







文章目录
- 零、本节学习目标
- 一、RDD的处理过程
- 二、RDD算子
- 三、准备工作
- 四、掌握转换算子
- 五、掌握行动算子
零、本节学习目标
- 了解RDD的处理过程
- 掌握转换算子的使用
- 掌握行动算子的使用
一、RDD的处理过程
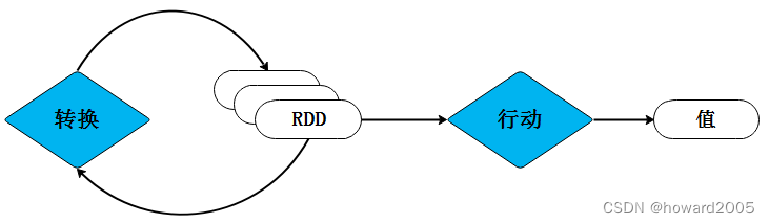
- Spark用Scala语言实现了RDD的API,程序开发者可以通过调用API对RDD进行操作处理。RDD经过一系列的“转换”操作,每一次转换都会产生不同的RDD,以供给下一次“转换”操作使用,直到最后一个RDD经过“行动”操作才会被真正计算处理,并输出到外部数据源中,若是中间的数据结果需要复用,则可以进行缓存处理,将数据缓存到内存中。
二、RDD算子
- RDD被创建后是只读的,不允许修改。Spark提供了丰富的用于操作RDD的方法,这些方法被称为算子。一个创建完成的RDD只支持两种算子:
转换(Transformation)算子和行动(Action)算子。
(一)转换算子
- RDD处理过程中的“转换”操作主要用于根据已有RDD创建新的RDD,每一次通过Transformation算子计算后都会返回一个新RDD,供给下一个转换算子使用。
- 常用转换算子操作的API
| 转换算子 | 相关说明 |
|---|---|
| filter(func) | 筛选出满足函数func的元素,并返回一个新的数据集 |
| map(func) | 将每个元素传递到函数func中,返回的结果是一个新的数据集 |
| flatMap(func) | 与map()相似,但是每个输入的元素都可以映射到0或者多个输出结果 |
| groupByKey() | 应用于(Key,Value)键值对的数据集时,返回一个新的(Key,Iterable <Value>)形式的数据集 |
| reduceByKey(func) | 应用于(Key,Value)键值对的数据集时,返回一个新的(Key,Value)形式的数据集。其中,每个Value值是将每个Key键传递到函数func中进行聚合后的结果 |
(二)行动算子
- 行动算子主要是将在数据集上运行计算后的数值返回到驱动程序,从而触发真正的计算。
- 常用行动算子操作的API
| 行动算子 | 相关说明 |
|---|---|
| count() | 返回数据集中的元素个数 |
| first() | 返回数组的第一个元素 |
| take(n) | 以数组的形式返回数组集中的前n个元素 |
| reduce(func) | 通过函数func(输入两个参数并返回一个值)聚合数据集中的元素 |
| collect() | 以数组的形式返回数据集中的所有元素 |
| foreach(func) | 将数据集中的每个元素传递到函数func中运行 |
三、准备工作
(一)准备文件
1、准备本地系统文件
- 在
/home目录里创建words.txt

