






八爪鱼采集器(Octoparse)是一种用于抓取网页数据的网络爬虫工具,可简单快速地将网页数据转化为结构化数据,存储于EXCEL或数据库等多种形式,并且提供基于云计算的大数据云采集解决方案,实现精准、高效、大规模的数据采集。八爪鱼采集器通常用于数据挖掘、竞争情报、市场研究、数据分析和各种其他用途。
八爪鱼采集器采用可视化操作界面,无需编写代码,用户可以通过简单的拖拽、点选和配置来定义爬取规则。
自定义采集
采集豆瓣网站上的图书标题信息
豆瓣图书标签: 小说
1.输入网址
在主页的搜索框内输入我们要采集的网址(示例网址:豆瓣图书标签: 小说)
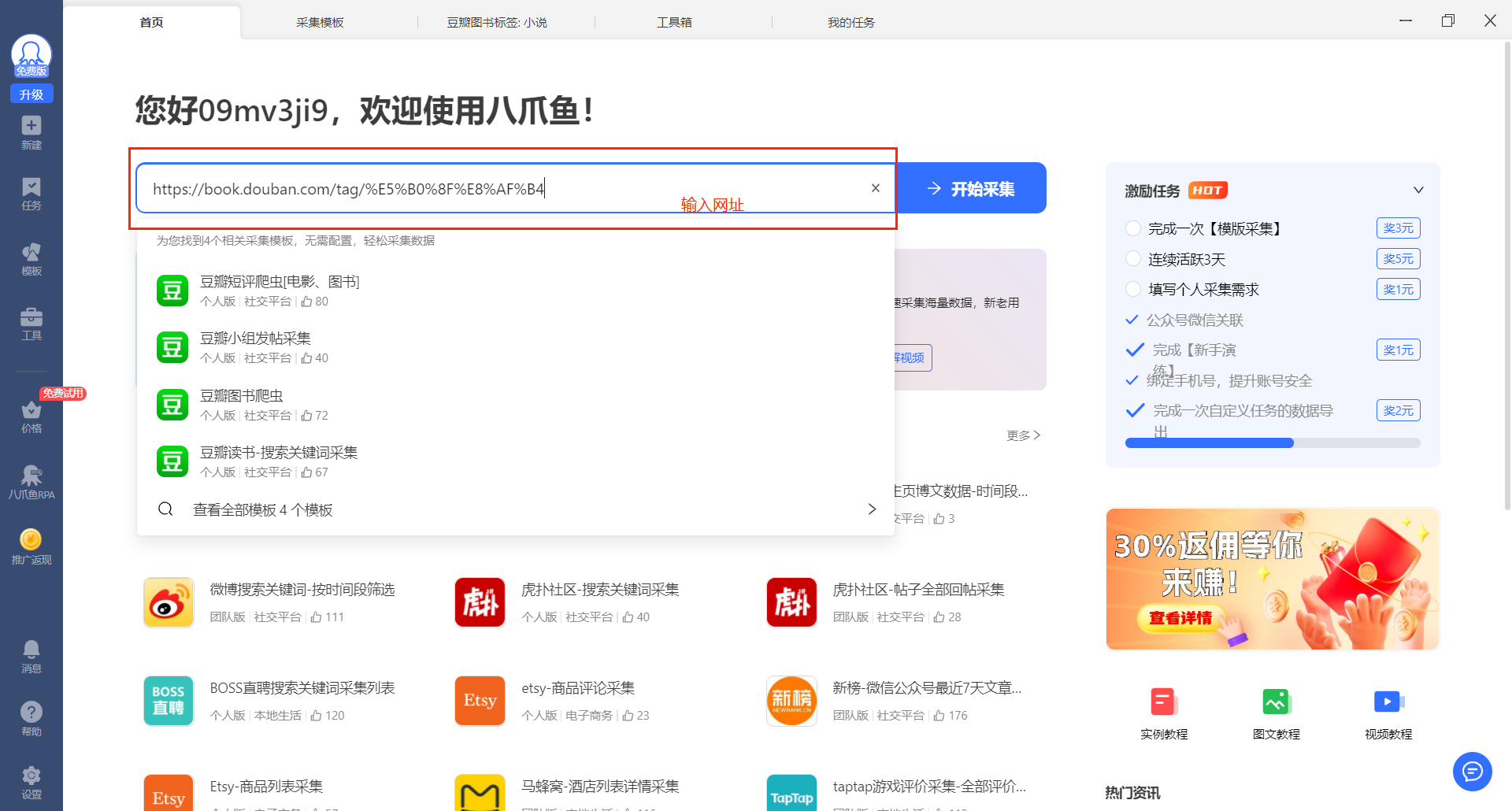
进入到采集页面后,我们观察到客户端右边有一栏规则,规则内只有一个打开网页,底部是数据预览区域,目前没有配置规则,所以为空。
