






活动地址:CSDN21天学习挑战赛
学习的最大理由是想摆脱平庸,早一天就多一份人生的精彩;迟一天就多一天平庸的困扰。各位小伙伴,如果您:
想系统/深入学习某技术知识点…
一个人摸索学习很难坚持,想组团高效学习…
想写博客但无从下手,急需写作干货注入能量…
热爱写作,愿意让自己成为更好的人…
前言
对于昨天我们只是用单一的线程完成了一个http服务器,但是在真实的应用场景中服务器都是多任务来完成的。故首先把昨天的http服务器针对多任务进行改版。
目录
一、使用多进程完成http服务器
import socket
import re
import sys
import urllib.parse
import multiprocessing
def service_client(new_socket):
"""为这个客户端服务数据"""
# 接收浏览器发送过来的请求,即http请求
# GET / HTTP1.1
request = new_socket.recv(1024)
# print("对方发来的请求数据为", request)
request_lines = request.splitlines()
try:
x = urllib.parse.unquote(request_lines[0])
except:
print("out of range")
sys.exit()
# GET /index.html HTTP/1.1
try:
ret = re.match(r"[^/]+/([^ ]+) ", x)
file_name = ret.group(1)
count = file_name.find("?")
# if file_name[-8:-1] == "?v=4.1.":
# file_name = file_name[:-8]
if count != -1:
file_name = file_name[:count]
print("经正则处理请求的数据为", file_name)
except:
file_name = "index.html"
print("正则无效已强制匹配")
# 返回http格式的数据给浏览器
# 准备发送的数据header
response = "HTTP/1.1 200 OK\r\n" # 正规的浏览器解析数据换行\r\n
response += "\r\n"
# 准备发送的数据body
with open("./html/"+file_name, "rb") as file:
html_body = file.read()
print("数据成功取出")
new_socket.send(response.encode("utf-8"))
new_socket.send(html_body)
print("对其服务结束")
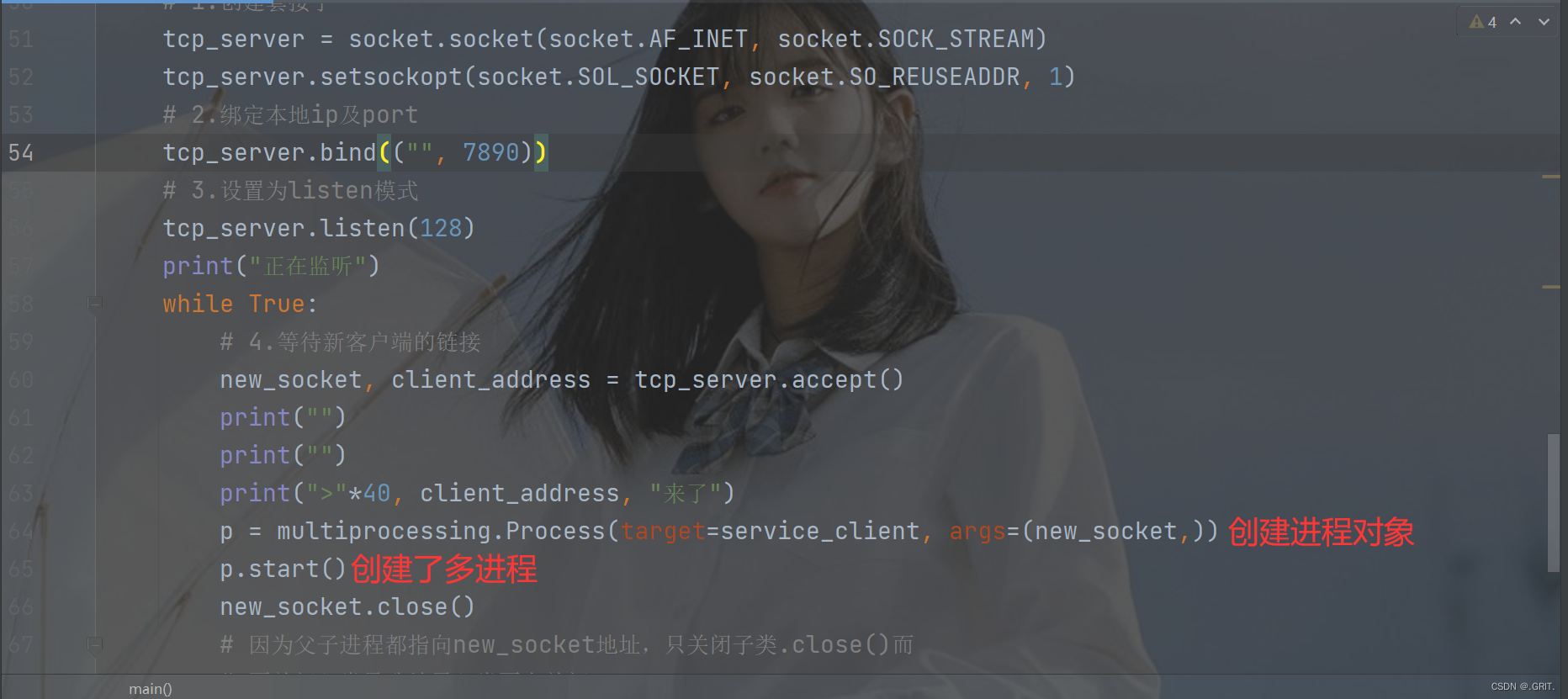
def main():
"""用来完成整体控制"""
# 1.创建套接字
tcp_server = socket.socket(socket.AF_INET, socket.SOCK_STREAM)
tcp_server.setsockopt(socket.SOL_SOCKET, socket.SO_REUSEADDR, 1)
# 2.绑定本地ip及port
tcp_server.bind(("", 7890))
# 3.设置为listen模式
tcp_server.listen(128)
print("正在监听")
while True:
# 4.等待新客户端的链接
new_socket, client_address = tcp_server.accept()
print("")
print("")
print(">"*40, client_address, "来了")
p = multiprocessing.Process(target=service_client, args=(new_socket,))
p.start()
new_socket.close()
# 因为父子进程都指向new_socket地址,只关闭子类.close()而
# 不关闭父类导致结果父类不会关闭
# 5.为这个客户端服务
# service_client(new_socket)
if __name__ == "__main__":
main()
部分结果
讲解
因为本段代码只是在原来的基础上使用了多进程的操作,当另外一个链接到来了以后会自动创建新的套接字来接待而不是等上一个服务完毕后再对其服务。
二、使用多线程版本
import socket
import re
import sys
