






决策树的目的:
根据给定的训练数据集构建一个决策树模型,或者说从训练集中归纳出一组分类规则,使它能够对实例进行正确的分类。
创建决策树有三步:
特征选择、决策树生成、决策树修剪
决策树学习的算法通常是一个递归地选择最优特征,并根据该特征对训练数据进行分割,使得各个子数据集有一个最好的分类的过程。这一过程对应着对特征空间的划分,也对应着决策树的构建。
决策树的生成过程:
1)构建根节点,将所有训练数据都放在根节点,选择一个最优特征,按着这一特征将训练数据集分割成子集,使得各个子集有一个在当前条件下最好的分类。
2) 如果这些子集已经能够被基本正确分类,那么构建叶节点,并将这些子集分到所对应的叶节点去。
3)如果还有子集不能够被正确的分类,那么就对这些子集选择新的最优特征,继续对其进行分割,构建相应的节点,如果递归进行,直至所有训练数据子集被基本正确的分类,或者没有合适的特征为止。
4)每个子集都被分到叶节点上,即都有了明确的类,这样就生成了一颗决策树
特征的评估与选择:
如果一个特征具有更好的分类能力,或者说,按照这一特征将训练数据集分割成子集,使得各个子集在当前条件下有最好的分类,那么就更应该选择这个特征。
信息增益就能够很好地表示这一直观的准则。在划分数据集之前之后信息发生的变化成为信息增益,知道如何计算信息增益,我们就可以计算每个特征值划分数据集获得的信息增益,获得信息增益最高的特征就是最好的选择。


决策树的组成和创建
1.决策节点(特征,图中圆)
2.叶子节点(目标对象,图中方块)
3.决策树的深度(层数,图中4层)
从数据集构造决策树算法所需的子功能模块工作原理如下:得到原始数据集,然后基于最好的属性值划分数据集,由于特征值可能多于两个,因此可能存在大于两个分支的数据集划分,第一次划分之后,数据将被向下传递到树分支的下一个节点,在此节点在此划分数据,因此可以使用递归的原则处理数据集。程序完全遍历所有划分数据集的属性,或者每个分支下的所有实例都具有相同的分类,如果所有实例具有相同的分类,则得到一个叶子节点或者终止块,任何到达叶子节点的数据必然属于叶子节点的分类。

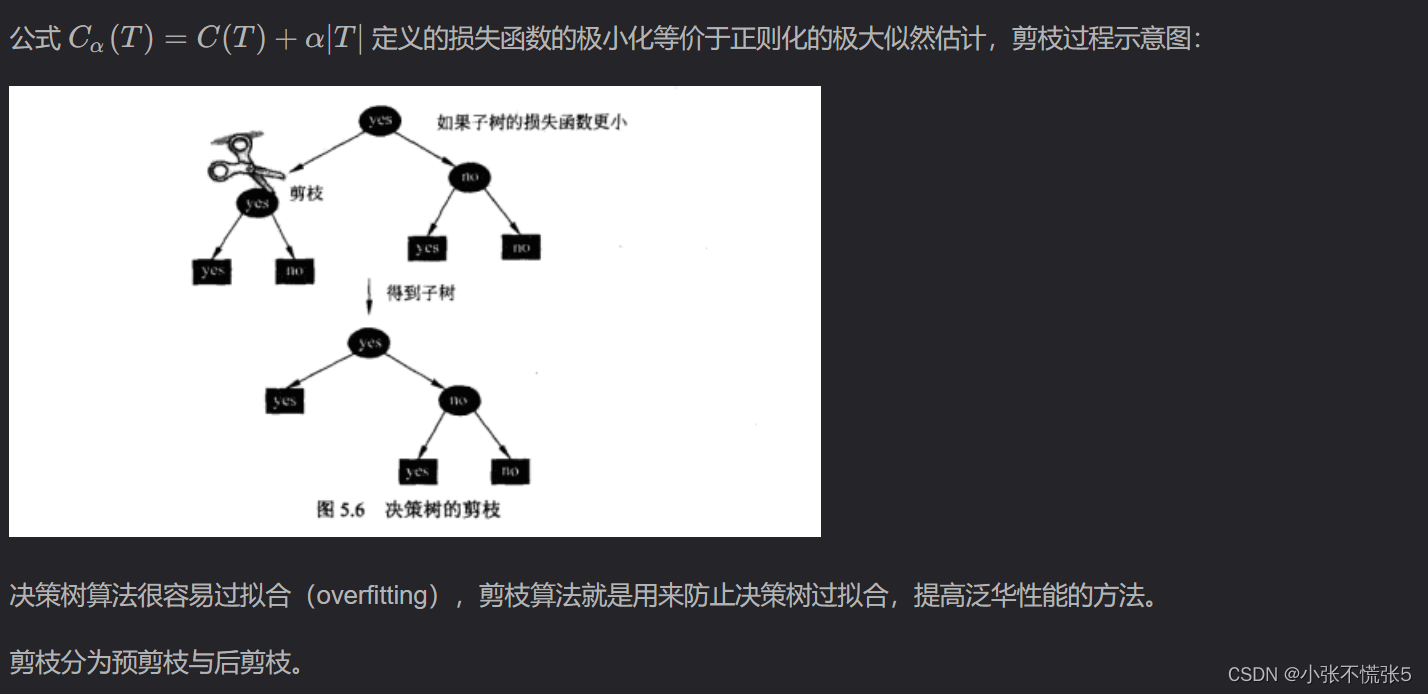