2、把文件上传到HDFS
- 将
words.txt上传到HDFS系统的/park目录里
- 说明:
/park是在上一讲我们创建的目录 - 查看文件内容

(二)启动Spark Shell
1、启动HDFS服务
- 执行命令:
start-dfs.sh
2、启动Spark服务
- 执行命令:
start-all.sh
3、启动Spark Shell
- 执行名命令:
spark-shell --master spark://master:7077
- 以集群模式启动的Spark Shell,不能访问本地文件,只能访问HDFS文件,加不加
hdfs://master:9000前缀都是一样的效果。
四、掌握转换算子
- 转换算子负责对RDD中的数据进行计算并转换为新的RDD。Spark中的所有转换算子都是
惰性的,因为它们不会立即计算结果,而只是记住对某个RDD的具体操作过程,直到遇到行动算子才会与行动算子一起执行。
(一)映射算子 - map()
1、映射算子功能
- map()是一种转换算子,它接收一个函数作为参数,并把这个函数应用于RDD的
每个元素,最后将函数的返回结果作为结果RDD中对应元素的值。
2、映射算子案例
- 预备工作:创建一个RDD -
rdd1 - 执行命令:
val rdd1 = sc.parallelize(List(1, 2, 3, 4, 5, 6))
-
对
rdd1应用map()算子,将rdd1中的每个元素平方并返回一个名为rdd2的新RDD
-
上述代码中,向算子map()传入了一个函数
x = > x * 2。其中,x为函数的参数名称,也可以使用其他字符,例如a => a * 2。Spark会将RDD中的每个元素传入该函数的参数中。 -
其实,利用神奇占位符
_可以写得更简洁
-
rdd1和rdd2中实际上没有任何数据,因为parallelize()和map()都为转化算子,调用转化算子不会立即计算结果。
-
若需要查看计算结果,则可使用行动算子
collect()。(collect是采集或收集之意) -
执行
rdd2.collect进行计算,并将结果以数组的形式收集到当前Driver。因为RDD的元素为分布式的,数据可能分布在不同的节点上。
-
take action: 采取行动。心动不如行动。
-
上述使用
map()算子的运行过程如下图所示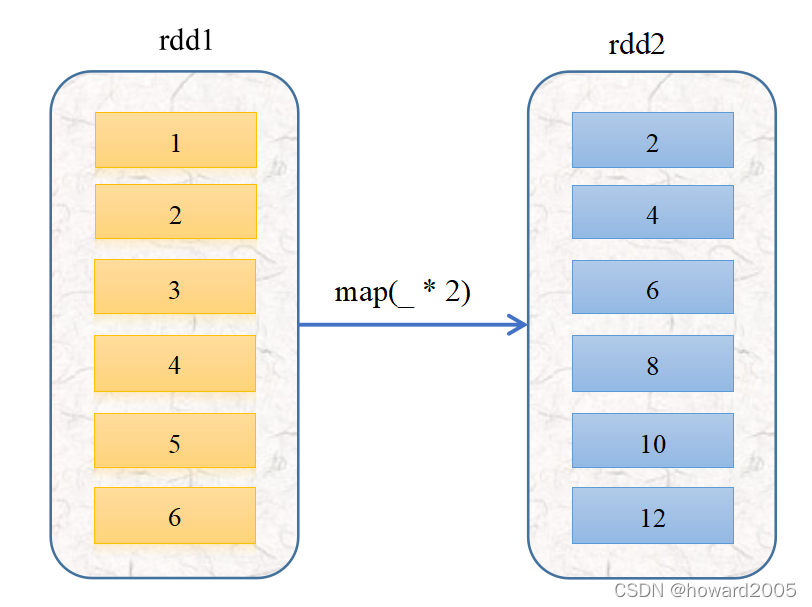
-
函数本质就是一种特殊的映射。上面这个映射写成函数:f ( x ) = 2 x , x ∈ R f(x)=2x,x\in \Bbb Rf(x)=2x,x∈R
-
方法一、采用普通函数作为参数传给map()算子

-
方法二、采用下划线表达式作为参数传给map()算子
-
刚才翻倍用的是
map(_ * 2),很自然地想到平方应该是map(_ * _)
-
报错,
(_ * _)经过eta-expansion变成普通函数,不是我们预期的x => x * x,而是(x$1, x$2) => (x$1 * x$2),不是一元函数,而是二元函数,系统立马就蒙逼了,不晓得该怎么取两个参数来进行乘法运算。-
难道就不能用下划线参数了吗?当然可以,但是必须保证下划线表达式里下划线只出现
1次。引入数学包scala.math._就可以搞定。
-
-
但是有点美中不足,rdd2的元素变成了双精度实数,得转化成整数

- 菱形正立的等腰三角形和倒立的等腰三角形组合而成

- 半菱形


- 加上前导空格,显示菱形

- 参考代码(兼顾通用性)

import scala.collection.mutable.ListBuffer
val list = new ListBuffer[Int]()
val n = 21
(1 to n by 2).foreach(list += _)
(n - 2 to 1 by -2).foreach(list += _)
val rdd = sc.makeRDD(list)
val rdd1 = rdd.map(i => " " * ((n - i) / 2) + "*" * i)
rdd1.collect.foreach(println)
- 参照讲课笔记2.4创建Maven项目 -
SparkRDDDemo
- 单击【Finish】按钮
- 将
java目录改成scala目录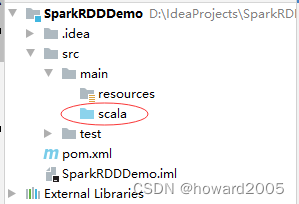
- 在
pom.xml文件里添加相关依赖和设置源程序目录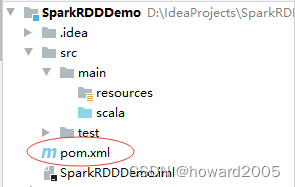
<?xml version="1.0" encoding="UTF-8"?>
<project xmlns="http://maven.apache.org/POM/4.0.0"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://maven.apache.org/POM/4.0.0
http://maven.apache.org/xsd/maven-4.0.0.xsd">
<modelVersion>4.0.0</modelVersion>
<groupId>net.huawei.rdd</groupId>
<artifactId>SparkRDDDemo</artifactId>
<version>1.0-SNAPSHOT</version>
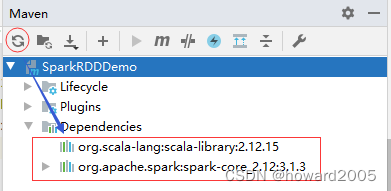
<dependencies>
<dependency>
<groupId>org.scala-lang</groupId>
<artifactId>scala-library</artifactId>
<version>2.12.15</version>
</dependency>
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-core_2.12</artifactId>
<version>3.1.3</version>
</dependency>
</dependencies>
<build>
<sourceDirectory>src/main/scala</sourceDirectory>
</build>
</project>

