







文章目录
前言
哈喽,大家好,本文我将来带大家复现一篇顶会论文 DDColor: Towards Photo-Realistic Image Colorization via Dual Decoders,我将会分为两大部分来完成介绍。分别为论文代码复现和论文内容介绍,本篇我将详细介绍论文内容。(PS:本人是科研小白,第一次进行复现论文的工作,如有错误请大家积极指出,我会第一时间修改错误。)
论文代码复现:小白代码复现
简要介绍
我们先简单介绍一下论文相关内容:
课题:DDColor: Towards Photo-Realistic Image Colorization via Dual Decoders
领域:计算机视觉——图像上色
会议:ICCV
作者:Xiaoyang Kang, Tao Yang, Wenqi Ouyang, Peiran Ren, Lingzhi Li, Xuansong Xie
论文内容
1.内容概要
- 实验目的:作者构建DDColor模型对灰度图像进行上色。
- 主要方法:DDColor模型具有双解码器:像素解码器和色彩解码器。通过交叉注意建立颜色和多尺度语义表征之间的相关性,并且引入了一种色彩损失来增强色彩的丰富度。
- 论文贡献:提出了一个带有双解码器的端到端网络,用于自动图像着色,这确保了生动和语义一致的结果。色彩解码器可以从视觉特征中学习颜色查询,而不依赖于手工制作的先验。像素解码器提供了多尺度语义表示来指导颜色查询的优化,有效地减少了颜色溢出效应。综合实验表明,与基线相比,其方法达到了最先进的性能,并表现出良好的泛化。
2.课题背景
- 图像着色是一项经典的计算机视觉任务,给定灰度图像后,着色的目的是恢复图像中缺失的两个颜色通道。这是个高度复杂的问题,通常存在多模态不确定性,例如,一个物体可能有多种可行的颜色。传统的着色方法主要基于用户引导来解决这一问题,随着深度学习的兴起,自动着色技术引起了广泛关注,其目标是从复杂的图像语义(如形状、纹理和上下文)中生成合适的颜色。
- 早期的方法 尝试使用卷积神经网络 (CNN) (一文搞懂卷积神经网络(CNN)的原理)预测每个像素的颜色分布。遗憾的是,由于缺乏对图像语义的全面理解,这些基于 CNN 的方法往往会产生不正确或不饱和的着色结果(图 1 CIC 、InstColor 和 DeOldify )。为了包含语义信息,一些方法 采用了生成对抗网络 (GAN)(生成对抗网络GAN 原理详解),并利用其丰富的表征作为着色的生成先验。然而,由于 GAN 先验的表示空间有限,它们无法处理具有复杂结构和语义的图像,从而导致着色结果不佳。(图 1 Wu 等人 和 BigColor )
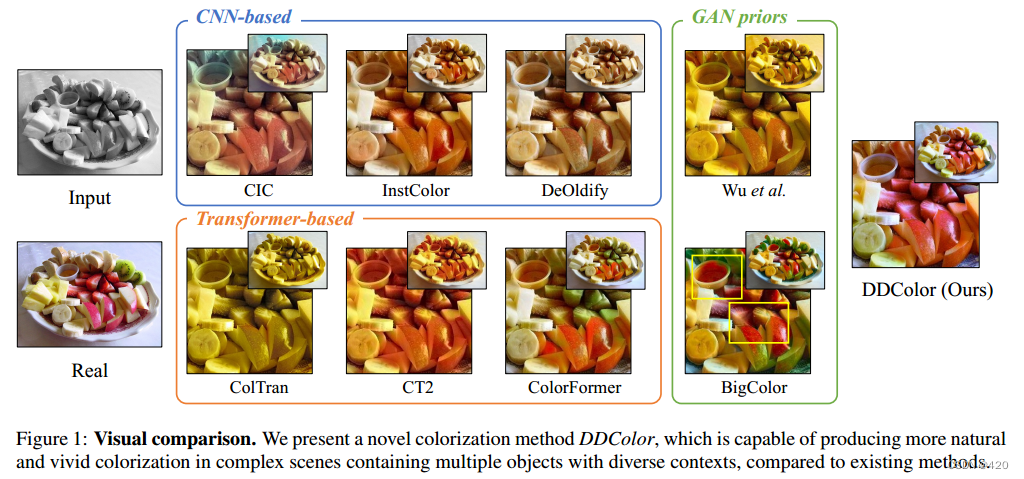
- 随着 Transformer(一文读懂Transformer) 在自然语言处理(NLP)领域的巨大成功,它已被扩展到许多计算机视觉任务中。最近,一些研究将Transformer的非局部注意机制引入图像着色。虽然这些方法取得了可喜的成果,但它们要么训练多个独立子网,导致累积误差(图 1 ColTran ),要么在单尺度图像特征图上执行颜色注意操作,在处理复杂图像上下文时造成明显的颜色失真(图 1 CT2 和 ColorFormer )。此外,这些方法通常依赖于手工制作的数据集级经验分布先验,既繁琐又难以推广。
