







图的定义和术语
图的定义
G=(V,E)
V:顶点(数据元素)的有穷非空集合
E:边的有穷集合
图分为有向图和无向图
完全图
任意两个点都有一条边相连
无向完全图: n个顶点,n(n-1)/2条边
有向完全图: n个顶点,n(n-1)条边
网
边/弧带权的图
顶点的度
与该顶点相关联的边的数目
在有向图中,顶点的度等于该顶点的入度和出度之和
路径长度
接续的边构成的顶点序列上边或弧的数目/权值之和
连通图
在无(有)向图G=(V,{E})中,若对任何两个顶点v,u都存在从v到u的路径,则称G是连通图(强连通图)
子图
设有两个图G=(V,{E}),G1=(V1,{E1}),若V1∈V,E1∈E,则称G1是G的子图
(强)连通分量
无向图G的极大连通子图称为G的连通分量
极大连通子图:该子图是G的连通子图,将G的任何不在该图中的顶点加入,子图不再连通
有向图G的极大连通子图称为G的强连通分量
极小连通子图和生成树
极小连通子图:该子图是G的连通子图,在该子图中删除任何一条边,子图不再连通
生成树:包含无向图G所有顶点的极小连通子图
生成森林
对于非连通图,由各个连通分量的生成树所构成的集合
图的存储结构
邻接矩阵(数组)表示法

无向图

有向图
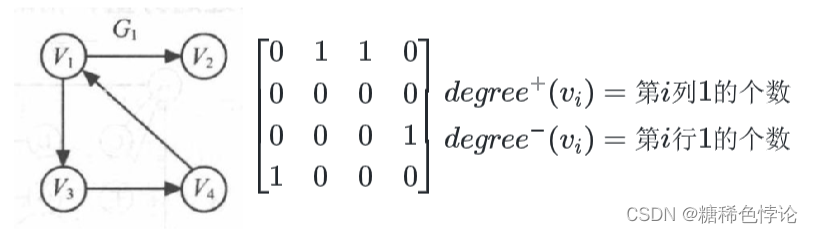
网
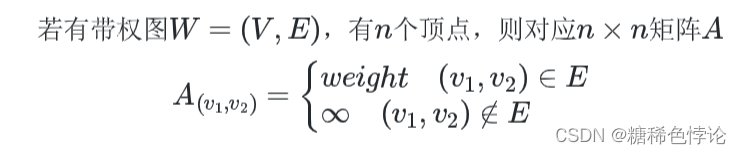
优缺点
优点:
- 直观、简单、好理解
- 方便检查任意一对顶点间是否存在边
- 方便查找任一顶点所有邻接点
- 方便计算任一顶点的度
缺点:
- 不便于增加和删除顶点
- 浪费时间和空间(适合稠密图/完全图)
代码实现
图的定义
#define MAX 9999 //最大权值
#define MAXSIZE 100 //最大顶点数
struct Graph
{
char vexs[MAXSIZE]; //图的顶点表(一维数组)
int arcs[MAXSIZE][MAXSIZE]; //图的邻接矩阵(二维数组)
int vexnum, arcnum; //定义图的总顶点数和总边数
};
邻接矩阵的LocateVex函数
int LocateVex(Graph& G, const char& e)
{
for (int i = 0; i < G.vexnum; ++i) {
if (G.vexs[i] == e) //(查找输入元素在顶点表中对应的数组下标)
return i;
}
return -1;
}
无向无权图
void Creat_unAMGraph(Graph& G)
{
cout << "无向无权图:请输入顶点数和边数" << endl;
cin >> G.vexnum >> G.arcnum;
cout << "请输入顶点" << endl;
for (int i = 0; i < G.vexnum; ++i)
{
cin >> G.vexs[i]; //输入顶点,保存在一维数组顶点表中
}
for (int i = 0; i < G.arcnum; ++i) {
for (int j = 0; j < G.arcnum; ++j) {
G.arcs[i][j] = 0; //将邻接矩阵的权值置为0
}
}
for (int k = 0; k < G.arcnum; ++k) {
int i, j;
char a, b;
cout << "输入与边相连的两个顶点" << endl;
cin >> a >> b;
i = LocateVex(G, a); //查找输入的两个顶点在顶点表(一维数组)中对应的数组下标
j = LocateVex(G, b);
G.arcs[i][j] = G.arcs[j][i] = 1; //邻接矩阵为对称矩阵
}
}
无向带权图
void Creat_unAMGraph_weight(Graph& G)
{
