






经常碰到的20个等待事件
oracle等待事件简介
DBA团队维护的部分应用运行在oracle数据库平台,为及时了解数据库的运行情况,需要建立涵盖各个维度的监控体系,包括实例状态、空间使用率、ORA错误等数十项监控指标。这其中有一个有效判断数据库运行负载是否发生变化、有没有隐患或潜在异常的指标就是等待事件数量,有了它就好比给数据库安装了一个听诊器、温度计,能及时感知脉搏、体温等关键指标变化。
下面我们就来讲讲等待事件是什么含义,以及如何实施有效的监控。
一、等待事件是什么
等待事件(wait event) 是在Oracle 7.0.1版本引入的,它是诊断和优化数据库的核心利器。形象的说,如果把oracle数据库比作一个医院,分类别的等待事件就是组成医院的各个科室。每一类等待事件都有其独特的含义和处置方法,在数据库发生隐患或问题时就可以去特定的科室看病或安排联合会诊。
等待事件主要分为空闲等待事件和非空闲等待事件两类:
1)空闲等待事件(idle event):主要是指Oracle正等待某种工作,目前资源是空闲的,在优化和诊断数据库中,不需要特别关注。常见的空闲等待事件主要有:Null event、pipe get、PL/SQLlock timer等。
2)非空闲等待事件(non-idleevent): 指数据库任务或应用运行中发生的等待,指数据库正在运行过程中的活动,在数据库诊断和优化中要特别关注。常见的非空闲等待事件主要有:db file scattered read(数据块离散读)、db filesequential read(数据块顺序读)、buffer busy wait(热点块)、enq: index contention(索引争用等)。
可以用下面的方法查询当前非空闲等待事件的分类及数量:
SELECT a.inst_id, a.event, COUNT(*)
FROM gv$session a
WHERE a.username IS NOT NULL
AND a.status = 'ACTIVE'
AND a.wait_class <> 'Idle'
GROUP BY a.inst_id, a.event;
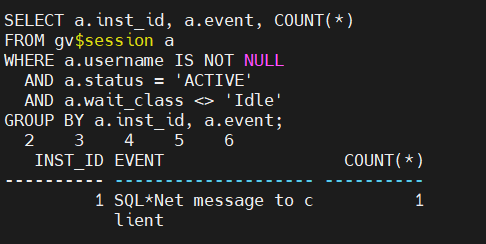
随着版本的演变,等待事件数量也在不断变化,在Oracle11g数据库中,等待事件有1152个,可以通过v$event_name视图查询等待事件的相关信息。
常见等待事件有26个,每一个等待事件都属于某一类,对于存在一定风险、需要关注的主要有下面几类:
1)应用程序类:主要由用户程序的代码引起,比如锁等待,主要与程序设计不优等有关。
2)集群类:和Oracle RAC资源有关,比如gc cr block busy等待,主要与RAC资源管理、节点应用分布等有关。
3)提交确认类:在执行一个commit后,等待重做日志写确认,即log file sync等待,主要与程序频繁的commit或数据库自身处理能力等有关。
4)系统IO类: 由后台进程的IO操作引起,比如DBWR等待、db file parallel write等,主要与数据库自身的处理能力、内存参数设置等有关、
5)用户IO类:有用户IO操作引起,比如db file sequentailread等,主要与程序设计、访问路径等有关。
1.db file scattered read DB
文件分散读取 (太多索引读,全表扫描-----调整代码,将小表放入内存)
这种情况通常显示与全表扫描相关的等待。当全表扫描被限制在内存时,它们很少会进入连续的缓冲区内,而是分散于整个缓冲存储器中。如果这个数目很大,就表明该表找不到索引,或者只能找到有限的索引。尽管在特定条件下执行全表扫描可能比索引扫描更有效,但如果出现这种等待时,最好检查一下这些全表扫描是否必要。因为全表扫描被置于LRU(Least Recently Used,最近最少适用)列表的冷端(cold end),所以应尽量存储较小的表,以避免一次又一次地重复读取它们。
==================================================
该类事件的p1text=file#,p1是file_id,p2是block_id,通过dba_extents即可确定出热点对象(表或索引)
select owner,segment_name,segment_type
from dba_extents
where file_id = &file_id
and &block_id between block_id and block_id + &blocks - 1;
