







声明
本文章中所有内容仅供学习交流使用,不用于其他任何目的。严禁用于商业用途和非法用途,否则由此产生的一切后果均与作者无关!
本文章未经许可禁止转载,禁止任何修改后二次传播,擅自使用本文讲解的技术而导致的任何意外,作者不负责。
任务解析
爬取猫眼电影上面的标题、演员、上映时间、评分,爬取所有页数上的。
首先我们要确定网页把数据存储到js中还是html中,通过搜索我们发现第一部电影的具体数据在html中。浏览器的请求方式为get
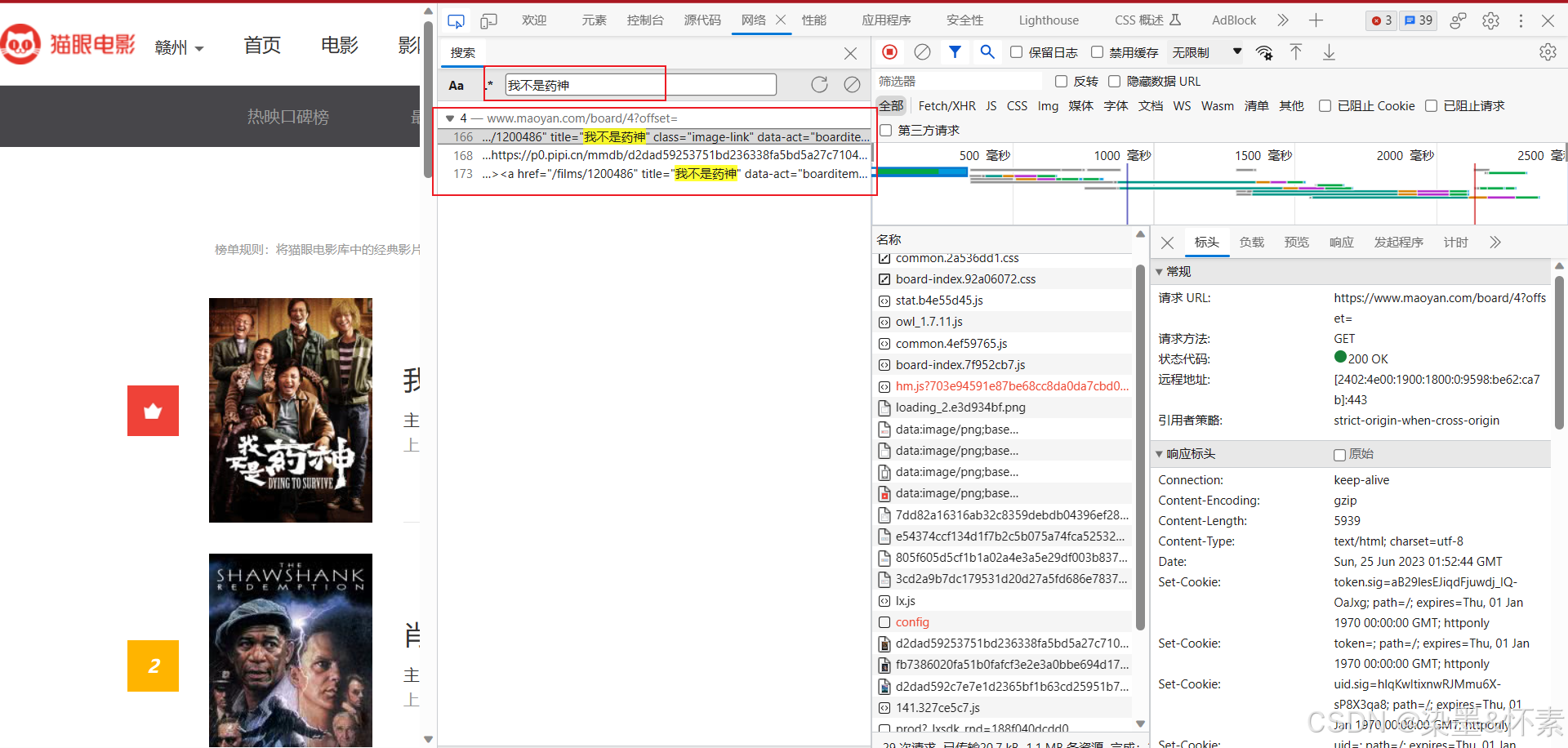
那么就可以先导包,通过bs4解析一下该网页。