cout << "无向带权图:请输入顶点数和边数" << endl;
cin >> G.vexnum >> G.arcnum;
cout << "请输入顶点" << endl;
for (int i = 0; i < G.vexnum; ++i)
{
cin >> G.vexs[i]; //输入顶点,保存在一维数组顶点表中
}
for (int i = 0; i < G.arcnum; ++i) {
for (int j = 0; j < G.arcnum; ++j) {
G.arcs[i][j] =0; //将邻接矩阵的权值置为0
}
}
for (int k = 0; k < G.arcnum; ++k) {
int i, j, weight;
char a, b;
cout << "输入与边相连的两个顶点以及边的权" << endl;
cin >> a >> b >> weight;
i = LocateVex(G, a); //查找输入的两个顶点在顶点表(一维数组)中对应的数组下标
j = LocateVex(G, b);
G.arcs[i][j] = G.arcs[j][i] = weight; //邻接矩阵为对称矩阵
}
}
有向带权图
void Creat_AMGraph_weight(Graph& G)
{
cout << "有向带权图:请输入顶点数和边数" << endl;
cin >> G.vexnum >> G.arcnum;
cout << "请输入顶点" << endl;
for (int i = 0; i < G.vexnum; ++i)
{
cin >> G.vexs[i]; //输入顶点,保存在一维数组顶点表中
}
for (int i = 0; i < G.arcnum; ++i) {
for (int j = 0; j < G.arcnum; ++j) {
G.arcs[i][j] = 0; //将邻接矩阵的权值置为0
}
}
for (int k = 0; k < G.arcnum; ++k) {
int i, j, weight;
char a, b;
cout << "输入有向边的两个顶点(a指向b)以及权值" << endl;
cin >> a >> b >> weight;
i = LocateVex(G, a); //查找输入的两个顶点在顶点表(一维数组)中对应的数组下标
j = LocateVex(G, b);
G.arcs[i][j]= weight;
}
}
有向无权图
void Creat_AMGraph(Graph& G)
{
cout << "有向无权图:请输入顶点数和边数" << endl;
cin >> G.vexnum >> G.arcnum;
cout << "请输入顶点" << endl;
for (int i = 0; i < G.vexnum; ++i)
{
cin >> G.vexs[i]; //输入顶点,保存在一维数组顶点表中
}
for (int i = 0; i < G.arcnum; ++i) {
for (int j = 0; j < G.arcnum; ++j) {
G.arcs[i][j] = 0; //将邻接矩阵的权值置为0
}
}
for (int k = 0; k < G.arcnum; ++k) {
int i, j;
char a, b;
cout << "输入有向边的两个顶点(a指向b)" << endl;
cin >> a >> b;
i = LocateVex(G, a); //查找输入的两个顶点在顶点表(一维数组)中对应的数组下标
j = LocateVex(G, b);
G.arcs[i][j] = 1;
}
}
打印邻接矩阵
void Showgraph(Graph& G)
{
cout << "顶点表为:" << endl;
cout << "-------------------------" << endl;