==================================================
2.db file sequential read DB
文件顺序读取 (表连接顺序不佳-----调整代码,特别是表连接)
这一事件通常显示单个块的读取(如索引读取)。这种等待的数目很多时,可能显示表的连接顺序不佳,或者不加选择地进行索引。对于大量事务处理、调整良好的系统,这一数值大多是很正常的,但在某些情况下,它可能暗示着系统中存在问题。你应当将这一等待统计量与Statspack 报告中的已知问题(如效率较低的SQL)联系起来。检查索引扫描,以保证每个扫描都是必要的,并检查多表连接的连接顺序。DB_CACHE_SIZE 也是这些等待出现频率的决定因素。有问题的散列区域(Hash-area)连接应当出现在PGA 内存中,但它们也会消耗大量内存,从而在顺序读取时导致大量等待。它们也可能以直接路径读/写等待的形式出现。
===================================================
该类事件的p1text=file#,p1是file_id,p2是block_id,通过dba_extents即可确定出热点对象(表或索引)
select owner,segment_name,segment_type
from dba_extents
where file_id = &file_id
and &block_id between block_id and block_id + &blocks - 1;
==================================================
3.free buffer waits
释放缓冲区等待 (增大DB_CACHE_SIZE,加速检查点,调整代码)
这种等待表明系统正在等待内存中的缓冲,因为内存中已经没有可用的缓冲空间了。如果所有SQL 都得到了调优,这种等待可能表示你需要增大DB_BUFFER_CACHE。释放缓冲区等待也可能表示不加选择的SQL 导致数据溢出了带有索引块的缓冲存储器,没有为等待系统处理的特定语句留有缓冲区。这种情况通常表示正在执行相当多数量的DML(插入/更新/删除),并且数据库书写器(DBWR)写的速度不够快,缓冲存储器可能充满了相同缓冲器的多个版本,从而导致效率非常低。为了解决这个问题,可能需要考虑增加检查点、利用更多的DBWR 进程,或者增加物理磁盘的数量。
4.buffer busy waits
缓冲区忙等待 (BUFFER热块)
这是为了等待一个以非共享方式使用的缓冲区,或者正在被读入缓冲存储器的缓冲区。缓冲区忙等待不应大于1%。检查缓冲等待统计部分(或V$WAITSTAT):
A、如果等待处于字段头部,应增加自由列表(freelist)的组数,或者增加pctused到pctfree之间的距离。
B、如果等待处于回退段(undo)头部块,可以通过增加回滚段(rollback segment)来解决缓冲区的问题;
C、如果等待处于回退段(undo)非头部块上,就需要降低驱动一致读取的表中的数据密度,或者增大DB_CACHE_SIZE;
D、如果等待处于数据块,可以将数据移到另一数据块以避开这个"热"数据块、增加表中的自由列表或使用LMT表空间;
E、如果等待处于索引块,应该重建索引、分割索引或使用反向键索引。
为了防止与数据块相关的缓冲忙等待,也可以使用较小的块:在这种情况下,单个块中的记录就较少,所以这个块就不是那么"繁忙"。在执行DML(插入/更新/删除)时,Oracle DBWR就向块中写入信息,包括所有对块状态"感兴趣"的用户(感兴趣的事务表,ITL)。为减少这一区域的等待,可以增加initrans,这样会在块中创建空间,从而使你能够使用多个ITL槽。你也可以增加该块所在表中的pctfree(当根据指定的initrans 建立的槽数量不足时,这样可以使ITL 信息数量达到maxtrans 指定的数量)。
5.enqueue
enqueue:等待通常指的是ST enqueue、HW enqueue、TX4 enqueue 和TM enqueue。
A、ST enqueue 用于空间管理和字典管理的表空间的分配。利用LMT,或者试图对区域进行预分配,或者至少使下一个区域大于有问题的字典管理的表空间。
B、HW enqueue 与段的高水位标记一起使用;手动分配区域可以避免这一等待。
C、TX4 enqueue是最常见的enqueue 等待,通常是以下三个问题之一产生的结果:
第一个问题是唯一索引中的重复索引,需要执行提交(commit)/回滚(rollback)操作来释放enqueue。