3. 决策树的剪枝
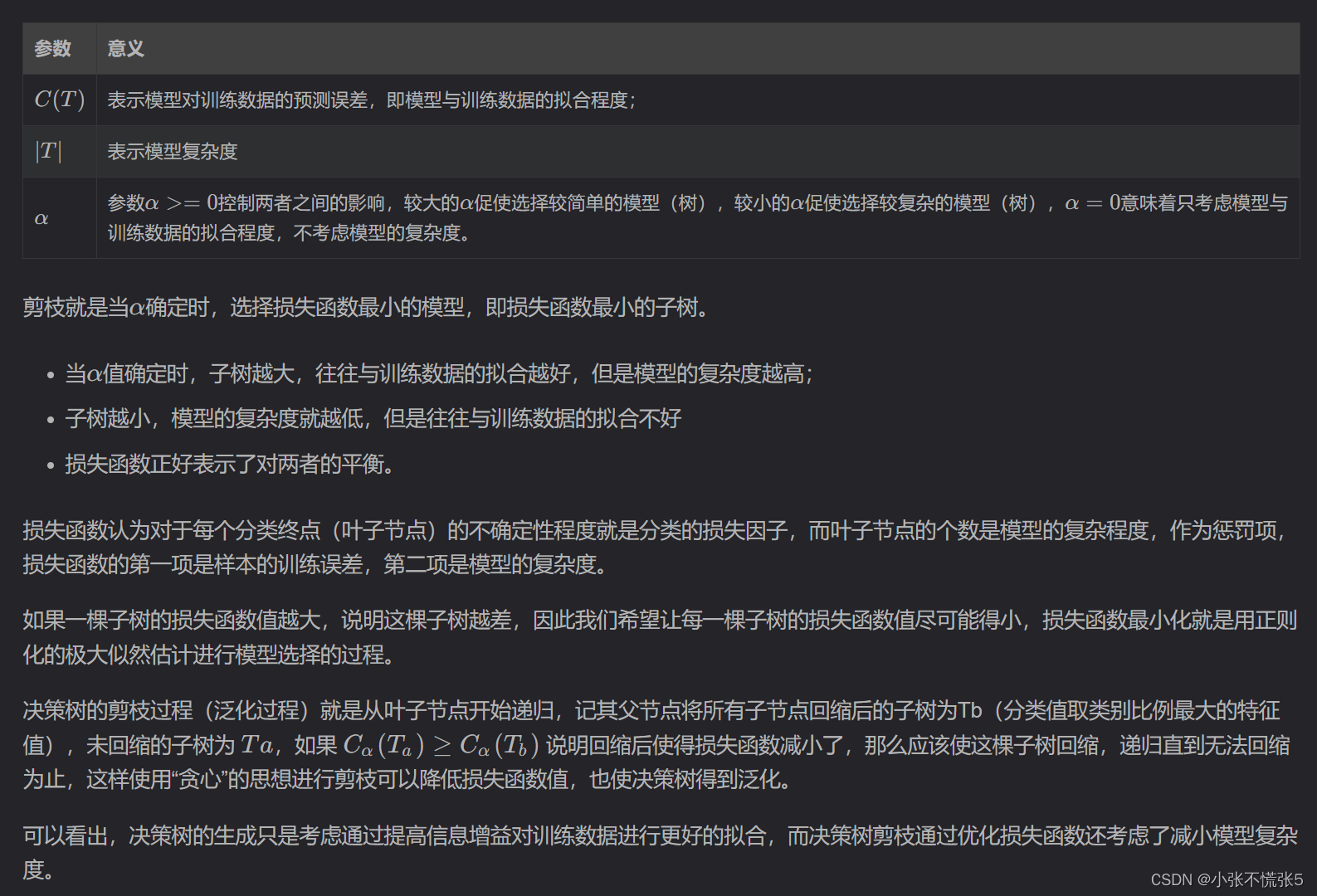
决策树生成算法递归的产生决策树,直到不能继续下去为止,这样产生的树往往对训练数据的分类很准确,但对未知测试数据的分类缺没有那么精确,即会出现过拟合现象。
过拟合产生的原因在于在学习时过多的考虑如何提高对训练数据的正确分类,从而构建出过于复杂的决策树,解决方法是考虑决策树的复杂度,对已经生成的树进行简化。
剪枝(pruning):从已经生成的树上裁掉一些子树或叶节点,并将其根节点或父节点作为新的叶子节点,从而简化分类树模型。
实现方式:极小化决策树整体的损失函数或代价函数来实现
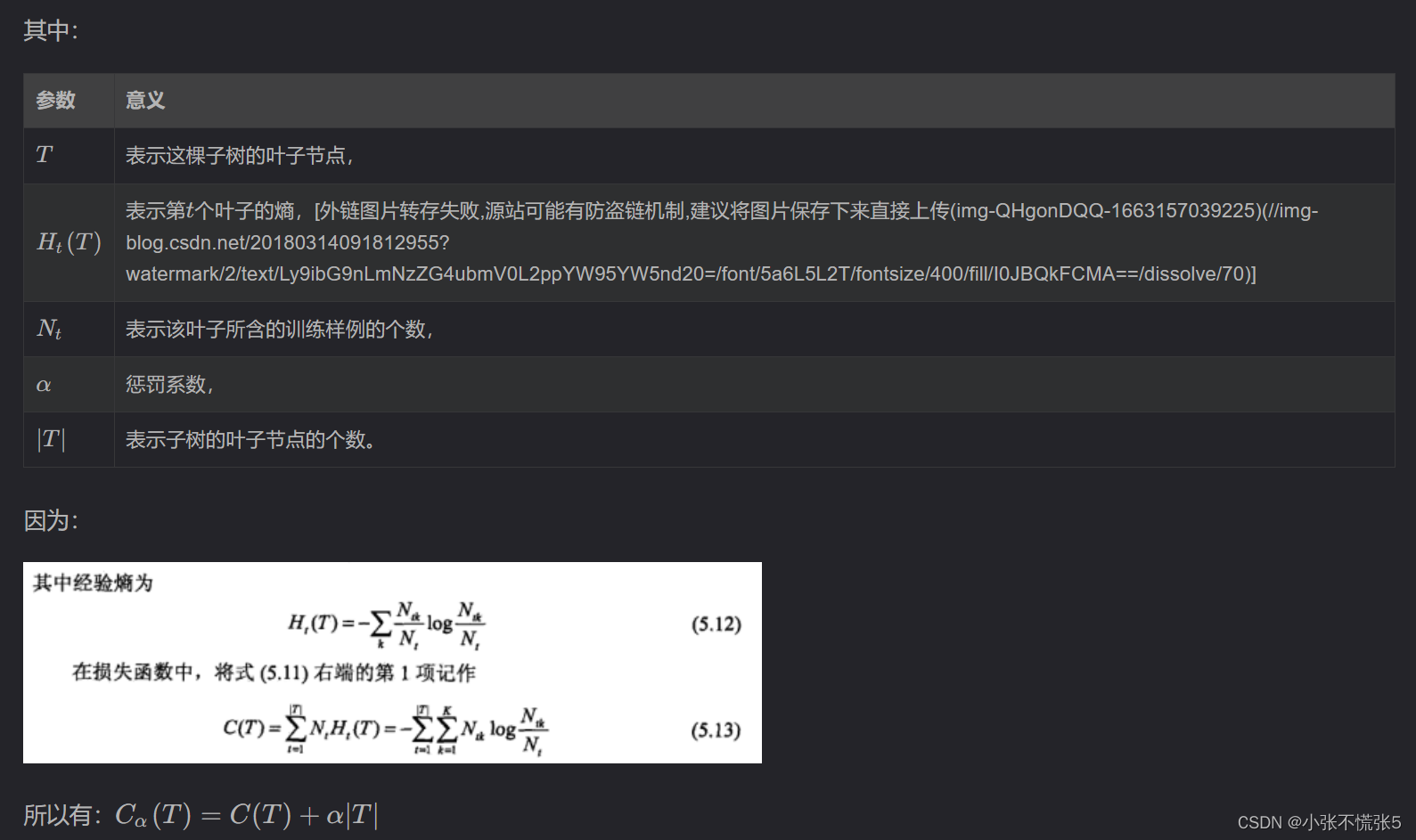
决策树学习的损失函数定义为:
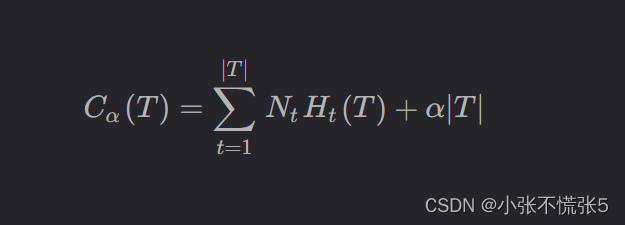

















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