for (int i = 0; i < G.vexnum; ++i) {
cout << "下标:" << i << " " << "顶点:" << G.vexs[i] << " ";
cout << endl;
}
cout << "-------------------------" << endl;
cout << "邻接矩阵为:" << endl;
cout << "-----------------------------------------" << endl;
for (int i = 0; i < G.vexnum; ++i) {
for (int j = 0; j < G.vexnum; ++j) {
cout << G.arcs[i][j] <<'\t';
}
cout << endl;
}
cout << "-----------------------------------------" << endl;
}
测试代码
#include <iostream>
using namespace std;
int main()
{
Graph G;
Creat_unAMGraph(G);
cout << "无向无权图:" << endl;
Showgraph(G);
Creat_unAMGraph_weight(G);
cout << "无向带权图:" << endl;
Showgraph(G);
Creat_AMGraph_weight(G);
cout << "有向带权图:" << endl;
Showgraph(G);
Creat_AMGraph(G);
cout << "有向无权图:" << endl;
Showgraph(G);
system("pause");
return 0;
}
邻接表(链式)表示法
顶点按编号顺序存储在一维数组中
关联同一顶点的边用线性链表存储
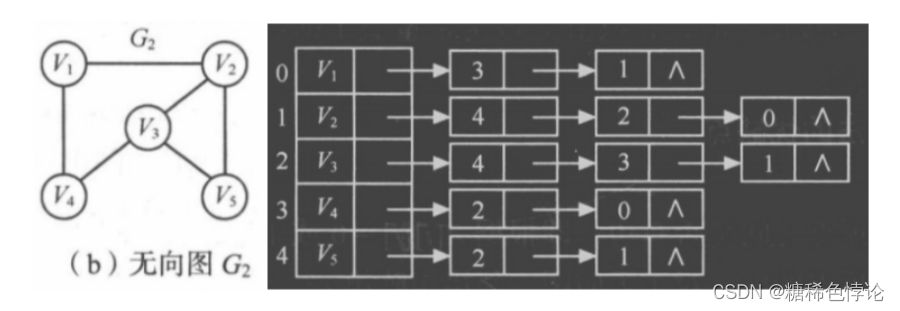
优缺点
优点:
- 方便查找任一顶点的所有邻接点
- 节约稀疏图空间(N个头指针+2e个节点),每个节点至少两个域
缺点:
- 不方便检查任意一对顶点之间是否存在边
代码实现
数据类型定义
typedef struct Arcnode //边表(表结点)的定义
{
int adjvex; //保存顶点的下标(邻接点域)
int weight; //保存边的权值
Arcnode* next; //指向下一个边结点(链域)
}Arcnode;
typedef struct Vexnode //顶点表(头结点)的定义
{
int data; //数据域,存放顶点
Arcnode* firstarc; //指针域,用于保存邻接点
}Vexnode;
typedef struct ALGraph //图的定义
{
Vexnode vexs[MAX]; //定义一个数组,保存图的顶点
int vexnum, arcnum; //定义当前图的顶点个数以及边的条数
}ALGraph;
邻接表的LocateVex函数
int LocateVex(ALGraph& G, const int& e)
{
for (int i = 0; i < G.vexnum; ++i) {
if (G.vexs[i].data == e) //(查找输入元素在顶点表中对应的数组下标)
return i;
}
return -1;
}
无向带权图
void Creat_unALGraph_weight(ALGraph& G)
{
cout << "无向带权图:请输入顶点数以及边数:" << endl;
cin >> G.vexnum >> G.arcnum;
cout << "请输入顶点:" << endl;
for (int i = 0; i < G.vexnum; ++i) {
cin >> G.vexs[i].data; //给头结点的数据域赋值,即输入顶点
