件中,这些过程完成之后,就可以用新的 AOF 文件代替旧得 AOF 文件了。
观察上面的流程,在父进程 fork 完毕之后,就已经让子进程写新的 aof 文件了,并且随着时间的推移,子进程很快就写完了新的 aof 文件,要让新的文件代替 旧的 aof 文件,那么父进程此时还在继续写这个即将消亡的旧的 aof 文件是否还有意义?
答案显然是有意义的,考虑到极端的情况下,假设再重写的过程中,重写一啊不能的时候,服务器挂了,子进程内存的数据就会丢失,新的 aof 文件内容还不完整,所以如果父进程不坚持写旧的 aof 文件,重启的时候就没办法保证数据的完整行了。
7. AOF 的 bgrewriteaof 和 RDB 的 bgsave 的区别
- RDB 是一种定期备份的策略,AOF 是一种实时备份的策略;
- RDB 对于 fork 之后的新数据就置之不理了,AOF 的 bgrewriteaof 则采取了 aof_rewrite_buf 缓冲区的方式进行处理;
为什么 RDB 不也采用这样的方式进行 fork 操作之后的数据处理呢?
其实原因很简单,因为RDB 的本质是定时备份,而 AOF 是实时备份,如果 RDB 也采取这样的方式进行备份,那么它就不符合定时备份的设计理念了。
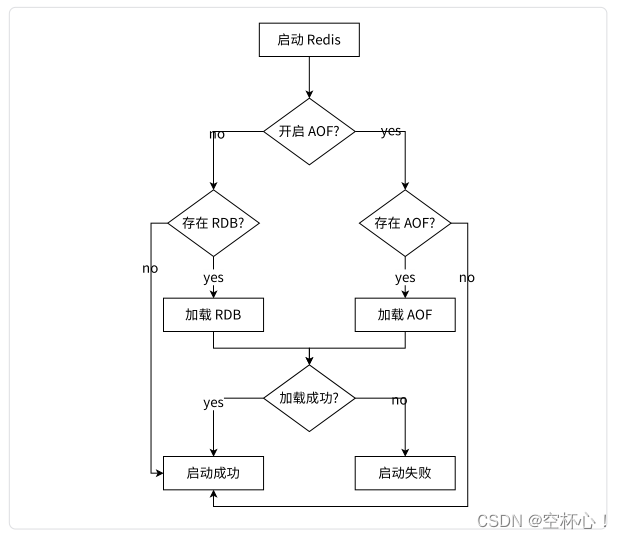
8. 启动时数据恢复
当 Redis 启动时,会根据 RDB 和 AOF 文件的内容,进行数据恢复。当 Redis 中同时存在 aof 文件和 rdb 快照时,以 aof 文件为主!!! rdb 被直接忽略了。














 1984
1984











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