import requests
from bs4 import BeautifulSoup
from fake_useragent import UserAgent
headers = {
"User-Agent":UserAgent().random,
'Cookie':'__mta=219117862.1686052750235.1687568949646.1687569342983.10; uuid_n_v=v1; uuid=8B7259D0046111EEA656FD7ECF47D2298F0830D681C748CDB242EC734792D191; _lxsdk_cuid=188909342cdc8-0a44179c29f2c2-7e56547a-144000-188909342cdc8; _lxsdk=8B7259D0046111EEA656FD7ECF47D2298F0830D681C748CDB242EC734792D191; __mta=219117862.1686052750235.1686052801700.1686052821642.5; _csrf=29c4405659fbe100f104545e4136ffa3d6c38774b74311471323c527bbaa94d3; _lx_utm=utm_source%3Dbing%26utm_medium%3Dorganic; _lxsdk_s=188eae02ba2-e51-0ec-8ff%7C%7C9'
}
url = "https://maoyan.com/board/4?offset"
resp = requests.get(url=url,headers=headers)
resp.enconding='utf-8'
soup = BeautifulSoup(resp.text,'lxml')
print(soup.prettify())但是在解析网页过程中,我们发现后面返回的数据为空。为此,我们可以在headers中添加Cookie

Cookie原理
Cookie是由服务器发给客户端的特殊信息,而这些信息以文本文件的方式存放在客户端,然后客户端每次向服务器发送请求的时候都会带上这些特殊的信息,用于服务器记录客户端的状态。
解析网页
我们这里以第一个我不是药神的代码作为解析,其他的电影数据模块类似使用这样的方法处理。
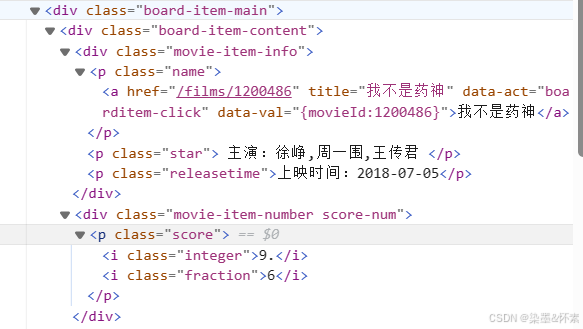
我们抓取每个电影中都相同的标签,在<div class="board-item-content">是所有数据的共同部分,我们可以先用find_all找出这部分。
all = soup.find_all("div",class_='board-item-content')再逐步解析我们需要爬取的字段数据位置
标题:在a标签中我们只需要将href=True就可以识别出每一个电影的标题了、
演员:在p标签中,我们先提取里面的文字,去除空格,切割掉主演:就行了、
上映时间:在p标签中,我们先提取里面的文字,去除空格,切割掉上映时间:就行了、
评分:分两部分来拼接,第一部分是integer和fraction

