






Hadoop启动
小白的Linux学习笔记 2024/4/22 16:19
文章目录
怎么解决海量数据存储?
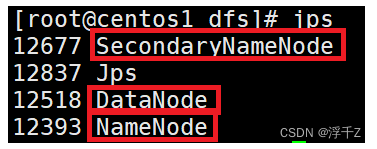
需要下面三个程序:namenode,datanode,Secondarynamenode
大数据技术:单机版数据存储是有限制的
所以分而治之,分布式存储
- 自动分块
- 分布式存储
- 备份
datanode可以分开存,但是不知道谁是谁
所以还需要账本
namenode就是做账本的,类似借钱,先记下什么时候借给谁了,然后借,最后对着账本收回
namenode负责:(做账本)
接受用户请求(读写)
维护文件斯通目录结构:Hadoop值维护逻辑结构,并没真正文件夹
管理文件与block之间的关系,bolck与datanode之间的关系
datanode负责
存储文件
文件被分成block存储在磁盘上
为了安全,会生成多个副本
Secondarynamenode(账本备份)
之间的通信通过socket
如何实现上面的程序?
start-dfs.sh

查看java进程
jps
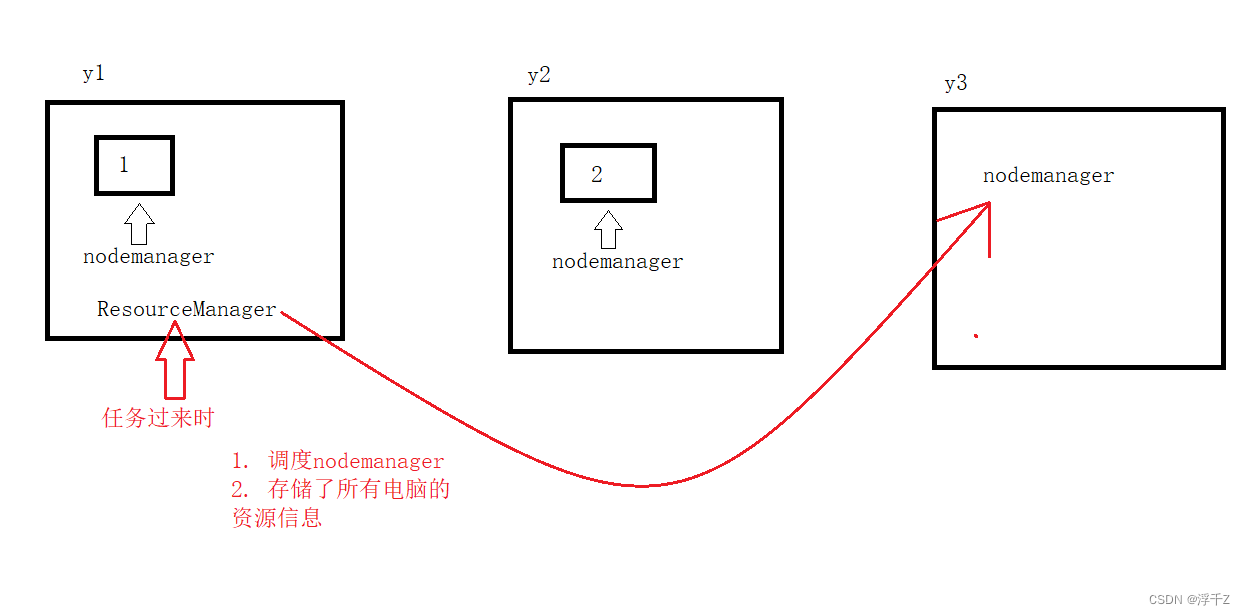
如何解决海量计算?
nodemanager
每台电脑上都有nodemanager程序
ResourceManager
如果资源被占用完了,如何调度资源?