第二个问题是对同一位图索引段的多次更新。因为单个位图段可能包含多个行地址(rowid),所以当多个用户试图更新同一段时,你需要执行提交或回滚操作,以释放enqueue。
第三个问题,也是最可能发生的问题是多个用户同时更新同一个块。如果没有自由的ITL槽,就会发生块级锁定。通过增大initrans 和/或maxtrans以允许使用多个ITL槽,或者增大表上的pctfree 值,就可以很轻松地避免这种情况。
D、TM enqueue 在DML 期间产生,以避免对受影响的对象使用DDL。如果有外来关键字,一定要对它们进行索引,以避免这种常见的锁定问题。
6.log buffer space
日志缓冲空间 (写REDO慢-----增大log_buffer,redo log file放到快速磁盘上)
当日志缓冲(log buffer)写入重做日志(redo log)的速度比LGWR 的写入速度慢,或者是当日志转换(log switch)太慢时,就会发生这种等待。为解决这个问题,可以增大日志文件的大小,或者增加日志缓冲器的大小,或者使用写入速度更快的磁盘。甚至可以考虑使用固态磁盘,因为它们的速度很高。
7. log file switch
log file switch 日志文件转换 (归档慢-----增加或者扩大重做日志)
A、log file switch (archiving needed)
当日志切换的时候由于日志组循环使用了一圈但日志归档还没有完成,通常是io有严重问题,可增大日志文件和增加日志组,调整log_archive_max_processes
B、log file switch (checkpoint incomplete)
当日志切换的时候由于日志组循环使用了一圈但将被使用的日志组中的checkpoint还没有完成造成,通常是io有严重问题,可增大日志文件和增加日志组
8.log file sync
日志文件同步 (提交太频繁----批量提交)
当用户commit的时候通知lgwr写日志但lwgr正忙,造成的可能原因是commit太频繁或者lgwr一次写日志时间太长(可能是因为一次log io size 太大),可调整 _log_io_size,结合log_buffer,使得 (_log_io_size*db_block_size)*n = log_buffer,这样可避免和增大log_buffer引起冲突;放置日志文件于高速磁盘上
在 LGWR 将日志缓冲区(包括提交重做记录)写入日志文件之前,提交是不完整的。在将 LGWR 发布到写入后,用户或后台进程等待 LGWR 以 1 秒的超时返回信号。用户进程将此等待时间计为“log file sync”事件。
造成 log file sync 原因
1.commit操作
2.rollback操作
3.DDL操作(DDL操作实施前都会首先进行一次commit)
4.DDL操作导致的数据字典修改所产生的commit
5.IO性能,延迟,cpu等
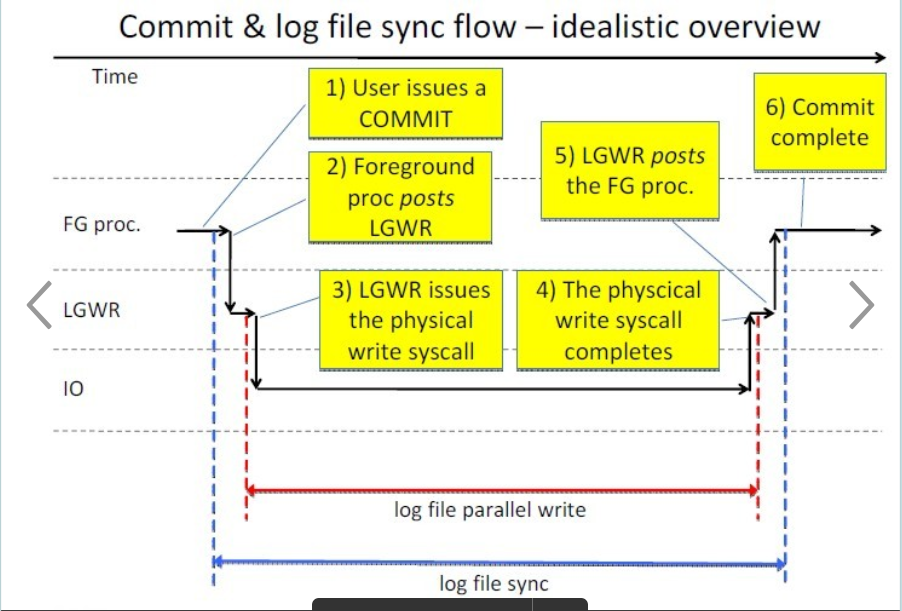
1)用户进程发起commit
2)用户进程通知lgwr写日志
3)lgwr接收到请求开始写
4)lgwr写完成
5)lgwr通知用户进程写完成
6)用户进程获得通知,继续做其他事
1,2阶段的时间,主要是post/wait的时间,典型的这种post/wait一般利用的是操作系统的信号量(IPC)实现,如果系统CPU资源充足,一般不会出现大的延迟。前台进程post lgwr后,就开始等待log file sync。
2,3阶段的时间,主要是lgwr为了获取cpu资源,等待cpu调度的时间,如果系统cpu资源充足,一般不会出现大的延迟。这里我们需要知道,lgwr只是操作系统的一个进程,它需要操作系统的调度获取cpu资源后才可以工作
3,4阶段的时间,主要是真正的物理io时间,lgwr通知os把log buffer的内容写入到磁盘,然后lgwr进入睡眠(等待log file parallel write),这个时间正常情况下的延迟占整个log file sync的大部分时间。还需要指出,lgwr在获取cpu资源后,可能并不能马上通知os写磁盘,只有在确保所有的redo copy latch都已经被释放,才能开始真正的IO操作。
4,5阶段的时间,os调度lgwr 重新获得cpu资源,lgwr post前台进程写完成。lgwr可能会post很多前台进程(group commit的副作用)
5,6阶段的时间,前台进程接受到lgwr的通知,返回cpu运行队列,处理其他事物(log file sync结束)。
解决方法:
1.批量提交
2.增加lgwr的优先级 _high_priority_processes这个参数