import urllib.parse
import threading
def service_client(new_socket):
"""为这个客户端服务数据"""
# 接收浏览器发送过来的请求,即http请求
# GET / HTTP1.1
request = new_socket.recv(1024)
# print("对方发来的请求数据为", request)
request_lines = request.splitlines()
try:
x = urllib.parse.unquote(request_lines[0])
except:
print("out of range")
sys.exit()
# GET /index.html HTTP/1.1
try:
ret = re.match(r"[^/]+/([^ ]+) ", x)
file_name = ret.group(1)
count = file_name.find("?")
# if file_name[-8:-1] == "?v=4.1.":
# file_name = file_name[:-8]
if count != -1:
file_name = file_name[:count]
print("经正则处理请求的数据为", file_name)
except:
file_name = "index.html"
print("正则无效已强制匹配")
# 返回http格式的数据给浏览器
# 准备发送的数据header
response = "HTTP/1.1 200 OK\r\n" # 正规的浏览器解析数据换行\r\n
response += "\r\n"
# 准备发送的数据body
with open("./html/"+file_name, "rb") as file:
html_body = file.read()
print("数据成功取出")
new_socket.send(response.encode("utf-8"))
new_socket.send(html_body)
new_socket.close()
print("对其服务结束")
def main():
"""用来完成整体控制"""
# 1.创建套接字
tcp_server = socket.socket(socket.AF_INET, socket.SOCK_STREAM)
tcp_server.setsockopt(socket.SOL_SOCKET, socket.SO_REUSEADDR, 1)
# 2.绑定本地ip及port
tcp_server.bind(("", 7890))
# 3.设置为listen模式
tcp_server.listen(128)
print("正在监听")
while True:
# 4.等待新客户端的链接
new_socket, client_address = tcp_server.accept()
print("")
print("")
print(">"*40, client_address, "来了")
t = threading.Thread(target=service_client, args=(new_socket,))
t.start()
# 5.为这个客户端服务
# service_client(new_socket)
if __name__ == "__main__":
main()
三、协程版本
import socket
import re
import sys
import urllib.parse
import gevent
from gevent import monkey
monkey.patch_all()
def service_client(new_socket):
"""为这个客户端服务数据"""
# 接收浏览器发送过来的请求,即http请求
# GET / HTTP1.1
request = new_socket.recv(1024)
# print("对方发来的请求数据为", request)
request_lines = request.splitlines()
try:
x = urllib.parse.unquote(request_lines[0])
except:
print("out of range")
sys.exit()
# GET /index.html HTTP/1.1
try:
ret = re.match(r"[^/]+/([^ ]+) ", x)
file_name = ret.group(1)
count = file_name.find("?")
