






安装Hadoop
小白的Linux学习笔记 2024/4/22 10:14
文章目录
Hadoop是java做的
Hadoop是java做的,所以需要java支持,把下图文件传入linux
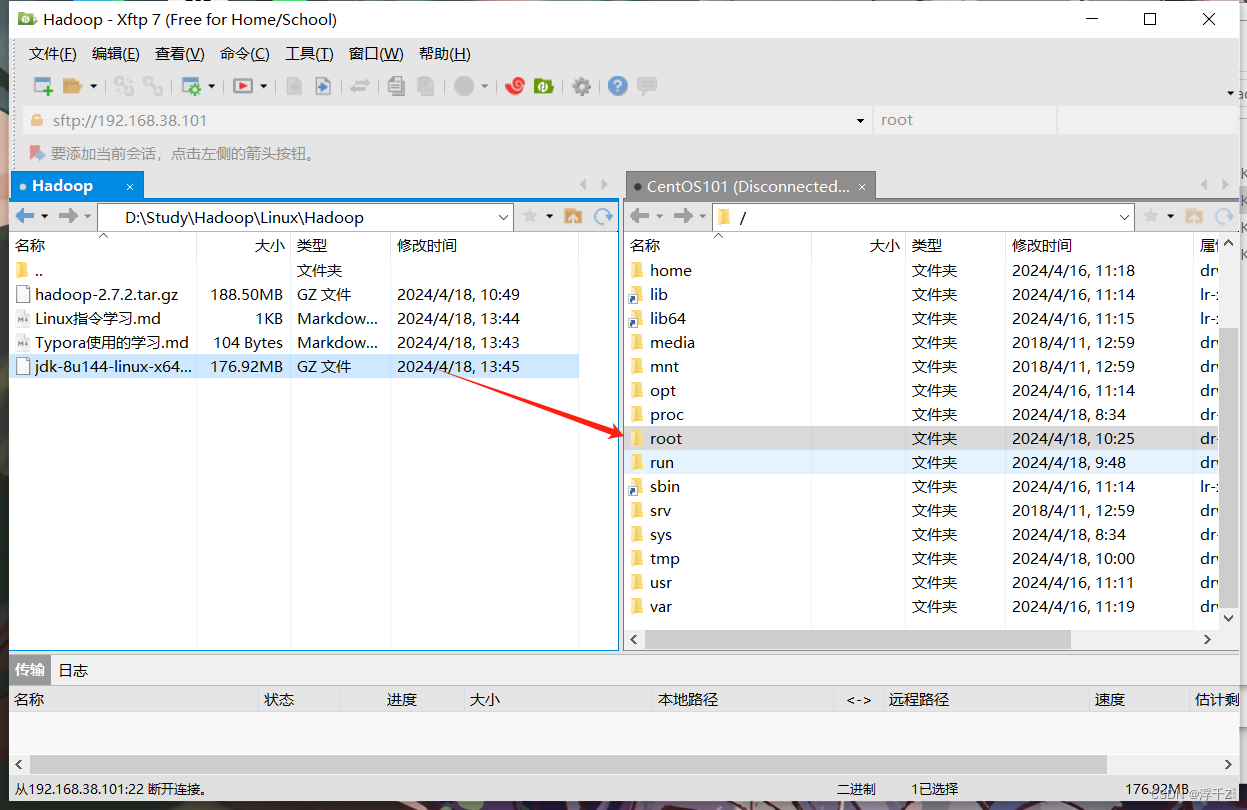
解压:
cd /usr/local
ll
tar -zxvf jdk1.8.0_144.tar.gz -C /usr/local
mv jdk1.8.0_144 jdk
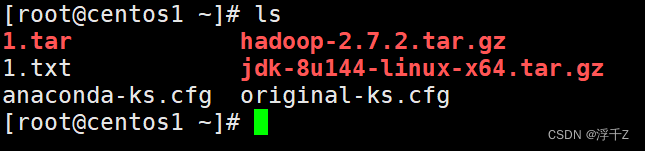
安装Hadoop
1.安装jdk
1.1 上传jdk到/root
1.2 tar
1.3 改名
tar -zxvf jdk-8u144-linux-x64.tar.gz -c /usr/local/
-x 抽取每一个文件
-v 能看到抽取的进度
-z 解压
-c 解压到什么地方
mv jdk1.8.0_144 jdk
mv 剪切
把jdk1.8.0_144 剪切到jdk中,在这里实现了改名的作用
.tar.gz 这种包,解压完就是安装完了
1.4 配置环境变量
1.5 source
配置环境变量
原因:第三方软件需要通过环境变量找到jdk
vi /etc/profile
profile :就是配置环境变量的地方,输入上面代码后找到如下图位置
export JAVA_HOME=/usr/local/jdk
export PATH=$PATH:$JAVA_HOME/bin
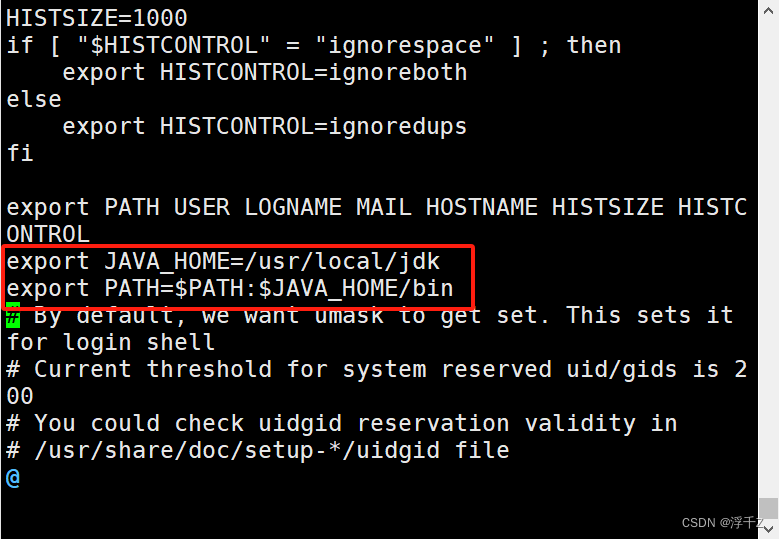
变量export之后,在很多地方都可以访问,子进程中也可以访问
shell 也是一门语言,和java一样
source /etc/profile
- 执行文件并从文件中加载变量及函数到执行环境
让刚才加的变量生效
2.配置文件
2.1 配置主机名和ip地址的映射
vim /etc/hosts
配置映射:ip地址 主机名