3.IO延迟的诊断、调优:可以通过log file parallel write这个后台进程等待事件来辅助判断。如果这个等待时间过大,那么系统的IO很可能出现了问题
4.cpu资源的诊断、调优:如果log file sync的时间与log file parallel write的时间差异过大,则可能系统的CPU资源出现了不足。
9.library cache pin
该事件通常是发生在先有会话在运行PL/SQL,VIEW,TYPES等object时,又有另外的会话执行重新编译这些object,即先给对象加上了一个共享锁,然后又给它加排它锁,这样在加排它锁的会话上就会出现这个等待。P1,P2可与x$kglpn和x$kglob表相关
X$KGLOB (Kernel Generic Library Cache Manager Object)
X$KGLPN (Kernel Generic Library Cache Manager Object Pins)
-- 查询X$KGLOB,可找到相关的object,其SQL语句如下
(即把V$SESSION_WAIT中的P1raw与X$KGLOB中的KGLHDADR相关连)
select kglnaown,kglnaobj from X$KGLOB
where KGLHDADR =(select p1raw from v$session_wait
where event='library cache pin')
-- 查出引起该等待事件的阻塞者的sid
select sid from x$kglpn , v$session
where KGLPNHDL in
(select p1raw from v$session_wait
where wait_time=0 and event like 'library cache pin%')
and KGLPNMOD <> 0
and v$session.saddr=x$kglpn.kglpnuse
-- 查出阻塞者正执行的SQL语句
select sid,sql_text
from v$session, v$sqlarea
where v$session.sql_address=v$sqlarea.address
and sid=<阻塞者的sid>
这样,就可找到"library cache pin"等待的根源,从而解决由此引起的性能问题。
10:library cache lock
该事件通常是由于执行多个DDL操作导致的,即在library cache object上添加一个排它锁后,又从另一个会话给它添加一个排它锁,这样在第二个会话就会生成等待。可通过到基表x$kgllk中查找其对应的对象。
-- 查询引起该等待事件的阻塞者的sid、会话用户、锁住的对象
select b.sid,a.user_name,a.kglnaobj
from x$kgllk a , v$session b
where a.kgllkhdl in
(select p1raw from v$session_wait
where wait_time=0 and event = 'library cache lock')
and a.kgllkmod <> 0
and b.saddr=a.kgllkuse
当然也可以直接从v$locked_objects中查看,但没有上面语句直观根据sid可以到v$process中查出pid,然后将其kill或者其它处理。
<5> latch free (等待LATCH FREE)
latch是一种低级排队机制(它们被准确地称为相互排斥机制),用于保护系统全局区域(SGA)中共享内存结构。latch 就像是一种快速地被获取和释放的内存锁。latch 用于防止共享内存结构被多个用户同时访问。如果latch 不可用,就会记录latch 释放失败。大多数latch 问题都与以下操作相关:不能使用邦定变量(库缓存latch)、重复生成问题(重复分配latch)、缓冲存储器竞争问题(缓冲器存储LRU 链),以及缓冲存储器中的"热"块(缓冲存储器链)。也有一些latch 等待与bug(程序错误)有关,如果怀疑是这种情况,可以检查MetaLink 上的bug 报告。
该事件的热点对象可通过以下语句查找,其中&2值是v$session_wait中的P1RAW,x$bh中的字段Hladdr表示该block buffer在哪个cache buffer chain latch 上,可以通过v$latch_children定位哪些segment是热点块。
===================================================