# if file_name[-8:-1] == "?v=4.1.":
# file_name = file_name[:-8]
if count != -1:
file_name = file_name[:count]
print("经正则处理请求的数据为", file_name)
except:
file_name = "index.html"
print("正则无效已强制匹配")
# 返回http格式的数据给浏览器
# 准备发送的数据header
response = "HTTP/1.1 200 OK\r\n" # 正规的浏览器解析数据换行\r\n
response += "\r\n"
# 准备发送的数据body
with open("./html/"+file_name, "rb") as file:
html_body = file.read()
print("数据成功取出")
new_socket.send(response.encode("utf-8"))
new_socket.send(html_body)
new_socket.close()
print("对其服务结束")
def main():
"""用来完成整体控制"""
# 1.创建套接字
tcp_server = socket.socket(socket.AF_INET, socket.SOCK_STREAM)
tcp_server.setsockopt(socket.SOL_SOCKET, socket.SO_REUSEADDR, 1)
# 2.绑定本地ip及port
tcp_server.bind(("", 7890))
# 3.设置为listen模式
tcp_server.listen(128)
print("正在监听")
while True:
# 4.等待新客户端的链接
new_socket, client_address = tcp_server.accept()
print("")
print("")
print(">"*40, client_address, "来了")
gevent.spawn(service_client, new_socket)
# 5.为这个客户端服务
# service_client(new_socket)
if __name__ == "__main__":
main()
四、长链接,短链接
你会发现对于上部分代码全部是浏览器请求资源需要啥就请求一次,需要啥就重新链接一次,这就是短链接。
长链接:把所有的资源全部发送完了确定没有了以后在断开链接,即一次性发送全部资源,而不如短链接间断性发送。
"""
长连接:资源直接在一个套接字全部发完再断开连接对应HTTP1.1
短连接:一个资源一个套接字连接对应HTTP1.0
"""
# 实现长连接
import socket
import re
import urllib.parse
def service_client(new_socket, recv_data):
"""为这个客户端服务数据"""
# 接收浏览器发送过来的请求,即http请求
# GET / HTTP1.1
request = recv_data
# print("对方发来的请求数据为", request)
request_lines = request.splitlines()
x = urllib.parse.unquote(request_lines[0])
# GET /index.html HTTP/1.1
try:
ret = re.match(r"[^/]+/([^ ]+) ", x)
file_name = ret.group(1)
count = file_name.find("?")