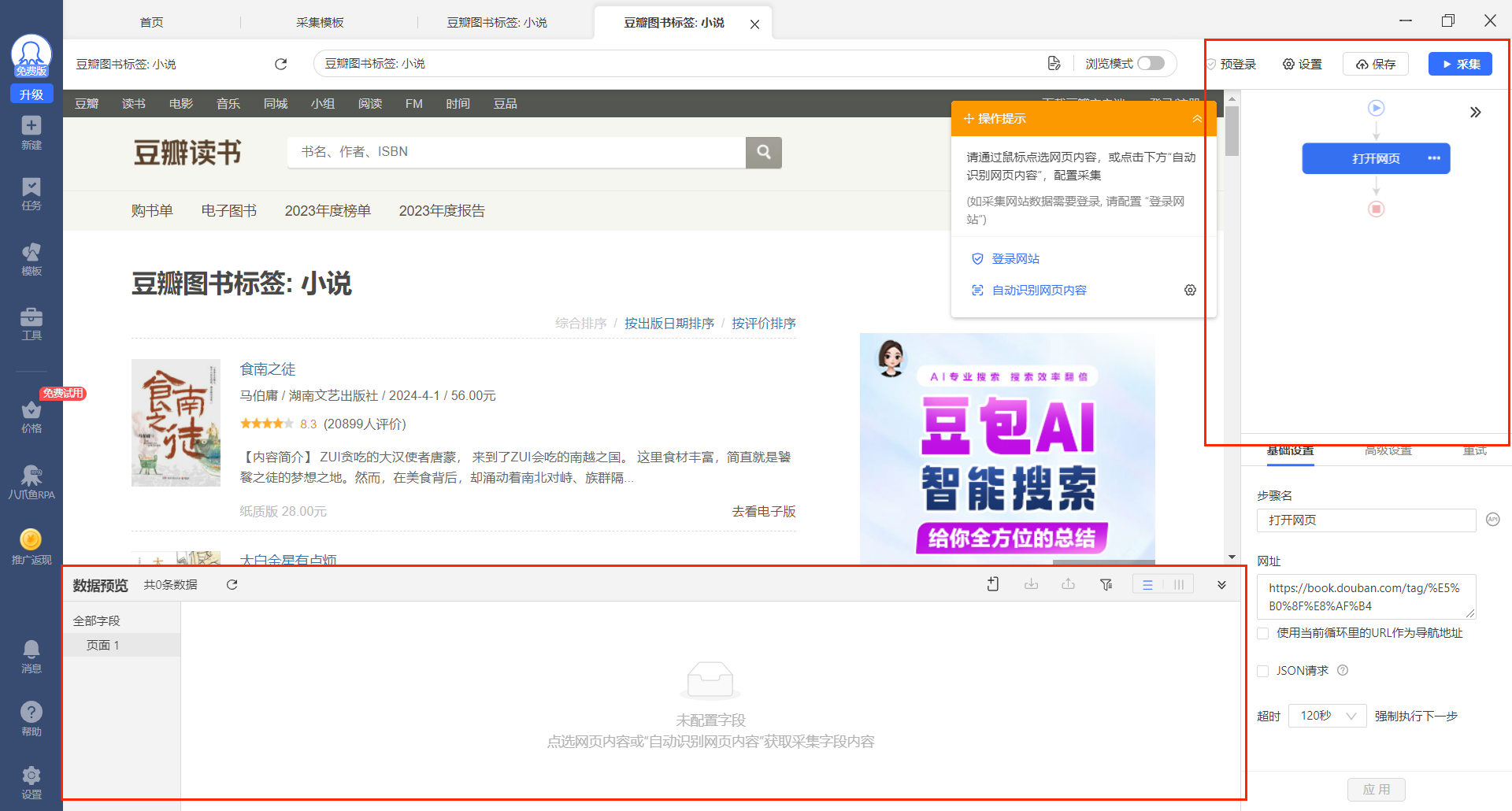
2.选中要采集的元素 提取数据
选中图书的标题,观察到网页内选中标题绿色高亮,底下相似的标题显示红色虚线,同时操作提示也发生了变化,出现了【提取数据】和【鼠标操作】两类以及【选中全部相似元素】
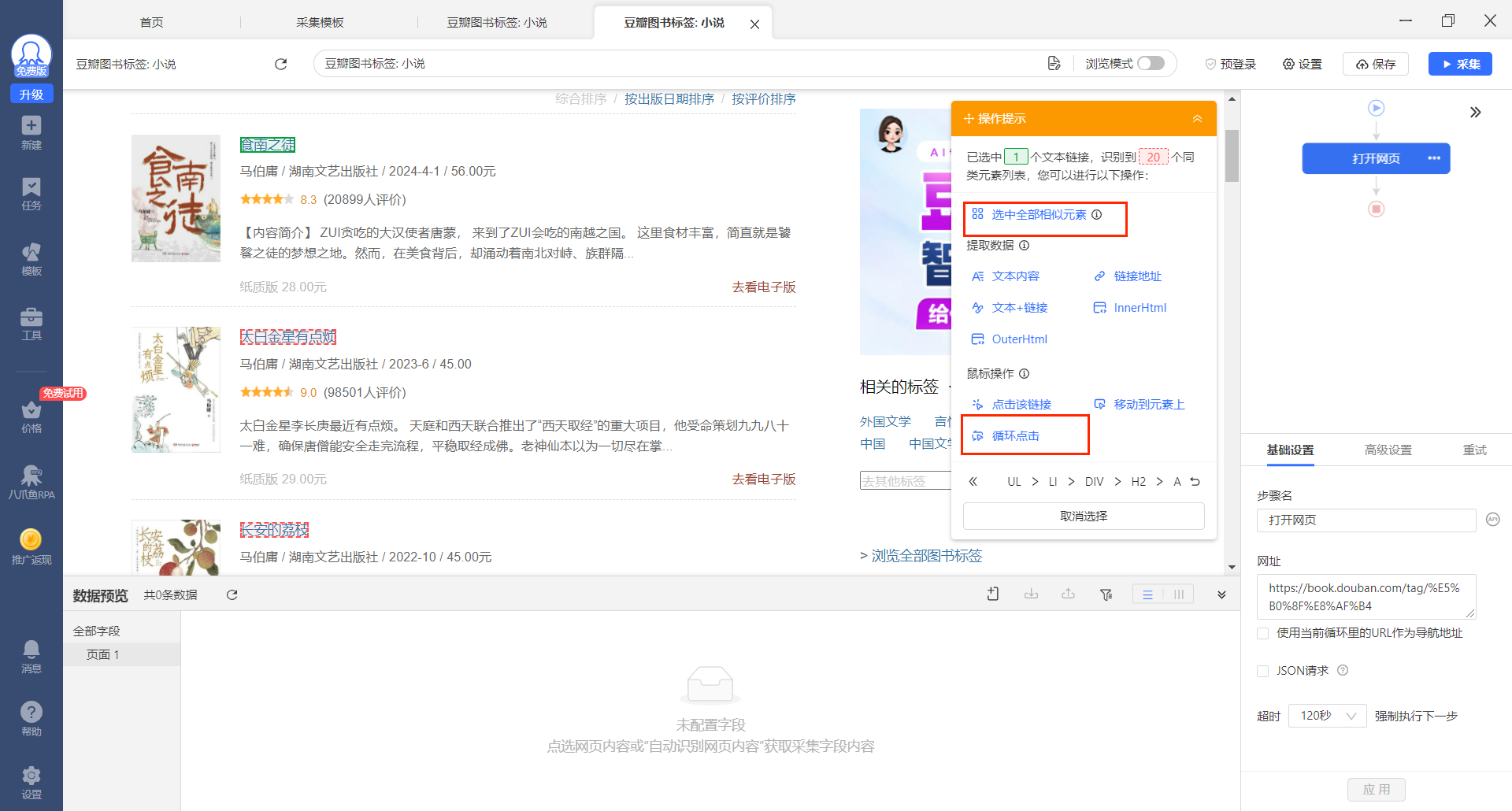