select a.hladdr, a.file#, a.dbablk, a.tch, a.obj, b.object_name
from x$bh a, dba_objects b
where (a.obj = b.object_id or a.obj = b.data_object_id)
and a.hladdr = &2
union
select hladdr, file#, dbablk, tch, obj, null
from x$bh
where obj in
(select obj from x$bh
where hladdr = &2
minus
select object_id from dba_objects
minus
select data_object_id from dba_objects)
and hladdr = &2
order by 4;
====================================================
***Latch 问题及可能解决办法
------------------------------
* Library Cache and Shared Pool (未绑定变量---绑定变量,调整shared_pool_size)
每当执行SQL或PL/SQL存储过程,包,函数和触发器时,这个Latch即被用到.Parse操作中此Latch也会被频繁使用.
* Redo Copy (增大_LOG_SIMULTANEOUS_COPIES参数)
重做拷贝Latch用来从PGA向重做日志缓冲区拷贝重做记录.
* Redo Allocation (最小化REDO生成,避免不必要提交)
此Latch用来分配重做日志缓冲区中的空间,可以用NOLOGGING来减缓竞争.
* Row Cache Objects (增大共享池)
数据字典竞争.过度parsing.
* Cache Buffers Chains (_DB_BLOCK_HASH_BUCKETS应增大或设为质数)
"过热"数据块造成了内存缓冲链Latch竞争.
* Cache Buffers Lru Chain (调整SQL,设置DB_BLOCK_LRU_LATCHES,或使用多个缓冲区池)
扫描全部内存缓冲区块的LRU(最近最少使用)链时要用到内存缓冲区LRU链Latch.太小内存缓冲区、过大的内存缓冲区吞吐量、过多的内存中进行的排序操作、DBWR速度跟不上工作负载等会引起此Latch竞争。
11.db file parallel write
与DBWR进程相关的等待,一般代表了I/O能力出现了问题. 通常与配置的多个DBWR进程或者DBWU的I/O slaves个数有关.当然也可能意味着设备上存在着I/O竞争
db file parallel write等待的发生原因和解决方法如下:
如果DBWR进程上db file parallel write等待时间表现得过长,就可以判断为I/O系统上有问题。如果DBWR上的db file parallel write等待时间延长,服务器进程就会接连经历free buffer waits事件或write complete waits事件的等待。这个问题可以通过改善I/O系统解决,改善I/O性能的方法如下:
(1)组合使用裸设备和异步I/O是目前为止的最好方法。
(2)OS级上使用Direct I/O。若CPU数量充足,可以调整db_writer_processes参数值,将DBWR数量增加。多个DBWR具有模拟异步的效果。oracle推荐的DBWR进程是CPU_COUNT/8。
2、I/O工作过多时
频繁发生检查点时,DBWR的活动量过多,可能导致DBWR的性能降低。DBWR的性能与整个系统的性能有直接的联系。将fast_start_mttr_target(MTTR指平均恢复时间,数据库进行崩溃恢复需要的秒数。)参数值设定过小时,将频繁发生增量检查点工作。日志文件过小时,将频繁发生日志文件的转换,因此检查点工作将增加。因Parallel Query发生direct path read时,在truncate、drop、hot backup时也发生检查点。如果I/O系统上不存在性能问题,但还是广泛出现db file parallel write等待,就应该检查是否存在给DBWR带来不必要的负荷的因素。
3、不能有效使用高速缓存区时
间接改善DBWR性能的另一种方法是合理使用多重缓冲池。与其说这个方法能改善I/O系统的性能,不如说是因为不必要的写入工作减少,进而减少了DBWR的负担。
12.db file single write
表示在检查点发生时与文件头写操作相关的等待.通常与检查点同步数据文件头时文件号的紊乱有关.