# if file_name[-8:-1] == "?v=4.1.":
# file_name = file_name[:-8]
if count != -1:
file_name = file_name[:count]
print("经正则处理请求的数据为", file_name)
except:
file_name = "index.html"
print("正则无效已强制匹配")
# 返回http格式的数据给浏览器
# 准备发送的数据header
# 准备发送的数据body
with open("./html/"+file_name, "rb") as file:
html_body = file.read()
print("数据成功取出")
response_header1 = "HTTP/1.1 200 OK\r\n" # 正规的浏览器解析数据换行\r\n
response_header1 += "Content-Length:%d\r\n" % len(html_body)
response_header1 += "\r\n"
response_header = response_header1.encode("utf-8")
response = response_header + html_body
new_socket.send(response)
print("对其服务结束")
def main():
"""用来完成整体控制"""
# 1.创建套接字
tcp_server = socket.socket(socket.AF_INET, socket.SOCK_STREAM)
tcp_server.setsockopt(socket.SOL_SOCKET, socket.SO_REUSEADDR, 1)
# 2.绑定本地ip及port
tcp_server.bind(("", 7890))
# 3.设置为listen模式
tcp_server.listen(128)
tcp_server.setblocking(False) # 设置非堵塞
print("正在监听")
client_socket_list = list()
while True:
# 4.等待新客户端的链接
try:
new_socket, client_address = tcp_server.accept()
except Exception as ret:
pass
else:
new_socket.setblocking(False)
client_socket_list.append(new_socket)
for client_socket in client_socket_list:
try:
recv_data = client_socket.recv(1024)
except Exception as ret:
pass
else:
if recv_data:
service_client(client_socket, recv_data)
else:
client_socket.close()
client_socket_list.remove(client_socket)
print(client_address, "用户离开")
if __name__ == "__main__":
main()
# 总结:长连接减少服务器压力
五、拓展web静态服务器epoll
"""
长连接:资源直接在一个套接字全部发完再断开连接对应HTTP1.1
短连接:一个资源一个套接字连接对应HTTP1.0
"""
# 实现长连接
import socket
import re
import urllib.parse
import select
def service_client(new_socket, recv_data):
"""为这个客户端服务数据"""
# 接收浏览器发送过来的请求,即http请求
# GET / HTTP1.1
request = recv_data
# print("对方发来的请求数据为", request)
request_lines = request.splitlines()
x = urllib.parse.unquote(request_lines[0])
# GET /index.html HTTP/1.1
try:
ret = re.match(r"[^/]+/([^ ]+) ", x)
file_name = ret.group(1)
count = file_name.find("?")
# if file_name[-8:-1] == "?v=4.1.":
# file_name = file_name[:-8]
if count != -1:
file_name = file_name[:count]
print("经正则处理请求的数据为", file_name)
except:
file_name = "index.html"
print("正则无效已强制匹配")
# 返回http格式的数据给浏览器
# 准备发送的数据header
# 准备发送的数据body
with open("./html/"+file_name, "rb") as file:
html_body = file.read()
print("数据成功取出")
response_header1 = "HTTP/1.1 200 OK\r\n" # 正规的浏览器解析数据换行\r\n
response_header1 += "Content-Length:%d\r\n" % len(html_body)
response_header1 += "\r\n"
response_header = response_header1.encode("utf-8")
response = response_header + html_body
new_socket.send(response)
print("对其服务结束")
def main():
"""用来完成整体控制"""
# 1.创建套接字
tcp_server = socket.socket(socket.AF_INET, socket.SOCK_STREAM)
tcp_server.setsockopt(socket.SOL_SOCKET, socket.SO_REUSEADDR, 1)
# 2.绑定本地ip及port
tcp_server.bind(("", 7890))
# 3.设置为listen模式
tcp_server.listen(128)
tcp_server.setblocking(False) # 设置非堵塞
# 创建一个epoll对象
epl = select.epoll()
# 将监听套接字对应的fd注册到epoll中
epl.register(tcp_server.fileno(), select.EPOLLIN)
print("正在监听")
client_socket_list = list()
fd_event_dict = dict()
while True:
fd_event_list = epl.poll() # 默认会堵塞,直到os检查到数据到来通过实践通知方式告诉这个程序才会解堵塞
# [(fd,event), (套接字对应的文件描述符描述文件是什么事件)]
for fd, event in fd_event_list:
if fd == tcp_server.fileno():
# 4.等待新客户端的链接
new_socket, client_address = tcp_server.accept()
epl.register(new_socket.fileno(), select.EPOLLIN)
fd_event_dict[new_socket.fileno()] = new_socket
elif event == select.EPOLLIN:
recv_data = fd_event_dict[fd].recv(1024)
if recv_data:
service_client(fd_event_dict[fd], recv_data)
else:
fd_event_dict[fd].close()
epl.unregister(fd)
client_socket_list.remove(fd_event_dict[fd])
if __name__ == "__main__":
main()
# 总结:因为epoll是虚拟机下的window没有
六、预告
明天更新python高级语法知识。
















 5784
5784

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