- 刷新项目依赖
- 添加日志属性文件
log4j.rootLogger=ERROR, stdout, logfile
log4j.appender.stdout=org.apache.log4j.ConsoleAppender
log4j.appender.stdout.layout=org.apache.log4j.PatternLayout
log4j.appender.stdout.layout.ConversionPattern=%d %p [%c] - %m%n
log4j.appender.logfile=org.apache.log4j.FileAppender
log4j.appender.logfile.File=target/rdd.log
log4j.appender.logfile.layout=org.apache.log4j.PatternLayout
log4j.appender.logfile.layout.ConversionPattern=%d %p [%c] - %m%n
- 创建
hdfs-site.xml文件,允许客户端访问集群数据节点
<?xml version="1.0" encoding="UTF-8"?>
<configuration>
<property>
<description>only config in clients</description>
<name>dfs.client.use.datanode.hostname</name>
<value>true</value>
</property>
</configuration>
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 创建
net.huawei.rdd.day01包
- 在
net.huawei.rdd.day01包里创建Example01单例对象
package net.huawei.rdd.day01
import org.apache.spark.{SparkConf, SparkContext}
import scala.collection.mutable.ListBuffer
import scala.io.StdIn
object Example01 {
def main(args: Array[String]): Unit = {
// 创建Spark配置对象
val conf = new SparkConf()
.setAppName("PrintDiamond") // 设置应用名称
.setMaster("local[*]") // 设置主节点位置(本地调试)
// 基于Spark配置对象创建Spark容器
val sc = new SparkContext(conf)
// 输入一个奇数
print("输入一个奇数:")
val n = StdIn.readInt()
// 创建一个可变列表
val list = new ListBuffer[Int]()
// 给列表赋值
(1 to n by 2).foreach(list += _)
(n - 2 to 1 by -2).foreach(list += _)
// 基于列表创建rdd
val rdd = sc.makeRDD(list)
// 对rdd进行映射操作
val rdd1 = rdd.map(i => " " * ((n - i) / 2) + "*" * i)
// 输出rdd1结果
rdd1.collect.foreach(println)
}
}

- 运行程序,查看结果
-

- 假如用户输入一个偶数,会出现什么情况?

- 修改一下代码,避免这个问题

- 运行程序,输入一个偶数
-

(二)过滤算子 - filter()
1、过滤算子功能
filter(func):通过函数func对源RDD的每个元素进行过滤,并返回一个新RDD,一般而言,新RDD元素个数会少于原RDD。
2、过滤算子案例
-
基于列表创建RDD,然后利用过滤算子得到偶数构成的新RDD
-
方法一、将匿名函数传给过滤算子

-
方法二、用神奇占位符改写传入过滤算子的匿名函数

-
将
rdd1里的每一个元素x拿去计算x % 2 == 0,如果关系表达式计算结果为真,那么该元素就丢进新RDD -rdd2,否则就被过滤掉了。
-
查看源文件
/park/words.txt内容
-
执行命令:
val lines= sc.textFile("/park/words.txt"),读取文件/park/words.txt生成RDD -lines
-
执行命令:
val sparkLines = lines.filter(_.contains("spark")),过滤包含spark的行生成RDD -sparkLines
-
执行命令:
sparkLines.collect,查看sparkLines内容,可以采用遍历算子,分行输出内容
任务1、利用过滤算子输出[2000, 2500]之间的全部闰年
-
传统做法,利用循环结构嵌套选择结构来实现
-