G.vexs[i].firstarc = nullptr; //将头结点的指针域置为空
}
cout << "顶点表为:" << endl;
cout << "-------------------------" << endl;
for (int i = 0; i < G.vexnum; ++i) {
cout << "下标:" << i << " " << "顶点:" << G.vexs[i].data << " ";
cout << endl;
}
cout << "-------------------------" << endl;
for (int j = 0; j < G.arcnum; ++j) {
int weight;
char a, b;
int m, n;
cout << "请输入与边相连的两个顶点以及权值:" << endl;
cin >> a >> b >> weight;
m = LocateVex(G, a); //查找输入的两个顶点在顶点表(一维数组)中对应的数组下标
n = LocateVex(G, b);
//cout <<"test "<< G.vexs[n].data<< endl;
Arcnode* p = new Arcnode; //在堆区申请动态内存
p->adjvex = n; //邻接点域指向顶点b的数组下标
p->weight = weight;
p->next = G.vexs[m].firstarc; //用头插法将表结点插在头结点之后
G.vexs[m].firstarc = p;
Arcnode* q = new Arcnode;
q->adjvex = m; //邻接点域指向顶点a的数组下标
q->weight = weight;
q->next = G.vexs[n].firstarc; //因为是无向图,有n个顶点就有n个头结点,e条边就有2e个表结点
G.vexs[n].firstarc = q;
}
}
无向无权图
void Creat_unALGraph(ALGraph& G)
{
cout << "无向无权图:请输入顶点数以及边数:" << endl;
cin >> G.vexnum >> G.arcnum;
cout << "请输入顶点:" << endl;
for (int i = 0; i < G.vexnum; ++i) {
cin >> G.vexs[i].data; //给头结点的数据域赋值,即输入顶点
G.vexs[i].firstarc = nullptr; //将头结点的指针域置为空
}
cout << "顶点表为:" << endl;
cout << "-------------------------" << endl;
for (int i = 0; i < G.vexnum; ++i) {
cout << "下标:" << i << " " << "顶点:" << G.vexs[i].data << " ";
cout << endl;
}
cout << "-------------------------" << endl;
for (int j = 0; j < G.arcnum; ++j) {
char a, b;
int m, n;
cout << "请输入与边相连的两个顶点" << endl;
cin >> a >> b;
m = LocateVex(G, a); //查找输入的两个顶点在顶点表(一维数组)中对应的数组下标
n = LocateVex(G, b);
//cout <<"test "<< G.vexs[n].data<< endl;
Arcnode* p = new Arcnode; //在堆区申请动态内存
p->adjvex = n; //邻接点域指向顶点b的数组下标
p->next = G.vexs[m].firstarc; //用头插法将表结点插在头结点之后