这个等待事件包含三个参数:
file# :要读取的数据块所在数据文件的文件号。
block#:读取的起始数据块号。
blocks:需要读取的数据块数目。(通常来说在这里应该等于1)
13.direct path read 和 direct path write
表示与直接I/O读相关的等待.当直接读数据到PGA内存时,direct path read 出现.这种类型的读请求典型地作为:排序IO(为排序不能在内存中完成的时候),并行Slave查询或者预先读请求等. 通常这种等待与I/O能力或者I/O竞争有关.
14.cursor:pin S wait on X
产生原因:当一个会话以X模式持有某个cursor(如sql/procedure/function/package body等)的mutex时,如果另一个会话需要以S模式请求该cursor的mutex;一般来说,对cursor进行硬解析时会以X模式持有cursor的mutex,而对cursor进行软解析时会以S模式持有cursor的mutex,例如:会话A正在解析(硬解析)某一个SQL语句时,另外一个会话B同时执行这条SQL语句,会话B就会出现该等待事件。该等待事件的p1参数idn实际上就是sql语句的hash_value,也就是说通过该等待事件的p1参数即可定位等待的实际对象,p2为mutex的holder。
select decode(trunc(&p2 / 4294967296),
0,
trunc(&p2 / 65536),
trunc(&p2 / 4294967296)) sid_holding_mutex
from dual;
15.free buffer inspected
表示在将数据读入数据调整缓存区的时候等待进程找到足够大的内在空间通常这类等待表示数据调整缓存区偏小.
16.library cache load lock
表示在将对象装载到库高速缓存时出现了等待.这种事件通常代表着发生了负荷尔蒙很重的语句重载或者装载,可能由于SQL语句没有共享或者共享池区域编小造成的.
17.log file parallel write
表示等待LGWR向操作系统请求I/O开始直到完成IO.在触发LGWR写的情况下如3秒、1/3、1MB、DBWR写之前可能发生.这种事件发生通常表示日志文件发生了I/O竞争或者文件所在的驱动器较慢
18.log file single write
表示写日志文件头块时出现了等待.一般都是发生在检查点发生时.
19.transaction
表示发生了一个阻塞回滚操作的等待
20.undo segment extension
表示在等待回滚段的动态扩展.这表示可能事务量过大,同时也意味着可能回滚段的寝大小不是最优,MINEXTENTS设置得偏小.考虑减少事务,或者使用最小区数更大的回滚段.
log buffer中没有可用的空间来缓存redo buffer或者服务器进程写入log buffer的速度快与LGWR进程写出的速度
产生原因:
1)log buffer太小
2)系统I/O缓慢导致LGWR进程写日志慢
3)日志切换频繁、事务提交频繁导致LGWR进程写负担重
21. Buffer latch
内存中数据块的存放位置是记录在一个hash列表(cache buffer chains)当中的。 当一个会话需要访问某个数据块时,它首先要搜索这个hash 列表,从列表中获得数据块的地址,然后通过这个地址去访问需要的数据块,这个列表Oracle会使用一个latch来保护它的完整性。 当一个会话需要访问这个列表时,需要获取一个Latch,只有这样,才能保证这个列表在这个会话的浏览当中不会发生变化。
产生buffer latch的等待事件的主要原因是:
Buffer chains太长,导致会话搜索这个列表花费的时间太长,使其他的会话处于等待状态。
同样的数据块被频繁访问,就是我们通常说的热快问题。
产生buffer chains太长,我们可以使用多个buffer pool的方式来创建更多的buffer chains,或者使用参数DB_BLOCK_LRU_LATCHES来增加latch的数量,以便于更多的会话可以获得latch,这两种方法可以同时使用。
这个等待事件有两个参数:
Latch addr: 会话申请的latch在SGA中的虚拟地址,通过以下的SQL语句可以根据这个地址找到它对应的Latch名称:
select * from v$latch a,v$latchname b where