我们选择【选中全部相似元素】,可以看到所有红色虚线的都变为绿色,并且底部也出现绿色数据的预选框,这时我们就选中了全部相似元素(所有图书的标题元素信息)同时观察到,我们的提示框也发生了变化,【鼠标操作】栏目内少了几项,这是因为我们采集器自动预判接下来的动作进行操作提示
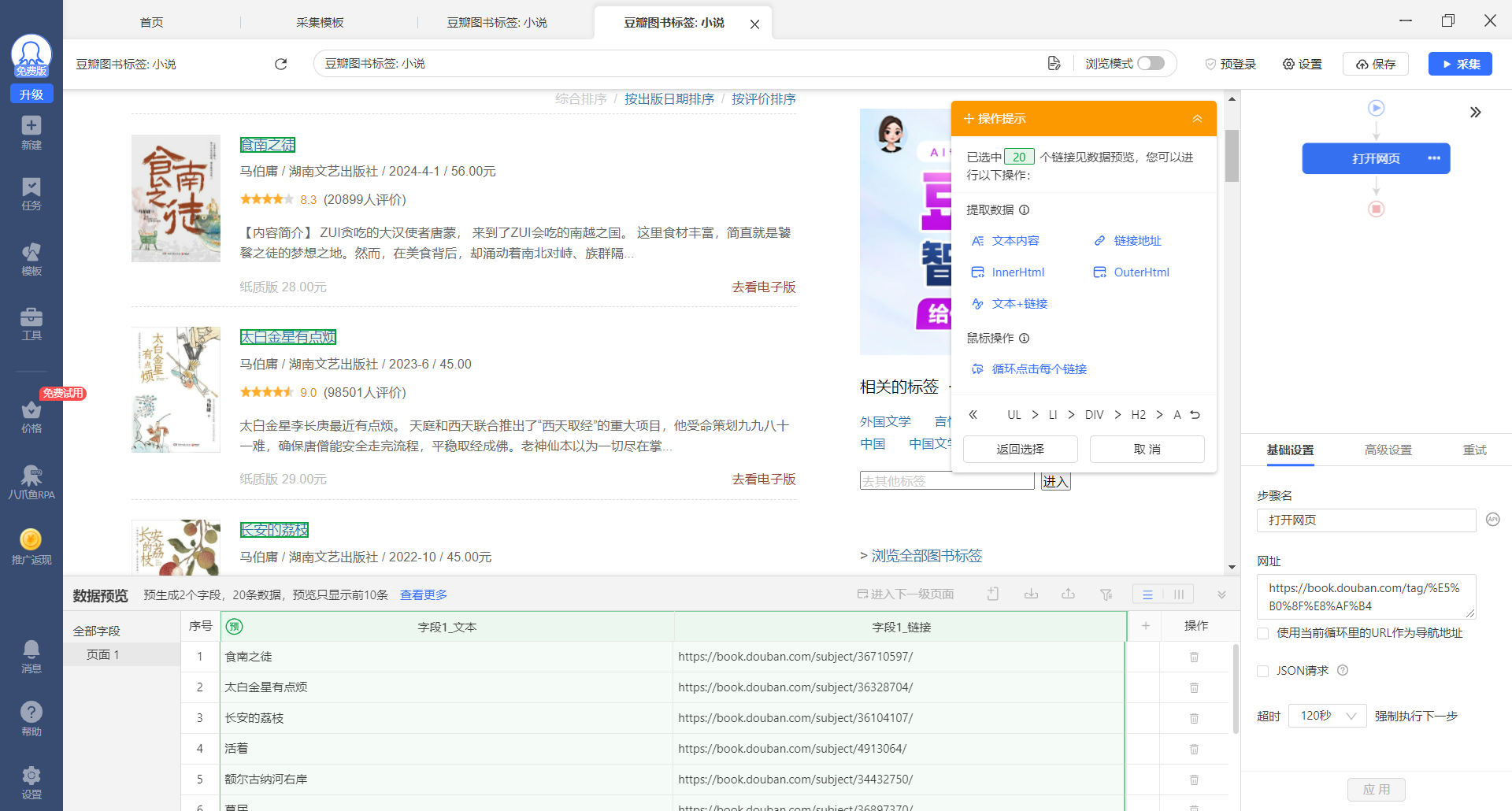