G.vexs[m].firstarc = p;
Arcnode* q = new Arcnode;
q->adjvex = m; //邻接点域指向顶点a的数组下标
q->next = G.vexs[n].firstarc; //因为是无向图,有n个顶点就有n个头结点,e条边就有2e个表结点
G.vexs[n].firstarc = q;
}
}
有向无权图
void Creat_ALGraph(ALGraph& G)
{
cout << "有向无权图:请输入顶点数以及边数:" << endl;
cin >> G.vexnum >> G.arcnum;
cout << "请输入顶点:" << endl;
for (int i = 0; i < G.vexnum; ++i) {
cin >> G.vexs[i].data; //给头结点的数据域赋值,即输入顶点
G.vexs[i].firstarc = nullptr; //将头结点的指针域置为空
}
cout << "顶点表为:" << endl;
cout << "-------------------------" << endl;
for (int i = 0; i < G.vexnum; ++i) {
cout << "下标:" << i << " " << "顶点:" << G.vexs[i].data << " ";
cout << endl;
}
cout << "-------------------------" << endl;
for (int j = 0; j < G.arcnum; ++j) {
char a, b;
int m, n;
cout << "请输入一条有向边对应的两个顶点(a指向b):" << endl;
cin >> a >> b ;
m = LocateVex(G, a); //查找输入的两个顶点在顶点表(一维数组)中对应的数组下标
n = LocateVex(G, b);
//cout <<"test "<< G.vexs[n].data<< endl;
Arcnode* p = new Arcnode; //在堆区申请动态内存
p->adjvex = n; //邻接点域指向顶点b的数组下标
p->next = G.vexs[m].firstarc; //用头插法将表结点插在头结点之后
G.vexs[m].firstarc = p;
}
}
有向带权图
void Creat_ALGraph_weight(ALGraph& G)
{
cout << "有向带权图:请输入顶点数以及边数:" << endl;
cin >> G.vexnum >> G.arcnum;
cout << "请输入顶点:" << endl;
for (int i = 0; i < G.vexnum; ++i) {
cin >> G.vexs[i].data; //给头结点的数据域赋值,即输入顶点
G.vexs[i].firstarc = nullptr; //将头结点的指针域置为空
}
cout << "顶点表为:" << endl;
cout << "-------------------------" << endl;
for (int i = 0; i < G.vexnum; ++i) {
cout << "下标:" << i << " " << "顶点:" << G.vexs[i].data << " ";
cout << endl;
}
cout << "-------------------------" << endl;
for (int j = 0; j < G.arcnum; ++j) {
int weight;
char a, b;
int m, n;
cout << "请输入一条有向边对应的两个顶点(a指向b)以及权值" << endl;
cin >> a >> b >> weight;