- 调度nodemanager
- 存储了所有电脑的资源信息
start-yarn.sh
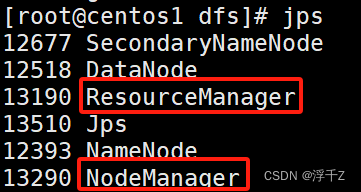
测试
把Linux下的文件上传到Hadoop上
hadoop fs -put linux文件路径 Hadoop路径
hadoop fs -put /root/a.txt /
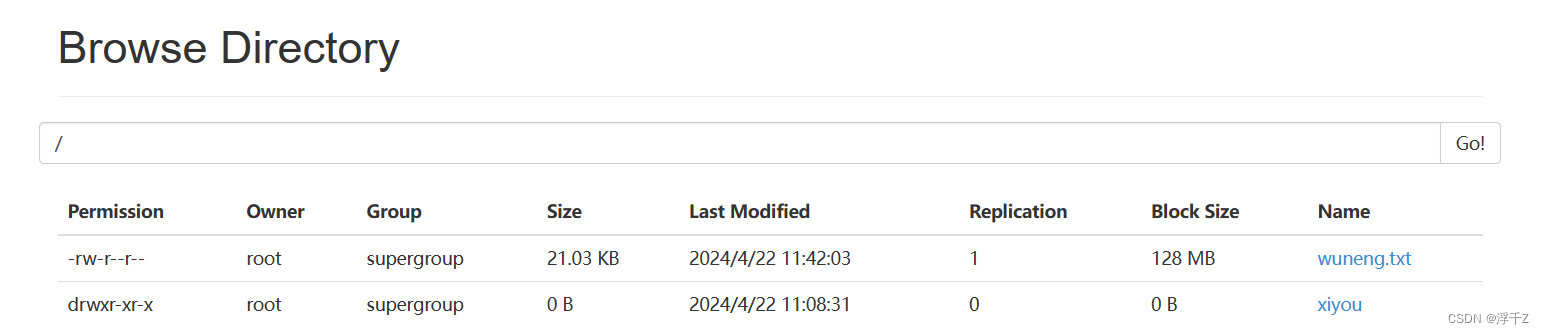
查看Hadoop根目录下的文件和目录
hadoop fs -ls /

192.168.38.101:50070

JavaAPI
目的:想用java程序把文件传到Hadoop上
maven下载配置

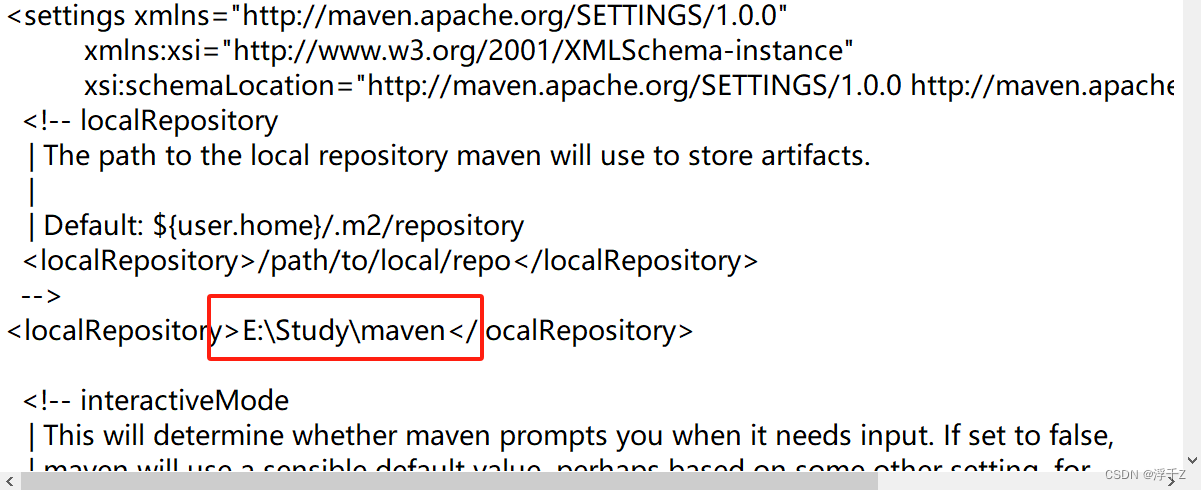
解压,找一个空间大点的位置,创建一个repository文件夹
然后找到这个文件,文本文档打开
修改位置为你自己选择的位置
maven作用
从网上下载jar包,为什么要下载Hadoop jar包?