-
要求每行输出10个数

-
采用过滤算子来实现

-
要求每行输出10个数

- 过滤算子:
filter(n => !(n % 2 == 0 || n % 3 == 0 || n % 5 == 0 || n % 7 == 0))
value
(三)扁平映射算子 - flatMap()
1、扁平映射算子功能
- flatMap()算子与map()算子类似,但是每个传入给函数func的RDD元素会返回0到多个元素,最终会将返回的所有元素合并到一个RDD。
2、扁平映射算子案例
-
读取文件,生成RDD -
rdd1,查看其内容和元素个数
-
对于
rdd1按空格拆分,做映射,生成新RDD -rdd2
-
对于
rdd1按空格拆分,做扁平映射,生成新RDD -rdd3,有一个降维处理的效果
-
统计结果:文件里有25个单词
- rdd1的
5个元素经过扁平映射变成了rdd2的20个元素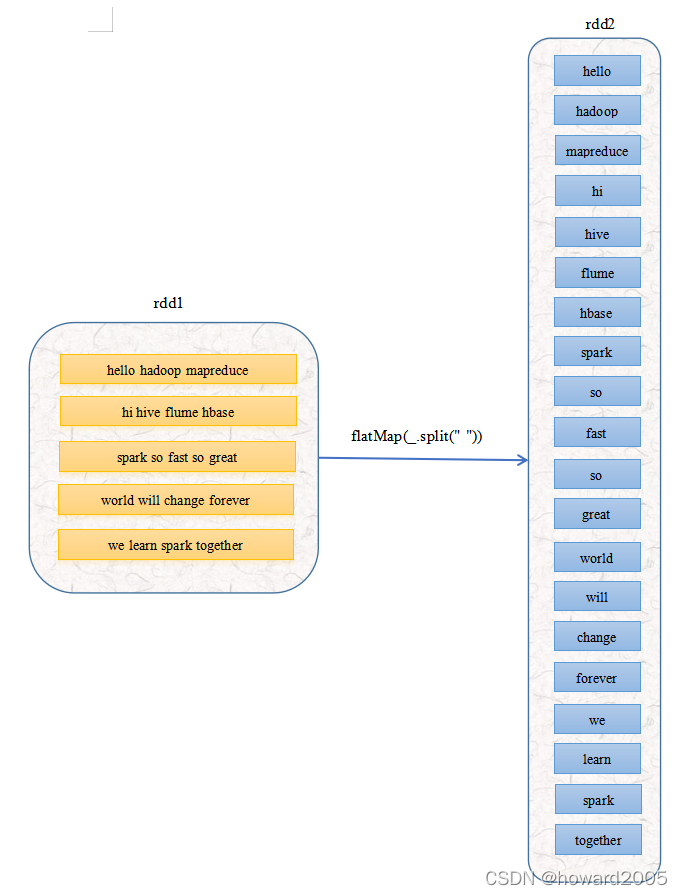
[ 7 8 1 5 10 4 9 7 2 8 1 4 21 4 7 − 4 ] \left[
7107218424198751−4478151049728142147−4
\right]7107218424198751−44
- 利用列表的
flatten函数 - 在
net.huawei.rdd.day01包里创建Example02单例对象
package net.huawei.rdd.day01
import org.apache.spark.{SparkConf, SparkContext}
/**
* 功能:利用Scala统计不规则二维列表元素个数
* 日期:2023年04月19日
*/
object Example02 {
def main(args: Array[String]): Unit = {
// 创建Spark配置对象
val conf = new SparkConf()
.setAppName("PrintDiamond") // 设置应用名称
.setMaster("local[*]") // 设置主节点位置(本地调试)
// 基于Spark配置对象创建Spark容器
val sc = new SparkContext(conf)
// 创建不规则二维列表
val mat = List(
List(7, 8, 1, 5),
List(10, 4, 9),
List(7, 2, 8, 1, 4),
List(21, 4, 7, -4)
)
// 输出二维列表
println(mat)
// 将二维列表扁平化为一维列表
val arr = mat.flatten
// 输出一维列表
println(arr)
// 输出元素个数
println("元素个数:" + arr.size)
}
}
- 运行程序,查看结果

- 利用flatMap算子
- 在
net.huawei.rdd.day01包里创建Example03单例对象
package net.huawei.rdd.day01
import org.apache.spark.{SparkConf, SparkContext}
//功能:利用RDD统计不规则二维列表元素个数
object Example03 {
def main(args: Array[String]): Unit = {
// 创建Spark配置对象
val conf = new SparkConf()
.setAppName("PrintDiamond") // 设置应用名称
.setMaster("local[*]") // 设置主节点位置(本地调试)
// 基于Spark配置对象创建Spark容器
val sc = new SparkContext(conf)
// 创建不规则二维列表
val mat = List(
List(7, 8, 1, 5),
List(10, 4, 9),
List(7, 2, 8, 1, 4),
List(21, 4, 7, -4)
)
// 基于二维列表创建rdd1
val rdd1 = sc.makeRDD(mat)
// 输出rdd1
rdd1.collect.foreach(x => print(x + " "))
println()
// 进行扁平化映射
val rdd2 = rdd1.flatMap(x => x.toString.substring(5, x.toString.length - 1).split(", "))
// 输出rdd2
rdd2.collect.foreach(x => print(x + " "))
println()
// 输出元素个数
println("元素个数:" + rdd2.count)
}
}

- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 运行程序,查看结果

- 扁平化映射可以简化

(四)按键归约算子 - reduceByKey()
1、按键归约算子功能
- reduceByKey()算子的作用对像是元素为(key,value)形式(Scala元组)的RDD,使用该算子可以将相同key的元素聚集到一起,最终把所有相同key的元素合并成一个元素。该元素的key不变,value可以聚合成一个列表或者进行求和等操作。最终返回的RDD的元素类型和原有类型保持一致。
2、按键归约算子案例
- 成绩表,包含四个字段(姓名、语文、数学、英语),只有三条记录
| 姓名 | 语文 | 数学 | 英语 |
|---|---|---|---|
| 张钦林 | 78 | 90 | 76 |
| 陈燕文 | 95 | 88 | 98 |
| 卢志刚 | 78 | 80 | 60 |
- 创建成绩列表
scores,基于成绩列表创建rdd1,对rdd1按键归约得到rdd2,然后查看rdd2内容
val scores = List(("张钦林", 78), ("张钦林", 90), ("张钦林", 76),
("陈燕文", 95), ("陈燕文", 88), ("陈燕文", 98),
("卢志刚", 78), ("卢志刚", 80), ("卢志刚", 60))
val rdd1 = sc.makeRDD(scores)
val rdd2 = rdd1.reduceByKey((x, y) => x + y)
rdd2.collect.foreach(println)
- 1
- 2
- 3
- 4
- 5
- 6
- 不仅可以在Spark Shell里完成任务,也可以编写Scala程序生成jar提交到Spark服务器运行。有兴趣的同学不妨参看《Spark案例:两种方式计算学生总分》
- 成绩表,包含四个字段(姓名、语文、数学、英语),只有三条记录
| 姓名 | 语文 | 数学 | 英语 |
|---|---|---|---|
| 张钦林 | 78 | 90 | 76 |
| 陈燕文 | 95 | 88 | 98 |
| 卢志刚 | 78 | 80 | 60 |
-
可能存在问题:在Windows下的IDEA中访问HDFS报错
Could not locate executable null\bin\winutils.exe -
下载对应版本的
winutils.exe,放在hadoop安装目录的bin子目录里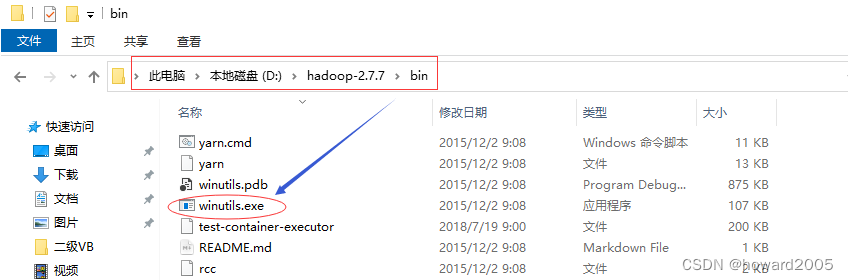
-
配置hadoop环境变量

-
创建Maven项目 - SparkRDDDemo


-
将
java目录改为scala
-
在
pom.xml文件里添加依赖和构建插件
<?xml version="1.0" encoding="UTF-8"?>
<project xmlns="http://maven.apache.org/POM/4.0.0"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://maven.apache.org/POM/4.0.0
http://maven.apache.org/xsd/maven-4.0.0.xsd">
<modelVersion>4.0.0</modelVersion>
<groupId>net.hw.rdd</groupId>
<artifactId>SparkRDDDemo</artifactId>
<version>1.0-SNAPSHOT</version>
<dependencies>
<dependency>
<groupId>org.scala-lang</groupId>
<artifactId>scala-library</artifactId>
<version>2.12.15</version>
</dependency>
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-core_2.12</artifactId>
<version>2.4.4</version>
</dependency>
</dependencies>
<build>
<sourceDirectory>src/main/scala</sourceDirectory>
<plugins>
<plugin>
<groupId>org.apache.maven.plugins</groupId>
<artifactId>maven-assembly-plugin</artifactId>
<version>3.3.0</version>
<configuration>
<descriptorRefs>
<descriptorRef>jar-with-dependencies</descriptorRef>
</descriptorRefs>
</configuration>
<executions>
<execution>
<id>make-assembly</id>
<phase>package</phase>
<goals>
<goal>single</goal>
</goals>
</execution>
</executions>
</plugin>
<plugin>
<groupId>net.alchim31.maven</groupId>
<artifactId>scala-maven-plugin</artifactId>
<version>3.3.2</version>
<executions>
<execution>
<id>scala-compile-first</id>
<phase>process-resources</phase>
<goals>
<goal>add-source</goal>
<goal>compile</goal>
</goals>
</execution>
<execution>
<id>scala-test-compile</id>
<phase>process-test-resources</phase>
<goals>
<goal>testCompile</goal>
</goals>
</execution>
</executions>
</plugin>
</plugins>
</build>
</project>

- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17

- 在资源文件夹里创建日志属性文件

log4j.rootLogger=ERROR, stdout, logfile
log4j.appender.stdout=org.apache.log4j.ConsoleAppender
log4j.appender.stdout.layout=org.apache.log4j.PatternLayout
log4j.appender.stdout.layout.ConversionPattern=%d %p [%c] - %m%n
log4j.appender.logfile=org.apache.log4j.FileAppender
log4j.appender.logfile.File=target/spark.log
log4j.appender.logfile.layout=org.apache.log4j.PatternLayout
log4j.appender.logfile.layout.ConversionPattern=%d %p [%c] - %m%n
- 创建
net.hw.rdd包

- 在
net.hw.rdd包里创建CalculateScoreSum单例对象


- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 运行程序,查看结果

- 在
net.hw.rdd包里创建CalculateScoreSum02单例对象
package net.hw.rdd
import org.apache.spark.{SparkConf, SparkContext}
import scala.collection.mutable.ListBuffer
// 功能:计算总分
object CalculateScoreSum02 {
def main(args: Array[String]): Unit = {
// 创建Spark配置对象
val conf = new SparkConf()
.setAppName("CalculateScoreSum")
.setMaster("local[*]")
// 基于配置创建Spark上下文
val sc = new SparkContext(conf)
// 创建四元组成绩列表
val scores = List(
("张钦林", 78, 90, 76),
("陈燕文", 95, 88, 98),
("卢志刚", 78, 80, 60)
)
// 将四元组成绩列表转化成二元组成绩列表
val newScores = new ListBuffer[(String, Int)]();
// 通过遍历算子遍历四元组成绩列表
scores.foreach(score => {
newScores += Tuple2(score._1, score._2)
newScores += Tuple2(score._1, score._3)
newScores += Tuple2(score._1, score._4)}
)
// 基于二元组成绩列表创建RDD
val rdd1 = sc.makeRDD(newScores)
// 对成绩RDD进行按键归约处理
val rdd2 = rdd1.reduceByKey((x, y) => x + y)
// 输出归约处理结果
rdd2.collect.foreach(println)
}
}

- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 可以采用循环结构将四元组成绩列表转化成二元组成绩列表
for (score <- scores) {
newScores += Tuple2(score._1, score._2)
newScores += Tuple2(score._1, score._3)
newScores += Tuple2(score._1, score._4)
}
- 运行程序,查看结果
-

- 在master虚拟机的
/home目录里创建成绩文件 -scores.txt 
- 将成绩文件上传到HDFS的
/input目录
- 在
net.hw.rdd包里创建CalculateScoreSum03单例对象
package net.hw.rdd
import org.apache.spark.{SparkConf, SparkContext}
import scala.collection.mutable.ListBuffer
/**
* 功能:计算总分
* 作者:华卫
* 日期:2022年05月31日
*/
object CalculateScoreSum03 {
def main(args: Array[String]): Unit = {
// 创建Spark配置对象
val conf = new SparkConf()
.setAppName("CalculateScoreSum")
.setMaster("local[*]")
// 基于配置创建Spark上下文
val sc = new SparkContext(conf)
// 读取成绩文件,生成RDD
val lines = sc.textFile("hdfs://master:9000/input/scores.txt")
// 定义二元组成绩列表
val scores = new ListBuffer[(String, Int)]()
// 遍历lines,填充二元组成绩列表
lines.collect.foreach(line => {
val fields = line.split(" ")
scores += Tuple2(fields(0), fields(1).toInt)
scores += Tuple2(fields(0), fields(2).toInt)
scores += Tuple2(fields(0), fields(3).toInt)
})
// 基于二元组成绩列表创建RDD
val rdd1 = sc.makeRDD(scores)
// 对成绩RDD进行按键归约处理
val rdd2 = rdd1.reduceByKey((x, y) => x + y)
// 输出归约处理结果
rdd2.collect.foreach(println)
}
}