m = LocateVex(G, a); //查找输入的两个顶点在顶点表(一维数组)中对应的数组下标
n = LocateVex(G, b);
//cout <<"test "<< G.vexs[n].data<< endl;
Arcnode* p = new Arcnode; //在堆区申请动态内存
p->adjvex = n; //邻接点域指向顶点b的数组下标
p->weight = weight;
p->next = G.vexs[m].firstarc; //用头插法将表结点插在头结点之后
G.vexs[m].firstarc = p;
}
}
打印邻接表
void Showgraph_weight(ALGraph& G)
{
for (int i = 0; i < G.vexnum; ++i)
{
cout << i << " 顶点:" << G.vexs[i].data << "-->";
Arcnode* p = G.vexs[i].firstarc; //p为头结点指向的第一个表结点
while (p != NULL)
{
cout << G.vexs[p->adjvex].data << "||" << p->weight << "--"; //输出表结点的数据域和权值
p = p->next;
}
cout << endl;
}
}
void Showgraph(ALGraph& G)
{
for (int i = 0; i < G.vexnum; ++i)
{
cout << i << " 顶点:" << G.vexs[i].data << "-->";
Arcnode* p = G.vexs[i].firstarc; //p为头结点指向的第一个表结点
while (p != NULL)
{
cout << G.vexs[p->adjvex].data << "-->"; //输出表结点的数据域和权值
p = p->next;
}
cout << endl;
}
}
测试代码
#include <iostream>
using namespace std;
int main()
{
ALGraph G; //定义无向图G
Creat_unALGraph_weight(G); //创建无向图G
cout << "无向带权图邻接表为:" << endl;
Showgraph_weight(G); //打印邻接表
Creat_unALGraph(G);
cout << "无向无权图邻接表为:" << endl;
Showgraph(G);
Creat_ALGraph(G);
cout << "有向无权图邻接表为:" << endl;
Showgraph(G);
Creat_ALGraph_weight(G);
cout << "有向带权图邻接表为:" << endl;
Showgraph_weight(G);
system("pause");
return 0;
}
邻接表与邻接矩阵的比较
- 邻接表中每个链表对应于邻接矩阵中的一行,链表中节点个数等于一行中非零元素的个数
- 对于任一确定的无向图,邻接矩阵是唯一的,但是邻接表不是唯一的
- 邻接矩阵的空间复杂度为O(n^2),邻接表的空间复杂度为O(n+e)
- 邻接矩阵多用于稠密图,邻接表多用于稀疏图
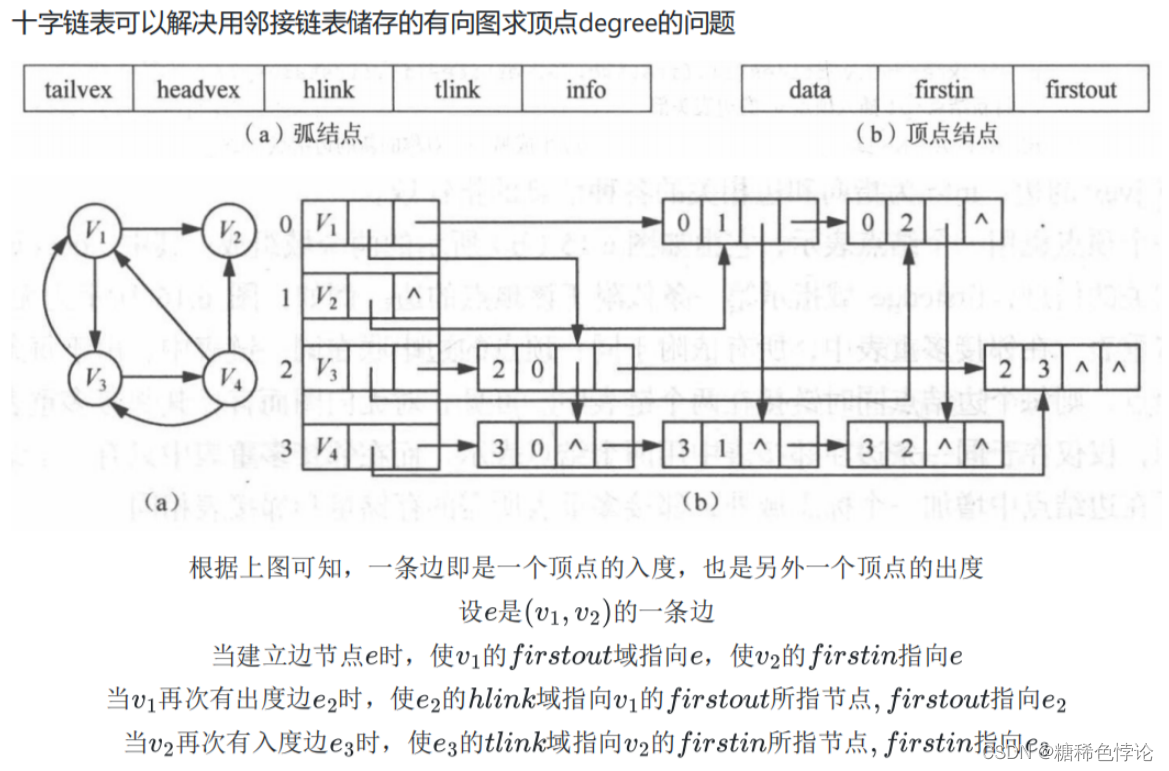
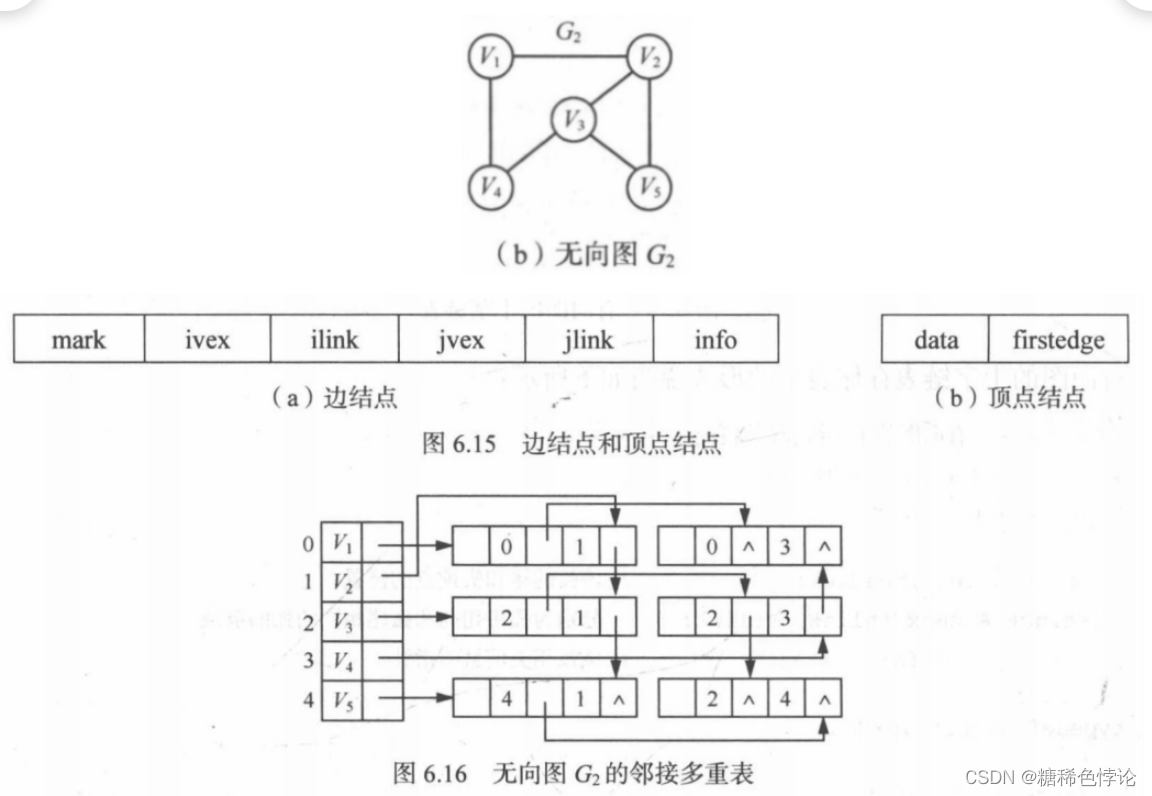
邻接表有向图—缺点:求节点的度困难—十字链表改进
邻接表无向图—缺点:每条边都要存储两遍—邻接多重表改进
十字链表
邻接多重表
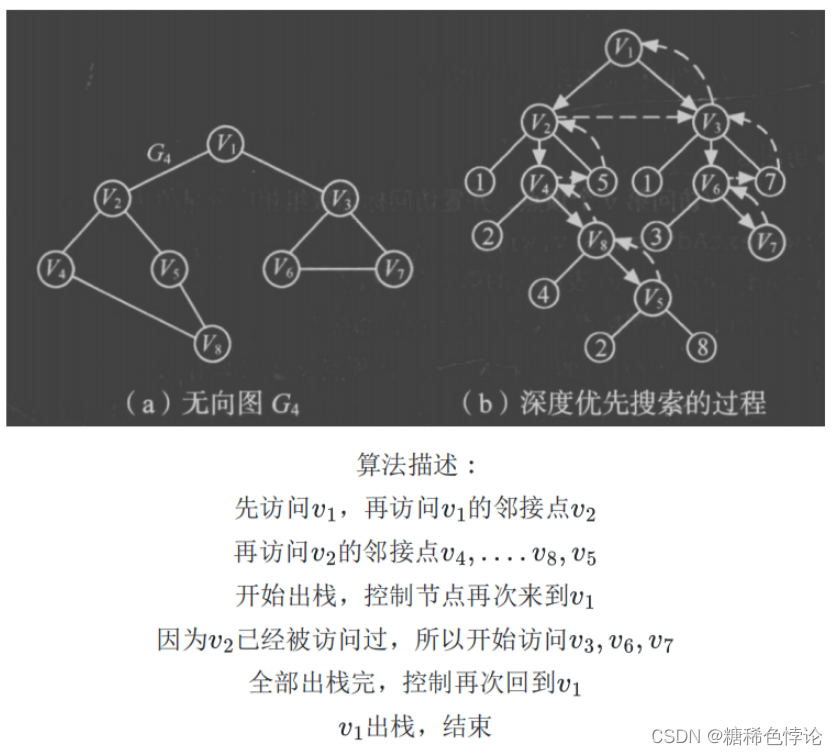
图的遍历
从已给的连通图中某一顶点出发,沿着一些边访遍图中所有的顶点,且使每个顶点仅被访问一次,叫做图的遍历,它是图的基本运算
如何避免重复访问?