只能用他(Hadoop作者)写好的类,其中实现了文件上传功能,所以要调用Hadoop的类
想操作MySQL,也要用MySQL提供的类
Hadoop有几十个jar包,一个一个找很费劲,所以maven的作用就体现出来了,能自动下载需要的jar包
idea创建新的工程

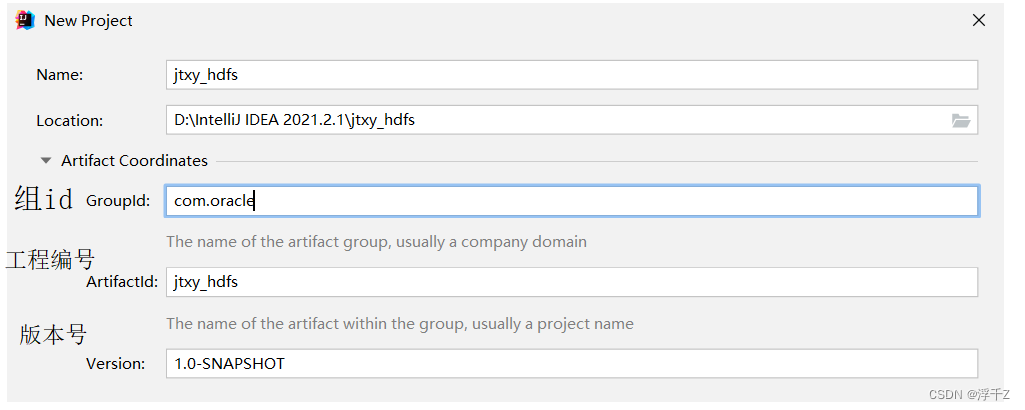
一个工程,分多个模块来做,开发中会产生很多子项目,这些子项目都属于同一个组
要定位一个子项目,通过组id、工程名、版本号就能定位
配置idea与maven关联(不能自动关联)
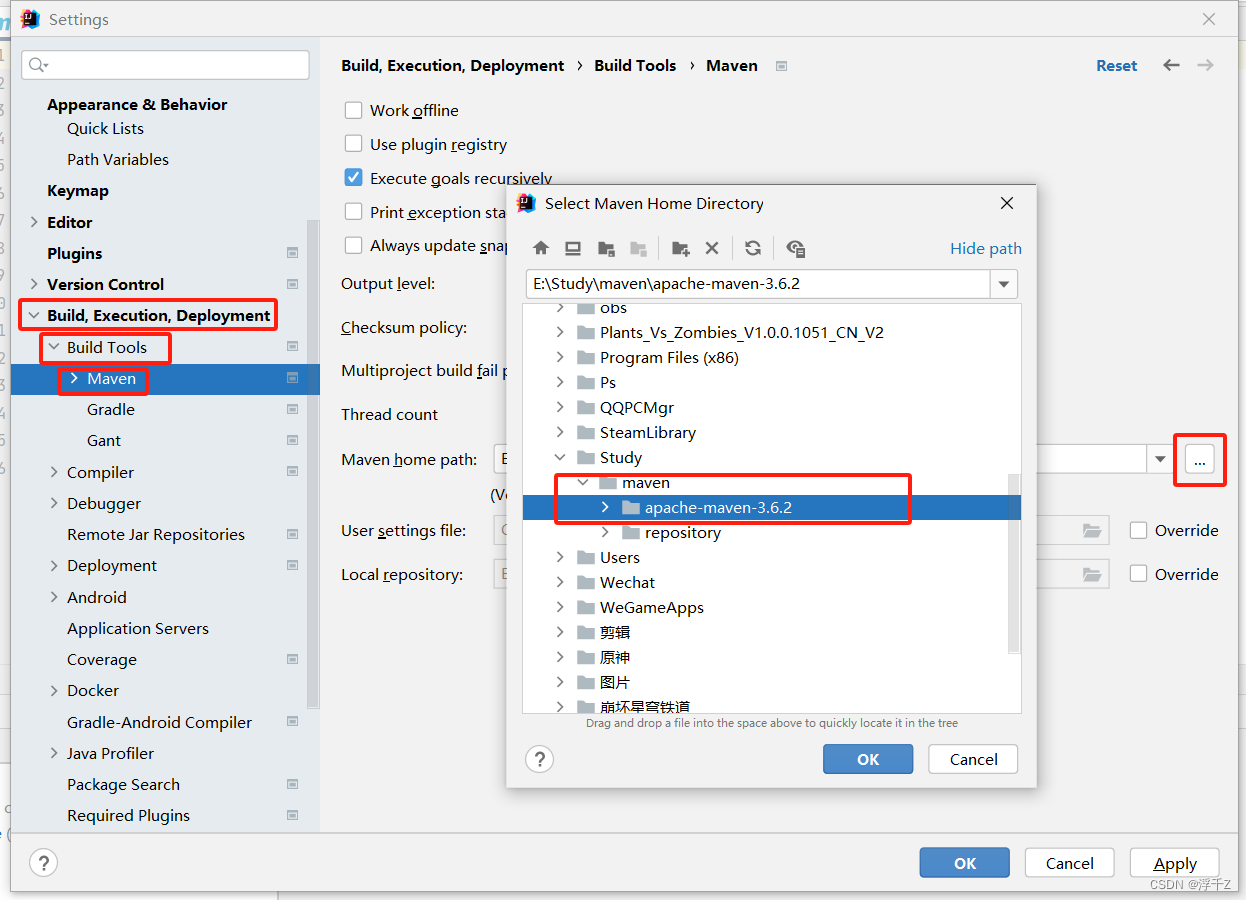
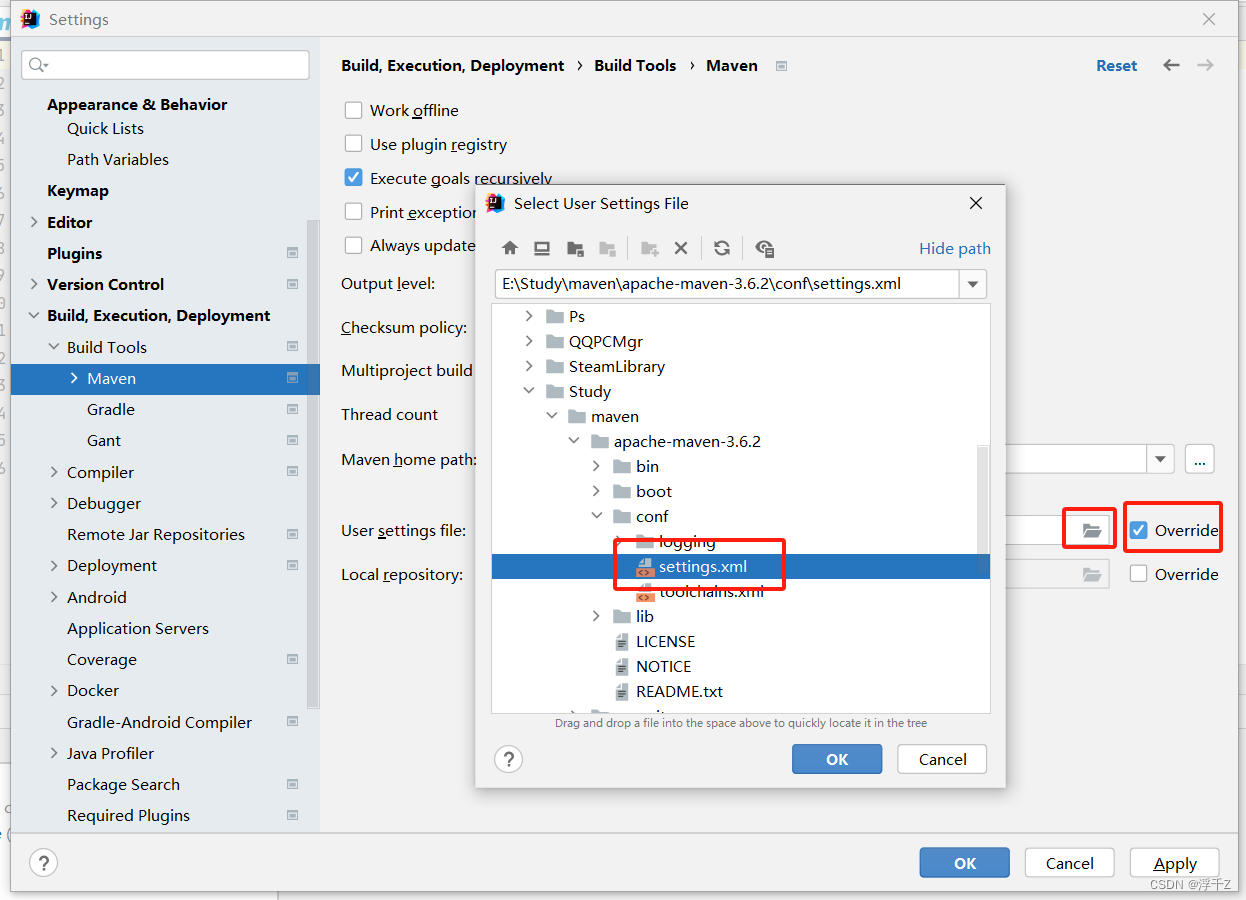
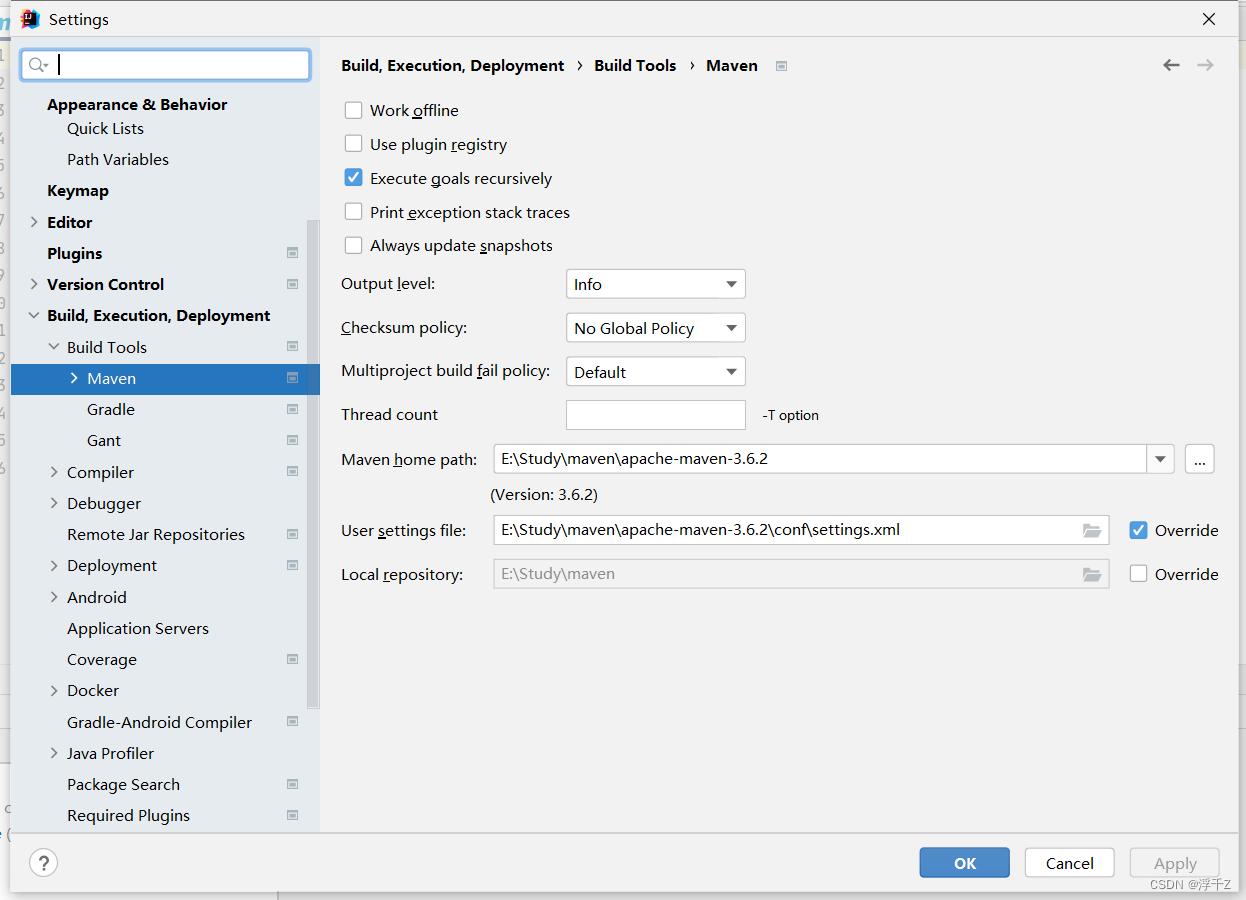
ok之后稍等
hadoop依赖jar的坐标
把下面代码覆盖到如图位置
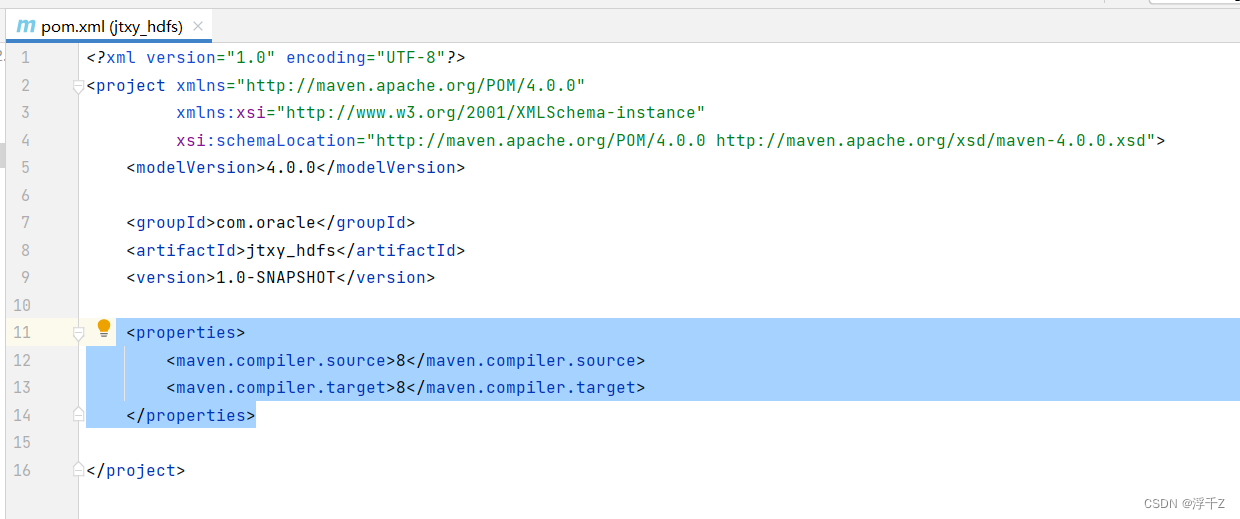
<properties>
<maven.compiler.source>8</maven.compiler.source>
<maven.compiler.target>8</maven.compiler.target>
<mysql.version>5.1.6</mysql.version>
<hadoop.version>2.7.1</hadoop.version>
<hbase.version>1.1.2</hbase.version>
<lzo_hadoop_verion>1.0.0</lzo_hadoop_verion>
</properties>
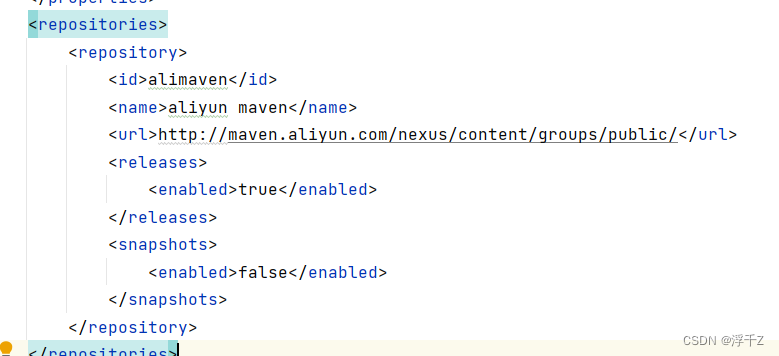
<repositories>
<repository>
<id>alimaven</id>
<name>aliyun maven</name>
<url>http://maven.aliyun.com/nexus/content/groups/public/</url>