- 运行程序,查看结果

- 在Spark Shell里完成同样的任务


- 修改程序,将计算结果写入HDFS文件
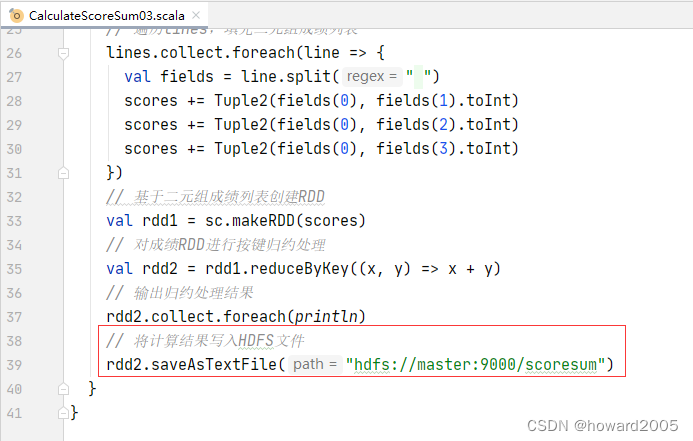
- 运行程序,报错没有
写权限
- 设置
HADOOP_USER_NAME属性为root
- 运行程序,查看结果
-

- 查看HDFS上生成的结果文件

(五)合并算子 - union()
1、合并算子功能
- union()算子将两个RDD合并为一个新的RDD,主要用于对不同的数据来源进行合并,两个RDD中的数据类型要保持一致。
2、合并算子案例
- 创建两个RDD,合并成一个新RDD

(六)排序算子 - sortBy()
1、排序算子功能
- sortBy()算子将RDD中的元素按照某个规则进行排序。该算子的第一个参数为排序函数,第二个参数是一个布尔值,指定升序(默认)或降序。若需要降序排列,则需将第二个参数置为false。
2、排序算子案例
- 一个数组中存放了三个元组,将该数组转为RDD集合,然后对该RDD按照每个元素中的第二个值进行降序排列。

sortBy(x=>x._2,false)中的x代表rdd1中的每个元素。由于rdd1的每个元素是一个元组,因此使用x._2取得每个元素的第二个值。当然,sortBy(x=>x._2,false)也可以直接简化为sortBy(_._2,false)。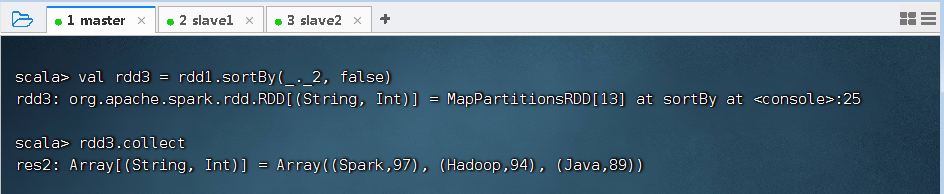
(七)按键排序算子 - sortByKey()
1、按键排序算子功能
- sortByKey()算子将(key,value)形式的RDD按照key进行排序。默认升序,若需降序排列,则可以传入参数false。
2、按键排序算子案例
- 将三个二元组构成的RDD按键先降序排列,然后升序排列

(八)连接算子
1、内连接算子 - join()
- join()算子将两个(key, value)形式的RDD根据key进行连接操作,相当于数据库的内连接(Inner Join),只返回两个RDD都匹配的内容。
- 将rdd1与rdd2进行内连接

2、左外连接算子 - leftOuterJoin()
- leftOuterJoin()算子与数据库的左外连接类似,以左边的RDD为基准(例如rdd1.leftOuterJoin(rdd2),以rdd1为基准),左边RDD的记录一定会存在。例如,rdd1的元素以(k,v)表示,rdd2的元素以(k, w)表示,进行左外连接时将以rdd1为基准,rdd2中的k与rdd1的k相同的元素将连接到一起,生成的结果形式为(k,(v,Some(w))。rdd1中其余的元素仍然是结果的一部分,元素形式为(k,(v,None)。Some和None都属于Option类型,Option类型用于表示一个值是可选的(有值或无值)。若确定有值,则使用Some(值)表示该值;若确定无值,则使用None表示该值。
- rdd1与rdd2进行左外连接

3、右外连接算子 - rightOuterJoin()
- rightOuterJoin()算子的使用方法与leftOuterJoin()算子相反,其与数据库的右外连接类似,以右边的RDD为基准(例如rdd1.rightOuterJoin(rdd2),以rdd2为基准),右边RDD的记录一定会存在。
- rdd1与rdd2进行右外连接

4、全外连接算子 - fullOuterJoin()
- fullOuterJoin()算子与数据库的全外连接类似,相当于对两个RDD取并集,两个RDD的记录都会存在。值不存在的取None。
- rdd1与rdd2进行全外连接

(九)交集算子 - intersection()
1、交集算子功能
- intersection()算子对两个RDD进行交集操作,返回一个新的RDD。要求两个算子类型要一致。
2、交集算子案例
- rdd1与rdd2进行交集操作