设置辅助数组visited[n],用来标记每个被访问过的顶点
初始状态:visited[i]=0
顶点i被访问,改visited[i]为1,防止被多次访问
深度优先遍历(DFS)
遍历邻接矩阵
//深度优先遍历算法,算法时间复杂度为O(n*n)
int visited1[MAXSIZE] = {}; //定义一个visited数组做标志
void DFS_AMGraph(Graph& G, int v)
{
cout << G.vexs[v] << " "; //输出图顶点表包含的内容
visited1[v] = 1; //标志数组visit对应的元素被访问了,记为1
for (int w = 0; w < G.vexnum; ++w) //从邻接矩阵某一行的第一个元素开始遍历到该行的第n个元素
{
if ((G.arcs[v][w] != 0) && visited1[w] == 0)
{
DFS_AMGraph(G, w); //如果找到一个相连的顶点,且该顶点还没有被访问过,进入递归函数
}
}
}
测试代码
#include <iostream>
suing namespace std;
int main()
{
Graph G;
CreatUDM(G);
Showgraph(G);
cout << endl;
cout << "深度优先遍历为:" << endl;
DFS_AMGraph(G, 0);
cout << endl;
system("pause");
return 0;
}
//
/*
8 9
A B C D E F G H
A B
A C
B D
D H
B E
E H
C F
C G
F G
----------------------
A B D H E C F G
*/
遍历邻接表
int visited1[MAX] = {}; //定义一个辅助数组作为顶点访问标记
void DFS_ALGraph(ALGraph& G, int v)
{
cout << G.vexs[v].data<<" "; //访问数组下标为v的顶点
visited1[v] = 1; //访问之后,顶点标记为1
Arcnode* p = G.vexs[v].firstarc; //访问该结点之后的边结点
while (p != NULL)
{
int i = p->adjvex; //i为邻接表域中储存的数据,即顶点在顶点表中对应的数组下标
if (visited1[i] == 0) //如果该顶点还没被访问,继续递归
{
DFS_ALGraph(G, i);
}
p = p->next;
}
}
测试代码
#include <iostream>
using namespace std;
int main()
{
ALGraph G; //定义无向图G
Creat_unALGraph_weight(G); //创建无向图G
Showgraph(G); //打印邻接表
cout << "深度优先遍历为:" << endl;
DFS_ALGraph(G, 0);
system("pause");
return 0;
}
//
/*
8 9
A B C D E F G H
A B
A C
B D
D H
B E
E H
C F
C G
F G
----------------------
A C G F B E H D
*/
广度优先遍历(BFS)

遍历邻接矩阵
//广度优先遍历(输入开始访问的顶点的下标)
int visited3[MAXSIZE] = {}; //定义一个visited数组做标志
void BFSvisit(Graph& G, int v)
{
queue<int>deq; //创建一个队列容器
deq.push(v); //将数组下标入队
visited3[v] = 1; //数组下标v已被访问,标记为1
while (!deq.empty()) //当队列为空时停止循环
{
int x = deq.front(); //x为队头元素
cout << G.vexs[x] << " "; //输出顶点表中的数组下标对应的顶点
deq.pop(); //队列元素删除操作,无参返回
for (int w = 0; w < G.vexnum; ++w) {
if ((G.arcs[x][w] != 0) && visited3[w] == 0)
//邻接矩阵对应位置不为0且该数组下标未被访问
{
deq.push(w); //将数组下标w入队
visited3[w] = 1; //该数组下标已访问,标记为1
}
}
}
}
测试代码
#include <iostream>
suing namespace std;
int main()