<releases>
<enabled>true</enabled>
</releases>
<snapshots>
<enabled>false</enabled>
</snapshots>
</repository>
</repositories>
<pluginRepositories>
<pluginRepository>
<id>maven-net-cn</id>
<name>Maven China Mirror</name>
<url>http://maven.net.cn/content/groups/public/</url>
<releases>
<enabled>true</enabled>
</releases>
<snapshots>
<enabled>false</enabled>
</snapshots>
</pluginRepository>
</pluginRepositories>
<dependencies>
<!--groupid:-->
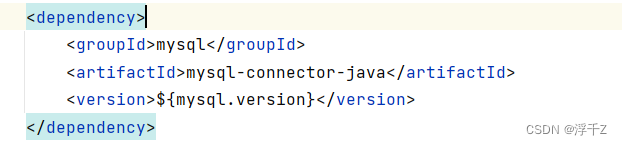
<dependency>
<groupId>mysql</groupId>
<artifactId>mysql-connector-java</artifactId>
<version>${mysql.version}</version>
</dependency>
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-common</artifactId>
<version>${hadoop.version}</version>
</dependency>
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-hdfs</artifactId>
<version>${hadoop.version}</version>
</dependency>
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-mapreduce-client-core</artifactId>
<version>${hadoop.version}</version>
</dependency>
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-mapreduce-client-jobclient</artifactId>
<version>${hadoop.version}</version>
</dependency>
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-mapreduce-client-common</artifactId>
<version>${hadoop.version}</version>
</dependency>
<dependency>
<groupId>org.apache.hbase</groupId>
<artifactId>hbase-it</artifactId>
<version>${hbase.version}</version>
<exclusions>
<exclusion>
<artifactId>jdk.tools</artifactId>
<groupId>jdk.tools</groupId>
</exclusion>
</exclusions>
</dependency>
<!-- <dependency>-->
<!-- <groupId>org.anarres.lzo</groupId>-->
<!-- <artifactId>lzo-hadoop</artifactId>-->
<!-- <version>${lzo_hadoop_verion}</version>-->
<!-- </dependency>-->
<!-- <dependency>-->
<!-- <groupId>org.anarres.lzo</groupId>-->