(十)去重算子 - distinct()
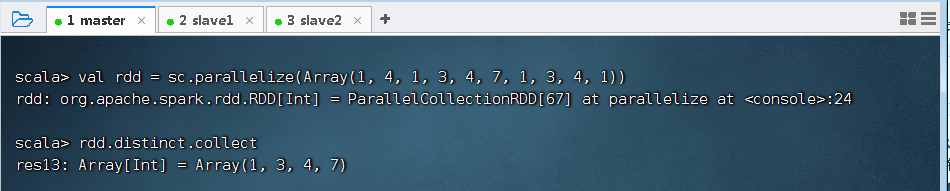
1、去重算子功能
- distinct()算子对RDD中的数据进行去重操作,返回一个新的RDD。有点类似与集合的不允许重复元素。
2、去重算子案例
- 去掉rdd中重复的元素
(十一)组合分组算子 - cogroup()
1、组合分组算子功能
- cogroup()算子对两个(key, value)形式的RDD根据key进行组合,相当于根据key进行并集操作。例如,rdd1的元素以(k, v)表示,rdd2的元素以(k, w)表示,执行rdd1.cogroup(rdd2)生成的结果形式为(k, (Iterable, Iterable))。
2、组合分组算子案例
- rdd1与rdd2进行组合分组操作

五、掌握行动算子
- Spark中的转化算子并不会马上进行运算,而是在遇到行动算子时才会执行相应的语句,触发Spark的任务调度。

(一)归约算子 - reduce()
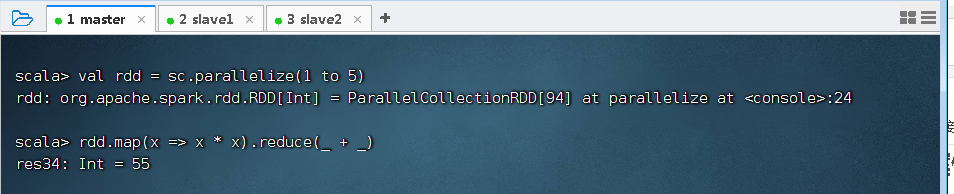
1、归约算子功能
- reduce()算子按照传入的函数进行归约计算
2、归约算子案例
- 计算1 + 2 + 3 + … … + 100 1 + 2 + 3 + …… + 1001+2+3+……+100的值

- 计算1 2 + 2 2 + 3 2 + 4 2 + 5 2 1^2 + 2^2 + 3^2 + 4^2 + 5^212+22+32+42+52的值
(三)按键计数算子 - countByKey()
1、按键计数算子功能
- 按键统计RDD键值出现的次数,返回由键值和次数构成的映射。
2、按键计数算子案例
- List集合中存储的是键值对形式的元组,使用该List集合创建一个RDD,然后对其进行countByKey()的计算。

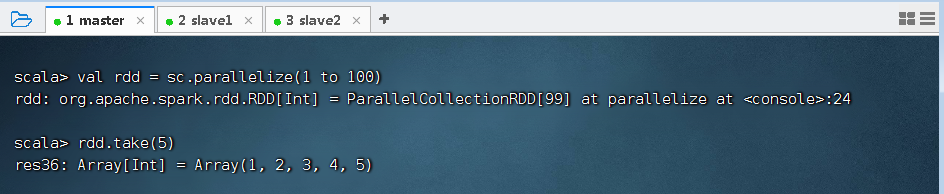
(四)前截取算子 - take(n)
1、前截取算子功能
- 返回RDD的前n个元素(同时尝试访问最少的partitions),返回结果是无序的,测试使用。
2、前截取算子案例
- 返回集合中前5个元素组成的数组
(五)遍历算子 - foreach()
1、遍历算子功能
- 计算 RDD中的每一个元素,但不返回本地(只是访问一遍数据),可以配合println()友好打印数据。
2、遍历算子案例
- 将RDD里的每个元素平方后输出

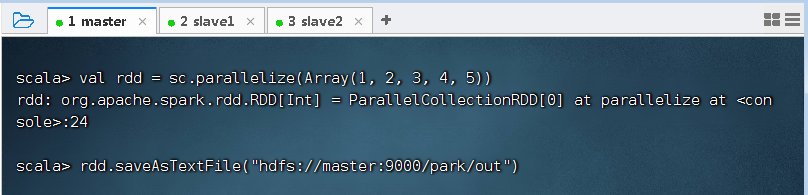
(六)存文件算子 - saveAsFile()
1、存文件算子功能
- 将RDD数据保存到本地文件或HDFS文件
2、存文件算子案例
- 将rdd内容保存到HDFS的/park/out.txt
















 1229
1229











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