addr=latch addr -- 这里的latch addr 是你从等待事件中看到的值
and a.latch#=b.latch#;
chain#: buffer chains hash 列表中的索引值,当这个参数的值等于s 0xfffffff时,说明当前的会话正在等待一个LRU latch。
22.Control file parallel write
当数据库中有多个控制文件的拷贝时,Oracle 需要保证信息同步地写到各个控制文件当中,这是一个并行的物理操作过程,因为称为控制文件并行写,当发生这样的操作时,就会产生control file parallel write等待事件。
控制文件频繁写入的原因很多,比如:
日志切换太过频繁,导致控制文件信息相应地需要频繁更新。
系统I/O 出现瓶颈,导致所有I/O出现等待。
当系统出现日志切换过于频繁的情形时,可以考虑适当地增大日志文件的大小来降低日志切换频率。
当系统出现大量的control file parallel write 等待事件时,可以通过比如降低控制文件的拷贝数量,将控制文件的拷贝存放在不同的物理磁盘上的方式来缓解I/O 争用。
这个等待事件包含三个参数:
Files: Oracle 要写入的控制文件个数。
Blocks: 写入控制文件的数据块数目。
Requests:写入控制请求的I/O 次数。
23.Control file sequential read
当数据库需要读取控制文件上的信息时,会出现这个等待事件,因为控制文件的信息是顺序写的,所以读取的时候也是顺序的,因此称为控制文件顺序读,它经常发生在以下情况:
备份控制文件
RAC 环境下不同实例之间控制文件的信息共享
读取控制文件的文件头信息
读取控制文件其他信息
这个等待事件有三个参数:
File#:要读取信息的控制文件的文件号。
Block#: 读取控制文件信息的起始数据块号。
Blocks:需要读取的控制文件数据块数目。
24.gc cr multi block request
申请者实例需要向远程实例(可能是多个)申请多个(具体的数据块数量取决于参数db_file_mulitblock_read_count的设置)cr块,并且这个等待事件只有在所有申请的数据块都被成功返回之后才会结束,也就是说如果有其中的一个数据块因为某种原因没有被成功接收的话就需要重新申请所有的数据块,这也是为什么这个等待事件经常和gc cr failure/gc current retry同时出现的原因。
产生原因:
1)在远程实例上有一个blocker进程一直持有数据块,导致了申请者无法拿到数据;
2)申请的数据块太多了,导致了私网的负载太大,产生了性能问题;
3)私网配置不当,导致了数据无法被快速的传递到远程节点。
25.log buffer space
log buffer中没有可用的空间来缓存redo buffer或者服务器进程写入log buffer的速度快与LGWR进程写出的速度
产生原因:
1)log buffer太小
2)系统I/O缓慢导致LGWR进程写日志慢
3)日志切换频繁、事务提交频繁导致LGWR进程写负担重
26.write complete waits
DBWR进程将buffer cache中的脏块写回到数据文件时,对该脏块是持有Exclusive模式的,若想读取或修改该脏块的进程将会等待DBWR进程完成。
产生原因:
1)DBWR进程写缓慢,如系统I/O缓慢
2)DBWR进程的工作量过多,如频繁发生检查点或者重做日志切换
的数据块太多了,导致了私网的负载太大,产生了性能问题;
3)私网配置不当,导致了数据无法被快速的传递到远程节点。
## 25.log buffer space
log buffer中没有可用的空间来缓存redo buffer或者服务器进程写入log buffer的速度快与LGWR进程写出的速度
产生原因:
1)log buffer太小
2)系统I/O缓慢导致LGWR进程写日志慢
3)日志切换频繁、事务提交频繁导致LGWR进程写负担重
## 26.write complete waits
DBWR进程将buffer cache中的脏块写回到数据文件时,对该脏块是持有Exclusive模式的,若想读取或修改该脏块的进程将会等待DBWR进程完成。
产生原因:
1)DBWR进程写缓慢,如系统I/O缓慢
2)DBWR进程的工作量过多,如频繁发生检查点或者重做日志切换


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