- 于是,作者便在本文提出了一种新的着色方法,即DDColor,旨在实现语义合理和视觉生动的着色。其方法利用编码器-解码器结构,其中编码器提取图像特征,双解码器恢复空间分辨率。与之前通过额外网络或手动计算先验来优化颜色可能性的方法不同,作者使用基于查询的转换器作为颜色解码器,以端到端的方式学习语义感知的颜色查询。通过使用多尺度图像特征来学习颜色查询,该方法减轻了颜色失真,并显著改善了复杂上下文和小物体的着色(见图1)。在此基础上,还提出了一种新的色彩损失,以提高生成结果的色彩丰富度。
3.模型介绍
整体框架
- 如图( a a a)所示,给定灰度输入图像 x L ∈ R ( H × W × 1 ) x_L∈R^{(H×W×1)} xL∈R(H×W×1),着色网络预测两个缺失的颜色通道 y ^ A B ∈ R ( H × W × 2 ) {\hat{y}}_{AB}∈R^{(H×W×2)} y^AB∈R(H×W×2),其中 L 、 A B L、AB L、AB 通道分别代表 C I E L A B CIELAB CIELAB 色彩空间中的亮度和色度。提出的模型DDColor以端到端的方式对灰度图像 x L x_L xL进行着色。
- 模型利用骨干网络作为编码器,从灰度图像中提取高级语义信息。骨干网络旨在提取图像语义嵌入,文中选择了 C o n v N e X t ConvNeXt ConvNeXt ,它是图像分类的前沿模型。以 x L x_L xL 为输入,骨干网络输出 4 个中间特征图,分辨率分别为 H / 4 × W / 4 、 H / 8 × W / 8 、 H / 16 × W / 16 H/4 × W/4、H/8 ×W/8、H/16 × W/16 H/4×W/4、H/8×W/8、H/16×W/16 和 H / 32 × W / 32 H/32 × W/32 H/32×W/32。前三个特征图通过快捷连接馈送给像素解码器,最后一个特征图则作为像素解码器的输入。至于骨干网络结构,有多种选择,如 R e s N e t , S w i n − T r a n s f o r m e r ResNet,Swin-Transformer ResNet,Swin−Transformer等,只要网络能够产生分层表示即可。
- 模型框架的解码器部分由像素解码器和颜色解码器组成。像素解码器使用一系列堆叠的上采样层来恢复图像特征的空间分辨率。每个上采样层都与编码器的相应阶段有快捷连接。色彩解码器利用不同尺度的多个图像特征,逐步完善语义感知色彩查询。然后,两个解码器产生的图像和颜色特征融合在一起,生成颜色输出 y ^ A B {\hat{y}}_{AB} y^AB 。最后,沿着通道尺寸将 y ^ A B {\hat{y}}_{AB} y^A
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 123
123

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