192.168.38.101 centos1
为什么配映射?
因为ip地址不好记,写起来麻烦,所以给ip地址起个别名,以后可以用这个名字代替ip地址
2.2 解压Hadoop到 /usr/local下
①解压
②进入local
③改名
tar -zxvf hadoop-2.7.2.tar.gz -C /usr/local
cd /usr/local
mv hadoop-2.7.2/ hadoop
2.4 配置xml文件
2.4.1 配置jdk位置
①进入
cd /usr/local/hadoop/etc/hadoop/
vim hadoop-env.sh
修改这里

改成
export JAVA_HOME=/usr/local/jdk

2.4.2 配置core-site.xml
在/usr/local/hadoop/etc/hadoop下
vim core-site.xml
- 额外,xml是什么?
- xml是一种存储结构化数据的格式
- 它的数据有规律,叫结构化(乱糟糟的就不是结构化)
把下面的放在 中间
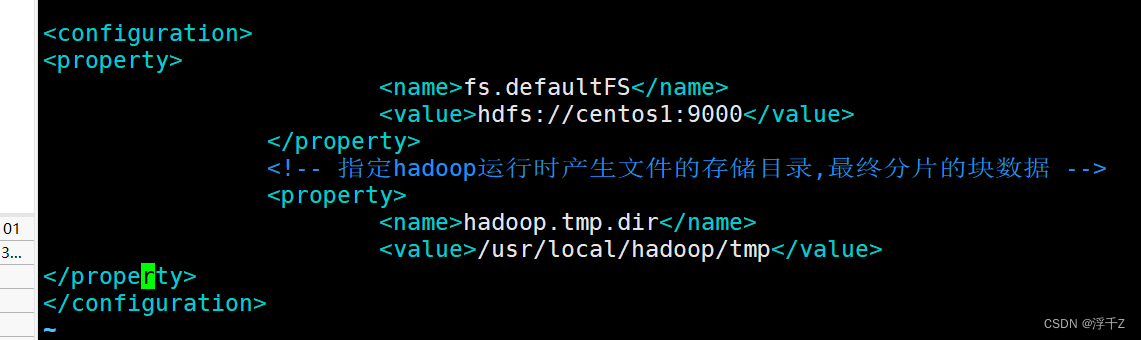
<!-- 制定HDFS的老大(NameNode)的地址,这文件存储系统 ,这里的老大是个进程,socket,hadoop.tmp.dir,数据和账本在linux上存储位置-->
<property>
<name>fs.defaultFS</name>
<value>hdfs://centos1:9000</value>
</property>
<!-- 指定hadoop运行时产生文件的存储目录,最终分片的块数据 -->
<property>
<name>hadoop.tmp.dir</name>
<value>/usr/local/hadoop/tmp</value>
</property>
- 其中centos是主机名,也可以写ip
然后保存退出
2.4.3 配置hdfs-site.xml
在/usr/local/hadoop/etc/hadoop下
vim hdfs-site.xml
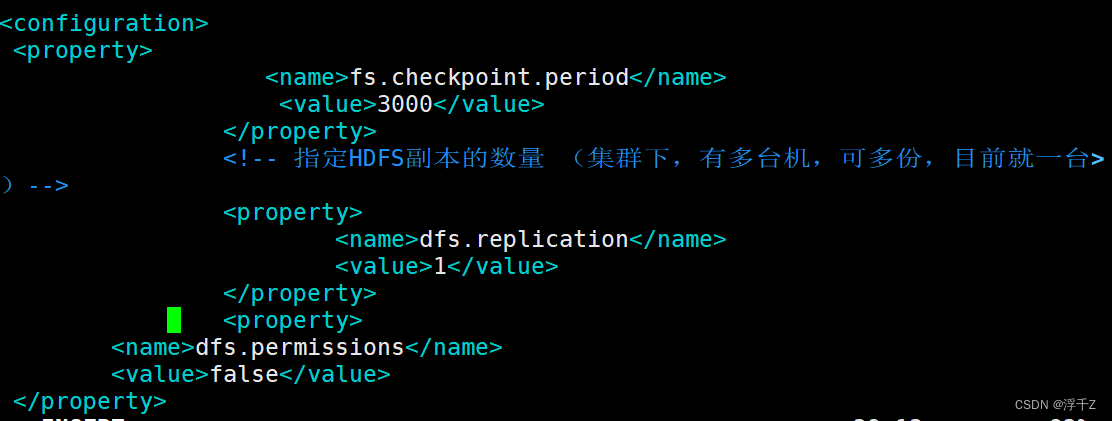
<property>
<name>fs.checkpoint.period</name>
<value>3000</value>
</property>
<!-- 指定HDFS副本的数量 (集群下,有多台机,可多份,目前就一台)-->
<property>
<name>dfs.replication</name>
<value>1</value>
</property>
<property>
<name>dfs.permissions</name>
<value>false</value>
</property>
2.4.4 配置mapred-site.xml
在/usr/local/hadoop/etc/hadoop下
- 注意:原来没有mapred-site.xml,是改名来的
mv mapred-site.xml.template mapred-site.xml
vim mapred-site.xml
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>