<!-- <artifactId>lzo-core</artifactId>-->
<!-- <version>${lzo_hadoop_verion}</version>-->
<!-- </dependency>-->
<dependency>
<groupId>org.apache.maven.plugins</groupId>
<artifactId>maven-assembly-plugin</artifactId>
<version>3.6.0</version>
</dependency>
</dependencies>
<build>
<sourceDirectory>src/main/java</sourceDirectory>
<testSourceDirectory>src/test</testSourceDirectory>
<plugins>
<plugin>
<groupId>org.apache.maven.plugins</groupId>
<artifactId>maven-assembly-plugin</artifactId>
<version>3.6.0</version>
<configuration>
<descriptorRefs>
<descriptorRef>jar-with-dependencies</descriptorRef>
</descriptorRefs>
<archive>
<manifest>
<mainClass>com.oracle.Test</mainClass>
</manifest>
</archive>
</configuration>
<executions>
<execution>
<id>make-assembly</id>
<phase>package</phase>
<goals>
<goal>single</goal>
</goals>
</execution>
</executions>
</plugin>
</plugins>
</build>
刷新
坐标
用来下载jar包的网址,通常设置国内的(下载快),如果不设置默认去国外的网站下载
利用Hadoop javaAPI把d:/a.txt 上传到Hadoop上
创建类Test1
package com.oracle.example;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.FSDataOutputStream;
import org.apache.hadoop.fs.FileSystem;
import org.apache.hadoop.fs.Path;
import java.net.URI;
public class Test1 {
public static void main(String[] args) {
//配置文件对象类,用于加载Hadoop的配置:比如:hdfs-default.xml 上传用于分块
Configuration configuration=new Configuration();
try {
//获取Hadoop文件系统 hdfs://192.168.38.101:9000 namenode
FileSystem fs=FileSystem.get(new URI("hdfs://192.168.38.101:9000"),configuration);
FSDataOutputStream out=fs.create(new Path("/b.txt"));
byte[] bytes = "aaaaaaaaaaaa".getBytes();//把字符串转换成字节数组
out.write(bytes);
out.close();
}
catch (Exception e){
e.printStackTrace();
}
}
}



查看是否成功
hadoop fs -ls /
















 8928
8928











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