{
Graph G;
CreatUDM(G);
Showgraph(G);
cout << endl;
cout << "广度优先遍历为:" << endl;
BFSvisit(G, 0);
cout << endl;
system("pause");
return 0;
}
//
/*
8 9
A B C D E F G H
A B
A C
B D
D H
B E
E H
C F
C G
F G
----------------------
A B C D E F G H
*/
遍历邻接表
int visited2[MAX] = {}; //定义一个辅助数组作为顶点访问标记
void BFS_ALGraph(ALGraph& G, int v)
{
SqQueue Q; //定义一个队列,存储访问的元素(先进先出)
Initqueue(Q); //初始化队列
Arcnode* p; //定义一个结点p
Insertqueue(Q, v); //将我们输入的数组下标v进队
visited2[v] = 1; //数组下标v已被访问,标记为1
int x;
while (!Isempty(Q)) //当队列为空时停止循环
{
Outqueue(Q,x); //将队列中的元素(顶点表中的数组下标)出队
cout << G.vexs[x].data<<" "; //输出顶点表中的数组下标对应的顶点
p = G.vexs[x].firstarc; //p为该顶点指向的下一个边结点
while (p!=NULL)
{
if (visited2[p->adjvex] == 0) //当数组下标未被访问,进入循环
{
Insertqueue(Q, p->adjvex); //将这个未被访问的数组下标进队
visited2[p->adjvex] = 1; //然后将这个数组下标标记为1,表示已访问
}
p = p->next; //p指向下一个边结点
}
}
}
测试代码
#include <iostream>
using namespace std;
int main()
{
ALGraph G; //定义无向图G
Creat_unALGraph_weight(G); //创建无向图G
Showgraph(G); //打印邻接表
cout << "深度优先遍历为:" << endl;
BFS_ALGraph(G, 0);
system("pause");
return 0;
}
//
/*
8 9
A B C D E F G H
A B
A C
B D
D H
B E
E H
C F
C G
F G
----------------------
A C B G F E D H
*/
算法效率分析
邻接矩阵的时间效率为O(n^2)
邻接表的时间效率为O(n+e)
稠密图适合在邻接矩阵上进行深度遍历
稀疏图适合在邻接表上进行深度遍历
DFS与BFS空间复杂度相同,都是O(n)
时间复杂度只与存储结构有关,而与搜索路径无关
最小生成树
生成树:所有顶点均由边连接在一起,但不存在回路的图
生成树的顶点个数与图相同,是图的极小连通图
一个有n个顶点的连通图的生成树有n-1条边
生成树中任意两个顶点之间的路径是不唯一的
最小生成树:给定一个无向网络,在该网的所有生成树中,使得各边权值之和最小的那棵生成树称为该网的最小生成树
构造最小生成树的方法:
- Prim算法:选择点—时间复杂度O(n)—适用于稠密图
- Kruskal算法:选择边–时间复杂度O(eloge)—适用于稀疏图
Prim算法

Kruskal 算法

最短路径
一类:两点间最短路径(权值之和)
二类:某源点到其他各点最短路径—Dijkstra算法
三类:所有顶点间的最短路径—Floyd算法
Dijkstra算法

Floyd算法

有向无环图
AOV网:拓扑排序
以顶点表示活动,弧表示活动之间的优先制约关系的有向图
构造拓扑有序序列
- 在有向图中选择一个没有前驱的顶点且输出
- 从图中删除该顶点和所有以它为尾的弧
- 若网中所有顶点都在它的拓扑有序序列中,该AOV网不存在
AOE网:关键路径
以弧表示活动,以顶点表示活动的开始或结束事件的有向图
关键路径
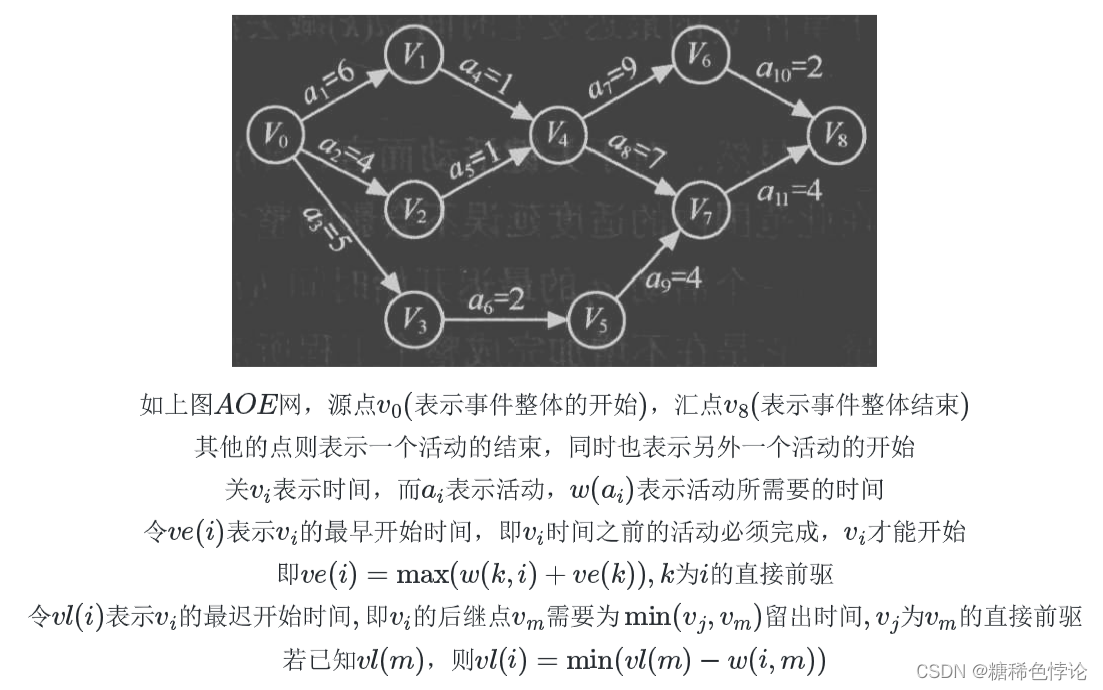

- 加快同时在几条关键路径上的活动可以缩短整个活动的时间
- 关键路径上活动的时间不能缩短太多,否则关键路径会发生改变
图片来源:PDF整理笔记By: LI LIANGJI (Wechat:llj907015000)
本章完~


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









