






1.获取数据集,并清洗数据

2.提取特征向量,并进行编码分类
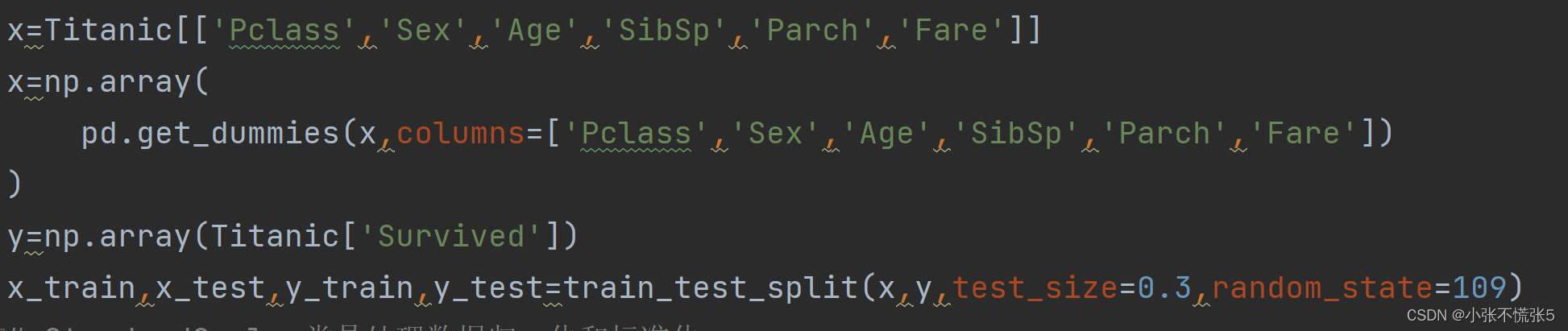
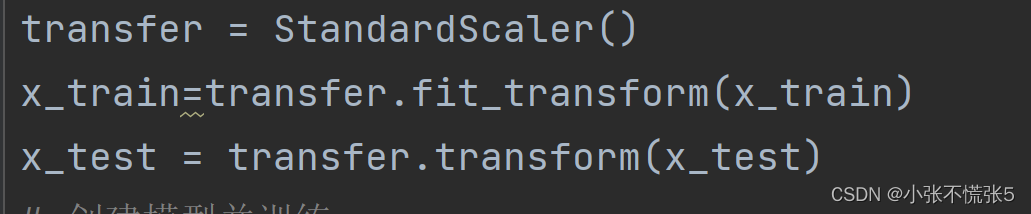
3.StanderScaler类是处理数据归一化和标准化,其中的原理是:
这段代码的转换函数为:z = (x - u) / s,其中z为转换后的值,x为当前值,u为均值,s为样本的标准差。通过该标准化操作,可以使每一列的数据都按照其均值为0,标准差为1的分布进行转换,以便更好地适应机器学习算法的训练和预测过程。
4。创建模型,并采用不同的核函数训练数据集
 5.使用分类报告和混淆矩阵评估每个 SVM 模型在测试集上的性能
5.使用分类报告和混淆矩阵评估每个 SVM 模型在测试集上的性能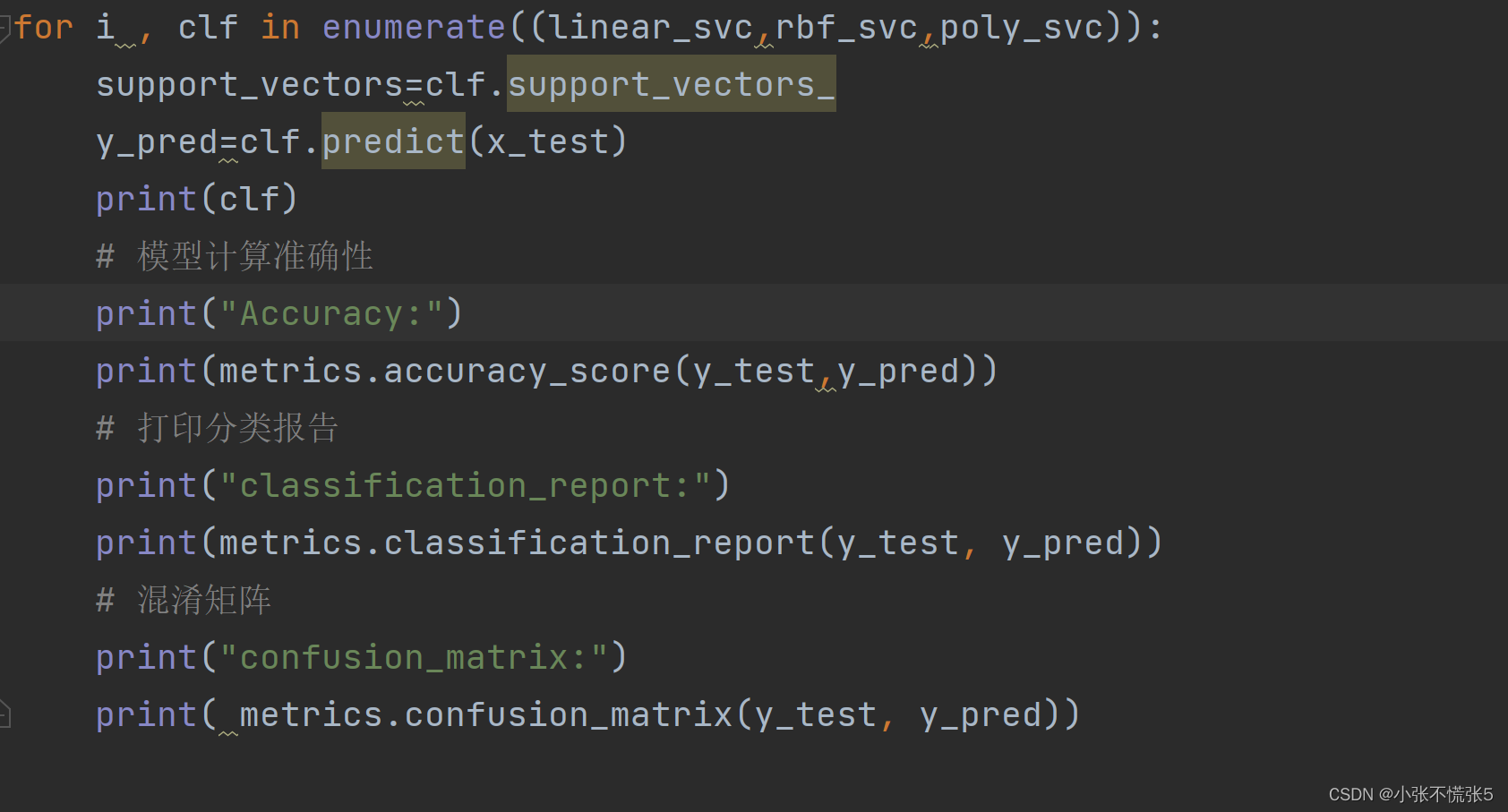
1.获取数据集,并清洗数据
2.提取特征向量,并进行编码分类
3.StanderScaler类是处理数据归一化和标准化,其中的原理是:
这段代码的转换函数为:z = (x - u) / s,其中z为转换后的值,x为当前值,u为均值,s为样本的标准差。通过该标准化操作,可以使每一列的数据都按照其均值为0,标准差为1的分布进行转换,以便更好地适应机器学习算法的训练和预测过程。
4。创建模型,并采用不同的核函数训练数据集
5.使用分类报告和混淆矩阵评估每个 SVM 模型在测试集上的性能
 745
745











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言
