我们此时已经选中所有要采集的数据元素,但是我们还没有明确要采集元素内的什么信息,因为网页上的某个元素块可能包含文本信息,链接信息,以及网页源代码信息,我们采集图书标题的文本信息,选择【文本内容】
可以看到页面又发生了变化,原本的网页内的选中框已经消失,底部的绿色预选框也变为白色,这意味着我们已经选择好了要采集的数据,并且已经在右边生成了相对应的规则,同时操作提示又发生了变化,提示我们是否要翻页等等,这里我们不需要翻页,修改字段名称点击采集即可

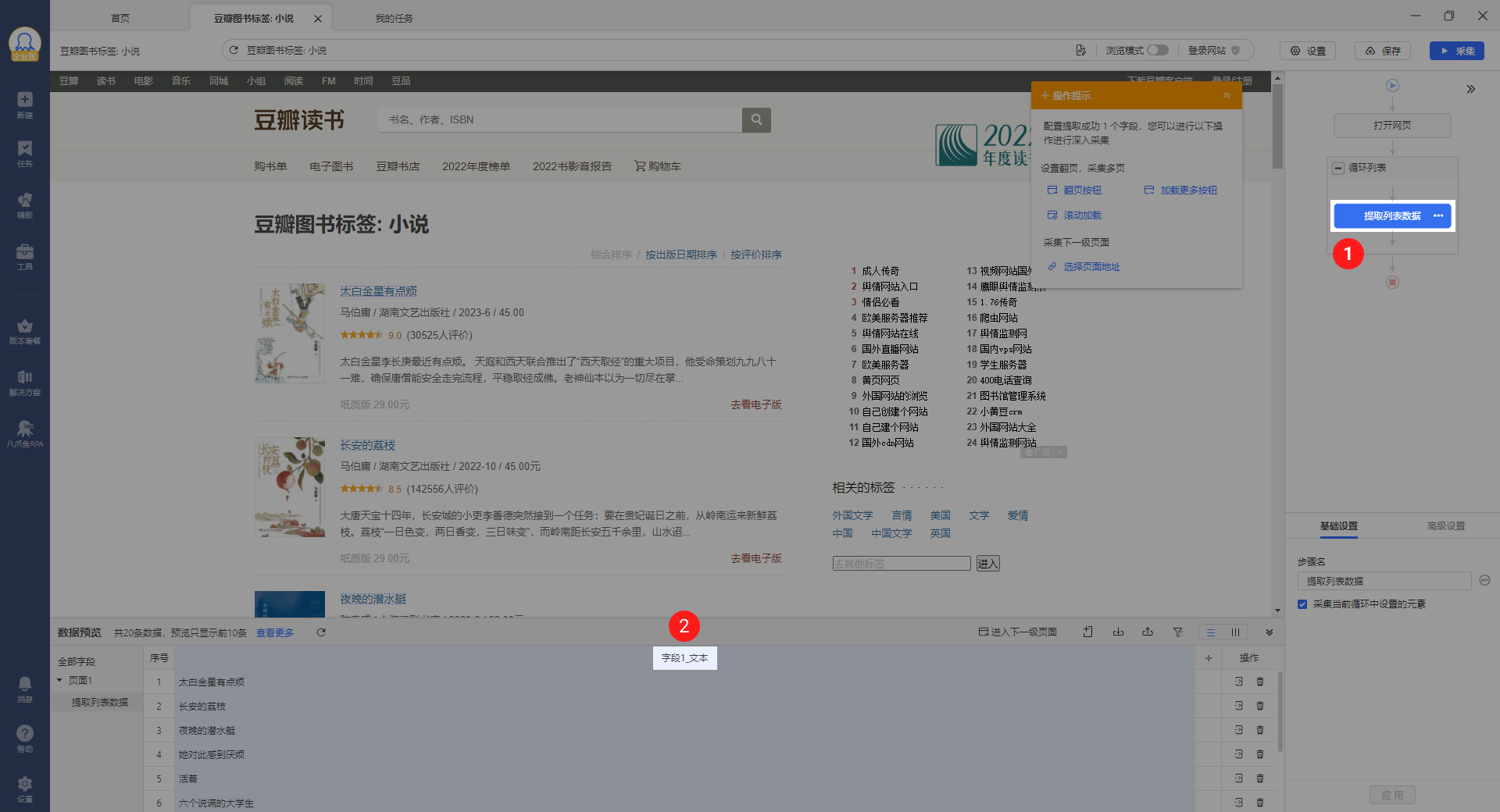
3.修改字段名称
选中提取列表数据,双击修改字段名,修改为图书名
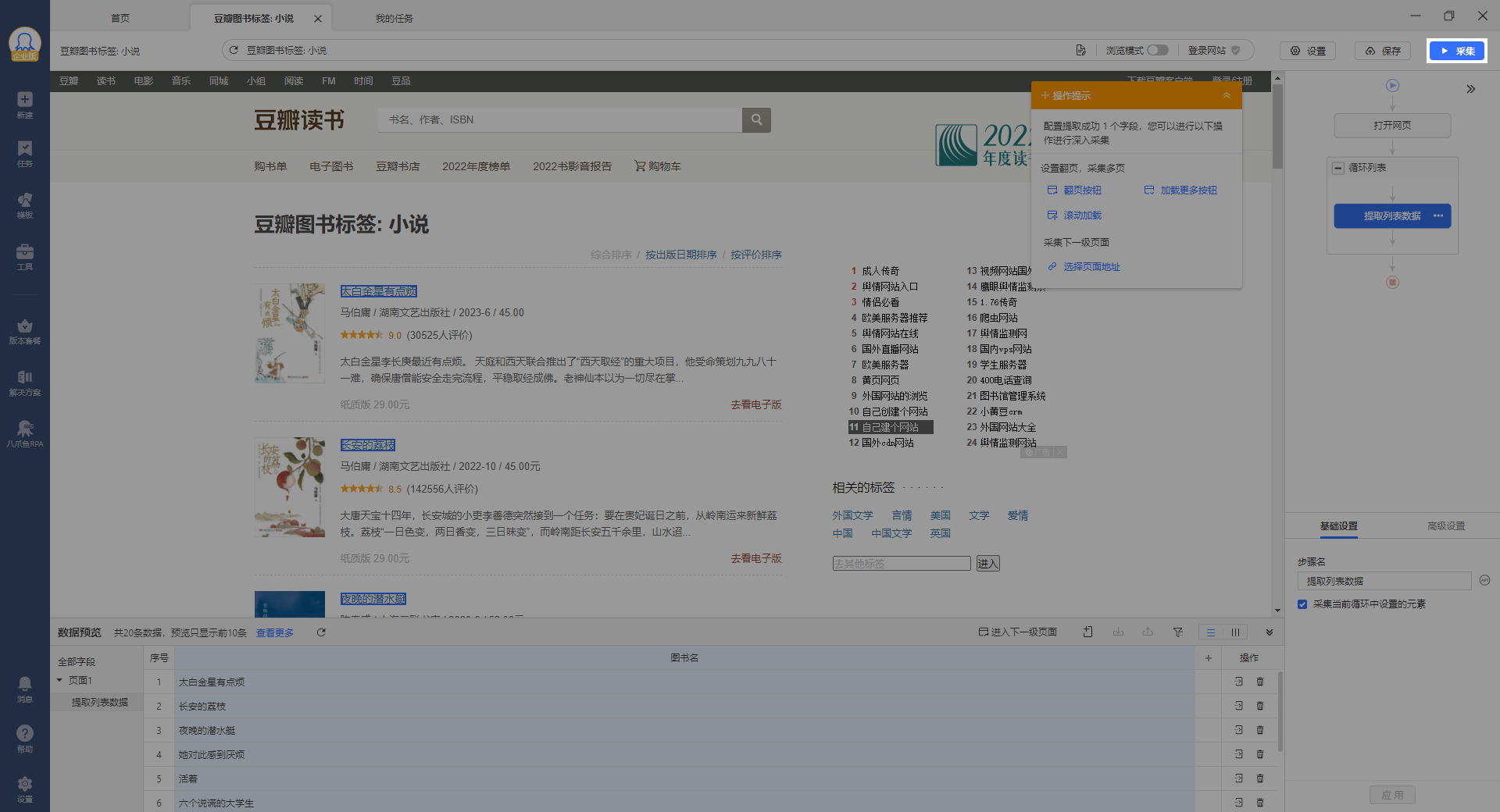
4.开始采集
修改完成后,点击采集
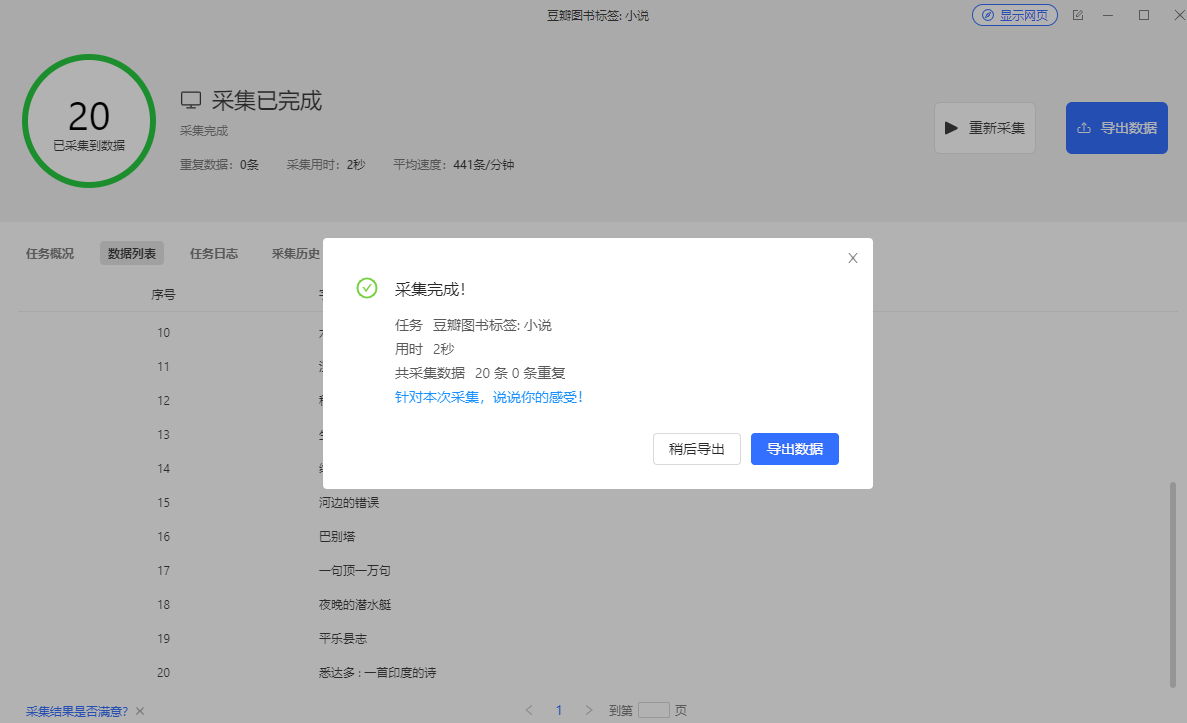
5.导出数据
将采集到的全部数据,导出到本地或者数据库
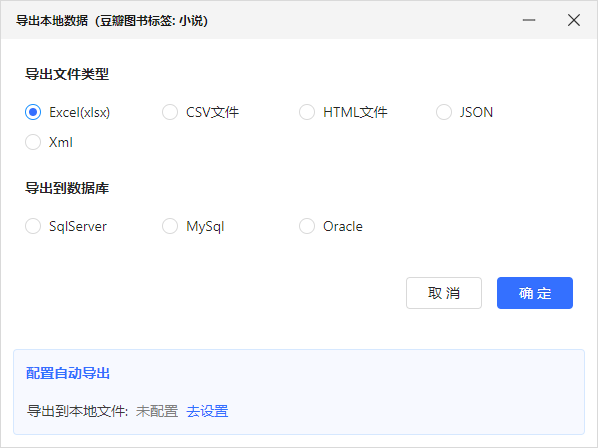
选择导出的格式
若有收获,就点个赞吧

















 6186
6186

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