2.4.5 配置yarn-site.xml
在/usr/local/hadoop/etc/hadoop下
vim yarn-site.xml
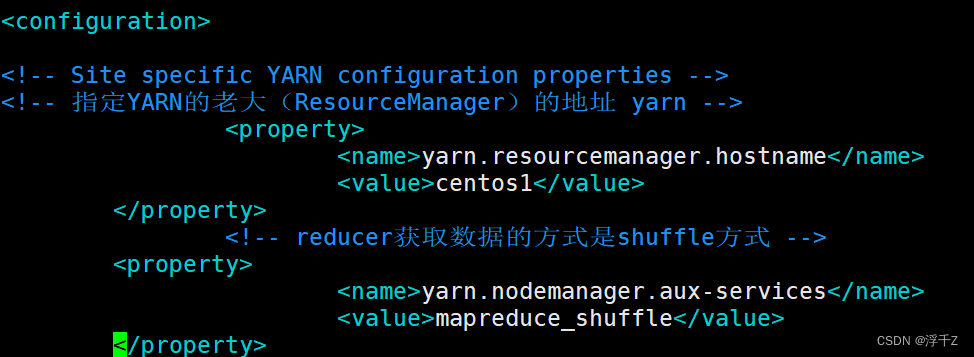
<!-- 指定YARN的老大(ResourceManager)的地址 yarn -->
<property>
<name>yarn.resourcemanager.hostname</name>
<value>centos1</value>
</property>
<!-- reducer获取数据的方式是shuffle方式 -->
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
3.配置Hadoop环境变量
3.1 进入、添加、使修改后的环境变量生效
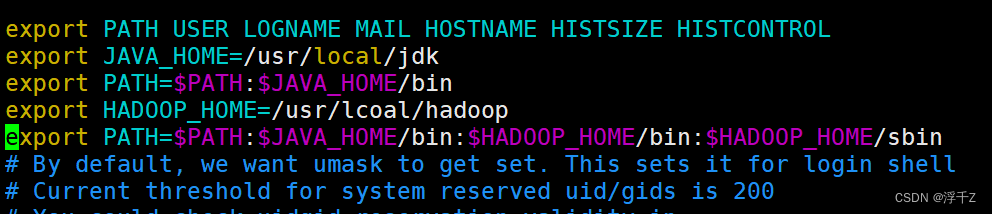
vim /etc/profile
export HADOOP_HOME=/usr/local/hadoop
export PATH=$PATH:$HADOOP_HOME/bin:$HADOOP_HOME/sbin
source /etc/profile
3.3格式化namenode
hdfs namenode -format
创建账本目录、datanode目录

遇到的问题
原因是配置环境变量有问题,要保证3.1配置环境变量没写错,是你的Hadoop的安装位置(别写错字母了)

- 额外:
- 端口,两个电脑需要有端口才能相互传递信息,一个电脑有很多端口,类似一个国家有很多港口















 3万+
3万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