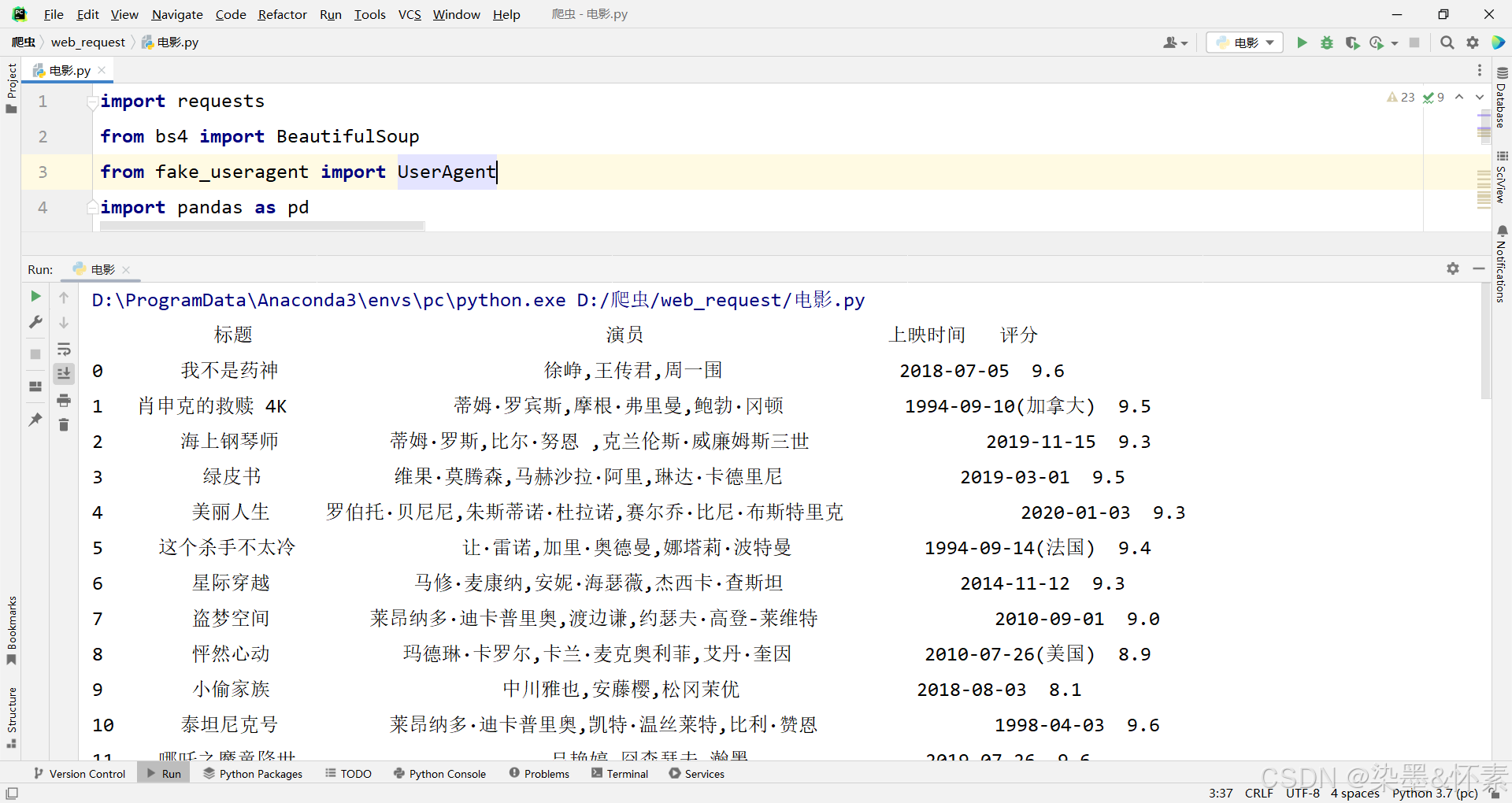
将其爬取多个页面的
dict = []
for i in range(0,100,10):
url = f'https://maoyan.com/board/4?offset={i}'
resp = requests.get(url=url,headers=headers)
resp.encoding = 'utf-8'
soup = BeautifulSoup(resp.text,'lxml')
mvs = soup.find_all("div",class_='board-item-content')
for mv in mvs:
dic = {}
dic['标题'] = mv.find('a',href=True).text.strip()
dic['演员'] = mv.find('p',class_='star').text.strip().split('主演:')[-1]
dic['上映时间']= mv.find('p',class_='releasetime').text.strip().split('上映时间:')[-1]
dic['评分'] = mv.find('i',{'class':'integer'}).text.strip()+mv.find('i',{'class':'fraction'}).text.strip()[0]
dict.append(dic)
dict = pd.DataFrame(dict)
print(dict)
dict.to_excel('./data/movie.xlsx')
完整代码
import requests
from bs4 import BeautifulSoup
from fake_useragent import UserAgent
import pandas as pd
headers = {
'User-Agent':UserAgent().random,
'Cookie':'__mta=219117862.1686052750235.1687568949646.1687569342983.10; uuid_n_v=v1; uuid=8B7259D0046111EEA656FD7ECF47D2298F0830D681C748CDB242EC734792D191; _lxsdk_cuid=188909342cdc8-0a44179c29f2c2-7e56547a-144000-188909342cdc8; _lxsdk=8B7259D0046111EEA656FD7ECF47D2298F0830D681C748CDB242EC734792D191; __mta=219117862.1686052750235.1686052801700.1686052821642.5; _csrf=29c4405659fbe100f104545e4136ffa3d6c38774b74311471323c527bbaa94d3; _lx_utm=utm_source%3Dbing%26utm_medium%3Dorganic; _lxsdk_s=188eae02ba2-e51-0ec-8ff%7C%7C9',
'Accept':'text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,image/apng,*/*;q=0.8,application/signed-exchange;v=b3;q=0.7',
'Host':'www.maoyan.com'
}
dict = []
for i in range(0,100,10):
url = f'https://maoyan.com/board/4?offset={i}'
resp = requests.get(url=url,headers=headers)
resp.encoding = 'utf-8'
soup = BeautifulSoup(resp.text,'lxml')
mvs = soup.find_all("div",class_='board-item-content')
for mv in mvs:
dic = {}
dic['标题'] = mv.find('a',href=True).text.strip()
dic['演员'] = mv.find('p',class_='star').text.strip().split('主演:')[-1]
dic['上映时间']= mv.find('p',class_='releasetime').text.strip().split('上映时间:')[-1]
dic['评分'] = mv.find('i',{'class':'integer'}).text.strip()+mv.find('i',{'class':'fraction'}).text.strip()[0]
dict.append(dic)
dict = pd.DataFrame(dict)
print(dict)
dict.to_excel('./data/movie.xlsx')


















 2087
2087

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









